Wan S2V开源视频生成模型
WAN-S2V不是AI视频的最终答案,但它显然走在正确的方向上。它能够处理长视频,保持身份不变,并且实际上感觉它“理解”了场景,是的,这是一个巨大的转变。

长期以来,开源社区一直在等待一个可以同时生成音频的视频生成模型。我认为现在是时候说再见了,告别谷歌Veo3,这个唯一可以生成带音频视频的AI选项,但它是付费的。现在我们有了WAN 2.2 S2V,可以免费为你做到这一点。
来自阿里云通义实验室的WAN-S2V可以生成带音频的AI视频,没错,你没听错。
这不仅仅是说话的人头。它更接近于电影制作中预可视化工具所预期的效果:从一张图片、一段音频和一个文本描述生成长而富有表现力的场景。输出不仅仅是移动,而是表演。
想法很简单:
你给WAN-S2V:
一张图片(这是你的角色) 一段音频(说话、唱歌等) 一个文本提示(比如:“一个男人沿着铁路走,情绪化地唱着歌,火车从他身边经过”)
它会给你返回一个视频,其中一切都在动,包括面部、四肢,甚至相机本身。它记得角色的表情,对环境做出反应,并像一个小电影场景一样演绎出来。
1、这里有什么不同?
大多数模型只专注于微观层面的控制。它们只是同步嘴唇动作。WAN-S2V当然也这样做,但它不止于此。它将工作分为:
- 文本: 引导大的东西,摄像机角度,角色站立的位置,场景布局
- 音频: 处理小的东西,唇形同步、点头、眼神、手势
这种分离有效。因为文本在时间上很糟糕,但在上下文上很好。而音频在节奏上很好,但无法告诉你“低角度戏剧性镜头”是什么样子。两者结合在一起,效果很好。
2、Wan S2V内部结构
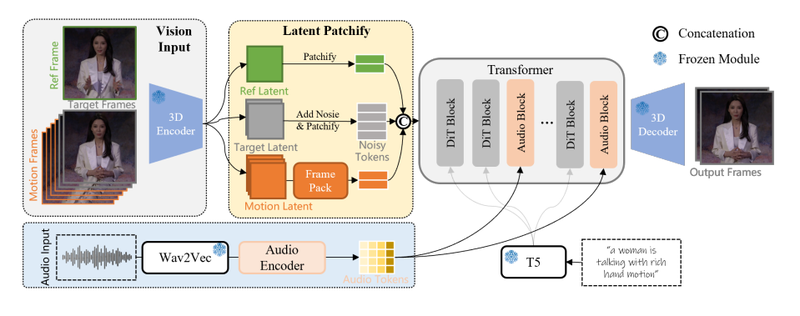
WAN-S2V的核心是一个他们称为WAN-14B的大视频模型。
它是一个扩散模型,因此它通过从噪声视频数据开始并逐步清理来学习。经典的去噪方法,但有一个转折:它不仅在视频上进行训练,还在对齐的图像+音频+提示上进行训练。该模型根据这三个因素确定如何移动像素。
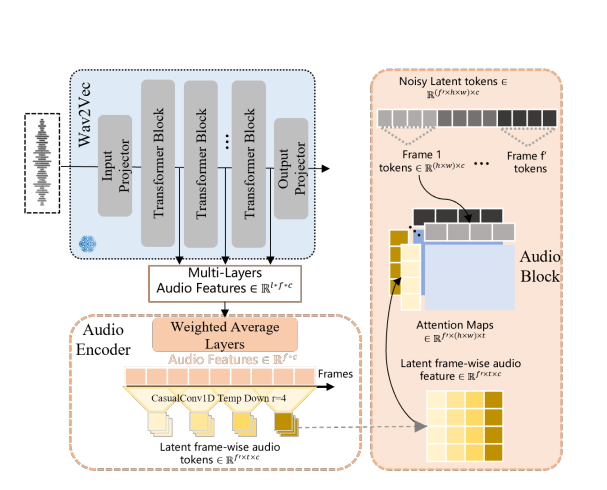
音频由Wav2Vec处理,它可以提取节奏和情感基调。而不是向模型输入原始波形,它逐帧压缩音频以匹配视频标记。这就是嘴唇和手保持同步的原因。
对于长视频,他们使用一种叫做FramePack的技术。基本上,它压缩运动历史,这样模型就能记住之前发生的事情,角色是谁,在上一场景中做了什么,火车移动有多快。这有助于它在剪辑之间保持一致性,就像实际的电影场景一样。
3、数据游戏
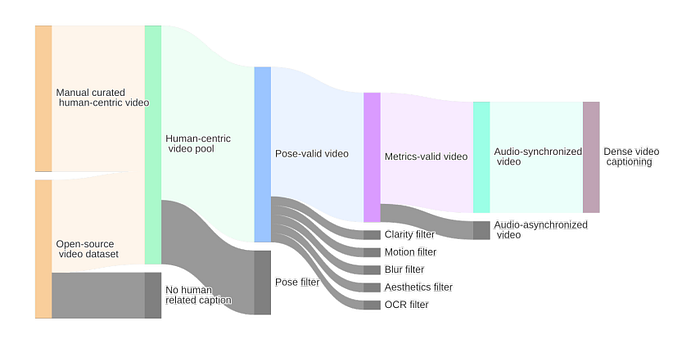
一个主要优势?他们不仅在YouTube的演讲者头上训练。WAN-S2V从开放数据集如OpenHumanVid和Koala36M中获取数据,还添加了手动策划的场景:在船上唱歌、在戏剧般的环境中表演、多个角色互动。
他们严格过滤数据,扔掉任何模糊的手或脸、不同步的音频,甚至遮挡脸部的字幕。他们用ViTPose跟踪身体姿态,确保脸部始终可见,并且甚至使用美学评分来保持内容的精致。这个流程比人们想象的更重要。
4、性能
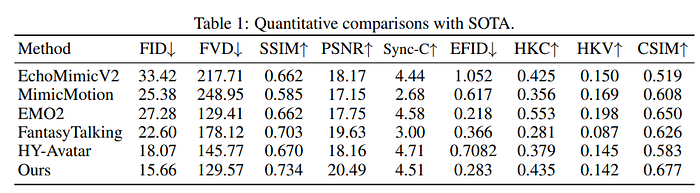
数字不是一切,但它们确实重要。WAN-S2V在几乎所有关键指标上都优于其他模型:
- FID(真实性):15.66,优于EchoMimicV2(33.42)和甚至Hunyuan-Avatar(18.07)
- SSIM/PSNR(清晰度):行业领先
- CSIM(面部身份一致性):再次获得最高分
- 唇形同步(Sync-C):第二好,仅略逊于Hunyuan
不过它并不完美。在手部动作方面,EMO2由于其预先生成的动作序列仍然获胜。但考虑到它是在没有太多手工工程步骤的情况下端到端完成的,WAN-S2V在这方面表现得也不错。
5、使用案例
如果你对视频生成感兴趣,你就会知道大多数演示在尝试超过5秒时会崩溃。WAN-S2V不一样。
想要从自拍和一首歌生成音乐视频吗?完成了。 想让一个角色以电影般的摄像机移动方式演绎剧本吗?可以做到。 想要拼接多个视频场景,同时保持相同的角色和动作风格吗?它也可以做到。
这个模型是迈向更生产就绪的一步。不只是用于研究幻灯片。真正的可用输出。
你可以从这里使用这个模型。
6、结束语
WAN-S2V不是AI视频的最终答案,但它显然走在正确的方向上。它能够处理长视频,保持身份不变,并且实际上感觉它“理解”了场景,是的,这是一个巨大的转变。如果你在构建任何AI视频、虚拟形象或创意工具,这个模型值得你深入研究。
如果别的什么都没有,它终于摆脱了说话人头的陷阱。仅凭这一点,它就值得认真对待。
原文链接:Wan S2V : Goodbye Google Veo3
汇智网翻译整理,转载请标明出处
