用于LLM微调的数据清洗技术指南
无论你是为小众应用微调 LLM,还是为实时信息检索增强 RAG 系统,掌握数据清洗都是你成功的关键。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
数据质量在 AI 中至关重要,特别是对于微调大语言模型(LLM)和实施检索增强生成(RAG)架构等高级应用。这些系统依赖于结构化、高质量的数据集来生成准确且上下文相关的输出。另一方面,质量差的数据可能导致 LLM 输出中的幻觉、不相关的文档检索,甚至严重偏见,从而侵蚀对 AI 系统的信任。
本博客深入探讨了数据清洗在 AI 工作流中的关键作用。你将探索关键技术、像 IBM 的 Data Prep Kit 这样的创新工具,以及重塑 AI 数据准备的新兴趋势。无论你是为小众应用微调 LLM,还是为实时信息检索增强 RAG 系统,掌握数据清洗都是你成功的关键。
1、AI 流水线中的数据清洗是什么?
数据清洗是为 AI 系统(如 LLM 和基于向量的架构)准备数据集的关键步骤。它涉及识别和处理问题,以确保数据准确、一致且结构化,以便最佳使用。数据清洗解决的关键挑战包括:
- 有害数据(语言、代码): 检测并移除有毒语言或不安全的代码,确保数据集符合伦理且安全可部署。
- PII 移除: 通过识别和匿名化个人身份信息(PII)来保护敏感信息,以符合 GDPR 和 CCPA 等法规。
- 偏见缓解: 识别并减少系统性偏见,以创建公平且具代表性的数据集,防止 LLM 输出偏差。
- 噪声消除: 过滤无关、冗余或误导性内容,以提高嵌入的质量和相关性。
对于 LLM 微调,干净的数据集通过确保模型从高质量数据中学习,增强了泛化能力和领域特定性能。在 RAG 架构中,干净的数据确保嵌入准确反映内容,提高了检索精度和整体系统性能。
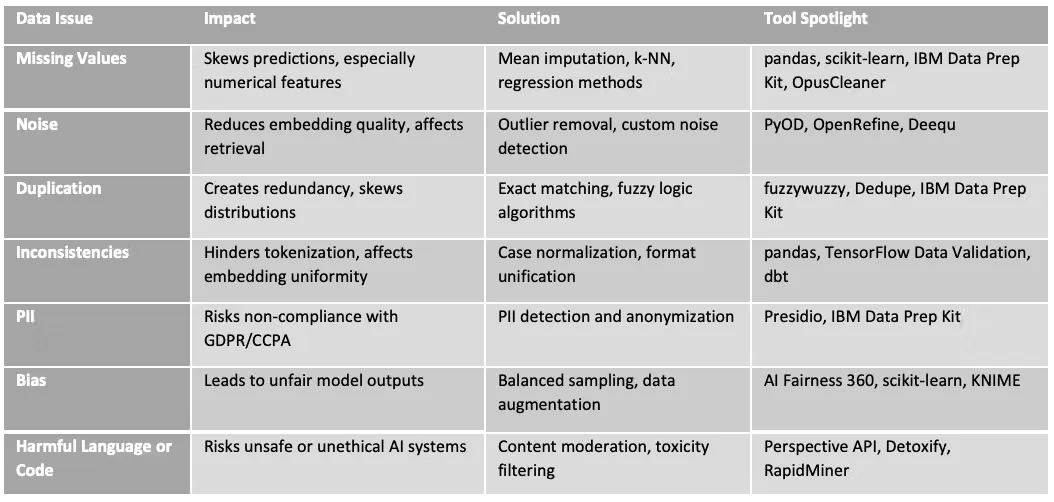
2、AI 中的常见数据问题有哪些?
高质量数据是可靠的 AI 系统(如 LLM 和 RAG 架构)的支柱。没有它,即使是最先进的模型也可能失败,导致糟糕的预测、低效率和偏见的结果。下面,我们探讨了 AI 数据流水线中面临的关键挑战以及如何有效应对它们。
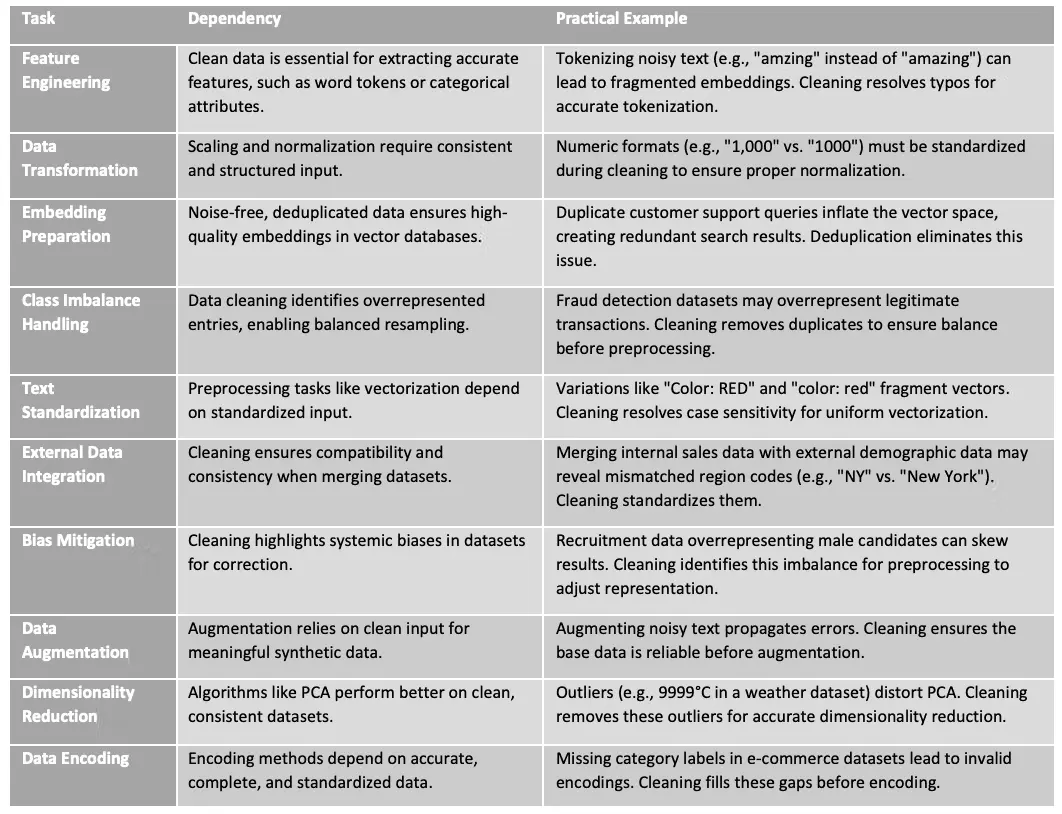
3、数据清洗如何为预处理提供动力:全面分解
数据清洗和预处理本质上是相互关联的,预处理工作流的成功取决于干净、结构化和一致的数据。这种协同作用对于构建可靠高效的 AI 模型至关重要,因为数据清洗为预处理任务的有效运作奠定了基础。从特征工程到偏见缓解,这些相互依赖关系确保了数据完整性,增强了下游流程,并使 AI 系统能够实现最佳性能。
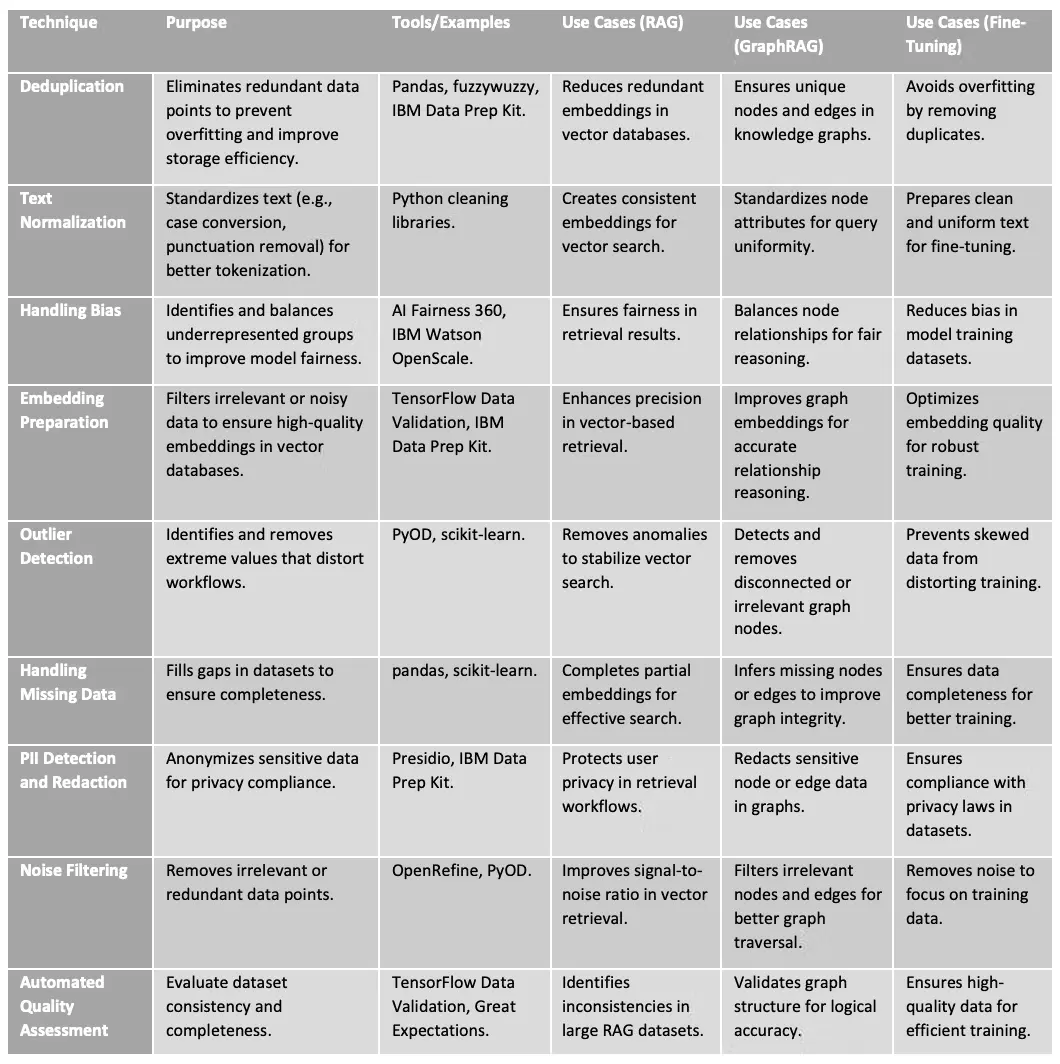
4、适用于 RAG/GraphRAG/微调的数据清洗技术
以下表格全面概述了关键数据清洗技术及其在三个关键 AI 工作流中的应用:检索增强生成(RAG)、GraphRAG 和微调大语言模型(LLM)。每种技术都详细说明了其目的、相关工具和具体用例,以强调其在确保高质量数据流水线中的重要性。例如,去重消除了冗余条目以优化 RAG 的向量数据库,而处理偏见则确保基于图的模型和微调模型中的公平表示。该表格还强调了实际示例,如用于更好图遍历的噪声过滤和用于增强检索任务精度的嵌入准备。此资源可作为实践者优化其 AI 系统的实用指南,解决常见挑战如缺失数据、PII 编辑和异常值检测。无论你是在构建健壮的向量数据库、构建逻辑知识图,还是为高级应用微调 LLM,这些技术都提供了成功的基础。
5、新兴数据清洗方法:推动 LLM 和 RAG 架构发展
有效的数据清洗对于优化 LLM、RAG 系统和 GraphRAG 架构至关重要,确保 AI 工作流的准确性和可靠性。与专注于静态数据集和手动清洗过程的传统方法不同,这些新兴技术利用 AI 驱动的自动化、实时能力和合成数据生成来应对现代挑战,如流数据、低资源领域和偏见缓解。以下表格重点介绍了这些先进方法、它们的应用、工具和挑战,为尖端 AI 系统中的数据准备提供了实用指南。
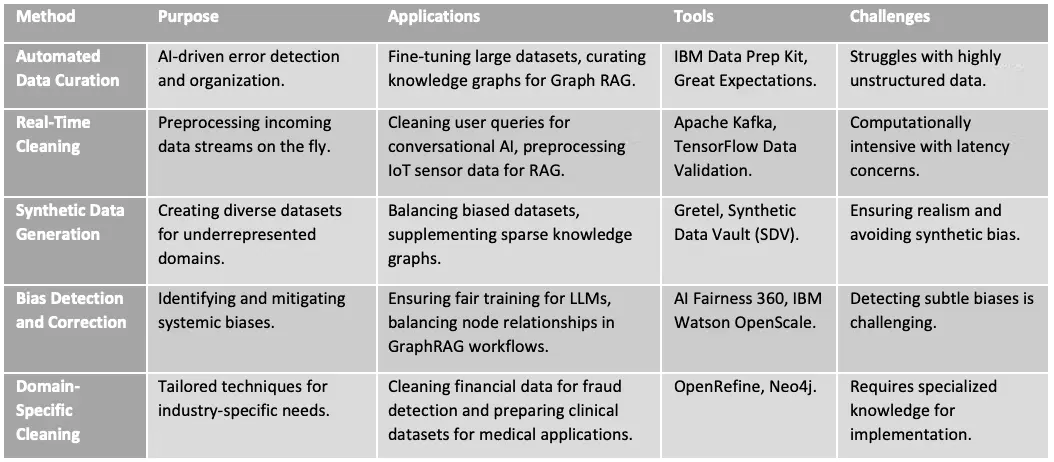
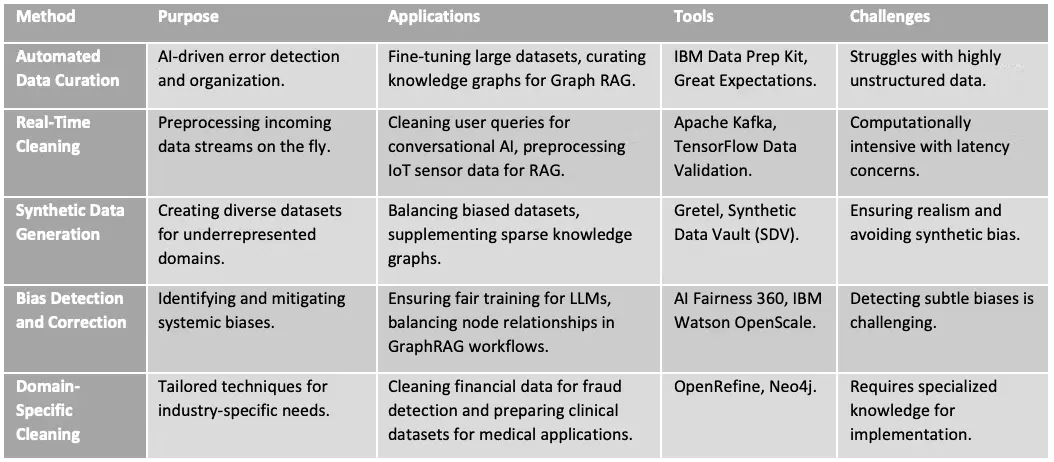
6、AI 先进流水线的数据清洗工具对比
在快节奏的人工智能世界中,选择正确的数据清洗工具是构建高效流水线的关键。以下表格清晰对比了流行工具,分析了它们的特性、优势、局限性等。从像 Pandas 这样多功能的开源选项到像 IBM Data Prep Kit 这样的企业级平台,它重点介绍了满足各种需求和规模的工具。
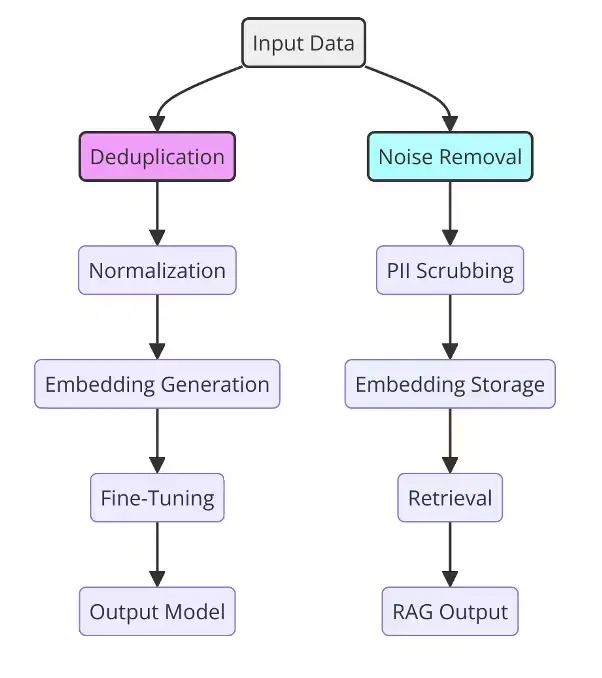
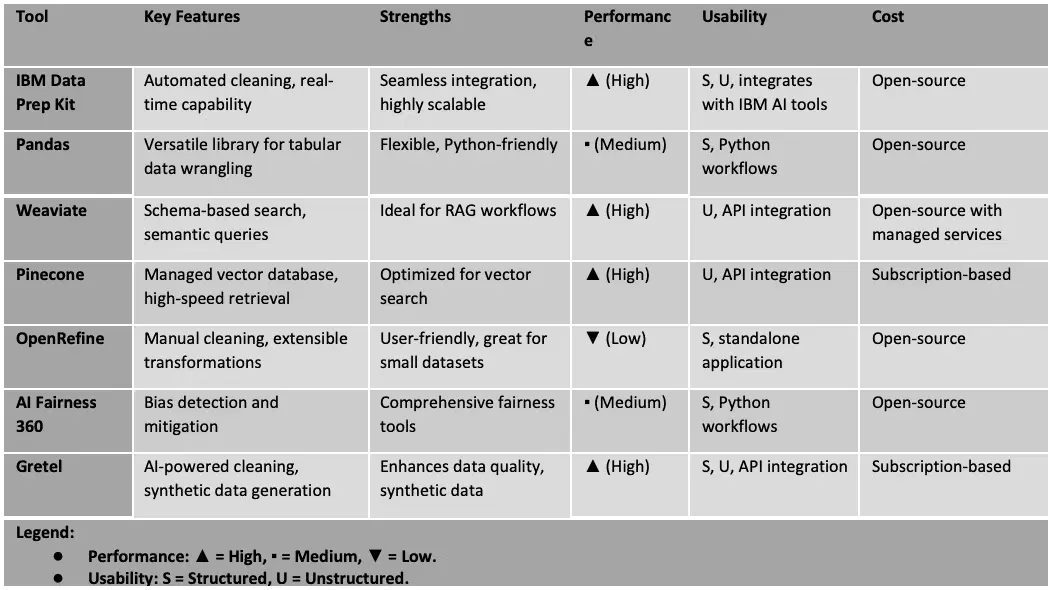
7、数据清洗工作流对比:微调 vs. RAG 检索
微调和检索增强生成(RAG)的数据清洗工作流对比突显了针对特定 AI 应用量身定制的不同目标和方法论。两种工作流都从原始输入数据开始,经过针对性的清洗和预处理。在微调中,重点在于去重和归一化,以确保高质量嵌入用于有效的模型训练。相反,RAG 工作流优先考虑噪声移除和 PII 清洗,以维护隐私和优化检索系统。通过并排比较这些工作流,我们理解了数据清洗如何适应不同的用例,从而实现准确的模型微调和高效的检索系统,用于实际 AI 部署。
8、结束语
数据清洗不再只是一个初步步骤;它是构建成功 AI 工作流的基石。对于 LLM 微调,干净的数据集能够实现更好的泛化能力和领域特定学习,确保模型提供准确且有意义的输出。在 RAG 架构中,干净的嵌入直接影响检索质量,决定了用户体验的顺畅与否。
通过利用像 IBM Data Prep Kit 这样的先进工具、集成实时清洗等新兴趋势以及应对偏见和噪声等挑战,实践者可以显著提高其 AI 系统的可靠性和性能。干净的数据不仅能改善指标;它还能建立信任并确保合规性,为可扩展和合乎道德的 AI 应用铺平道路。
原文链接: Mastering Data Cleaning for Fine-Tuning LLMs and RAG Architectures
汇智网翻译整理,转载请标明出处
