为什么LLM搞不定时间序列?
让我们明确一点:LLMs并不是一个万能的解决方案。而就时间序列建模而言,它们是错误的工具。

大型语言模型(LLMs)已经引起了全世界的关注。这确实有充分的理由——它们功能强大、灵活且通用。但不知从何时起,我们开始将它们视为解决所有问题的万能钥匙。
让我们明确一点:LLMs并不是一个万能的解决方案。而就时间序列建模而言,它们是错误的工具。
1、一个激励性的例子
我们进行一个简单的实验来展示LLMs在预测方面的表现有多差。我们对油价(每日收盘价)进行建模,并使用ChatGPT和Claude进行价格预测,然后比较输出结果。我们报告了均方误差(MSE),这是预测任务中一种流行的误差指标。
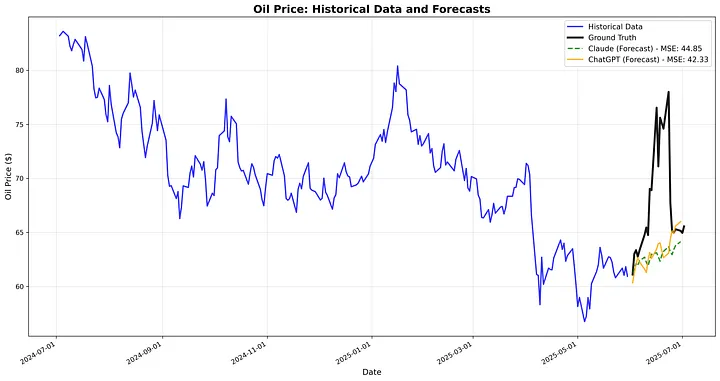
这些模型完全错过了峰值,而是显示了一条相对平滑的线,与之前的趋势一致。
2、Transformers 的局限性
LLMs 基于 transformer 架构构建。Transformer 在深度学习中是一个重大突破,解锁了自然语言处理、图像生成甚至分子建模的新能力。它们的力量在于 自注意力机制 —— 让模型动态决定应关注输入的哪些部分的机制。
但 Transformer 也有其假设。其中最重要的是:
- 输入数据是一个离散标记的序列
- 唯一的方法是通过在上下文中包含更多标记来对模型进行条件设定
对于语言来说,这些假设是完美的。文本本质上是分词的——单词、子词、标点符号。通过添加更多上下文进行条件设定(“总结这篇文章…”,“翻译这句话…”)自然地融入到标记流中。
时间序列?就不一样了。
3、为什么 Transformers 在时间序列上挣扎
时间序列数据是连续的。 它由像 93.4、71.2、108.0 这样的值组成——随时间采样的实数序列。要使用 Transformer,我们需要将这些值 离散化 成标记。但离散化是有损的、任意的,并且对于大多数现实世界的信号来说本质上是不自然的。
还有一个问题是:条件设定。
假设我们试图预测一个人随时间变化的心率。我们可能需要根据元数据对模型进行条件设定——比如年龄、性别、病史和实验室结果。但这些元数据有多种格式:二进制(如吸烟者/非吸烟者)、分类(如性别)、连续(如血红蛋白水平),甚至是非结构化的文本(医生的笔记)。Transformer 要求所有这些信息都以相同的标记流形式进行序列化。这在最好的情况下也很别扭,在最坏的情况下则具有破坏性。
简而言之:
Transformers 强迫我们将时间序列扭曲成一种会丢失我们想要保留的信息的格式。
4、我们需要什么替代方案
时间序列问题需要的模型是:
- 原生连续的
- 能够纳入任意元数据——无论类型如何
- 能够在时间上生成和推理密集的多变量信号
这正是我们在 Synthefy 所构建的。
我们的核心技术是一种专为时间序列设计的 扩散模型。如果你见过 DALL·E 或 Midjourney 根据文本提示生成令人惊叹的图像,你就见过扩散模型的运作方式。我们做同样的事情——但针对时间序列。我们的模型可以基于任何元数据生成或预测信号,无论格式或领域如何。
为了实现这一点,我们开发了一个 通用的元数据编码器 —— 一种架构,使我们能够基于文本、表格数据、分类变量和连续信号对时间序列预测进行条件设定。它类似于 CLIP,但适用于现实世界的预测任务。
5、真实世界的结果
我们的模型在各个领域都表现出 最先进的结果:
- 能源需求预测
- 零售销售和库存模拟
- 医疗时间序列(ECG、PPG、心率)
Synthefy 模型(顶部行,红色)生成的样本比 GANs(底部行,红色)等先前方法更接近真实样本(蓝色)。
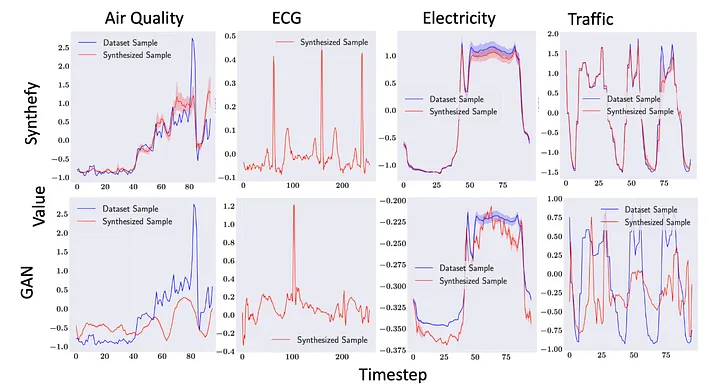
Synthefy 模型(顶部行,红色)生成的样本比 GANs(底部行,红色)等先前方法更接近真实样本(蓝色)。
6、生成式 AI ≠ 只是 LLMs
生成式 AI 不仅仅是聊天机器人和代码补全。它是对结构化数据进行建模和生成的一种新范式——各种类型的结构化数据。它要求架构与数据本身的结构相匹配。
LLMs 在语言方面非常出色。但时间序列是一个独立的领域,有自己的规则。这就是为什么我们不是试图让 Transformer 适应时间序列——而是从零开始构建正确的工具。
如果你正在尝试理解、预测或模拟复杂的时间依赖行为,LLMs 无法带你到达那里。
Synthefy 会。
原文链接:Why LLMs Can’t Solve Time Series
汇智网翻译整理,转载请标明出处
