为什么大多数AI产品都是骗局
最近围绕Anthropic决定严重限制其最重负载用户使用量的争议引发了热议,声称其中一些用户每月给他们造成数千美元的损失。

最近围绕Anthropic决定严重限制其最重负载用户使用量的争议引发了热议,声称其中一些用户每月给他们造成数千美元的损失。
起初,你不能责怪他们;他们每用户每月最多赚200美元,而有些用户每月却给他们造成数千美元的损失。
但现实是,这个系统是大多数AI产品都很棒,但定价方式非常欺诈性。
激励机制是错误的,这意味着AI市场即将经历一次痛苦的转型,进入一种新的商业模式:基于成功。
1、AI公司如何赚钱(亏损)
AI行业分为四个层次:
- 硬件公司,制造训练和运行AI所需的芯片和服务器。
- 基础设施公司,建设托管这些服务器的数据中心,要么将空间租给实验室,要么用于部署自己的AI产品或服务。
- 模型层公司,训练和运行AI模型,并以两种方式提供它们:通过订阅和通过API(仅按使用量付费)。
- 应用层公司,通常被称为“AI包装器”,它们在第三方AI模型之上构建自己的产品或服务。
这些层次并不是互斥的。像Google和中期内的OpenAI这样的公司会在所有层次上运营。
虽然硬件和基础设施公司的商业模式清晰明了,你只需为所使用的部分付费,但在模型和应用层,你一直在被欺骗。但为什么?
1.1 非确定性和标记
这里的问题是,AI软件是如何计费的?
我们将专注于生成式AI,比如ChatGPT,因为这些是终端用户/公司无法自行训练并因此从第三方购买的产品。
在这种情况下,这些模型是根据一个因素来计费的:标记。
但什么是标记?
根据定义,它是任何数据模态中的基本语义信息单位(文本中的单词或子词、图像中的像素或像素块等)。这是AI中的重要组成部分,因为它将用户的数据转换成计算机可以处理的数字,因为计算机无法直接处理文本。让我进一步解释。
当你将句子“尼泊尔的首都是哪里?”发送给AI模型时,模型实际上看到的是一串数字,在GPT-4o的情况下,如下面的图片所示。
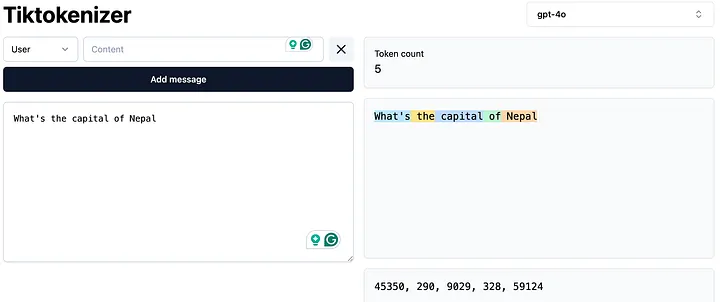
这些数字是我们在称为“嵌入表”的表格中的行索引,其中每一行是一个模型知道的单词或子词(即标记),该表的列是该标记的属性数值。
换句话说,你句子中的每个单词都会被转换成一组我们称之为“嵌入”的数字。这些数字不是随意的,而是可以理解为概念的属性。
最简单的例子是,当模型只了解五件事:“罗宋汤”、“热狗”、“烤肉卷”、“披萨”和“沙拉”。因此,为了给这五个词分配一组数值,我们可以简单地为“烤肉卷”分配一个1作为“烤肉卷”的属性,其余的为零,其他食物也是如此。

然而,这种区分概念的方法是有缺陷的,或者至少是次优的,因为这些元素共享共同的属性。
热狗和烤肉卷都有肉,所以它们彼此更相似,而不是沙拉和热狗(沙拉和烤肉卷都有绿叶,所以它们比沙拉和披萨更接近)。你明白了吗?
这意味着我们可以增加我们“概念空间”的复杂性,以捕捉更细微的关系,比如根据“三明治程度”来分布:
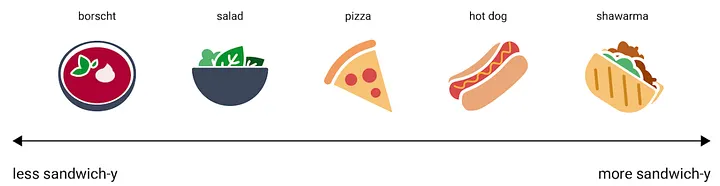
或者根据不断增长的维度,如“三明治度”、“甜点度”或“液体度”

现在,将这个想法扩展到数十万维,你就得到了类似ChatGPT的概念空间。
这个“内部世界”,称为“潜在空间”,由相似性原则支配,相似的概念有相似的嵌入,不相似的概念则被分隔开。
这意味着模型基于它与其他已知概念的相似或不相似程度来建立“某物是什么”的理解,因为模型没有物理身体来像我们一样扎根于概念,这就引发了关于它们是否“理解”事物的问题。
好吧,那么呢?
要理解的关键点是,模型既处理又生成这些标记,产生电费成本。这意味着生成式AI模型有两种计费方式:
- 按照它们处理的标记
- 按照它们生成的标记
通常,后者的价格是前者的三倍,因为标记处理阶段,称为“预填充阶段”,更适合GPU,因为它主要由矩阵到矩阵的乘法组成,而GPU擅长于此,使LLM提供商更接近甚至超过GPU的算术强度阈值(尽管罕见)。 另一方面,标记生成是矩阵到向量乘法密集型的,这意味着总耗电量中有更高比例用于移动数据而不是计算数字(后者是产生收入的,前者不是)由于内存缓存(KV缓存)。但我说得太多了。
一开始,这一切看起来不错;我们有固定价格,对吗? 不完全是。
价格是按标记固定的,是的,但模型处理或生成的标记数量是动态的; 它会因不同的用户请求而完全改变。即使输入相同,输出也会略有不同,这被称为非确定性。
通俗地说,用户和OpenAI都不知道一次互动会花费多少。
这就是我们进入Anthropic争议的地方。
1.2 向投资者求助是错误的选择
尽管非确定性是AI模型的核心(我们甚至还没有考虑准确性,稍后会详细说明),大多数AI公司使用固定价格的订阅提供他们的服务。
这对用户来说很容易理解,他们可以预测服务的成本。这对投资者也非常有吸引力,因为他们无法满足每月和每年的经常性收入(MRR/ARR)指标, 因为它们给了一个原本不可预测的业务——以及投资——一个容易预测年度收入的借口,实际上是在一个完全不可预测的环境中。
由于这些预期收入在新融资轮次的讨论中至关重要(该轮次的估值主要通过与ARR相关的倍数来衡量),AI公司在急需现金时会达到荒谬的水平(甚至非法的) 来增加他们的ARR。
一切看似良好,但问题在于:这根本没道理。
归根结底,你的业务,无论是赚钱还是花钱,都基于处理/生成的标记的不可预测指标, 这就是你支付上游供应商(基础设施公司)的方式。
如果你也是基础设施公司,你仍然根据一小时内消耗的瓦特数支付巨额电费,这在很大程度上是动态的,取决于你服务的标记(和人)数量。
所有这些都是动态的,但定价是固定的。
我想知道会发生什么问题? 很多问题都会发生。
2、运营卓越将成为护城河
在当前的商业模式下,公司被迫实施严格的速率限制(你可以实际使用模型的程度),有时是基于使用情况或任意的标记值。
例如,如果你在Tier 1设置中使用Anthropic的模型(你还没花够钱升级到更好的层级),你不能发送超过30,000个标记的输入序列(约23k个单词)。

这听起来很多,但你会惊讶于标记迅速增长的速度。这是每分钟的限制,所以如果你在同一分钟内发送三个各为10k的请求,你就会被速率限制。
这对用户来说是一个糟糕的体验,他们无法预测,甚至对于单个序列,它是否会触发速率限制,在生产环境中可能是一场灾难(想象一下你的客户支持聊天机器人耗尽标记并忽略了它正在支持的客户)。
或者,你可能会遇到一些似乎完全荒谬的情况,比如Google提供Gemini 2.5 Pro Deep Think,可以说是地球上最聪明的AI系统,但只能提供给Ultra订阅会员(每月300美元)并且每天只能查询5次。
真正糟糕的体验,只能用我们还处于这一业务的早期阶段来解释。但被早期阶段所原谅并不能为你改进一个明显崩溃的系统开脱。
但,猜猜看,还有更糟的!
2.1 失败也要付费!
对于模型提供商和用户来说,一定数量的生成不会有效果,意味着它们对用户没有相关性。
在大多数情况下,让AI对用户有用是统计覆盖的游戏,重复几次尝试直到你得到一个满意的答案。
事实上,像Gemini 2.5 Pro Deep Think或o3-pro这样的模型进行“最佳n选一”采样,它们会多次运行问题,并根据另一个AI模型作为评委来评分,给出最好的结果。
你可以争论说这些“额外的推理”不会被用户收费;但是,它们确实会被收费,因为这些模型的API价格飙升(至少对于o3-pro来说是这样,因为Deep Think只能通过订阅获得)。
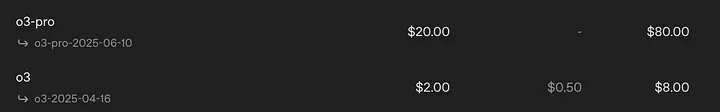
o3-pro,每个查询多次尝试,比“单次查询”选项贵十倍
考虑到所有因素,用户获得的订阅:
- 对于大多数标准用户来说,价格极其昂贵,他们可能只产生3或4美元的成本,却被收取5到7倍的费用。
- 对于处理高负载用户的公司来说,价格极低,他们可以花费比他们支付的多几十倍,迫使Anthropic等公司实施严格的限制。
- 对于用户来说,极为不透明,他们无法“看到”他们所获得的价值(他们不知道他们被收取了多少次无效调用,模型是否陷入绝望推理——思考时间过长),甚至可能被“降级”到更差的模型而不被告知,还有谁知道其他什么。
- 你甚至可能陷入隐藏的成本陷阱,其中某些分词器(模型将数据分解为标记的方式)更加精细(将序列分解成更小的块),这意味着,尽管一些公司可能提供更具竞争力的标记价格,它们的模型会产生更多的标记, 导致更高的总成本。
总之,不透明、隐藏成本和不可预测性是游戏规则。
那么,公司应该怎么做?
2.2 运营卓越是护城河
大多数AI公司都在依靠其商业模式的借贷时间生存。
很快,随着模型层继续商品化,人们将开始更加关注成本,尤其是考虑到开源模型在性能与成本方面击败了大多数排行榜。
在这种情况下,人们对定价将变得如此敏感, 结合产品体验(这是一个另文讨论的话题),定价将成为选择的决定性因素。
这将使行业陷入价格战, 只有提供基于成功的定价(仅对有用的内容收费)的公司将吸引最多的用户(公司和个人消费者)。
在仅对部分推理收费的同时实现盈利是非常具有挑战性的,需要真正的运营卓越。
但如果我们考虑AI将成为一种商品, 这种运营卓越将成为你的护城河,因为你可以在价格上超越其他人(在商品化环境中定义的指标)。
3、一项生活在过去的前沿技术
随着AI越来越多地吞噬软件,不透明的订阅时代,客户愿意接受他们被欺骗的日子将结束。
按使用量计费和特别是按成功计费将成为常态。
对于习惯于这种循环的投资者和习惯于高利润率的软件公司来说,后果是巨大的;所有这些都将消失。
AI不仅会带来通货紧缩,还会成为打击价值数十亿美元的数字软件市场的诈骗行为, 该市场长期以来享有高进入壁垒,导致利润过高和购买体验不佳。
而最受这种新现实影响的将是AI公司本身,他们正在引领变革,但仍坚持旧软件时代的过时且令人震惊的欺诈行为。
不愿主动做出转变的软件公司将会被迫付出代价。
相反,那些理解这一点并在被迫之前做出改变的人将经历一段痛苦的旅程,但他们会从中获得AI工程专业知识,使他们能够降价以超越他人同时保持盈利。
在一个所有人都提供相同东西的时代,更便宜通常代表获胜的形容词。
原文链接:Why Most AI Products are Scams
汇智网翻译整理,转载请标明出处
