GPT-5.4的7个本地LLM平替
前沿API账单是真实的。这7个系列现在能处理你大部分在Codex上花费的任务——而且它们运行在你已有的硬件上

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
现在有两个理由值得你花时间了解这个。
首先,开源模型现在能处理日常工作的很大一部分。对于大量编码、写作、自动化和智能体任务,你不再需要每一步都默认使用GPT-5.4或Codex 5.3。
其次,每次发送到云API的提示都会离开你的机器并经过第三方基础设施。对于专有代码库、敏感原型或受监管行业来说,这是不可接受的。在本地运行推理将所有数据保留在设备上,对于许多团队来说,仅数据主权这一点就足以证明设置成本是值得的。
实际的Claude Code重度用户每月花费在100-200美元。通过Cline或Kilo Code运行Claude Sonnet 4.6,按当前API费率计算,每小时重度使用约花费3-8美元。如果你正在运行智能体集群、大量迭代或委派许多子任务,本地模型是停止在不需要前沿能力的任务上消耗前沿积分的最简单方法之一。
除了排行榜头条,我还将介绍与Claude Code和Codex的本地设置、NVIDIA和Mac设置的硬件层级指南,以及操作中的坑、故障模式和权衡:延迟、内存占用、工具使用、编码可靠性和指令遵循质量。
1、选择系列之前的硬件层级指南
你能运行的模型受你拥有的硬件限制。如果你用的是MacBook Air,评估70B模型是没有意义的。

Q4_K_M量化在大多数模型的MMLU基准测试中保留了与全精度相差1-3分的分数,尽管在多步骤数学推理等专业工作负载上退化可能超过5%。Salesforce Ben 从Q4_K_M开始。如果在目标任务上观察到准确度不足,请升级到Q5_K_M。
1. Qwen3 (阿里巴巴)
- 最适合编码和多语言智能体
- 尺寸: 1.7B, 7B, 14B, 32B, 72B, 235B MoE
- 最佳硬件: RTX 4060 → Mac M4 → 工作站
Qwen3 7B在本次比较中8B以下参数的所有模型中发布最高HumanEval分数(76.0)——比Llama 3.3的72.6高出3.4分。它在所有四个主要系列中多语言支持最强,在CJK语言和英语方面都表现出色。Salesforce Ben
32B密集变体是认真进行智能体编码工作的甜蜜点,在单个24GB GPU上运行良好。Qwen3.5和GLM-4.7-Flash是截至2026年3月最强的35B MoE智能体和编码模型,在24GB RAM/统一内存设备上运行良好,可处理自主复杂任务。AOL
与Claude Code设置:
# 通过llama.cpp下载Qwen3 32B Q4_K_M
./llama-cli \
-m qwen3-32b-instruct-q4_k_m.gguf \
--server \
--host 127.0.0.1 \
--port 8080 \
--ctx-size 32768
# 将Claude Code指向本地服务器
export ANTHROPIC_BASE_URL=http://127.0.0.1:8080
export ANTHROPIC_API_KEY=sk-dummy-local
# Claude Code现在路由到你的本地Qwen3实例
claude
操作注意事项: 西方开发者的主要弱点是工具。Qwen3的工具使用模式遵循与OpenAI标准函数调用略有不同的约定,这会导致某些假定严格遵循OpenAI格式的智能体框架出现静默失败。在运行智能体集群之前显式测试工具使用。
故障模式: 7B变体在24K token以上的长上下文退化。在新架构问题上,多步骤推理可靠性比32B+明显下降。
2. DeepSeek-Coder V3 / DeepSeek V3
- 最适合代码任务
- 尺寸: 7B, 14B, 33B, 236B MoE(V3完整版)
- 最佳硬件: RTX 4070(14B)→ 工作站(完整236B MoE)
DeepSeek V3有235B参数(22B活跃),专门为编码和智能体任务调整。MoE架构意味着推理期间的活跃参数数量远低于总数——你获得235B级别的知识,但只需要22B级别的计算要求。
14B密集变体可以舒适地适配单个16GB GPU,在HumanEval和SWE-bench子集上优于许多上一代34B模型。对于工作负载主要是代码的团队——生成、审查、重构、测试编写——这个系列比列表中的任何其他系列都更稳定地表现出超出其重量级的性能。
使用Ollama设置:
# 拉取DeepSeek-Coder V3 14B
ollama pull deepseek-coder-v3:14b
# 作为OpenAI兼容端点提供服务
ollama serve
# 端点:http://localhost:11434/v1
# 连接Claude Code
export ANTHROPIC_BASE_URL=http://localhost:11434/v1
export ANTHROPIC_API_KEY=ollama
claude
操作注意事项: 在非代码任务上的指令遵循明显弱于代码任务。如果你路由混合工作负载——编码和写作和工具使用——DeepSeek-Coder V3会很好地处理编码,但在其他方面令人失望。将其用作专用代码工作者,而不是通用智能体。
故障模式: 7B和14B变体的Markdown格式有时不一致。在将任何内容提交到文件系统之前,规划对智能体输出的审查。
3. Llama 3.3(Meta)
- 最佳生态系统和最多工具支持
- 尺寸: 8B, 70B
- 最佳硬件: RTX 4060 8GB(8B Q4)→ Mac M3/M4 36GB+(70B Q4)
Llama 3.3是最大的开放权重生态系统,拥有广泛的社区微调和广泛的工具支持。对于大多数开发者来说,Llama 3.3 8B是最佳的整体起点。
Llama在生态系统而非原始基准性能上领先的原因是Meta的模型发布节奏和OpenAI兼容API格式使其成为每个微调工作、每个优化库、每个添加本地模型支持的智能体框架的默认目标。当新工具添加本地LLM支持时,Llama是第一个测试的模型系列。
这意味着更少的集成意外。更少的静默格式故障。涉及工具使用时更少的模式不匹配。
使用Docker Model Runner设置:
# 通过Docker Model Runner拉取并运行Llama 3.3 8B
docker model pull ai/llama3.3:8B-Q4_K_M
docker model run ai/llama3.3:8B-Q4_K_M
# OpenAI兼容端点
# http://localhost:12434/engines/llama.cpp/v1
# Claude Code集成
export ANTHROPIC_BASE_URL=http://localhost:12434/engines/llama.cpp/v1
export ANTHROPIC_API_KEY=sk-dummy-local
claude
操作注意事项: Llama 3.3 70B是值得为认真工作运行的变体,但Q4需要40GB+ VRAM/统一内存——这意味着Mac M3 Max(48GB)或M4 Max(128GB),或Linux上的多GPU设置。8B变体确实适合日常任务且几乎可以在任何地方运行,但8B和70B在多步骤推理任务上的差距比参数数量差异暗示的要大。
故障模式: 8B变体的上下文窗口处理在16K token以上退化。保持上下文严格范围或在智能体框架中使用滑动窗口策略。
4. Phi-4(微软)
- 最适合资源受限环境
- 尺寸: Phi-4-mini(3.8B), Phi-4(14B), Phi-4-reasoning(14B)
- 最佳硬件: 任何4GB RAM硬件(mini)→ RTX 4060(14B)
Phi-4-mini(3.8B)是低资源硬件上唯一真正的选择。Phi-4-mini是与Phi-4 14B不同的模型,有自己的基准配置文件。设计用于相对于参数数量的高性能,针对资源受限设备。
Phi-4-reasoning和Phi-4-reasoning-plus在数学和科学推理的博士级问题的大多数基准测试中优于OpenAI o1-mini和DeepSeek-Distill-Llama-70B。这不是对通用能力的声明——这是对结构化推理任务的特定而真实的优势。
对于CI/CD流水线、边缘部署、IoT设备或任何需要在硬内存上限下进行LLM推理的场景,列表中没有其他系列能与Phi-4-mini的性能占用比竞争。
CI/CD集成设置:
# CI流水线中的Phi-4-mini in llama.cpp
./llama-server \
-m phi-4-mini-instruct-q4_k_m.gguf \
--port 8080 \
--ctx-size 8192 \
--n-gpu-layers 0 # CI运行器上仅CPU
# 在GitHub Actions中使用
- name: AI Code Review
run: |
curl http://localhost:8080/completion \
-d '{"prompt": "Review this diff for security issues: '"$(git diff HEAD~1)"'",
"max_tokens": 512}'
操作注意事项: 在复杂多步骤推理任务上出现限制,3.8B变体的准确度比7/8B竞争者明显下降。较小的模型对量化损失更敏感——如果在目标任务上观察到准确度不足,请评估Q5_K_M。
故障模式: 在长、多部分系统提示上的指令遵循在mini变体上不一致。保持系统提示在200 token以下,任务指令尽可能单一目标。
5. Mistral Small 3 / Mixtral 8x7B(Mistral AI)
- 最适合吞吐量
- 尺寸: Mistral Small 3(7B密集), Mixtral 8x7B MoE
- 最佳硬件: RTX 4060 8GB(Small 3)→ RTX 4090 24GB(Mixtral 8x7B)
当吞吐量最重要时,Mistral Small 3 7B胜出。以推理速度和强指令遵循能力著称。
如果你的瓶颈是每秒token数而非推理深度——大批量摘要、同时处理许多文档的并行智能体工作者、实时响应生成——Mistral Small 3在相同硬件上提供每GPU美元更多的吞吐量。在RTX 4060上,Mistral Small 3 Q4以50-80 token/秒运行,而Llama 3.3 8B在同一硬件上为40-60 token/秒。
操作注意事项: Mixtral 8x7B需要加载完整的MoE权重矩阵,即使推理期间只有一小部分处于活跃状态,也需要24-48GB系统内存。在24GB VRAM和64GB系统RAM的机器上,卸载有效——但会在卸载层引入延迟。在提交之前,请针对你的实际硬件进行基准测试。
故障模式: Mistral模型使用与Llama略有不同的聊天模板格式。大多数框架透明处理,但手动构建提示的手动API集成如果使用错误的模板,会看到指令遵循能力下降。检查tokenizer_config.json并显式匹配聊天模板。
6. GLM-4.7(Z.AI / 智谱AI)
- 最适合多模态和长上下文智能体工作
- 尺寸: GLM-4.7-Flash(9B), GLM-4.7(35B MoE)
- 最佳硬件: RTX 4070 16GB(Flash)→ RTX 4090 / Mac M4 Max(35B MoE)
GLM-4.7-Flash是截至2026年3月最强的35B MoE智能体和编码模型,适用于需要多模态输入的智能体工作流。
GLM-4.7是此列表中西方开发者最不熟悉的系列,这正是它获得一席之地的原因。该模型原生处理交错的图像和文本输入,这意味着处理截图、图表或UI模型与代码一起的智能体工作流可以在本地路由这些任务,而无需单独的视觉模型。
Z.AI的GLM-5和GLM-4.7仍然相关,但一旦你在真实智能体循环而非孤立代码提示中测试它们,其优势就不那么明显了。Flash变体(9B活跃参数)是实际入口点。完整的35B MoE才是多模态能力真正与众不同的地方。
操作注意事项: GLM-4.7中的信任评分与西方模型校准不同——它更可能拒绝涉及安全相关代码的请求,即使意图是合法的。为渗透测试、漏洞扫描或安全审查任务在系统提示中添加明确上下文。
故障模式: 工具使用模式在框架之间的兼容性各不相同。在部署之前使用你的智能体框架显式测试。Flash变体的函数调用在相同参数规模下不如DeepSeek-Coder V3可靠。
7. Qwen3.5(阿里巴巴)
- 2026年最适合严肃智能体工作负载
- 尺寸: 7B, 14B, 32B, 72B, 235B MoE
- 最佳硬件: RTX 4070(14B)→ Mac M4 Max(72B)→ 工作站(235B MoE)
Qwen3.5是截至2026年3月最强的智能体和编码模型,适用于需要在24GB设备上同时具备编码可靠性和长上下文处理的工作负载。
中等规模的Qwen3.5蒸馏9B模型在日常开发任务中在紧凑性和功率之间达到了最佳平衡。32B密集变体是严肃智能体工作所在——多文件重构、复杂调试会话、需要保持大型代码库完整上下文的架构级推理。
完整本地智能体设置:
# 构建支持CUDA的llama.cpp
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF \
-DGGML_CUDA=ON
cmake --build llama.cpp/build --config Release -j \
--target llama-server
# 提供Qwen3.5 32B MoE服务
./llama.cpp/build/bin/llama-server \
-m qwen3.5-32b-instruct-q4_k_m.gguf \
--host 127.0.0.1 \
--port 8080 \
--ctx-size 65536 \
-ngl 40 # GPU上的层
# Claude Code → 本地Qwen3.5
export ANTHROPIC_BASE_URL=http://127.0.0.1:8080
export ANTHROPIC_API_KEY=sk-local-dummy
# 添加到~/.claude.json以持久化:
# "primaryApiKey": "sk-local-dummy"
claude
操作注意事项: 长上下文处理是Qwen3.5的差异化因素;检查Hugging Face上的模型卡以获取你特定量化变体的确切支持上下文窗口长度。Q4_K_M相比全精度截断了一些上下文窗口配置。
故障模式: 235B MoE需要多节点设置或NVLink连接的双GPU装置才能获得实用的推理速度。在单GPU上,即使是4090,完整MoE对于交互式使用来说太慢——在消费硬件上它是批处理模型。
8、路由指南
你不再需要为每一步都默认使用前沿云模型。对于大量编码、写作、自动化和智能体任务,本地模型现在可以可靠地处理这些工作。
以下是如何思考路由:
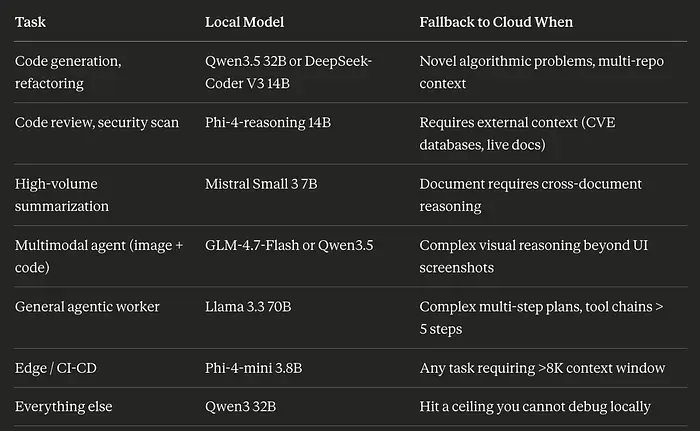
最有生产力的开发者使用组合方式。终端智能体用于自动化,IDE智能体用于日常工作,本地模型用于不需要前沿能力的任务。
目标不是消除云API使用。而是使云API使用有意识——保留给前沿能力是真正瓶颈的任务,而不是所有事情的默认。
从通过llama.cpp在Claude Code中使用Qwen3 32B开始。运行一周。确定它无法处理什么。将这些任务路由到云端。这是实际的迁移路径。
原文链接: 7 Local LLM Families to Replace GPT-5.4/Codex for Everyday Tasks
汇智网翻译整理,转载请标明出处
