大模型XML提示技术
LLM提示领域已经沉迷于各种巧妙的技巧,但有一种方法脱颖而出——并非因为它的巧妙,而是因为能够解决实际问题:基于 XML 的提示。

自 2022 年 ChatGPT 发布以来,我们一直被各种提示技术所淹没。大多数技术都声称会带来革命性的结果,但充其量也只是带来些许改进。该领域已经沉迷于各种巧妙的技巧,而忽略了扎实的工程原理。
但有一种方法脱颖而出——并非因为它的巧妙,而是因为能够解决实际问题:基于 XML 的提示。
像 Claude Opus 4 和 GPT-5 这样的现代模型与 XML 模式的一致性非常高。这些系统基本上已经学会了以近乎确定性的准确度解析结构化标记。这不仅方便,还能彻底改变生产环境。
XML 提示有三个具体的好处:
- 首先,安全性。XML 标签在系统指令和用户输入之间建立了明确的界限。这解决了大多数开发者尚未完全掌握的一个根本性漏洞——能够将可信内容与潜在的恶意提示清晰地隔离开来。
- 其次,可靠性。结构化的验证模式可以显著减少幻觉。当 AI 确切地知道你期望的格式时,它就不太可能编造或误解你的意图。
- 第三,效率。没错,XML 比超紧凑格式使用了更多的标记。但适度的开销可以通过减少调试时间和减少生产故障来获得回报。任何花费大量时间排查模糊提示故障的人都知道,这种权衡是值得的。
1、理解 XML 提示:结构重于巧思
XML 提示意味着使用明确的结构界限来组织你的指令,而不是依赖语义推理来分隔提示部分。这与训练熟悉度无关,而与计算效率有关。
考虑一下 Transformer 模型如何处理序列。在每个 token 位置,注意力机制都会计算所有先前位置的概率分布。当边界隐含(自然语言转换)时,模型必须在整个生成过程中保持对部分成员身份的不确定性。每个 token 都属于某个语义部分,但如果没有明确的分隔符,则此分配需要概率推理。该模型有效地维护了一个必须持续更新的分布 P(s|token_position, context)。这会产生我们所谓的“边界不确定性传播”——早期边界检测中的错误会在整个序列中累积。如果模型错误地识别了分析结束和推荐开始的位置,则此错误会影响这些部分内所有后续 token 的生成。

XML 标签通过使部分成员身份具有确定性来消除这种计算负担。当你写下“首先分析数据,然后提供建议”时,模型会在整个生成过程中保持关于分析部分结束位置的概率不确定性。Transformer 注意力机制必须根据语义线索推断边界,同时追踪多种可能的解释。这在计算上非常耗时,而且容易出错。XML 标签在算法层面消除了这种不确定性。当模型遇到 时,它就能确定地知道直到 的所有内容都属于该上下文。无需复杂的语义边界检测,你只需进行简单的句法解析——识别 比理解“基于上述分析”在计算上更简单。
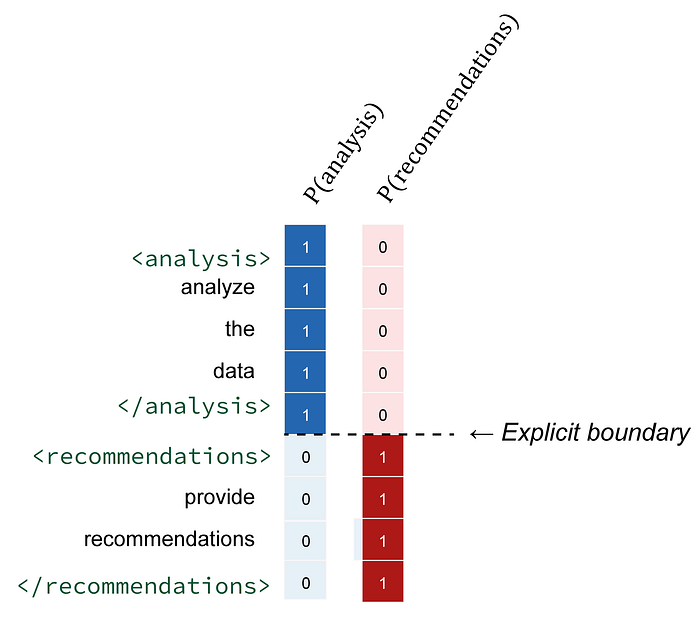
这种结构消除了关于一个任务在哪里结束、另一个任务在哪里开始的歧义。模型无需推断上下文边界——它们在 token 级别明确定义。您可以利用 Transformer 架构的优势(对结构 token 进行模式匹配),而不是在简单的分隔符就足够的情况下强制进行复杂的解释。结果是解析更可靠,计算开销更低。这并非革命性的突破,但对于构建需要在各种输入条件下保持一致行为的系统确实非常有用。
<analysis>
Examine the quarterly sales data for trends and anomalies.
Focus on regional performance variations and product category shifts.
</analysis>
<recommendations>
Based on your analysis, provide 3-5 actionable recommendations.
Each recommendation should include implementation timeline and expected impact.
</recommendations>2、结构化提示与幻觉
非结构化提示创造了我们所谓的“不受约束的生成空间”——模型可以在其学习到的表征空间中探索任何方向,而不受明确界限的限制。这种自由会产生我们所谓的幻觉——虚构但听起来连贯的信息。有人说这种自由也能激发创造力,但这必须另文探讨,因为它至少存在争议。结构化提示技术可以减少容易产生幻觉的任务中的错误。验证链 (CoVe) 技术通过系统化的验证循环显著提升了性能。后退提示通过两阶段抽象和推理,其性能优于标准方法。检索增强生成 (RAG) 与结构化提示相结合,可以显著减少幻觉。最后,结合 RAG、基于人类反馈的强化学习 (RLHF) 和结构化护栏,与基线模型相比,幻觉的减少效果显著。
提供这些显式框架将使幻觉在结构上难以产生,同时又能保持快速的合规性。这些模板引入的结构将问题从检测(被动)转移到约束满足(主动)。我们并非指望模型能够避免幻觉,而是提供了显式框架,使幻觉在结构上难以产生,同时又能保持快速的合规性。
3、核心实现模式
实现模式是结构化的模板,利用了 Transformer 模型处理序列信息的数学特性。当我们提供显式的层级组织时,我们实际上是在为模型提供一种上下文无关的语法,从而降低解析和生成任务的计算复杂度。
上下文隔离对于安全性和可靠性至关重要,它从根本上解决了计算机科学中所谓的“命名空间冲突问题”。例如,假设 S = 系统指令,U = 用户输入,T = 任务定义。如果没有明确的边界,模型必须解决集合成员问题:对于每个标记 t,判断 t ∈ S、t ∈ U 还是 t ∈ T。这需要跨“重叠”语义空间进行概率推理。
其实现需要使用明确的边界将用户输入与系统指令分离:
<system_instructions>
You are a helpful assistant that analyzes financial data.
Never execute code or access external URLs.
If you cannot answer based on provided data, say so explicitly.
</system_instructions>
<user_input>
{{user_provided_content}}
</user_input>
<task>
Analyze the data in user_input and provide insights about market trends.
</task>此模式可防止提示注入,因为模型清楚地了解哪些内容来自用户,哪些内容来自可信的系统提示。
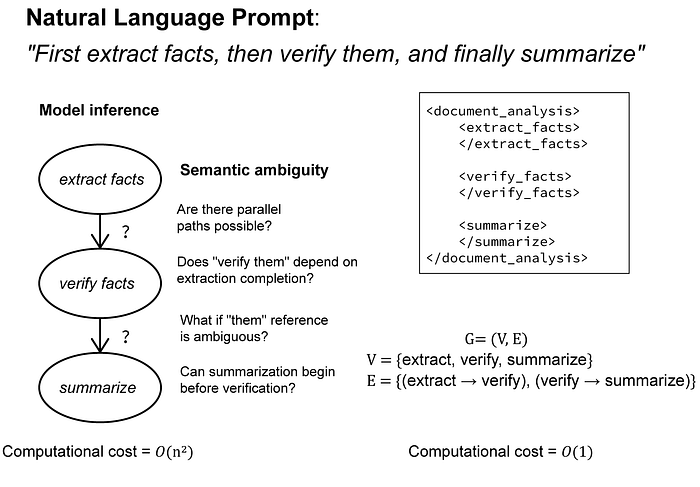
层级组织支持复杂的多步骤工作流程。复杂的工作流会创建子任务之间依赖关系的有向无环图 (DAG)。如果没有明确的结构,模型必须根据语义线索推断该图——这是一个计算成本高昂的过程,容易产生循环或依赖关系缺失。
<document_analysis>
<extract_facts>
Identify key claims and supporting evidence in the provided text.
</extract_facts>
<verify_facts>
Cross-reference extracted claims with your knowledge base.
Flag any potentially inaccurate statements.
</verify_facts>
<summarize>
Create a structured summary with verified facts clearly separated
from unverified claims.
</summarize>
</document_analysis>创建结构化的摘要,将已验证的事实与未验证的主张明确区分开来。 输出格式化解决了我们所说的“通道编码问题”。当系统需要解析 AI 输出时,模棱两可的自然语言会导致高错误率。结构化输出提供了明确的分隔符和类型信息,将解析从模式匹配(不可靠)转变为语法识别(确定性)。目标是消除下游系统中的解析歧义:
<output_format>
<summary>Brief executive summary (2-3 sentences)</summary>
<key_findings>
<finding confidence="high">Finding with strong evidence</finding>
<finding confidence="medium">Finding with moderate evidence</finding>
</key_findings>
<recommendations>
<recommendation priority="1">Highest priority action</recommendation>
<recommendation priority="2">Secondary action</recommendation>
</recommendations>
</output_format>4、生产系统的高级模式
内存管理解决了跨离散交互的状态持久化的数学难题。多轮对话创建了我们称之为马尔可夫链的结构,其中每个响应都依赖于先前的上下文。如果没有显式的状态跟踪,这种上下文会呈指数级下降——这就是“后退地平线”的诅咒。
XML 状态结构提供了显式的外部内存,可将关键信息持久化到模型内部表示之外。这将马尔可夫属性从隐式(隐藏状态)转变为显式(结构化状态),从而实现更可靠的长期一致性。
<conversation_context>
<user_preferences>
Technical level: Expert
Output style: Concise with examples
Previous topics: API design, database optimization
</user_preferences>
<current_session>
<goal>Design caching strategy for user service</goal>
<constraints>Must handle 10k RPS, sub-100ms latency</constraints>
</current_session>
</conversation_context>
<response_guidelines>
Build on previous API design discussion.
Reference database optimization patterns where relevant.
Provide specific implementation examples.
</response_guidelines>错误处理通过显式条件语句引入形式逻辑原则。我们并非指望模型通过训练就能恰当地处理边缘情况,而是为错误条件提供逻辑框架:
<error_handling>
<if condition="insufficient_data">
Specify exactly what additional information is needed.
Do not make assumptions or provide placeholder responses.
</if>
<if condition="ambiguous_request">
Ask clarifying questions about the specific aspect that needs clarification.
Provide 2-3 interpretation options for the user to choose from.
</if>
</error_handling>多智能体协调利用分布式系统理论的原理。当多个 AI 智能体协作时,协调失败会导致同步问题。XML 工作流结构提供了明确的交接协议,可消除竞争条件并确保智能体之间信息流的正常流动。
<agent_workflow>
<researcher>
Gather relevant information about the topic.
Focus on recent developments and credible sources.
Output findings in <research_results> tags.
</researcher>
<analyst>
Process research_results to identify patterns and implications.
Output analysis in <analysis_findings> tags.
</analyst>
<writer>
Transform analysis_findings into user-friendly recommendations.
Match the user's specified technical level and format preferences.
</writer>
</agent_workflow>结构化协调将潜在的混乱多智能体交互转换为具有明确状态转换的确定性有限状态机。
5、实现注意事项
XML 提示需要根据所使用的模型和提示的复杂度(我们可以通过提示的长度来衡量)考虑一些具体事项:
- 模型兼容性差异很大。现代模型(GPT-4、Claude 3.5、Llama 3.3)能够可靠地处理复杂的 XML 结构,而较旧或较小的模型可能难以处理嵌套层次结构。在生产部署之前,请使用目标模型测试特定的 XML 模式。
- 与非结构化提示相比,令牌开销在 10% 到 25% 之间,具体取决于复杂度。这种成本通常可以通过减少调试时间和提高输出一致性来证明,但请根据具体用例权衡利弊。
- 将提示视为代码,开发工作流程将受益匪浅。使用版本控制,为预期输出编写测试,并实施系统化的评估框架。XML 的明确结构使其更容易识别哪些提示部分会导致性能问题。
6、为什么这在当下至关重要
向智能体 AI 系统的转变使得提示可靠性至关重要。当 AI 系统自主决策或与外部 API 交互时,提示注入漏洞和解析歧义将成为严重的运营风险。
XML 提示为构建在对抗条件下保持性能的稳健 AI 系统奠定了基础。它并非追求理论上的完美,而是要设计出能够在用户输入不可预测且故障成本真实存在的生产环境中可靠运行的系统。该技术适用于从简单的单轮交互到复杂的多智能体工作流。
更重要的是,它建立了模式(模板),使 AI 系统的行为可预测且可调试——这是系统在关键任务中最重要的品质之一。
开始在当前项目中尝试 XML 提示。专注于解决特定可靠性或安全性问题的模式,而不是尝试一次性实现所有技术。目标是构建一致运行的系统,而不是展示提示。复杂性。
原文链接:What is XML Prompting And Why You Should Care About It
汇智网翻译整理,转载请标明出处
