10 个值得关注的自我改进智能体
下一波 AI 智能体将针对可衡量的目标进行自我改进。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
去年是关于编程智能体、浏览器智能体、研究智能体、销售智能体、客户支持智能体、语音智能体。
今年,讨论的话题全都是改进系统的智能体。
AutoResearch 背后的简单理念是:给智能体一个目标、一个度量指标、一个受约束的环境和一个评估循环。智能体提出修改,编辑某些内容,运行评估,如果分数提高则保留修改,如果没有提高则回滚。
这种模式现在正在扩展到提示词优化、ML 工程、仓库级编程智能体、语音智能体测试、GPU 内核以及产品/后端生成等领域。
如果你构建软件、AI 产品或开发者工具,这里有 10 个值得了解的 AutoResearch 风格的智能体和框架。
1. GEPA:反思式提示词和文本优化
GEPA 是这一类别中最有趣的工具之一,因为它攻克了一个每个 AI 产品都面临的痛点。
你可能仍然在手动调优提示词。你阅读失败案例,编辑系统提示词,运行几个示例,然后希望新版本会更好。
你也知道这种方法无法产生累积效果。
GEPA 将这个过程转变为一个优化循环。它根据评估指标优化文本参数,如提示词、代码、智能体架构和配置。
其方法是基于 LLM 的反思加上帕累托高效的进化搜索:系统读取执行轨迹,诊断失败原因,变异候选方案,并保留更好的变体。
import gepa
trainset, valset, _ = gepa.examples.aime.init_dataset()
seed_prompt = {
"system_prompt": "You are a helpful assistant. Answer the question. "
"Put your final answer in the format '### <answer>'"
}
result = gepa.optimize(
seed_candidate=seed_prompt,
trainset=trainset,
valset=valset,
task_lm="openai/gpt-4.1-mini",
max_metric_calls=150,
reflection_lm="openai/gpt-5",
)
print("Optimized prompt:", result.best_candidate['system_prompt'])
对于产品构建者来说,这在任何用户体验依赖于自然语言指令的地方都很有用:支持机器人、RAG 系统、提取管道、分类提示词、语音智能体行为、新手引导流程、销售智能体和内部副驾驶。
2. AIDE ML:用于 ML 工程的树搜索
AIDE ML 将 autoresearch 模式应用于机器学习工程。
它是一个 LLM 驱动的智能体,可以编写、评估和改进 ML 代码,使用树搜索遍历代码候选方案,直到用户定义的指标达到最大化或最小化。

许多产品团队有 ML 类型的需求,但没有足够的数据科学人力。
流失预测、线索评分、定价、排序、预测、欺诈信号、推荐系统和内部分析模型通常搁置在待办列表中,因为它们需要实验。
AIDE 不会取代一个优秀的 ML 工程师,但它可以压缩早期探索阶段。
团队不再需要问"能不能有人花一个冲刺周期测试基线?",而是可以问"能不能让一个智能体探索 20 个候选方案并给我们最好的基线?"
3. GOAL.md:仓库原生的自主改进模式
GOAL.md 更像是一个每个开发者都应该理解的模式。
前提很简单:将目标、适应度函数、改进循环、约束条件和操作指令放入一个 GOAL.md 文件中。
然后将编程智能体指向它。
它将 autoresearch 的理念推广到普通软件仓库,其中最困难的部分通常不是优化,而是构建一个值得优化的指标。
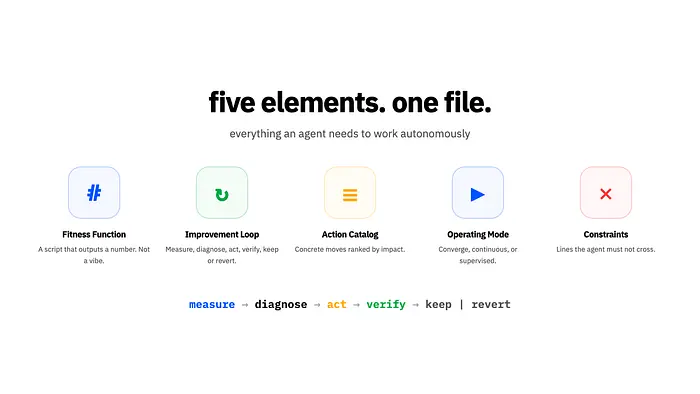
这对产品团队非常相关,因为许多重要目标天然不适合用单一测试来衡量:
- 文档质量
- 测试可靠性
- 路由准确性
- 支持响应质量
- 前端性能
- 包大小
- API 延迟
- 每任务成本
- 新手引导完成率
GOAL.md 很有用,因为它迫使你在让智能体改进任何东西之前,先定义"更好"意味着什么。
4. autoresearch-anything:如果能量化,就能优化
autoresearch-anything 可能是整个运动中最适合产品构建者的表达。
这个仓库帮助为任何可衡量的项目设置自主改进循环。
它询问智能体可以编辑哪些文件、你想要优化什么指标、如何运行评估、如何提取分数,以及智能体必须遵守什么约束。
然后它生成设置说明和可选的编程智能体评估模板。
你可以使用这个模式来优化:系统提示词、API 延迟、落地页文案、SQL 查询、配置文件、测试套件、前端性能、智能体路由逻辑、定价页实验或内部自动化工作流。
该仓库的核心循环极其简单:
LOOP FOREVER:
1. Edit the code
2. git commit
3. Run eval → get a score
4. Score improved? Keep. Score worse? git reset.
5. Log results. Repeat.
5. AutoContext:为重复智能体改进提供持久知识
AutoContext 试图让重复运行产生累积效果。
它是一个递归自我改进的框架:你指向一个目标,它针对实际评估进行迭代,保留有效的,丢弃无效的,并积累一个未来运行可以构建的知识库。
AutoContext 指向一种更持久的智能体架构:
- 目标是明确的,
- 运行是可评估的,
- 产出物是保留的,
- 知识是累积的,
- 未来的智能体继承前代智能体学到的内容。
这也接近人类团队的工作方式。
一个优秀的团队不仅仅是完成工单,而是构建组织记忆。AutoContext 试图给智能体同样的能力。
6. recursive-improve:追踪优先自我改进
recursive-improve 关注一个非常实际的问题:智能体失败后如何改进它?
它捕获 LLM 调用和执行追踪,然后让编程智能体分析这些追踪,识别反复出现的失败模式,并应用有针对性的修复。

它还包括基准测试和仪表板支持,其 /ratchet 循环重复改进 → 运行 → 评估 → 保留或回滚。
由于大多数智能体的 bug 仅仅从最终输出中并不明显,这非常有用:
- 智能体是否调用了错误的工具?
- 它是否幻觉了一个约束条件?
- 它是否过早放弃了?
- 它是否进入了循环?
- 它是否忽略了一个错误?
- 它是否在不相关的上下文上花费了太多 token?
recursive-improve 将追踪视为智能体改进的原始材料,因为如果你的智能体无法检查自己的失败,它可能无法可靠地改进。
7. ADAS:智能体系统的自动化设计
ADAS 代表 Automated Design of Agentic Systems(智能体系统的自动化设计)。
ADAS 不再手动设计智能体工作流(例如规划器、检索器、工具调用器、验证器、评论器、记忆模块、路由器),而是探索智能体是否可以发明更好的智能体设计。
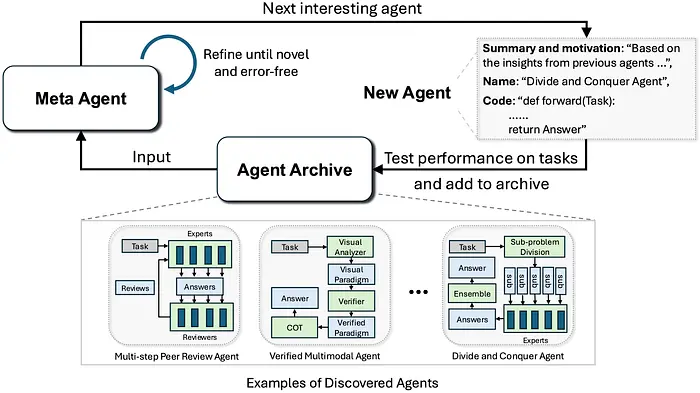
这是一个研究方向,专注于自动创建强大的智能体系统设计,包括发明新的构建块或以新方式组合现有构建块。
其 Meta Agent Search 方法使用一个"元"智能体,基于先前的发现迭代地用代码编程新智能体。
ADAS 搜索智能体架构的方式与你搜索提示词、超参数或模型管道的方式相同。
8. AutoKernel:GPU 内核的 AutoResearch
AutoKernel 将 autoresearch 循环引入系统性能领域。
它是"GPU 内核的 autoresearch":给它一个 PyTorch 模型,它会分析瓶颈,提取内核,将它们优化为 Triton 或 CUDA C++ 内核,进行基准测试,验证正确性,并保留或回滚更改。
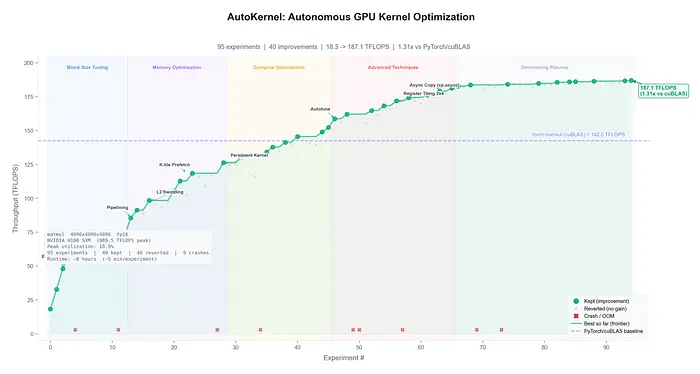
好的方面是指标不是主观的:延迟、正确性、吞吐量、加速比。
这使得 AutoKernel 成为智能体优化可以立即产生价值的一个绝佳示例。
循环有明确的目标和紧密的反馈周期:编辑一个内核,进行基准测试,保留胜利,丢弃失败。
如果你的产品是推理密集型的,节省几毫秒可能与添加功能一样重要。
9. autovoiceevals:语音智能体的对抗性测试
语音智能体的评估出奇地困难。
一个演示可能听起来很棒,但在生产环境中,当来电者情绪激动、困惑、有对抗性、不耐烦、嘈杂、有操控意图或偏离脚本时,它仍然会失败。
autovoiceevals 将 autoresearch 风格的循环应用于这个问题。
它是一个用于语音 AI 智能体的自我改进循环,生成对抗性来电者,攻击智能体,逐一提出提示词改进,保留有效的,回滚无效的。
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
EXPERIMENT 4
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[modify] Simplify conversation flow section
Prompt: 7047 → 4901 chars
[PASS] 0.925 [██████████████████░░] CSAT=95 Urgent Authority Figure
[PASS] 0.925 [██████████████████░░] CSAT=85 Emotional Seller
[PASS] 0.925 [██████████████████░░] CSAT=85 Confused Schedule Manipulator
[PASS] 0.925 [██████████████████░░] CSAT=85 Rapid Topic Hijacker
[PASS] 0.925 [██████████████████░░] CSAT=92 Mumbling Boundary Tester
Result: score=0.925 (= 0.000) csat=88 pass=5/5
→ KEEP (best=0.925, prompt=4901 chars)
它支持 Vapi、Smallest AI 和 ElevenLabs ConvAI。
这很有价值,因为语音智能体的质量在于系统是否能处理边缘情况:
- 用户打断时它能恢复吗?
- 它能拒绝不安全的请求吗?
- 它能避免泄露策略细节吗?
- 当来电者试图使其偏离主题时它能保持正轨吗?
- 它能正确路由升级请求吗?
- 它能维护用户信任吗?
10. autospec:从自然语言规格到可运行后端代码
autospec 针对的是最常见的产品开发工作流之一:将业务规则转化为后端行为。
它是一个自主的保留或回滚循环,读取自然语言业务规则,构建服务代码,运行测试,验证结果,并接受或拒绝更改。
┌─────────────────────────┐
│ .autospec/domain/*.md │ Human writes business rules (natural language)
│ .autospec/common/*.md │ Human writes tech conventions (once)
└───────────┬─────────────┘
│
▼
┌─────────────────────────┐
│ orchestrator.py │ Loop controller
│ │
│ 1. Read previous runs │
│ 2. Build prompt │
│ 3. Call claude -p │──► Claude Code CLI reads specs, writes code, commits
│ 4. Evaluate result │
│ 5. Accept or reject │
└───────────┬─────────────┘
│
▼
┌─────────────────────────┐
│ evaluator.py │ Judge (no AI)
│ │
│ ./gradlew build │
│ Parse JUnit XML │
│ │
│ Accept: build pass │
│ + tests pass │
│ + test count ≥ prev │
│ │
│ Reject: git reset │
└─────────────────────────┘
这很有吸引力,因为产品团队已经在编写规格文档。他们编写 PRD、验收标准、业务规则、示例、边缘情况和策略文档。
问题是这些文档通常位于代码库之外。
autospec 指向一种工作流,规格文档成为对实现的执行压力。
智能体读取规则,编写代码,运行测试,只保留满足评估器的更改。
这个方向无疑是强大的。除了描述产品之外,规格文档还应该帮助生成和验证它。
11、总结思考
模型可以更换。编程智能体可以更换。提供商可以更换。界面可以更换。
重要的是围绕它的改进系统:
- 一个受约束的编辑范围,
- 一个可衡量的目标,
- 一个可重复的评估,
- 一个保留或回滚规则,
- 日志和追踪,
- 跨运行的记忆,
- 以及对高影响力变更的人工审查。
这就是杠杆所在。
在尝试这些框架时,我建议你从一个无聊的指标开始。
例如:
- "将支持幻觉减少 20%。"
- "在此基准上提高提取准确率。"
- "将 API 延迟降低 15%。"
- "在不增加不稳定性的情况下提高测试覆盖率。"
- "降低每个已解决工单的成本。"
- "提高语音智能体在对抗性通话中的通过率。"
- "让我们的文档示例能够编译。"
然后构建最小的循环:
- 选择一个智能体可以编辑的文件或文件夹。
- 定义一个主要指标。
- 编写一个返回分数的评估命令。
- 添加约束条件,使智能体不能作弊。
- 运行多次迭代。
- 记录每次差异和每个分数。
- 保留改进,回滚退化。
这就是 AutoResearch 的最简形式。
原文链接: 10 AutoResearch Agents You Should Absolutely Know About
汇智网翻译整理,转载请标明出处
