代理技能开发详细指南
通过精心制作的技能将您的编码代理 OpenCode、Claude Code、Codex 和更多从通用 AI 转变为领域专家,将您的专业知识打包成可发现、自主的能力。 为什么技能很重要

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
您是否曾希望能够教您的编码代理团队的特定工作流程?或者给它关于公司工具和流程的即时专业知识?这正是 Claude Code Skills 所做的。
现在,不仅是 Claude Code,还有 Codex、Github Copilot 和 OpenCode 都宣布支持 Agentic Skills。甚至还有一个 Agent 技能市场,通过通用安装器支持 Gemini、Aidr、Qwen Code、Kimi K2 Code、Cursor(14+ 个,还在增加)以及更多具有 Agent 技能支持的工具。在本指南中,我将交替使用 Claude 和编码代理这个词,就像有人可能会说"帮我复印这份文件"而不是"帮我复制这份文件"。(在我的工作流程中,我倾向于使用 Claude Code、OpenCode 和 Gemini CLI。)
将技能视为优秀新员工的入职文档。它们包含 Claude 需要像资深团队成员一样工作的程序性知识和组织上下文。区别是什么?技能是模块化的、可发现的,并且仅在需要时加载,保持 Claude 的上下文窗口专注于重要内容。
本指南向您展示如何编写 Claude 可以成功发现和使用的技能。您将从核心原则学习到高级模式,所有这些都来自 Anthropic 的官方最佳实践。
到本指南结束时,您将知道如何:
- 编写简洁、有效的技能,尊重上下文窗口
- 使用经过验证的命名和组织模式构建技能
- 应用渐进式披露来管理复杂性,而不让 Claude 感到不知所措
- 设计工作流程,为质量关键任务包含反馈循环
- 使用评估驱动的开发进行测试和迭代
- 打包可执行代码,解决问题而不是创建问题
准备好让 Claude 成为团队的秘密武器了吗?让我们从技能的实际工作原理开始。
1、了解技能如何工作
在编写您的第一个技能之前,您需要了解 Claude 的三级加载系统。这个架构是技能力量的秘密。它保持您的上下文窗口精简,同时让 Claude 能够访问大量专业知识。
1.1 渐进式披露架构
技能不会一次性将所有内容都倒入 Claude 的上下文中。相反,它们使用巧妙的三阶段加载系统。这个巧妙的加载系统允许 Claude Code 使用 Agent 搜索。
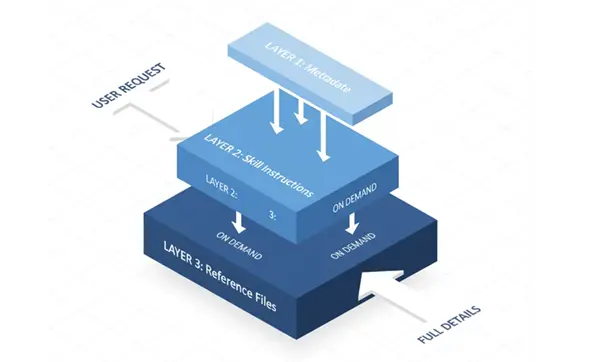
显示渐进式披露三个层的图表:元数据、技能指令和参考文件
1.2 Agent 技能加载的两个阶段
渐进式披露架构在两个不同的阶段中运行:
阶段 1:发现(始终激活)
启动时,Claude 仅从所有可用技能中加载元数据。这包括 YAML 前置内容中的 name 和 description。这个轻量级索引(每个技能约 50-100 个 token)允许 Claude 快速扫描和识别相关技能,而不会消耗大量上下文。
阶段 2:深度加载(按需)
当用户请求与技能的描述匹配时,Claude 加载完整的 SKILL.md 内容和任何其他引用的文件。这是渐进发生的——Claude 仅在需要时读取文件,保持上下文窗口专注于相关信息。
这种两阶段方法使技能可扩展。您可以拥有几十个可用技能,而不会使上下文窗口膨胀,因为只有相关的技能在需要时才会完全加载。
阶段 1:启动 — 只有元数据(名称和描述)加载到系统提示中。这意味着您可以拥有几十个可用技能,而不会消耗上下文 token。
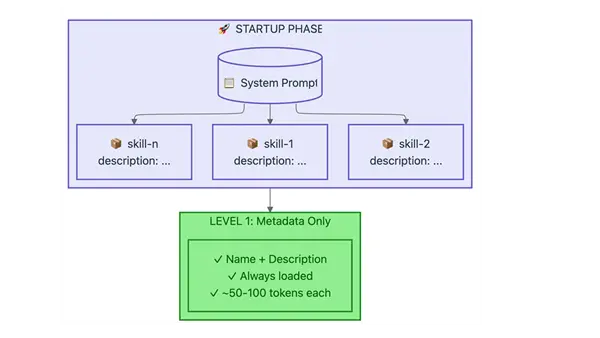
阶段 2–3:按需加载 — 当用户请求匹配时,更深层级会渐进式加载。只有第 1 级(元数据)始终被加载。其他所有内容?在 Claude 需要之前为零 token。
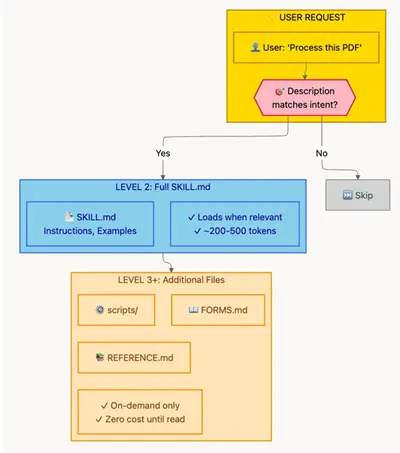
这意味着您可以将大量专业知识捆绑到一个技能中,包括 API 参考、详细示例和整个脚本,而不会使 Claude 的上下文膨胀。当 Claude 探索您的技能结构时,系统会按需加载文件。
**关键见解:**您可以包含的上下文量实际上是无限的。只有当 Claude 实际读取文件时,文件才会消耗 token。
2、三种类型的技能:个人、项目和插件
您放置技能的位置决定了它的范围和共享模型:
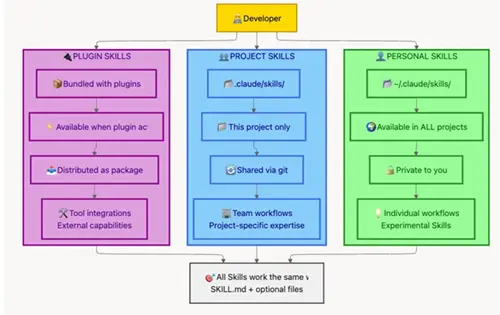
个人技能(~/.claude/skills/、~/.codex/skills、~/.config/opencode/skill)是您的私人工具包。它们非常适合您独有的工作流程或您正在测试的实验性技能。
项目技能(.claude/skills/、.codex/skills、.opencode/skill、.github/copilot/skills)被检入 git 并与您的团队共享。这些捕获每个人都受益的组织知识。
插件技能随 MCP 插件一起提供,提供在您启用插件时激活的特定工具专业知识。
Claude Code 和 OpenAI Codex 还支持在项目目录上方的目录中拥有项目级技能。Codex 还提供了几个更多的地方来安装技能以供企业级使用。
无论类型如何,所有技能都遵循相同的核心结构:一个带有可选支持材料的 SKILL.md 文件。加载架构保持不变。
以下内容基于 Anthropic 的创建技能最佳实践指南,我强烈建议您查看。
我非常喜欢 Anthropic 的最佳实践指南,以至于我创建了一个技能来评估和改进我的技能。
只是为了向您展示我最初的评分:
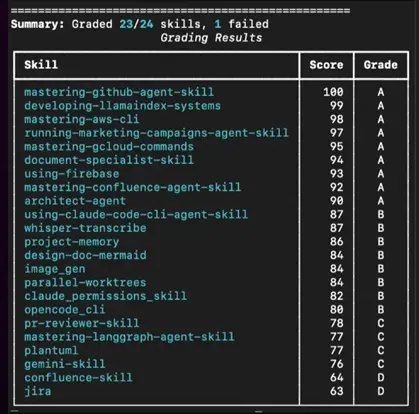
然后在使用指南并修复我的技能之后:
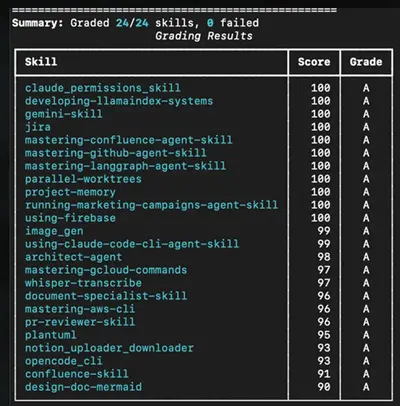
让我们来看看指南中的一些关键思想。
3、核心原则
3.1 简洁为王
这里有一个令人不安的真相:您的技能正在为编码代理上下文窗口中的空间而战。您添加的每个 token 都与系统提示、对话历史、其他技能的元数据、项目特定指令和用户的实际请求竞争。
黄金法则: 假设您的编码代理已经非常聪明。只添加您的编码代理没有的上下文。
在写一段话之前,问问自己:我的编码代理真的需要这个解释吗?我可以假设编码代理已经知道这个了吗?这一段话是否证明了其 50-100 个 token 成本的合理性?
比较这些示例:
好的说明(50 个 token):
## 提取 PDF 文本
使用 pdfplumber 进行文本提取:
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
简洁的版本直奔主题。它假设 Claude 知道 PDF 是什么,理解库,并且可以弄清楚如何安装。相信 Claude 的智能。与这个版本相比:
坏的说明(150 个 token):
## 提取 PDF 文本
PDF(便携式文档格式)文件是一种常见的文件格式,包含
文本、图像和其他内容。要从 PDF 中提取文本,您需要
使用库。有许多可用于 PDF 处理的库,但我们
推荐 pdfplumber,因为它易于使用并且能很好地处理大多数情况。
首先,您需要使用 pip 安装它。然后您可以使用下面的代码...
简洁的版本直奔主题。它假设您的编码代理(Claude Code、OpenCode、GitHub Copilot 等)知道 PDF 是什么,理解库,并且可以弄清楚如何安装。相信您的编码代理的智能。
3.2 设置适当的自由度
并非所有任务都需要相同级别的规定。关键问题是:这个操作有多脆弱?
将您的指令具体性与任务的容错性相匹配:
- 低自由度 — 对于必须遵循确切序列的脆弱、容易出错的操作。使用特定脚本,很少/没有参数,确切的命令。示例:数据库迁移。
- 中等自由度 — 对于具有首选模式但可以接受一些变化的任务。使用伪代码或带有可配置参数的模板。示例:报告生成。
- 高自由度 — 对于存在多种有效方法的任务。使用基于文本的指令和启发式方法来指导方法。示例:代码审查。
就像过桥一样想:两侧都有悬崖的狭窄桥梁需要特定的护栏(低自由度)。没有危险的宽阔开阔田野允许多条成功路径(高自由度)。穿过树林的标记路径:存在首选路径,但绕道不会造成问题;这提供模板但允许自定义(中等自由度)。
数据库迁移?用确切的脚本锁定它。代码审查?给您的编码代理思考空间。报告生成?提供模板但让您的编码代理适应数据。
3.3 使用您计划使用的所有模型进行测试
与 Opus 或 Gemini 3 Pro 完美配合的技能可能会让 Haiku 或 Gemini Flash Light 感到困惑。不同的模型具有不同的推理能力。跨模型测试以找到最佳点。您的技能应该足够简洁以适合 Opus 用户,但对于 Haiku 用户来说足够详细。如果您针对更高的思维模型,如 Opus 或 Gemini 3 Pro,只需说明即可。如果您计划与 Haiku 一起使用技能,您应该用 Haiku 测试它。
4、技能结构
4.1 YAML 前置内容:发现机制
每个 SKILL.md 文件都以包含两个必需字段的 YAML 前置内容开头:name 和 description。这个元数据总是被加载(渐进式披露系统中的第 1 级)。这是您的编码代理发现哪些技能与用户请求相关的方式。
---
name: your-skill-name
description: Brief description of what this Skill does and when to use it
---
字段要求:
- name:最多 64 个字符,仅小写字母/数字/连字符,没有保留词(如 "anthropic" 或 "claude")
- description:最多 1024 个字符,非空,描述技能做什么以及何时使用
4.2 命名约定:使用动名词形式
使用动名词形式(动词 + -ing)以保持清晰和一致:processing-pdfs、analyzing-spreadsheets、managing-databases、testing-code、generating-reports。您会看到很多旧技能,包括 Anthropic 的原始技能都不使用这种形式,但现在在 Anthropic 发布了最佳实践指南 之后,它们开始采用它。如果您认真对待技能开发,您应该阅读此指南。我们也在本文中介绍了一些最佳实践。
避免像 "helper" 或 "utils" 这样的模糊名称,像 "documents" 或 "files" 这样的通用名称,以及像 "pdf" 这样的歧义名称。
使用动名词形式(动词 + -ing)以保持清晰和一致:
推荐:
processing-pdfsanalyzing-spreadsheetsmanaging-databasestesting-codegenerating-reports
4.3 编写启用发现的描述
描述是您技能的电梯演讲。您的编码代理阅读它以决定此技能是否与用户的请求匹配。
神奇公式:描述技能做什么以及何时使用它。始终使用第三人称编写,因为描述直接注入到系统提示中。

好的示例:"从 PDF 文件中提取文本和表格,填充表单,合并文档。在使用 PDF 文件或当用户提及 PDF、表单或文档提取时使用。"
糟糕的示例:"帮助处理文档";这太模糊了,没有何时使用它的上下文。
很好的示例:
# PDF 处理
description: >
从 PDF 文件中提取文本和表格,填充表单,合并文档。
在使用 PDF 文件或当用户提及 PDF、表单或文档提取时使用。
# Excel 分析
description: >
分析 Excel 电子表格,创建数据透视表,生成图表。
在分析 Excel 文件、电子表格、表格数据或 .xlsx 文件时使用。
# Git 提交助手
description: >
通过分析 git 差异生成描述性提交消息。
当用户请求帮助编写提交消息或审查暂存更改时使用。
糟糕的示例:
description: Helps with documents # 太模糊 - 什么样的帮助?
description: Processes data # 没有何时使用的上下文
description: Does stuff with files # 完全没有帮助
4.4 目录结构:一层深
技能通过智能组织进行扩展。最好的技能不会将所有内容都倾倒到单个文件中。它们创建导航结构,让您的编码代理在需要时准确找到需要的内容。
将您的技能视为参考库。主 SKILL.md 文件是接待台。它提供方向并指向正确的部分。支持文件是详细信息所在的专门阅读室。
关键原则:保持一层深。Claude 应该永远不需要从 SKILL.md 跟随超过一个链接才能到达实际内容。这防止了导航开销并确保快速、可靠地访问信息。
保持您的技能文件结构扁平和可导航:
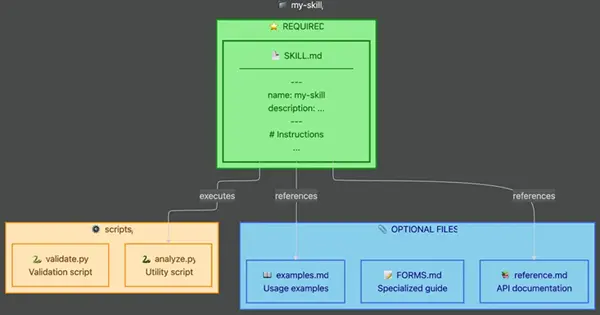
黄金法则:保持引用从 SKILL.md 起一层深。
为什么?编码代理通过跟随链接导航技能。深度嵌套(SKILL.md 到 advanced.md 到 details.md 到实际信息)会产生导航开销,并可能导致您的编码代理部分读取文件或完全错过内容。
好的结构:
my-skill/
├── SKILL.md # 主入口点
├── reference/
│ ├── api.md # 详细的 API 文档(从 SKILL.md 链接)
│ └── examples.md # 使用示例(从 SKILL.md 链接)
└── scripts/
├── analyze.py # 实用脚本
└── validate.py # 验证脚本
糟糕的结构:
您说得对!"糟糕的结构"示例应该更好地说明深度嵌套引用的反模式。这是一个改进版本,展示了有问题的链:
my-skill/
├── SKILL.md # 链接到 advanced.md
└── reference/
└── advanced.md # 链接到 details.md
└── deep/
└── details.md # 链接到 actual-content.md
└── nested/
└── actual-content.md # 终于,信息!
这清楚地显示了多跳导航问题:SKILL.md → advanced.md → details.md → actual-content.md,这正是指南警告的模式。
5、渐进式披露模式
渐进式披露是仅在需要时揭示信息的艺术。您的 SKILL.md 充当地图,根据任务需要指向 Claude 详细材料。
5.1 模式 1:高级指南与参考
最常见的模式:在 SKILL.md 中提供快速入门,然后为高级场景链接到详细参考。
---
name: pdf-processing
description: Extracts text and tables from PDF files, fills forms, merges documents. Use when working with PDF files.
---
# PDF 处理
## 快速入门
使用 pdfplumber 提取文本:
```
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
## 高级功能
**表单填充**:查看 [FORMS.md](FORMS.md) 获取完整指南
**API 参考**:查看 [REFERENCE.md](REFERENCE.md) 获取所有方法
**示例**:查看 [EXAMPLES.md](EXAMPLES.md) 获取常见模式
为什么这有效:您的编码代理立即加载 SKILL.md(200-500 个 token)。如果用户只需要基本的文本提取,快速入门就足够了。如果他们需要表单填充,编码代理会按需读取 FORMS.md。
结果:您通过不为简单的文本提取任务加载表单填充文档,可能节省了数千个 token。
5.2 模式 2:领域特定组织
对于涵盖多个领域的技能,按主题组织文件以避免加载不相关的上下文:
bigquery-skill/
├── SKILL.md # 概述和导航
└── reference/
├── finance.md # 收入、计费指标
├── sales.md # 机会、管道
├── product.md # API 使用、功能
└── marketing.md # 活动、归因
SKILL.md 导航部分:
## 领域指南
**财务指标**:[finance.md](reference/finance.md) -
收入、计费、订阅
**销售数据**:[sales.md](reference/sales.md) -
机会、管道、预测
**产品分析**:[product.md](reference/product.md) -
使用、功能、采用
**营销活动**:[marketing.md](reference/marketing.md) -
归因、ROI
当用户询问"显示本季度的销售管道"时,编码代理只加载 sales.md。财务、产品和营销文档保持未加载状态,为实际分析节省 token。
5.3 模式 3:长文件的目录
如果参考文件超过 100 行,添加目录以帮助 Claude 导航:
# API 参考
## 目录
- [身份验证和设置](#authentication-and-setup)
- [核心方法](#core-methods) - 创建、读取、更新、删除
- [高级功能](#advanced-features) - 批量操作、webhook
- [错误处理](#error-handling) - 模式和恢复
- [代码示例](#code-examples)
## 身份验证和设置
...
## 核心方法
...
为什么这有帮助:您的编码代理可以扫描目录并直接跳转到相关部分,而不是线性地读取整个文件。这是 Agent 搜索的基础,它允许您的编码代理使用 GLOB 和 GREP 等工具快速导航文件,而不是读取其全部内容;从而节省宝贵的上下文窗口资源。
5.4 反模式:深度嵌套引用
避免创建多级导航链:
糟糕的:
# SKILL.md
查看 [advanced.md](advanced.md) 了解更多...
# advanced.md
查看 [details.md](details.md) 了解具体细节...
# details.md
终于,实际信息!
问题:Claude 在跟随链时可能会部分读取文件,消耗 token 而没有到达实际内容。更糟糕的是,深度嵌套可能导致 Claude 完全错过重要信息。
好的:
# SKILL.md
- **基本用法**:[下面的快速示例]
- **高级功能**:查看 [advanced.md](advanced.md)
- **API 参考**:查看 [reference.md](reference.md)
- **故障排除**:查看 [troubleshooting.md](troubleshooting.md)
所有重要文件距离 SKILL.md 一跳。
6、工作流程和反馈循环
工作流程:将复杂任务分解为步骤
复杂操作需要结构。使用清晰、顺序的工作流程和检查清单来指导 Claude 完成多步骤过程:
## PDF 表单填充工作流程
复制此检查清单并在完成项目时勾选:
```markdown
任务进度:
[ ] 步骤 1:分析表单(运行 analyze_form.py)
[ ] 步骤 2:创建字段映射(编辑 fields.json)
[ ] 步骤 3:验证映射(运行 validate_fields.py)
[ ] 步骤 4:填充表单(运行 fill_form.py)
[ ] 步骤 5:验证输出(运行 verify_output.py)
```
**步骤 1:分析表单**
运行分析脚本:
```bash
python scripts/analyze_form.py input.pdf
```
这会提取所有表单字段及其位置,输出到 `fields.json`。
**步骤 2:创建字段映射**
编辑 `fields.json` 为每个字段添加值。示例:
```json
{ "customer_name": "John Doe", "order_total": "1234.56" }
```
**步骤 3:验证映射**
在填充之前,验证映射是否正确:
**步骤 3:验证映射**
在填充之前,验证映射是否正确:
```bash
python scripts/validate_fields.py fields.json
```
在继续之前修复任何报告的错误。
...
为什么检查清单有效: 它们在用户和 Claude 之间创建共享状态。用户可以看到进度,Claude 可以跟踪完成情况,如果被打断,两者都可以恢复。
7、反馈循环:验证-修复-重复模式
对于质量关键操作,没有验证绝不继续。验证-修复-重复模式显著提高输出质量:
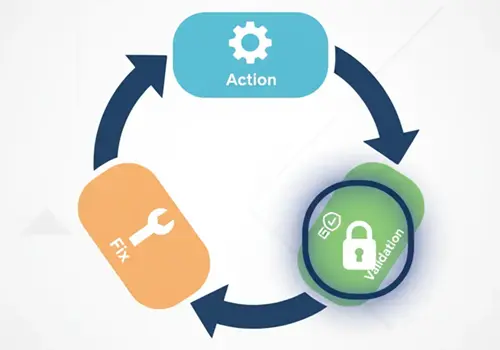
此图说明了反馈循环工作流程,这是质量关键操作的关键模式。工作流程显示了如何迭代地验证工作,而不是等到最后:
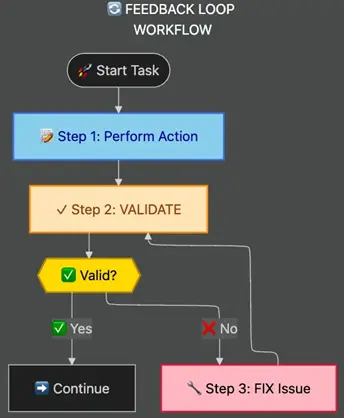
反馈循环更成功
流程:
- 开始任务 → 开始操作
- 步骤 1:执行操作 → 执行初始工作(例如,编辑 XML,生成代码,修改数据)
- 步骤 2:验证 → 立即检查输出是否正确
- 决策点 → 验证是否成功?
- 如果否(❌) → 进入步骤 3:修复问题,然后返回验证
- 如果是(✅) → 进入整体工作流程的下一步
关键原则: 验证 → 检查 → 修复 → 验证之间的循环持续直到验证通过。这防止使用损坏或不正确的工作继续。
为什么此模式有效:
- 立即捕获错误,当上下文新鲜时修复更容易
- 防止级联故障,确保每个步骤在继续之前都是正确的
- 显著减少调试时间,与"最后修复所有内容"的方法相比
- 建立信心,最终输出将是正确的
图表使用颜色编码来区分操作步骤(蓝色)、验证步骤(橙色)、决策点(金色)和修复步骤(粉色),使工作流程一目了然。
示例实现:
## 文档编辑流程
1. 对 `word/document.xml` 进行编辑
2. **立即验证**:
```bash
python scripts/validate.py unpacked_dir/
```
3. **如果验证失败**:
- 仔细查看错误消息
- 修复 XML 中的问题
- 再次运行验证
- **在验证通过之前不要继续**
4. 重建文档:
```bash
python scripts/pack.py unpacked_dir/ output.docx
```为什么这有效: 在进行更改后立即捕获错误比在最后调试损坏文件要容易得多。验证提供即时反馈,将脆弱的过程转变为可靠的过程。
真实世界影响: 与"先编辑所有内容然后检查"的方法相比,使用反馈循环的团队报告的损坏输出减少了 70-90%。
8、常见模式
8.1 模板模式:提供输出结构
当输出格式很重要时,提供显示预期结构的模板。
对于严格要求(低自由度):
## 文档修改流程
### 步骤 1:确定修改类型
问问自己:我是在创建新内容还是编辑现有内容?
**创建新内容?** 遵循创建工作流程
**编辑现有内容?** 遵循编辑工作流程
---
### 创建工作流程
从头开始构建文档时:
1. 使用 `docx-js` 库
2. 以编程方式构建文档
3. 以正确的顺序添加内容(样式优先,然后是内容)
示例:
```python
from docx import Document
doc = Document()
doc.add_heading('Report Title', 0)
doc.add_paragraph('First paragraph')
doc.save('report.docx')
```
---
### 编辑工作流程
修改现有文档时:
1. 将现有文档解压到目录
2. 直接修改 XML 文件
3. **每次更改后验证**使用 `validate.py`
4. 仅在验证通过时重新打包
```bash
python scripts/unpack.py document.docx unpacked/
# 对 unpacked/word/document.xml 进行编辑
python scripts/validate.py unpacked/
python scripts/pack.py unpacked/ modified.docx
```"ALWAYS" 一词表示这是强制性的,而非可选的
对于灵活的指导(高自由度):
## 报告结构
这是一个合理的默认格式,但根据您的发现进行调整:
```markdown
# [分析标题]
## 概述
[上下文和范围]
## 分析
[根据发现调整部分]
## 结论
[关键要点]
```
根据数据自然调整部分。
"根据...调整"这一短语表示灵活性。
8.2 示例模式:输入/输出对
对于质量很重要的任务,显示正确输出的具体示例:
## 提交消息格式
**示例 1:新功能**
输入:添加了具有 JWT 令牌的用户身份验证
输出:
```
feat(auth): 实现基于 JWT 的身份验证
添加具有令牌生成和验证中间件的登录端点。 包括令牌刷新逻辑和安全存储。
**示例 2:错误修复**
输入:修复了日期显示不正确的错误
输出:
```
fix(reports): 更正时区转换中的日期格式
```
在报告生成中一致地使用 UTC 时间戳。 以前使用本地时间,这会导致不同时区的用户出现差异。为什么示例有效:它们向 Claude 展示了预期的质量水平和风格,而不需要规定性规则。Claude 从示例中学习模式。
8.3 条件工作流程模式:决策点
在存在多个路径时指导 Claude 穿过决策树:
## 文档修改流程
### 步骤 1:确定修改类型
问问自己:我是在创建新内容还是编辑现有内容?
**创建新内容?** 遵循创建工作流程
**编辑现有内容?** 遵循编辑工作流程
---
### 创建工作流程
从头开始构建文档时:
1. 使用 `docx-js` 库
2. 以编程方式构建文档
3. 以正确的顺序添加内容(样式优先,然后是内容)
示例:
```python
from docx import Document
doc = Document()
doc.add_heading('Report Title', 0) doc.add_paragraph('First paragraph') doc.save('report.docx')
```
---
### 编辑工作流程
修改现有文档时:
1. 将现有文档解压到目录
2. 直接修改 XML 文件
3. **每次更改后验证**使用 `validate.py`
4. 仅在验证通过时重新打包
```python
python scripts/unpack.py document.docx unpacked/
# 对 unpacked/word/document.xml 进行编辑
python scripts/validate.py unpacked/
python scripts/pack.py unpacked/ modified.docx
```清晰的决策点("我是创建还是编辑?")帮助 Claude 选择正确的路径。
9、评估和迭代
8.1 从评估开始,而不是文档
这里有一个可以为您节省数小时的秘密:在编写大量文档之前构建评估。
为什么?因为评估揭示了 Claude 挣扎的地方,指导您只编写重要的文档。
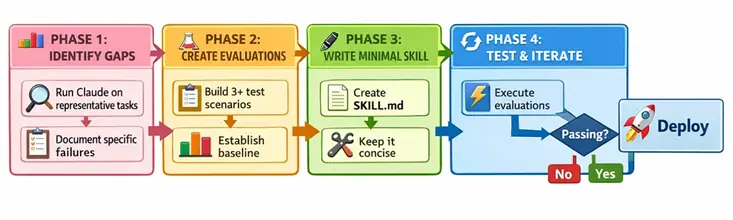
评估驱动的工作流程:
- 识别差距:在没有技能的情况下让 Claude 处理真实任务。注意它在哪里挣扎、犯错或请求指导。
- 创建评估:构建 3-5 个捕获这些失败模式的测试场景。每个场景应该测试特定能力。
- 编写最小技能:创建一个简洁的
SKILL.md,针对记录的失败。抵制过度解释的冲动。 - 测试和迭代:运行您的评估。如果失败,完善技能。如果通过,您就完成了。
评估结构示例:
{
"skills": ["pdf-processing"],
"query": "Extract all text from this PDF and save to output.txt",
"files": ["test-files/document.pdf"],
"expected_behavior": [
"Successfully reads the PDF file",
"Extracts text from all pages (not just the first page)",
"Saves to output.txt in readable UTF-8 format",
"Handles multi-column layouts correctly"
]
}
为什么这有效: 评估为您提供客观的通过/失败标准。不再猜测您的技能是否"足够好"。要么通过测试,要么不通过。
10、用 Claude 迭代开发技能
想知道创建技能的最快方法吗?用Claude 构建它。
以下是过程:
- 手动完成任务:用 Claude 完成一项任务,提供所有必要的上下文和指导。
- 观察您反复解释的内容:记录您在类似任务中多次提供的信息。
- 要求 Claude 创建技能:"创建一个捕获我们刚刚用于 [任务] 的模式的技能。专注于 [特定方面]。"
- 审查简洁性:Claude 的第一稿通常会过度解释。无情地删减,相信 Claude 的基础知识。
- 在新实例上测试:打开一个新的 Claude 对话(以清除上下文)并在类似任务上测试技能。
- 根据观察进行迭代:观察 Claude 在哪里挣扎或犯错,然后完善技能以解决这些特定问题。
真实示例: 一位开发人员在构建 BigQuery 技能时与 Claude 一起完成了 5 个财务查询,然后说:"创建一个捕获我们财务指标查询方法的技能。"Claude 生成了初始技能,开发人员将其修剪到原始长度的 40%,在新查询上进行了测试,并且在不到一小时内拥有了生产就绪的技能。
11、观察 Claude 如何实用您的技能
一旦您有了技能,观察 Claude 如何使用它。您会发现改进机会:
意外的探索路径:如果 Claude 以令人惊讶的顺序读取文件,您的导航结构可能不直观。添加更清晰的标志。
错过的连接:如果 Claude 没有发现相关的参考文件,链接可能不够明显。使连接更加明确。
过度依赖某些部分:如果 Claude 总是读取某个特定部分,该内容可能属于主 SKILL.md 以便更快访问。
被忽略的内容:如果 Claude 从不读取参考文件,它要么是不必要的,要么信号很弱。要么删除它,要么改进其描述。
模式识别:使用 5-10 次后,您将看到 Claude 如何导航的模式。围绕这些模式优化您的结构。
12、高级:具有可执行代码的技能
12.1 在脚本中显式处理错误
脚本应该解决问题,而不是把它们推给 Claude 处理。
好的错误处理:
def process_file(path):
"""处理文件,如果不存在则使用默认值创建它。"""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
print(f"文件 {path} 未找到,使用默认内容创建")
with open(path, 'w') as f:
f.write('# 默认配置\n')
return '# 默认配置\n'
except PermissionError:
print(f"权限被拒绝用于 {path}。检查文件权限。")
sys.exit(1)
糟糕的错误处理:
def process_file(path):
# 只是失败并让 Claude 搞清楚
return open(path).read() # 用无用的错误崩溃
为什么显式处理很重要:当脚本因清晰、可操作的错误消息而失败时,Claude 通常可以自动解决问题。通用错误迫使 Claude 猜测。
12.2 提供实用脚本以节省 token
预制的脚本比让 Claude 按需生成代码有几个优势:
- 更可靠:提前测试和调试
- 节省 token:上下文窗口中没有代码
- 节省时间:不需要生成
- 确保一致性:每次都相同的方法
## 实用脚本
**analyze_form.py**:从 PDF 中提取所有表单字段
```bash
python scripts/analyze_form.py input.pdf > fields.json
```
输出:具有字段名称、类型和位置的 JSON 文件
**validate_boxes.py**:检查重叠的边界框
```bash
python scripts/validate_boxes.py fields.json
```
返回:"OK" 或列出修复建议的冲突
真实世界影响: 一个构建文档处理技能的团队在用实用脚本替换生成的代码片段后,token 使用量减少了 40%。
12.3 创建可验证的中间输出
对于复杂的多步骤任务,使用计划-验证-执行模式:
- 分析以创建计划文件
- 验证计划以获得具体反馈
- 执行计划以执行操作
- 验证输出以确认成功
示例工作流程:
## 带验证的表单填充
1. 分析表单结构:
```bash
python scripts/analyze_form.py input.pdf > plan.json
```
2. **在继续之前验证计划**:
```bash
python scripts/validate_plan.py plan.json
```
修复任何报告的错误。常见问题:
- 缺少必填字段
- 重叠的边界框
- 无效的字段类型
3. 仅在验证通过时执行:
```bash
python scripts/fill_form.py plan.json input.pdf output.pdf
```
使验证具有具体的、可操作的错误消息:
糟糕的:"验证失败"
好的:"未找到字段 'signature_date'。可用字段:customer_name、order_total、delivery_address"
12.4 依赖项:列出和验证
始终明确指定所需的包:
## 要求
此技能需要以下包:
```bash
pip install pypdf pdfplumber pillow
```
**验证安装**:
```bash
python -c "import pdfplumber; print('pdfplumber:', pdfplumber.version)"
```
如果您看到版本输出,您就准备好了。
为什么验证很重要:安装可能会静默失败,特别是在虚拟环境中。快速验证步骤会在导致任务中途出现神秘错误之前捕获问题。
12.5 MCP 工具引用:使用完全限定名称
引用 MCP 工具时,始终使用完全限定格式:Plugin:tool_name
使用 `BigQuery:bigquery_schema` 工具检索表架构。
使用 `GitHub:create_issue` 工具创建问题。
使用 `Notion:create_page` 工具创建新页面。
为什么这很重要:像 "create_issue" 这样的通用名称可能指的是多个工具。限定名称消除了歧义。
13、内容指南
13.1 避免时间敏感信息
技能应该是永恒的。避免引用特定日期或变得过时的"当前"状态。
糟糕的:
如果您在 2025 年 8 月之前这样做,请使用旧 API。
在 2025 年 8 月之后,请使用新 API。好的:
## 当前方法
使用 v2 API 端点:
```python
response = requests.post("https://api.example.com/v2/messages")
```
## 旧模式
旧 v1 API(2025 年 8 月已弃用)
v1 API 使用不同的端点结构:
```python
response = requests.post("https://api.example.com/v1/messages")
```为什么这有效:新用户立即看到当前方法。维护遗留代码的用户可以展开详细信息部分。不需要基于时间的逻辑。
13.2 在整个过程中使用一致的术语
为每个概念选择一个术语并坚持使用:
- 一致:始终"API 端点" | 不一致(令人困惑):混合"API 端点"、"URL"、"路由"、"路径"
- 一致:始终"字段" | 不一致(令人困惑):混合"字段"、"框"、"元素"、"控件"
- 一致:始终"提取" | 不一致(令人困惑):混合"提取"、"拉"、"获取"、"检索"
- 一致:始终"验证" | 不一致(令人困惑):混合"验证"、"检查"、"确认"、"测试"
为什么一致性很重要:每个新术语都迫使 Claude(和用户)确定它是同义词还是不同的概念。一致的术语减少了认知负荷。
13.3 避免提供太多选项
不要用选择压倒一切。推荐一种方法,然后仅在真正需要时提及替代方案。
糟糕的:
您可以使用 pypdf,或 pdfplumber,或 PyMuPDF,或 pdf2image,或 tabula-py... 每个都有优缺点。选择您喜欢的任何一个。好的:
使用 pdfplumber 进行文本提取。它可靠地处理大多数 PDF:
```python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
```
**对于扫描的 PDF(图像,不是文本),使用 pdf2image 和 pytesseract 进行 OCR:**
```python
from pdf2image import convert_from_path
from pytesseract import image_to_string
```为什么单一推荐有效:它消除了决策瘫痪。Claude 可以专注于执行而不是评估权衡。如果推荐方法失败,Claude 可以探索替代方案。但大多数任务主要推荐都能成功。
14、有效技能的检查清单
在部署技能之前使用此检查清单:
核心质量:
- [ ] 描述具体且包含触发关键词
- [ ] 描述包括技能做什么以及何时使用它
- [ ] SKILL.md 主体在 500 行以下
- [ ] 其他详细信息在单独的参考文件中(不挤入 SKILL.md)
- [ ] 没有时间敏感信息(没有"2025 年之前"的逻辑)
- [ ] 在所有文件中术语一致
- [ ] 文件引用是一层深的(没有嵌套链)
- [ ] 适当地使用渐进式披露模式
代码和脚本:
- [ ] 脚本显式处理错误并带有清晰消息
- [ ] 没有"巫术常数"(所有硬编码值都有解释原因的注释)
- [ ] 列出所需的包并带有安装命令
- [ ] 所有文件路径使用正斜杠(跨平台兼容性)
- [ ] 关键操作的验证/验证步骤
- [ ] 脚本解决问题而不是把它们推给 Claude
测试:
- [ ] 至少创建了三个评估,涵盖主要用例
- [ ] 使用 Haiku、Sonnet 和 Opus 模型进行了测试
- [ ] 在真实场景上测试(不仅仅是玩具示例)
- [ ] 观察了 Claude 如何导航技能
- [ ] 融入了团队反馈(对于项目技能)
15、快速参考:创建您的第一个技能
让我们创建一个生成提交消息的简单技能。
15.1 步骤 1:创建技能目录
# 个人技能(随处可用,对您私有)
mkdir -p ~/.claude/skills/generating-commit-messages
# 项目技能(仅此项目,通过 git 共享)
mkdir -p .claude/skills/generating-commit-messages对于 Codex:
# 个人技能(随处可用,对您私有)
mkdir -p ~/.codex/skills/generating-commit-messages
# 项目技能(仅此项目,通过 git 共享)
mkdir -p .codex/skills/generating-commit-messages对于 OpenCode:
# 个人技能(随处可用,对您私有)
mkdir -p ~/.config/opencode/skill/generating-commit-messages
# 项目技能(仅此项目,通过 git 共享)
mkdir -p .opencode/skill/generating-commit-messages15.2 步骤 2:创建最小 SKILL.md
---
name: generating-commit-messages description: Generates clear commit messages by analyzing git diffs. Use when writing commit messages or reviewing staged changes.
---
# 生成提交消息
## 指令
1. 运行 `git diff --staged` 查看更改
2. 分析更改并建议提交消息,包括:
- 摘要:50 个字符以下,现在时
- 描述:更改了什么以及为什么
- 受影响的组件:列出修改区域
## 格式
```
<type>(<scope>): <summary>
```
类型:feat、fix、docs、refactor、test、chore
## 最佳实践
- 使用现在时("添加功能"而不是"添加了功能")
- 解释什么和为什么,而不是如何
- 在相关时引用问题编号15.3 步骤 3:测试它
打开一个新的编码代理对话并尝试:"帮我为我的暂存更改编写提交消息。"
15.4 步骤 4:迭代
观察您的编码代理如何使用技能。根据有效的和无效的进行改进。
16、结束语
编写有效的 Agent 代码技能是关于平衡:
在简洁性和清晰性之间取得平衡:每个 token 都在竞争空间,但 Claude 需要足够的上下文来成功。
在规定和自由度之间取得平衡:将指令具体性与任务脆弱性相匹配。
在结构和灵活性之间取得平衡:组织以便于导航,但不要过度设计。
在测试和发布之间取得平衡:根据实际使用进行迭代,但不要让完美成为良好的敌人。
最好的技能感觉像来自专家的知识转移。它们捕获了程序智慧和将 Claude 从通用 AI 转变为您的领域中的领域专家的组织上下文。
从小开始:
- 首先构建评估(揭示 Claude 在哪里挣扎)
- 编写最少的文档(相信 Claude 的智能)
- 跨模型测试(Haiku、Sonnet、Opus)
- 根据观察进行迭代(观察 Claude 如何导航)
每次迭代都使您的技能更敏锐。您覆盖的每个用例都使 Claude 更有能力。您不仅在编写文档。您在编码专业知识。
您会先教您的编码代理什么?
原文链接:Mastering Agentic Skills: The Complete Guide to Building Effective Agent Skills
汇智网翻译整理,转载请标明出处
