现代AI模型的8个类型
了解不同的人工智能模型如何协同工作——从 GPT 到大型概念模型。

AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
大多数人认为所有人工智能模型都是相同的——只是 ChatGPT 的不同版本具有不同的名称。
但在现实世界的人工智能代理系统中,这与事实相差甚远。现代人工智能代理并不依赖于单一模型来完成所有工作。相反,他们编排了多个专门的模型,每个模型都针对特定任务进行了优化。
本指南解释了为现代人工智能系统提供动力的八种不同类型的人工智能模型、每种模型的工作原理,以及为什么人工智能的未来在于智能模型组合,而不仅仅是更大的模型。
0、范式转变:单模型 → 多模型
在深入研究每种模型类型之前,请了解目前正在发生的范式转变:
旧方式(2022-2024):
- 一个大型模型试图做所有事情
- ChatGPT 回答您的问题,编写您的代码,并分析您的数据
- 简单但效率低且昂贵
新方式(2025-2026):
- 专门的模型处理特定的任务
- 路由系统决定使用哪个模型
- 快速、高效、能力更强
把它想象成一家医院。你不会有一位“超级医生”来进行脑部手术、接生婴儿和治疗骨折。你们有专家。人工智能系统也在以同样的方式发展。
1、GPT — 通用模型
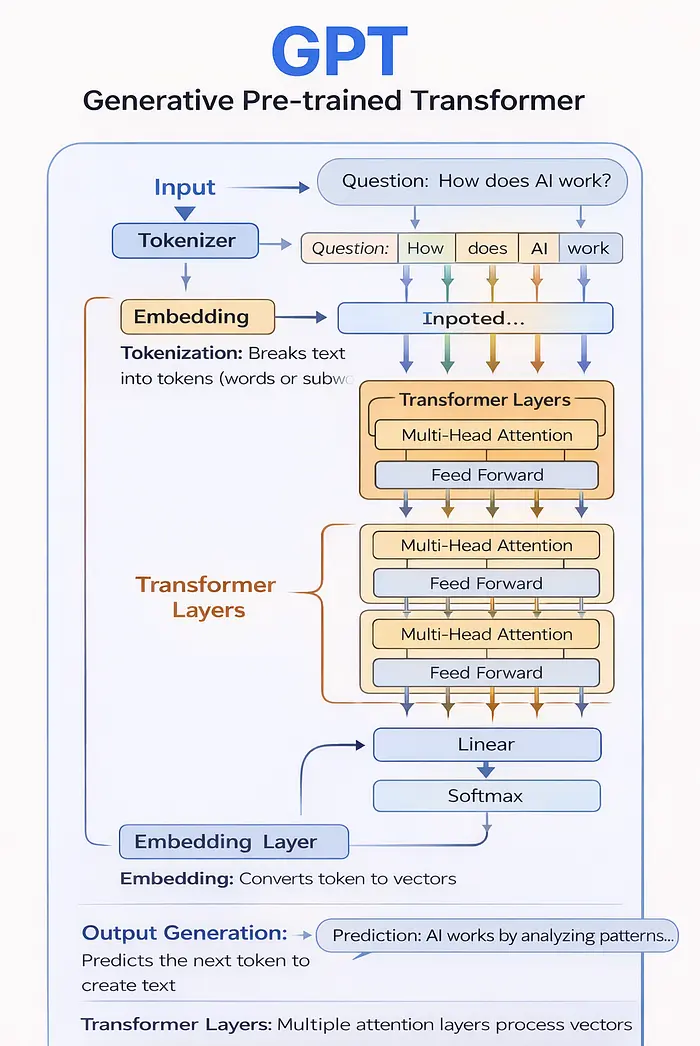
它是什么:
GPT 模型是通用语言模型,经过大量文本训练来理解和生成类人语言。
架构细分:
- 标记化 - 文本被分解为标记(单词或子词)
- 嵌入 - 标记被转换为数学向量
- 转换器层 - 多个注意力层处理向量
- 输出生成 - 模型预测下一个标记,逐字构建文本
它最擅长什么:
✅ 自然的对话和对话 ✅ 撰写电子邮件、文章和创意内容 ✅ 总结文档 ✅ 回答一般知识问题 ✅ 代码生成和调试
它的挣扎之处:
❌ 复杂的多步骤推理(通常“思考”得太快) ❌ 在现实世界中执行动作 ❌ 理解图像或视频 ❌ 需要极高效率的任务
现实世界的例子:
当您要求 ChatGPT“撰写营销电子邮件”时,您正在使用 GPT 模型。它擅长生成创意文本,但不验证事实或发送电子邮件 - 它只是生成内容。
主要型号:
- OpenAI GPT-4、GPT-4o
- Anthropic Claude 3.5 Sonnet
- Google Gemini 1.5 Pro
- Meta Llama 3
2、MoE — 专家网络
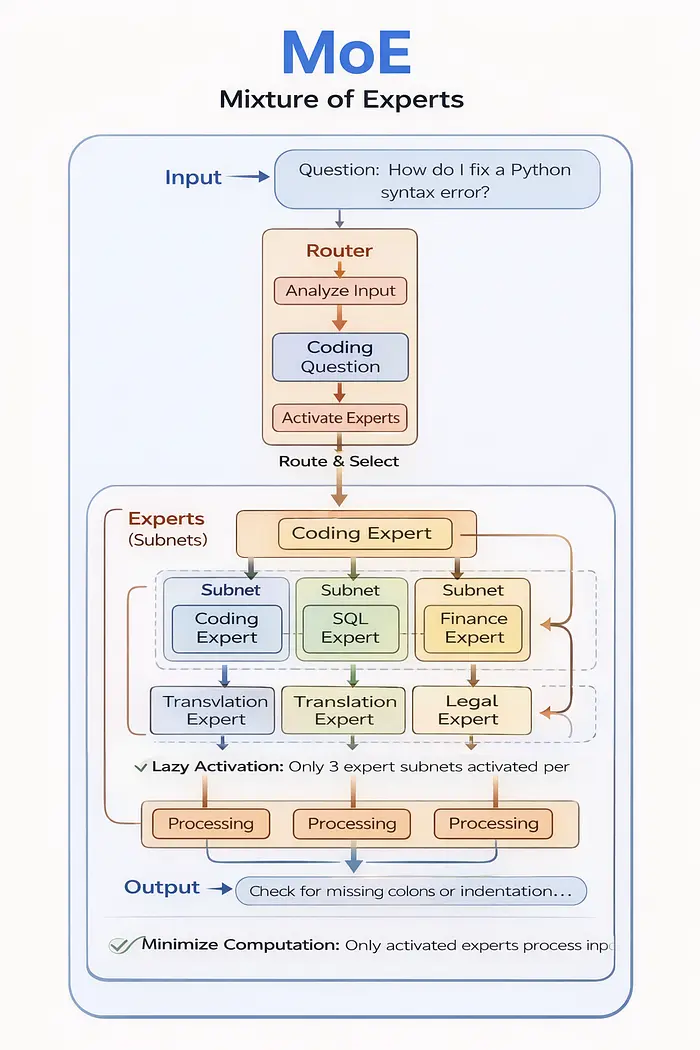
它是什么:
MoE 架构将大型模型划分为多个较小的专门“专家”网络。路由器机制决定为每个输入激活哪些专家。
它是如何工作的:
根据Hureka Technologies的技术分析,MoE架构通过以下步骤工作:
- 输入到达 — “如何修复 Python 语法错误?”
- 路由器分析 — 确定这是一个编码问题
- 专家选择 — 仅激活“编码专家”子网
- 处理 — 仅激活整个模型的 10–20%
- 输出 — 快速、专业的响应
效率突破:
MoE 可能只激活 200 亿个参数,而不是为每个查询运行 1750 亿个参数模型,使其效率提高 8-10 倍,同时保持质量。
它最擅长什么:
✅ 高效处理不同的查询类型 ✅ 经济实惠地扩展到大规模模型 ✅ 特定领域的专业知识(金融、医学、法律) ✅ 高吞吐量生产系统
使用地点:
- Mixtral 8x7B(开源 MoE 模型)
- Google 的 Gemini 模型在内部使用 MoE
- 处理各种客户查询的企业聊天机器人
现实世界的例子:
使用 MoE 的客户服务 AI 可能有单独的专家负责:
- 计费问题
- 技术支持
- 退货和退款
- 账户管理
当出现计费问题时,只有计费专家才会激活,从而使响应更快、更准确。
3、LRM — 专注思考
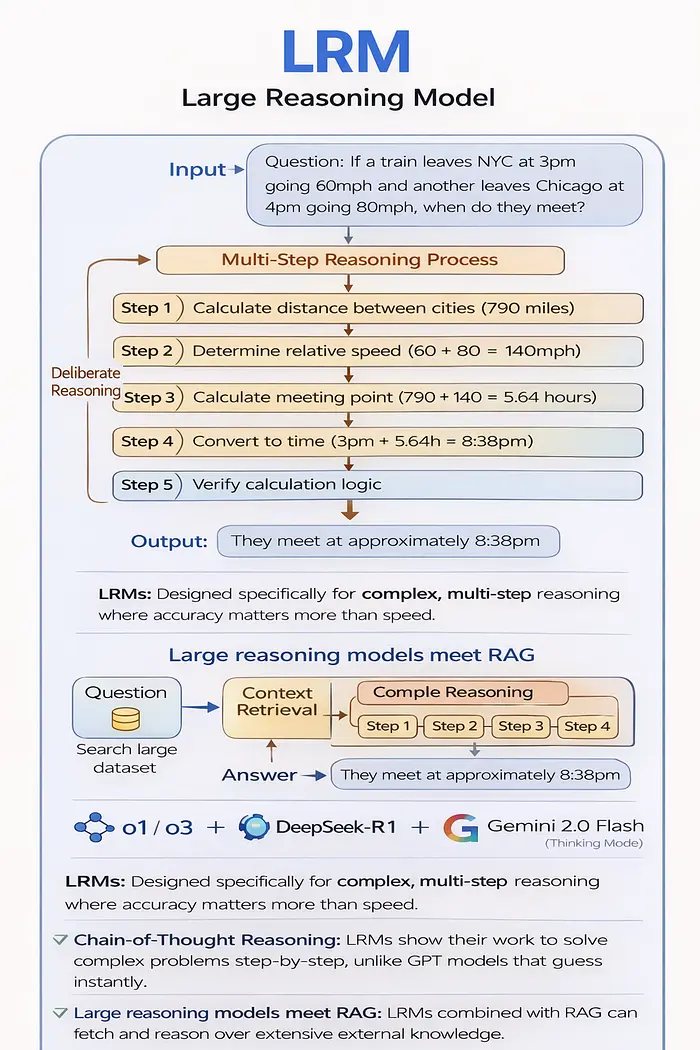
它是什么:
LRM 专为复杂的多步骤推理而设计。与立即生成响应的 GPT 模型不同,LRM 使用“系统 2 思维”——缓慢、深思熟虑的逻辑处理。
思想链方法:
根据 Hureka Technologies 记录的研究,LRM 采用思想链 (CoT) 推理:
用户:“如果一列火车于下午 3 点以 60 英里/小时的速度离开纽约,而另一列火车则以 60 英里/小时的速度出发
芝加哥下午 4 点以每小时 80 英里的速度行驶,他们什么时候见面?”
LRM流程:
步骤 1:计算城市之间的距离(790 英里)
步骤 2:确定相对速度 (60 + 80 = 140mph)
步骤 3:计算集合点(790 ÷ 140 = 5.64 小时)
步骤 4:转换为时间 (3pm + 5.64h = 8:38pm)
第五步:验证计算逻辑
输出:“他们约在晚上 8:38 见面”
它最擅长什么:
✅ 数学问题解决 ✅ 逻辑推理和形式证明 ✅ 代码验证和调试 ✅ 多步骤规划和策略 ✅ 事实检查和验证
GPT 失败的地方,LRM 成功:
GPT 可能会很快猜测“晚上 8:30 左右”——接近但不准确。 LRM 显示其工作、捕获错误并自我纠正。
主要型号:
- OpenAI o1 和 o3
- DeepSeek-R1
- Google Gemini 2.0 Flash 思维模式
现实世界的例子:
使用 LRM 分析患者症状的医疗 AI 代理将:
- 列出所有症状
- 考虑可能的诊断
- 根据测试结果排除不可能的情况
- 按概率对剩余的可能性进行排名
- 推荐特定的附加测试
这个深思熟虑的过程减少了诊断错误。
4、VLM — 视觉解读
它是什么:
VLM 结合了计算机视觉和自然语言处理,使人工智能能够同时理解图像和文本。
建筑学:
根据 Indapoint 的技术细分:
- 视觉编码器 - 处理图像(使用 ViT 或 CLIP 等模型)
- 文本编码器 - 处理语言输入
- 投影接口 - 在共享空间中对齐视觉和文本数据
- 多模态处理器 - 结合两种模态
- 语言模型 - 基于视觉上下文生成文本输出
它最擅长什么:
✅ 图像说明和描述 ✅ 视觉问答(“这张图片里有什么?”) ✅ 文档理解(收据、表格、图表) ✅ UI/UX 理解(阅读屏幕截图) ✅ 医学图像分析
现实世界的例子:
上传一张餐厅菜单的照片并询问“有哪些素食选择?”一个VLM:
- 阅读菜单图像上的文字
- 了解视觉布局
- 识别素食项目
- 生成结构化答案
主要型号:
- OpenAI GPT-4 Vision (GPT-4V)
- Google Gemini(默认多模式)
- Anthropic Claude 3.5 Sonnet(支持视觉)
- Meta Flame 3.2 Vision
它的挣扎之处:
视频理解(大多数 VLM 都是逐帧工作,无法理解随时间变化的运动——尽管这方面正在迅速改进)。
5、SLM — 高效的边缘AI
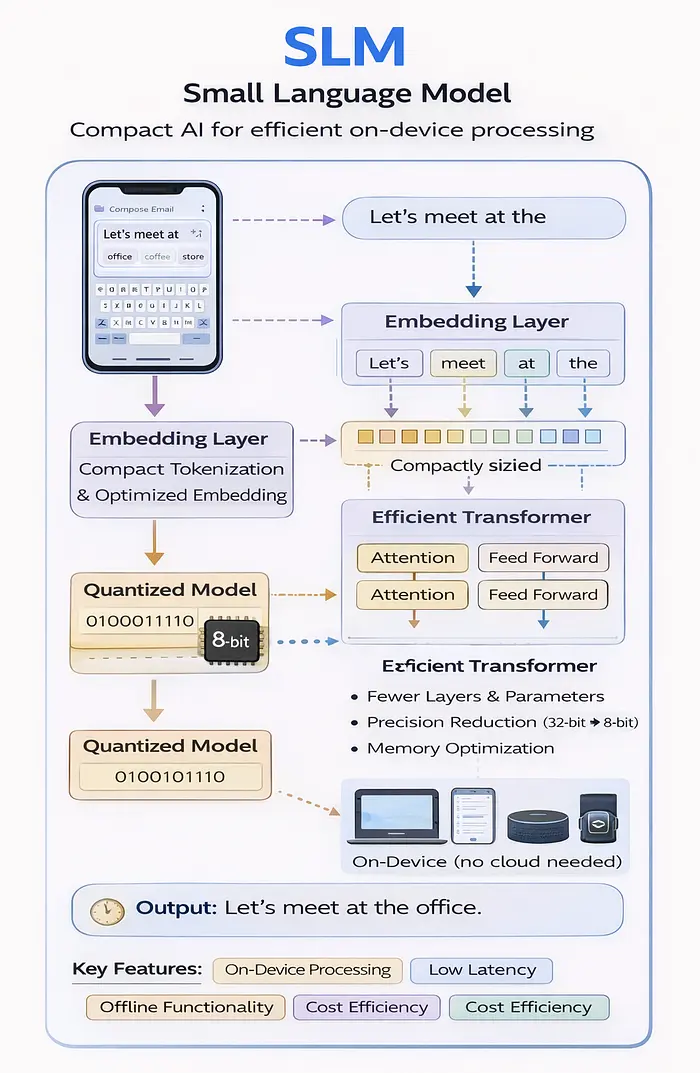
它是什么:
SLM 是一种紧凑的语言模型,经过优化,可以在资源有限的设备(智能手机、平板电脑、物联网设备)上运行,无需云连接。
它们是如何构建的:
根据SkillWisor对SLM架构的分析:
- 紧凑标记化 - 输入的有效表示
- 优化嵌入 - 更小的向量维度
- 高效转换器 - 更少的层和参数
- 模型量化 - 降低精度(32 位 → 8 位或 4 位)
- 内存优化 - 压缩技术
尺寸差异:
- GPT-4: ~1.7 万亿个参数,需要云服务器
- SLM: 1-70 亿个参数,在您的手机上运行
它最擅长什么:
✅ 设备上隐私(没有数据发送到云端) ✅ 低延迟响应(无网络往返) ✅ 离线功能 ✅ 路由、分类、汇总等简单任务 ✅ 成本效率(无 API 费用)
现实世界的例子:
您的智能手机的键盘自动完成功能使用 SLM。它在本地运行,立即响应,并且无需互联网即可工作。
在人工智能代理系统中,SLM 通常用作路由器 — 决定哪个更大的模型应该处理复杂的查询。
主要型号:
- Google Gemini Nano(设备上)
- Microsoft Phi-3 Mini
- Apple Intelligence 型号
- Meta Llama 3.2(1B 和 3B 变体)
6、LAM — 动作模型
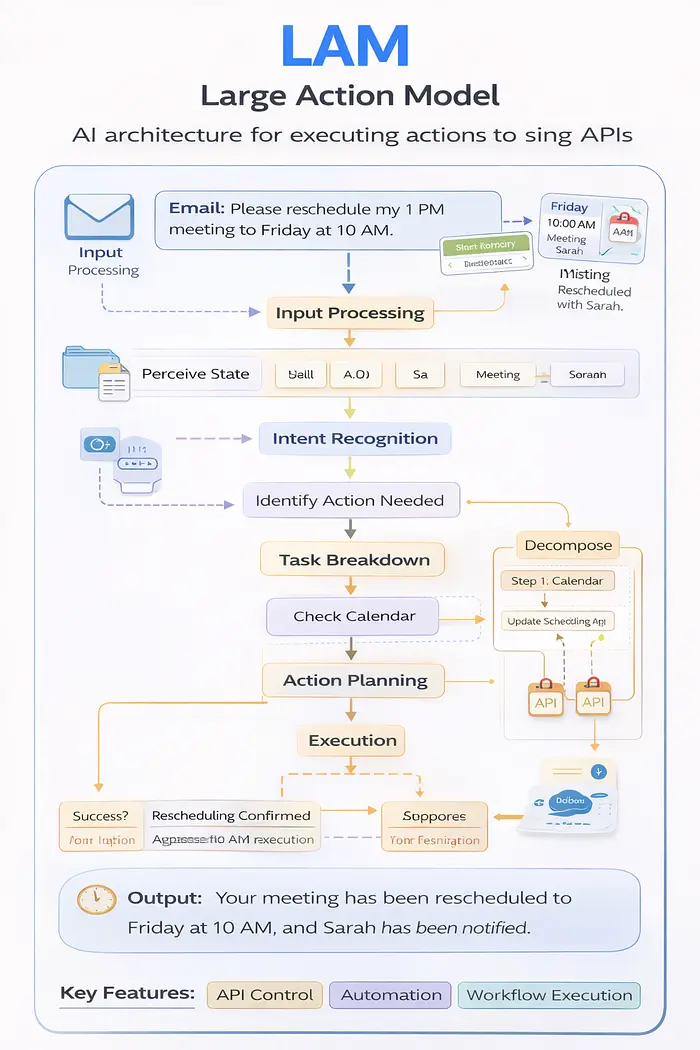
它是什么:
LAM 超越了理解语言的范围——它们可以在软件系统中执行操作、控制 API 并与工具交互。
架构组件:
根据 Indapoint 对 LAM 架构的研究:
- 输入处理 — 了解用户的意图
- 感知 — 读取系统/工具的当前状态
- 意图识别 — 确定需要执行什么操作
- 任务分解 — 将复杂的操作拆分为步骤
- 操作规划 — 决定API调用的顺序
- 执行 — 实际执行操作
- 反馈集成 — 验证成功并调整
它最擅长什么:
✅ API 编排(调用多个服务) ✅ 软件自动化(控制应用程序) ✅ 数据库查询和更新 ✅ 工作流程执行 ✅ 工具使用和集成
关键区别:
- GPT: “这是更新数据库的 Python 代码”
- LAM: “我已经为您更新了数据库”(实际执行 SQL)
现实世界的例子:
客户服务 LAM 代理可能:
- 阅读客户投诉电子邮件
- 查询订单数据库以获取订单详细信息
- 检查库存系统是否有替换品
- 通过支付 API 发起退款
- 向客户发送确认电子邮件
- 更新 CRM 并提供解决方案
所有这一切都是自发发生的,而不仅仅是建议。
新兴模型:
- OpenAI 的 Operator(2026 年宣布)
- Anthropic 的计算机使用(Claude 3.5)
- Rabbit R1 LAM
- Adept 的 ACT-1
安全问题:
LAM 需要严格的护栏。根据 E Lectures AI 的安全指南,生产 LAM 需要:
- 关键操作的批准门
- 用于测试的试运行模式
- 所有执行操作的审核日志
- 范围限制和允许列表
- 回滚功能
7、HLM — 规划大师
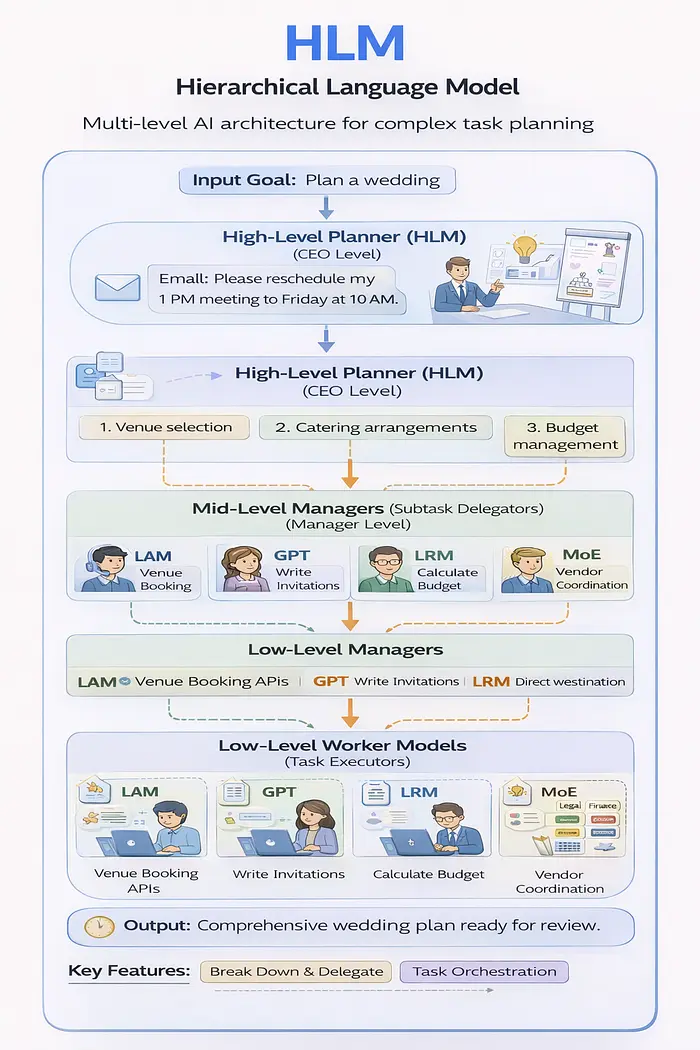
它是什么:
HLM 使用多级架构,其中高级模型规划复杂任务并将子任务委托给专门的低级模型。
它是如何工作的:
把它想象成一个公司结构:
- CEO 级别(高级 HLM):“我们需要推出一款产品”
- 经理级别(中级 HLM):细分为营销、工程、销售
- 工人级别(低级别模型):执行特定任务
架构模式:
用户目标:“策划婚礼”
↓
高级规划师 (HLM):
├─ 子任务1:场地选择
├─ 子任务2:餐饮安排
├─ 子任务3:嘉宾邀请
└─ 子任务4:预算管理
↓
委托给专业模型:
- LAM 处理场地预订 API
- GPT 写入邀请文本
- LRM计算预算优化
它最擅长什么:
✅ 复杂、多天的项目 ✅ 任务分解和委派 ✅ 并行工作流程执行 ✅ 项目管理和协调 ✅ 长期规划
当您需要 HLM 时:
根据E Lectures AI的实践指导:
- 不要将 HLM 用于短期、简单的任务(过度)
- 当任务跨越多个步骤、几天或需要跨域协调时,请使用 HLM
现实世界的例子:
由 HLM 支持的研究助理可能:
- 计划关于人工智能安全的文献综述
- 委托搜索代理寻找论文
- 协调 50多篇论文的总结
- 将结果综合成连贯的报告
- 管理时间线并确保没有遗漏
基础设施:
AWS Step Functions 通常用于实施 HLM 工作流程 - 管理状态机、重试和长时间运行的代理协调。
8、LCM — 抽象思维
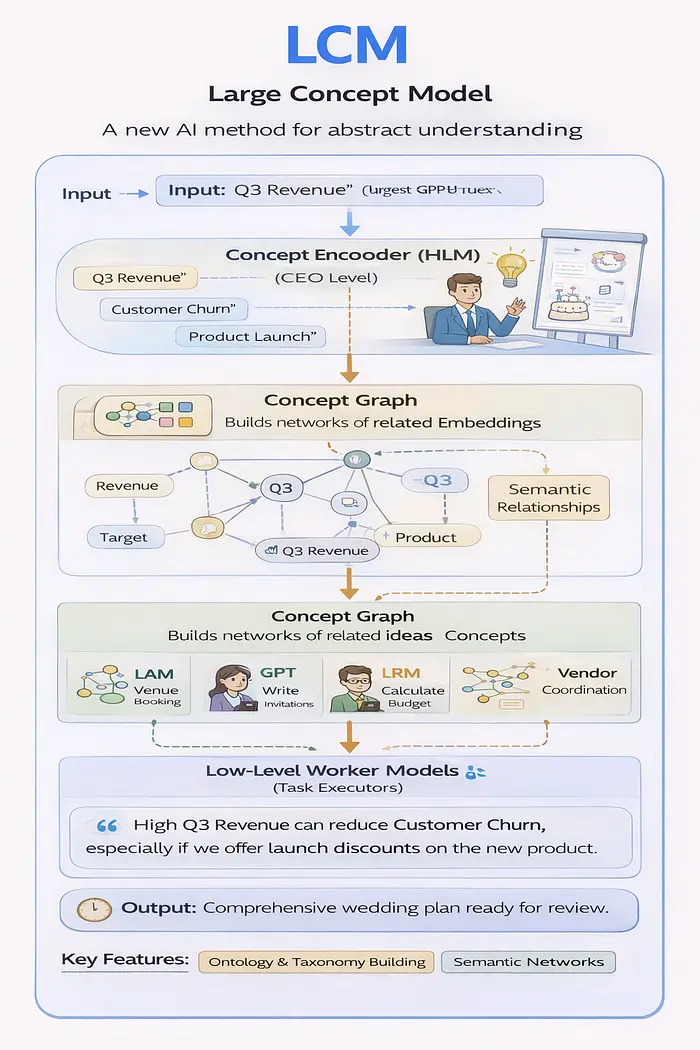
它是什么:
LCM 代表了人工智能的一个新领域——专注于概念理解而不是单词预测。他们构建了建模思想之间关系的语义网络。
根本区别:
- GPT: 根据统计模式预测下一个单词
- LCM: 理解抽象概念及其关系
建筑学:
根据SkillWisor的技术分析:
- 概念编码器 - 将文本转换为抽象概念嵌入
- 概念图 - 构建相关想法的网络
- 概念推理 - 导航概念之间的关系
- 概念解码器 - 将概念转换回文本或视觉效果
它最擅长什么:
✅ 本体论和分类法构建 ✅ 跨领域的概念推理 ✅ 长期记忆和世界理解 ✅ 保持一致的定义 ✅ 从非结构化数据中提取潜在结构
现实世界的例子:
维护“企业记忆”的企业 LCM 可能会理解:
“第三季度收入”在销售与工程中的含义不同“客户流失”在不同部门有具体计算*“产品发布”涉及团队之间的不同里程碑
LCM 在整个组织中保持一致的概念定义。
研究阶段:
LCM 仍在不断涌现。受 ConceptNet 启发的模型和研究级概念人工智能正在开发中,但广泛的商业部署在 2026 年受到限制。
它们重要的地方:
根据 Indapoint 的未来展望:
- 研究机构(医学文献理解)
- 推荐系统(了解深层偏好)
- 复杂决策支持系统
- 知识图谱构建
9、真正的迁移:从单一模型到智能编排
现在您已经了解了每种模型类型,下面介绍它们如何在现代人工智能代理系统中协同工作。
示例:客户支持AI代理。
传入查询:“我上周订购了鞋子,但尺码错误。您能帮我退货并找到合适的尺码吗?”
模型编排:
步骤 1:路由 (SLM)
- 轻量级 SLM 分析查询
- 分类为“产品退货 + 重新订购”
- 路由到适当的工作流程
第 2 步:了解(GPT + VLM)
- GPT 处理文本投诉
- 如果客户上传照片,VLM 会读取产品标签
- 摘录:订单 ID、收到的尺寸错误、需要正确的尺寸
步骤 3:推理 (LRM)
- 检查退货政策资格
- 验证库存尺寸是否正确
- 计算退款时间表
- 确定最佳解决路径
步骤 4:行动执行 (LAM)
- 查询订单数据库(查找订单详细信息)
- 启动退货标签生成
- 创建正确尺寸的重新订购
- 处理退款交易
- 发送确认电子邮件
步骤 5:层次规划 (HLM)
- 管理多步骤工作流程
- 处理依赖关系(在退货确认之前不退款)
- 协调操作的时间安排
第 6 步:概念记忆 (LCM)
- 更新客户偏好配置文件
- 记住该客户的尺码问题
- 存储有关该产品的学习模式
步骤 7:响应生成(GPT 或 MoE)
- 生成一条友好、富有同理心的消息
- 解释所做的事情
- 提供跟踪信息
结果:
一次查询→七种不同的模型类型→在几秒钟内完成解决。
这就是 2026 年现代人工智能代理架构的样子。
10、为不同任务选择合适的模型
这是实际的决策框架:
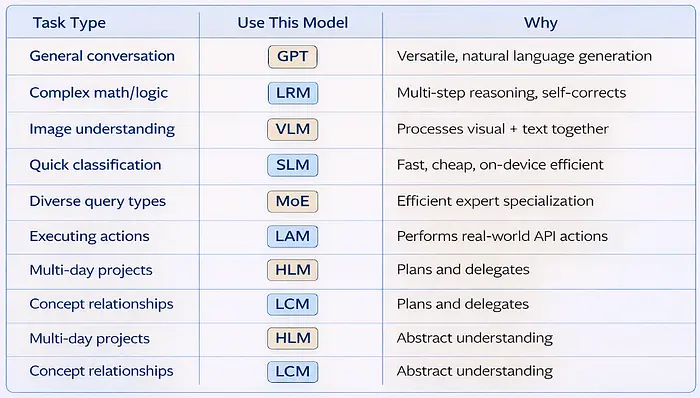
关键原则:
使用能够可靠完成任务的最小、最便宜、最快的模型。不要将 LRM 用于简单问题。当 SLM 足够时,不要使用 GPT。
11、通过模型混合实现成本优化
根据AI Cowboys的企业分析,智能模型混合可以降低60-80%的成本:
昂贵的方法(单一模型):
- 每次查询均使用 GPT-4
- 成本:每 1K 代币输入 0.03 美元,每 1K 输出 0.06 美元* 100 万次查询/月 = 45,000 美元
优化方法(多模型):
- 70% 简单查询 → SLM(设备上,0 美元)
- 20% 中等查询 → MoE 或 GPT-3.5(每 1K 0.002 美元)
- 10% 复杂查询 → GPT-4 或 LRM(每 1K 0.03–0.06 美元)
- 相同的 100 万个查询 = 8,000–12,000 美元
节省: 33,000 美元/月(减少 73%)
12、未来会怎样:2026–2027
根据 SkillWisor 和 Hureka Technologies 记录的趋势:
1. Hybrid Architectures
期望模型结合优势:
- LAM + MoE 用于可扩展的行动代理
- VLM + LRM 用于视觉推理
- HLM + LCM 用于概念规划
2. Edge AI Explosion
随着物联网设备的增多,SLM 将占据主导地位。每个智能设备都会有本地人工智能。
3. Multimodal Integration
VLM 将发展成为同时理解图像、视频、音频和 3D 空间数据的完全通用模型。
4. Autonomous Agent Ecosystems
LAM 和 HLM 将实现真正自主的人工智能代理,需要最少的人工监督。
13、结束语
1.人工智能是多模型,而不是单一模型。现代系统协调多个专门模型,而不是一个巨型模型。
2.每种模型类型都有特定的用途。 GPT 用于对话,LRM 用于推理,LAM 用于行动,VLM 用于视觉 - 使用正确的工具来完成工作。
3.效率来自智能路由。 SLM 和 MoE 架构使生产 AI 能够大规模负担得起。
4.这种转变是从响应到行动。 ChatGPT 回答问题。 LAM 执行解决方案。这就是2024年和2026年的区别。
5.顶级工程师设计系统,而不是提示。了解何时使用哪个模型比了解如何完美提示单个模型更有价值。
“一种模式一统天下”的时代已经结束。智能多模型编排时代已经开启。
原文链接: The 8 Types of AI Models Powering Modern AI Agents: A Complete Guide
汇智网翻译整理,转载请标明出处
