基于 A2A 协议的信用验证平台
我构建了 VerifyIQ——一个信用和就业验证平台,每个数据提供者作为 AI 智能体运行在自己的容器中。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我见过的大多数"多智能体"应用都遵循相同的模式:导入智能体 A,导入智能体 B,调用 A 然后 B,完成。它被贴上"多智能体"的标签,但在实践中只是多了额外步骤的顺序函数调用。
真正的分布式系统不是这样工作的。其他团队或其他公司不会让你导入他们的信用评分逻辑或薪资验证源代码。你通过网络边界调用他们的 API,获得响应——并处理它们缓慢、错误或完全宕机的情况。
所以我构建了 VerifyIQ——一个信用和就业验证平台,每个数据提供者作为 AI 智能体运行在自己的容器中。每个智能体在启动时自行注册。编排器直到向注册表查询时才知道它们的存在:"谁能做 credit_score?"
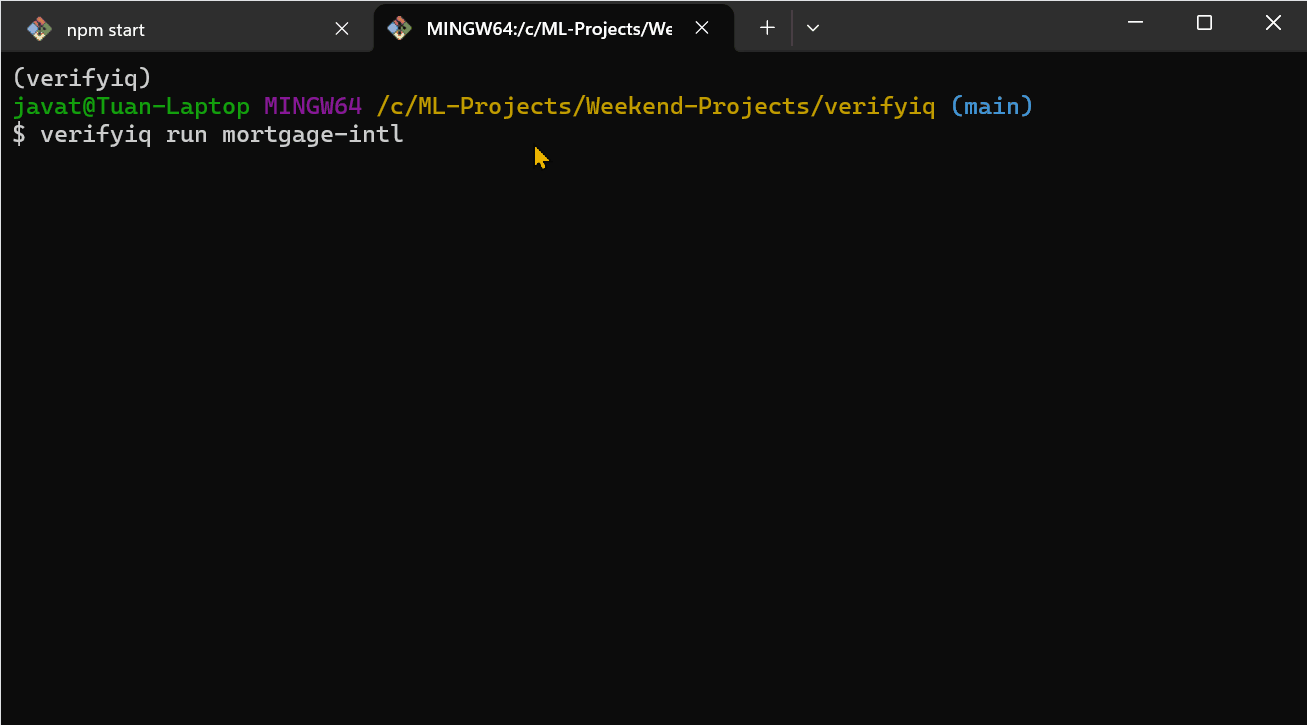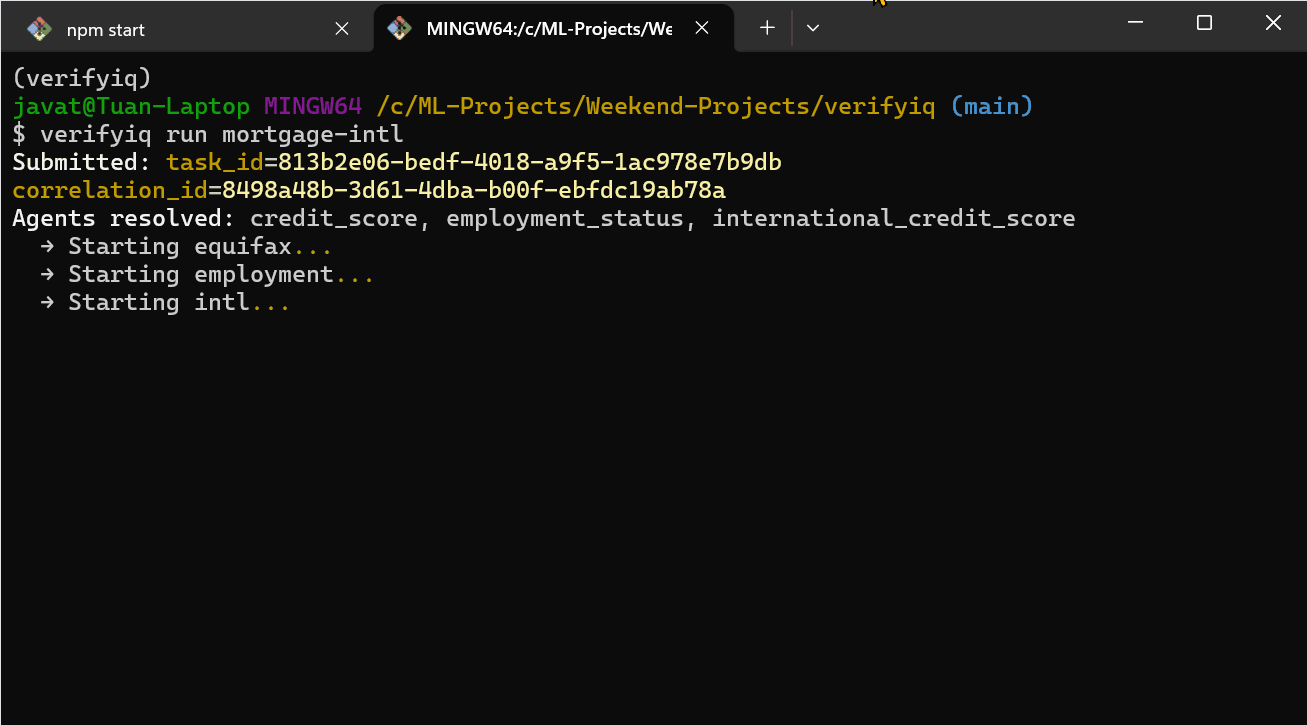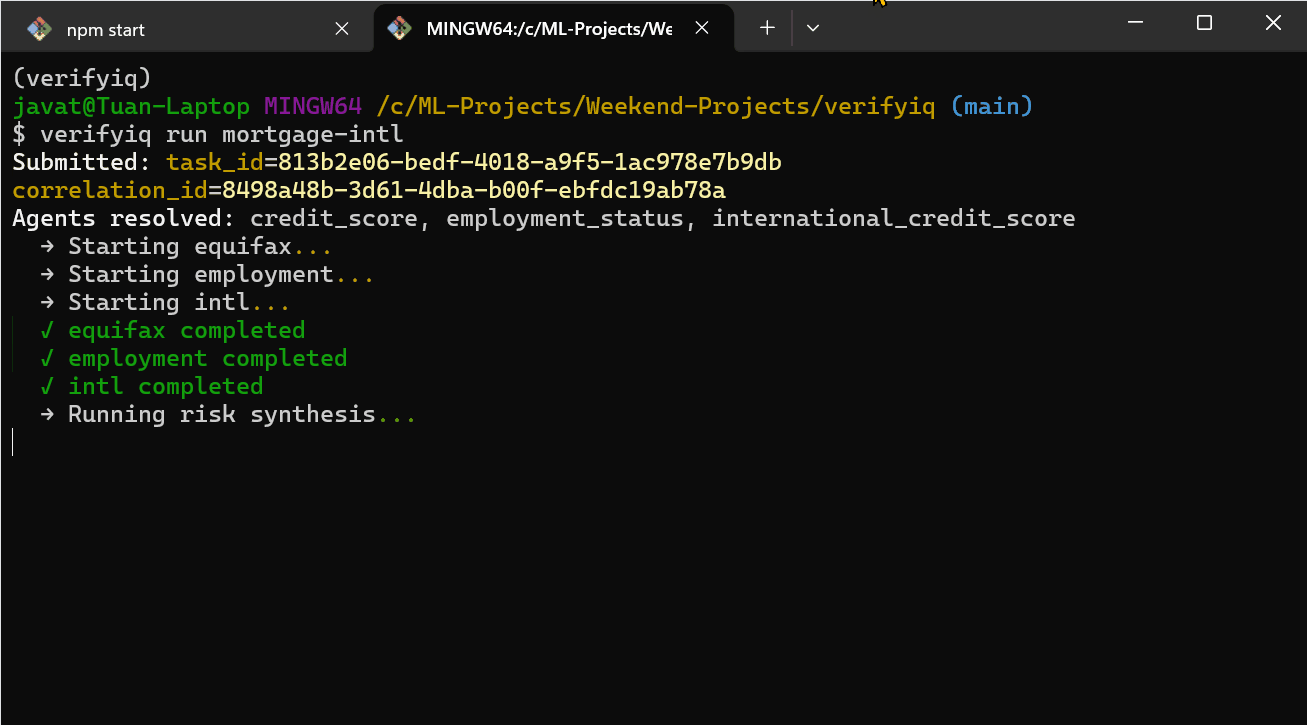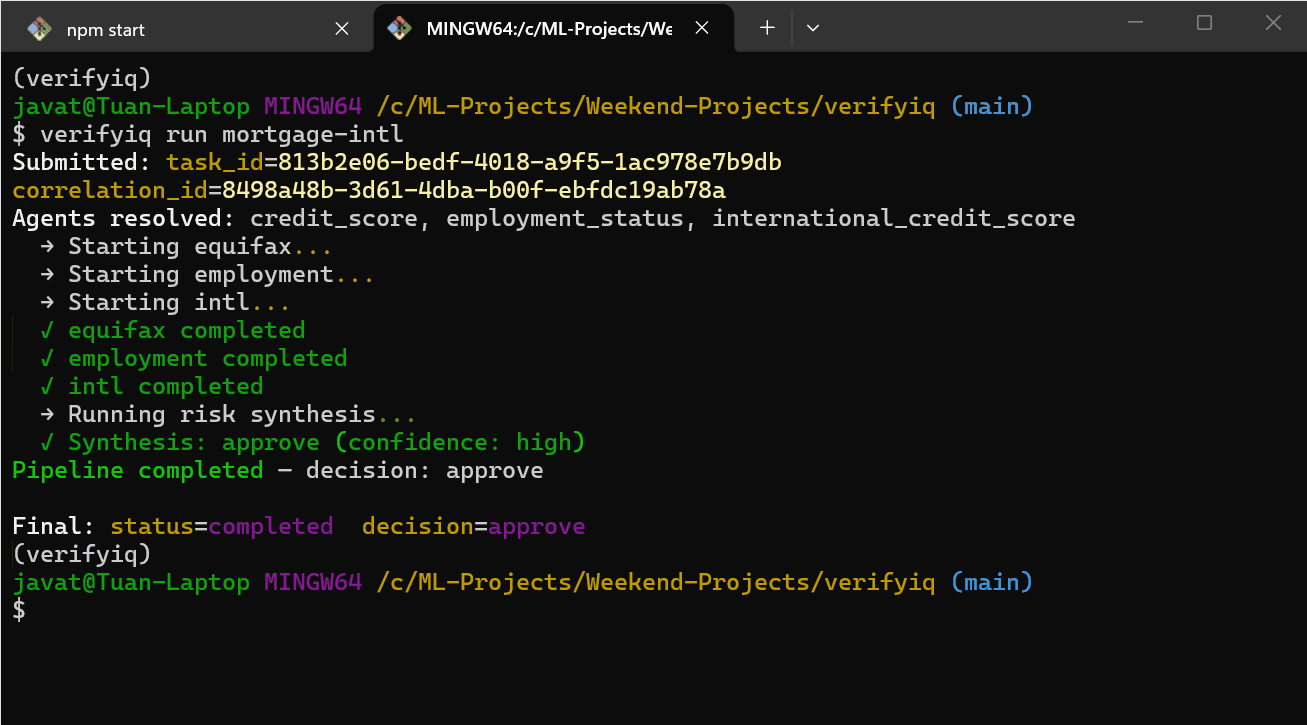
没有硬编码的 URL。没有跨服务导入。如果一个智能体宕机了,其余的继续运行。当新的提供者出现时,它可以插入而无需更改编排器。当出现问题时——这是不可避免的——系统仍然会产生决策,只是信心降低。
什么是编排器、注册表和风险综合?继续阅读。
1、架构设计
以下是架构的样子:
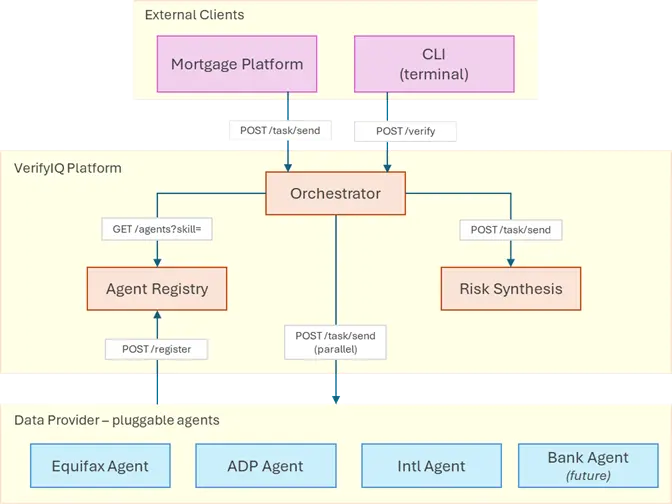
共有三层:
- 外部客户端(抵押贷款平台、CLI)通过 A2A 或普通 HTTP 调用 VerifyIQ。
- VerifyIQ 的核心(编排器、注册表、风险综合)处理协调、发现和最终决策。
- 数据智能体是可插拔的:每个都模拟生产中真实的征信局 API(Equifax、ADP、Nova Credit)。添加新数据源(例如 Bank of America 智能体、GoodHire 智能体)意味着部署新容器,而不是更改编排器。
智能体注册表是一个目录服务,智能体在其中注册自己。它存储每个智能体的联系信息和技能(以 JSON 智能体卡片形式),以便编排器可以查找该调用谁。
编排器是协调者,从注册表查找智能体,向它们发送任务(并行或顺序),处理超时和重试,并向 CLI 报告进度。它路由工作但从不自己做工作。
风险综合是最终的智能体,收集所有其他智能体的结果,根据用例进行加权,并产生单一的风险决策(批准、审核或拒绝),附带评分和解释。
docker compose up 启动核心平台和所有数据智能体。抵押贷款平台作为外部调用者,通过 docker compose --profile uc5 up 单独启动,因为它代表一个不同的组织。
▣ 查看我的仓库 https://github.com/tuangatech/verifyiq
2、为什么不只是链式调用一些 LLM?
最简单的版本可能只需 50 行 Python。调用一个 LLM 获取信用数据,调用另一个获取就业数据,调用第三个进行综合。发布它。
但问题是——当你试图真正这样做时,那个版本就崩溃了。在现实世界中,这些数据源是不同的公司。不同的代码库、不同的团队、不同的正常运行时间保证:

你不能把 Equifax 的逻辑导入你的代码库。你调用他们的 API,获得响应,并处理它——包括当他们缓慢、错误或完全宕机时。
VerifyIQ 将此建模为一个验证聚合器。你可以参考上面的设计,平台拥有三样东西:编排器(协调)、风险综合(决策引擎)和智能体注册表(发现)。本项目中的数据智能体(信用、就业、国际)是与外部提供者的集成点。在生产中,一家公司(例如 ADP)可以运行自己的 A2A 兼容智能体并自行注册。编排器不需要改变——它按技能发现智能体,而不是按名称。
每个智能体:
- 运行在自己的容器中
- 有自己的 LLM 提示和验证逻辑
- 在启动时向智能体注册表注册自己
- 对其他智能体一无所知
- 可以独立替换、重新部署或更新
编排器不知道智能体 URL。它向注册表询问:"谁能做 credit_score?" 并在运行时获得答案。明天部署一个更快的信用智能体,注册它,编排器会自动路由到它。
这引出了一个明显的问题。
3、"等等,数据到底从哪里来?"
确实,这里没有真正的 Equifax 或 ADP API(我只是用它们的名字让事情看起来正式)。每个智能体使用 LLM(通过 OpenRouter)生成逼真但虚构的数据。信用智能体用一个人的画像提示 LLM,获得一个合理的 FICO 分数、未结账户、利用率、不良记录。就业智能体对收入和任期做同样的事。国际智能体生成带有本地评分映射到美国等价物的外国信用档案。
数据源不是重点。重要的是数据周围的一切:智能体如何验证它,编排器如何在失败时处理它,综合如何对部分结果进行推理。这才是真正的工程所在。而且无论数据来自 LLM 还是 Equifax 的实际 API,它的工作方式都一样。
现在让我们看看将所有这些连接在一起的协议。
4、A2A 协议:智能体如何对话
协议有意保持简单。编排器发送一个任务,智能体做工作,返回一个结果。两种类型处理整个事情:
class A2ATask(BaseModel):
task_id: str
correlation_id: str # 同一个请求中所有任务相同
skill: str # 你想让智能体做什么
input: dict
timeout_ms: int = 30000
attempt: int = 1 # 1 = 第一次尝试, 2 = 重试
class A2ATaskResult(BaseModel):
task_id: str
correlation_id: str
status: Literal["completed", "failed", "timed_out"]
artifact: dict | None
error: AgentError | None
started_at: str
ended_at: str
每个智能体暴露 POST /tasks/send 和 GET /tasks/{task_id}。这就是整个契约。编排器不在乎智能体内部使用 LangGraph、一个简单函数还是一个仓鼠轮。它发送任务,获得结果。
correlation_id 至关重要——它在单个验证请求的每个任务中都是同一个 UUID。当出现问题时,一条 grep 命令就能重建整个执行追踪:
docker compose logs | grep "corr-abc123"
不需要分布式追踪系统。一个 ID,到处都是。
到目前为止很无聊。有趣的部分是当你需要同时使用三个智能体——而其中一个没有返回时。
5、扇出:并行调用智能体
抵押贷款验证需要信用、就业和国际数据。顺序调用意味着 30 多秒的等待。并行调用意味着你只需等待最慢的智能体。
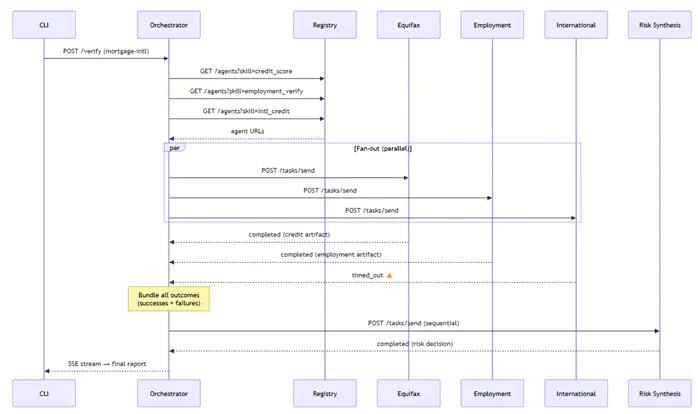
6、花费最长时间的部分:处理失败
在演示中,一切正常。在现实中,智能体可能会失败、超时和返回垃圾数据。我的设计规则是:总是生成报告,即使出了问题。
系统跟踪四种不同的任务状态:
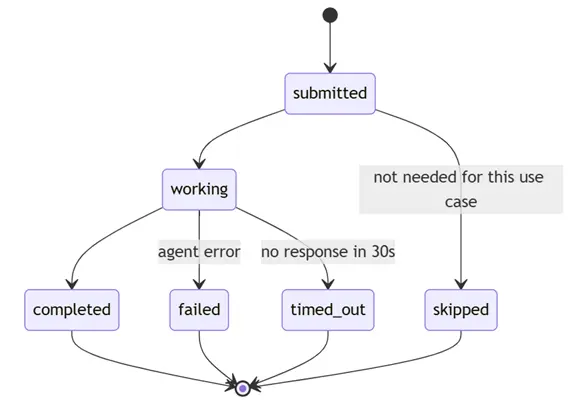
timed_out 和 failed 是刻意分开的。超时意味着基础设施出了问题——不要惩罚被验证的人。失败可能意味着数据不好或逻辑错误——那是真正的数据缺口。
当收集到结果时,编排器将所有内容——成功和失败——打包成结果包:
[
{ "agent": "equifax", "status": "completed", "artifact": {...} },
{ "agent": "employment", "status": "completed", "artifact": {...} },
{ "agent": "intl", "status": "timed_out", "artifact": null,
"error": { "code": "TIMEOUT" } }
]
整个结果包发送给风险综合智能体。综合 LLM 提示明确教模型如何对部分数据进行推理:
结果状态解释:
- "completed":使用工件数据进行你的分析
- "timed_out":瞬时基础设施问题;降低信心;不要惩罚对象
- "failed":数据缺口;在 risk_flags 中注明;降低信心
- "skipped":智能体未被调用;不要提及它
结果?当国际智能体超时时,系统不会崩溃或什么都不返回。它会说:"目前无法评估外国信用风险。信心降低。建议人工审核。" 这就是一个真正的风险分析师会说的话。
这是大多数多智能体教程完全跳过的部分。让智能体工作很容易。让编排器优雅地处理它们的失败才是真正的工程。
7、A2A 智能体内部的 LangGraph
大多数智能体很简单:获取任务、调用 LLM、返回结果。就业智能体不是。就业验证有真正的分支逻辑:检查某人目前是否在职。如果不是,查找前雇主。然后验证收入、计算任期。
LangGraph 很好地处理了这一点——带有条件边的有状态图:
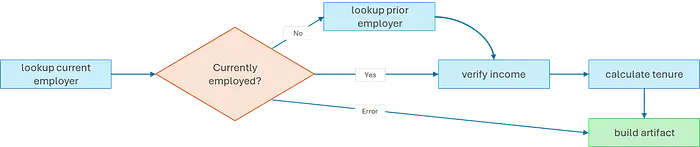
graph = StateGraph(EmploymentGraphState)
graph.add_node("lookup_current_employer", lookup_current_employer)
graph.add_node("lookup_prior_employer", lookup_prior_employer)
graph.add_node("verify_income", verify_income)
graph.add_node("calculate_tenure", calculate_tenure)
graph.add_node("build_artifact", build_artifact)
graph.set_entry_point("lookup_current_employer")
def route_after_employer_check(state):
if state.get("error"):
return "build_artifact" # 出错时短路
if state.get("currently_employed"):
return "verify_income" # 跳过前雇主查找
return "lookup_prior_employer" # 回退路径
graph.add_conditional_edges(
"lookup_current_employer",
route_after_employer_check,
{...}
)
但关键点是:编排器不知道涉及 LangGraph。它向就业智能体发送 POST /tasks/send 并获得一个 A2ATaskResult。该智能体使用 LangGraph、一个简单函数还是三个连续的 LLM 调用,都是内部实现细节。
这就是 A2A 的回报:框架无关的互操作。信用智能体是纯 FastAPI。就业智能体是 LangGraph。从外部看,它们完全一样。没人在乎内部是什么。
8、注册表:智能体如何找到彼此
每个智能体在启动时注册自己:
@asynccontextmanager
async def lifespan(app: FastAPI):
# 启动:向注册表注册
async with httpx.AsyncClient() as client:
await client.post(f"{registry_url}/register", json={
"name": "Equifax Credit Agent",
"url": "http://equifax:8001",
"skills": ["credit_score", "tradeline_summary", ...],
...
})
yield
# 关闭:注销
async with httpx.AsyncClient() as client:
await client.delete(f"{registry_url}/agents/{url_hash}")
编排器在运行时将技能解析为 URL,选择最快的健康候选者:
class AgentResolver:
async def find(self, skill: str) -> str:
response = await client.get(
f"{self.registry_url}/agents", params={"skill": skill}
)
candidates = [a for a in response.json() if a["health"] == "healthy"]
# 偏好观察延迟较低的智能体
candidates.sort(key=lambda a: a.get("avg_latency_ms") or float("inf"))
return candidates[0]["url"]
每次调度后,编排器将观察到的延迟报告回注册表。注册表维护一个指数移动平均,因此最近的性能权重更大。随着时间推移,如果两个智能体(例如 Equifax 和 Experian)都提供 credit_score,解析器自然路由到更快的那个。
编排器代码中从不写入任何智能体 URL。这意味着:
- 部署具有相关技能的新智能体 → 立即可用
- 替换智能体 → 编排器在下次请求时发现它
- 更快的智能体出现 → 随着延迟平均下降,逐渐赢得更多流量
- 智能体宕机 → 优雅关闭时注销;编排器不会尝试调用它
这就是聚合器模型的回报。假设一家银行想添加银行对账单分析作为新数据源。第三方提供者——或内部团队——构建一个新智能体,提供 bank_statement_analysis 技能。它在启动时向注册表注册。发现是自动的——编排器可以立即找到新智能体。你仍然需要将新技能添加到相关用例路由计划中(get_agent_plan() 中几行代码),但不需要其他编排器逻辑更改。不需要重新部署现有智能体。注册表就是集成面——新提供者插入它。
竞争提供者也可以工作。如果 Equifax 和 TransUnion 都注册了提供 credit_score 的智能体,解析器选择更快、更健康的那个。切换提供者是配置问题,不是代码更改。
这处理了后端。但管道需要 10-30 秒,没人想盯着空白屏幕。
9、SSE 流式传输:实时进度
没有实时进度,你提交请求然后等待。编排器通过在每个里程碑流式传输服务器发送事件来解决这个问题:
agents_resolved → "为此请求找到 3 个智能体"
agent_started → "正在调度到 Equifax..."
agent_completed → "信用报告已收到"
agent_completed → "就业验证完成"
agent_failed → "国际智能体超时"
synthesis_started → "正在运行风险综合..."
synthesis_completed → "决策:批准(信心:高)"
completed → 完整报告可用
CLI 使用 Rich 在终端中渲染为实时时间线。
SSE 是标准 HTTP——任何 Web 前端都可以通过浏览器的 EventSource API 使用它。编排器不在乎谁在监听。
到目前为止,编排器一直在向外调用智能体。但当有人调用你时会发生什么?
10、编排器作为 A2A 服务器:当有人调用你时
在生产中,抵押贷款公司不会运行 CLI 命令。他们会程序化地调用 VerifyIQ——发现能力、提交任务、轮询结果。这是编排器的被调用者角色:从你无法控制的服务接收 A2A 任务。
我构建了一个独立的抵押贷款平台服务——一个运行在 :9000 的纯 FastAPI + httpx 应用,对 VerifyIQ 代码库零导入。它只知道 A2A 线路协议:
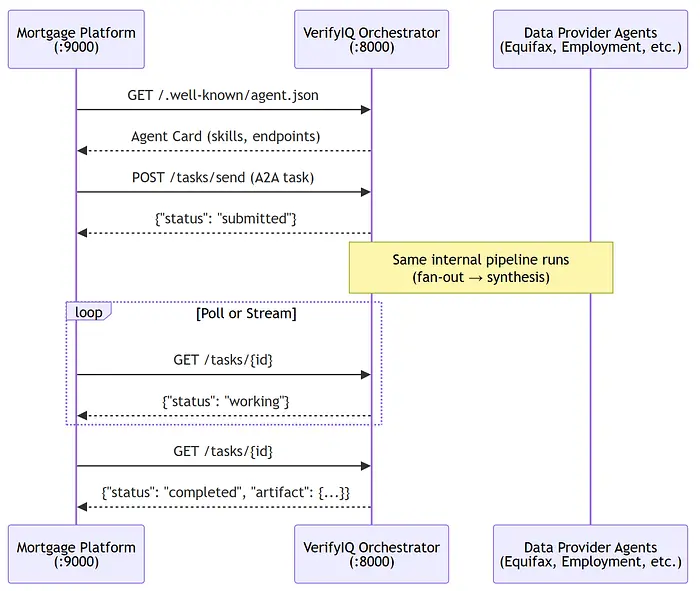
11、为什么用 CLI 而不是 Web UI?
VerifyIQ 使用由 Typer 和 Rich 构建的终端 CLI。没有 Web 前端。
产品是后端服务,不是消费者应用。 VerifyIQ 真正的"产品"是编排器的 API。CLI 是行使该 API 的客户端。对我们后端团队来说,我们可以在终端中更快地调试智能体管道、运行验证场景或检查审计追踪。CLI 为我们提供实时流式传输、丰富的表格和格式化报告,零前端开销。
Web UI 只是同一 API 的另一个客户端——它不替代 CLI,而是补充它。前端团队将为贷款专员开发和部署 Web 应用。
对于面向非技术用户的真正产品,你需要 Web UI。但驱动 CLI 的同一个 SSE 端点可以在不需要后端更改的情况下通过 EventSource 驱动浏览器仪表板。后端不在乎谁在消费流。
12、太多框架了
LangGraph、MCP、A2A、普通函数——诱惑是到处使用一切。一个问题可以穿透它:"这是否跨越了组织或部署边界?"
- A2A 用于服务之间——跨越进程/网络边界的所有智能体间通信
- LangGraph 在智能体内部——当内部逻辑需要状态分支或条件路径时(就业智能体的"当前在职?"分支)。它还可以处理重试、检查点和人在环中,不过 VerifyIQ 还不需要这些。
- 普通函数 是直接、线性逻辑的默认选择。VerifyIQ 的智能体对其内部工具使用普通的类型化 Python 函数
- MCP 在工具边界——当你需要跨运行时或团队标准化工具访问(模式、权限、可移植性)时。VerifyIQ 不使用 MCP,因为所有工具都是单个智能体内部的,但在工具跨团队共享的生产系统中,MCP 会替代普通函数
经验法则:从函数开始。当需要状态分支时提升到 LangGraph。当跨越服务边界时提升到 A2A。
13、这不只是信用验证
平台是模拟的。模式不是。同样的架构适用于你扇出到多个提供者并综合结果的任何地方:保险理赔(医疗记录 + 警方报告 + 修理估算),供应链合规(工厂审计 + 运输日志 + 海关数据),KYC 入驻(身份 + 制裁筛查 + PEP 检查)。换掉 LLM 提示和 Pydantic 模式,编排层原样工作。
聚合器模型是关键洞察。VerifyIQ 的价值不在于拥有数据——而在于编排数据。新数据源?部署一个容器,注册一个技能,在用例路由计划中加一行。银行对账单智能体、制裁筛查器、社交媒体风险评分器——它们都以相同方式插入。编排器的核心逻辑——发现、扇出、失败处理、综合——保持不变。
被调用者模式意味着运行在协议契约后面的内部管道的任何服务都可以作为子智能体嵌入更大的系统中。抵押贷款平台证明了这一点:VerifyIQ 的整个管道对调用者是透明的。它发送任务,获得决策。
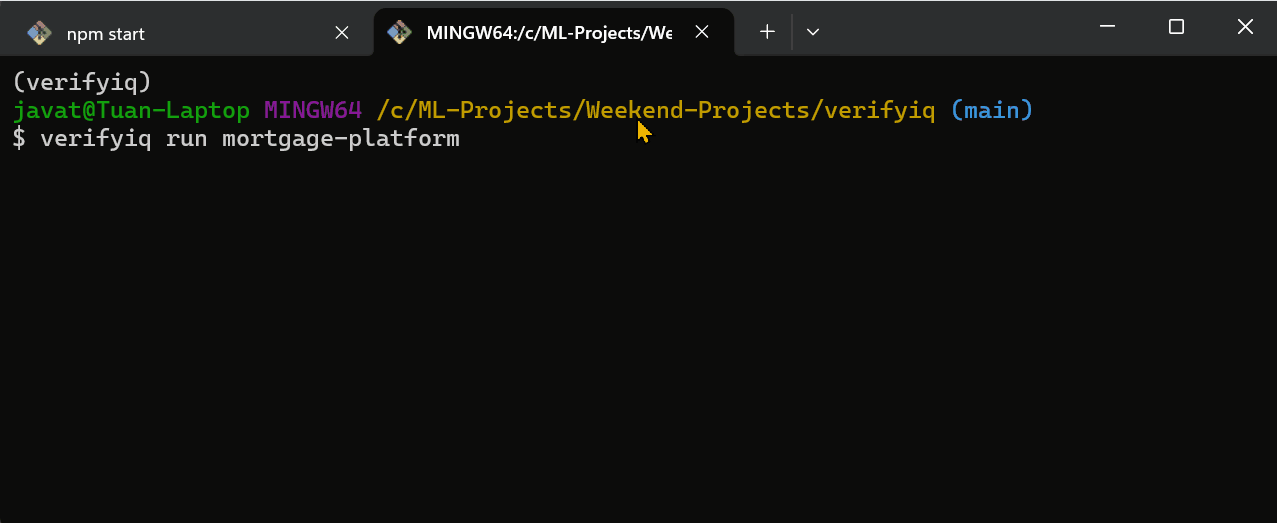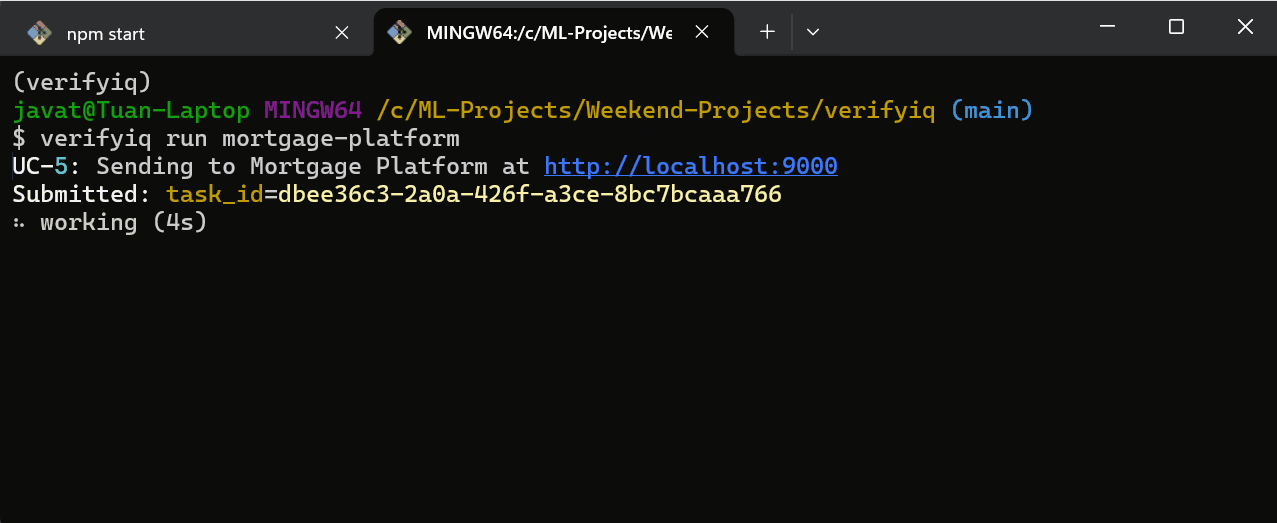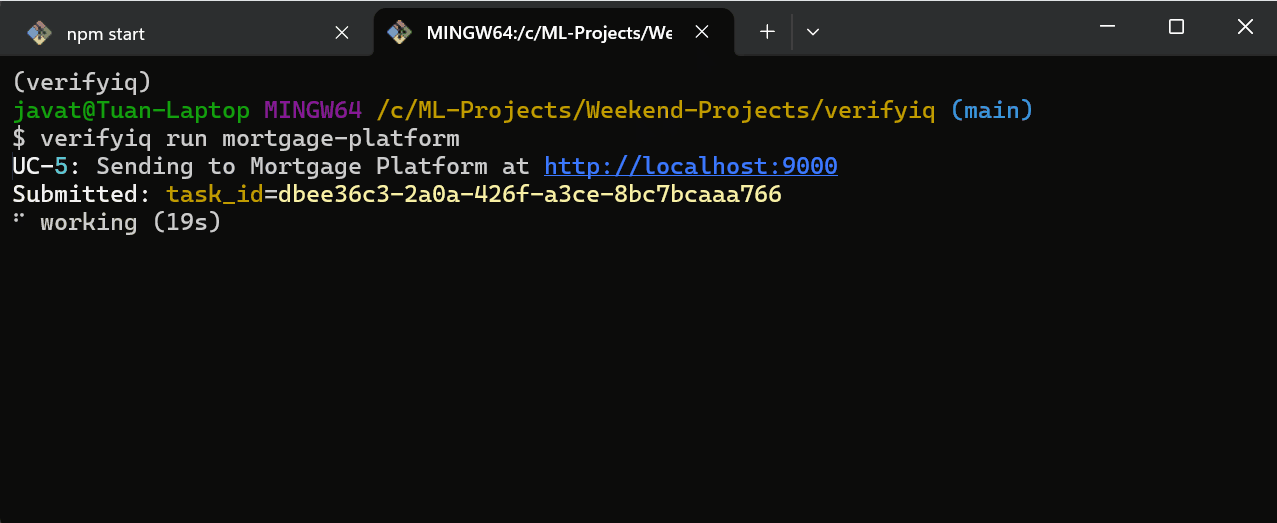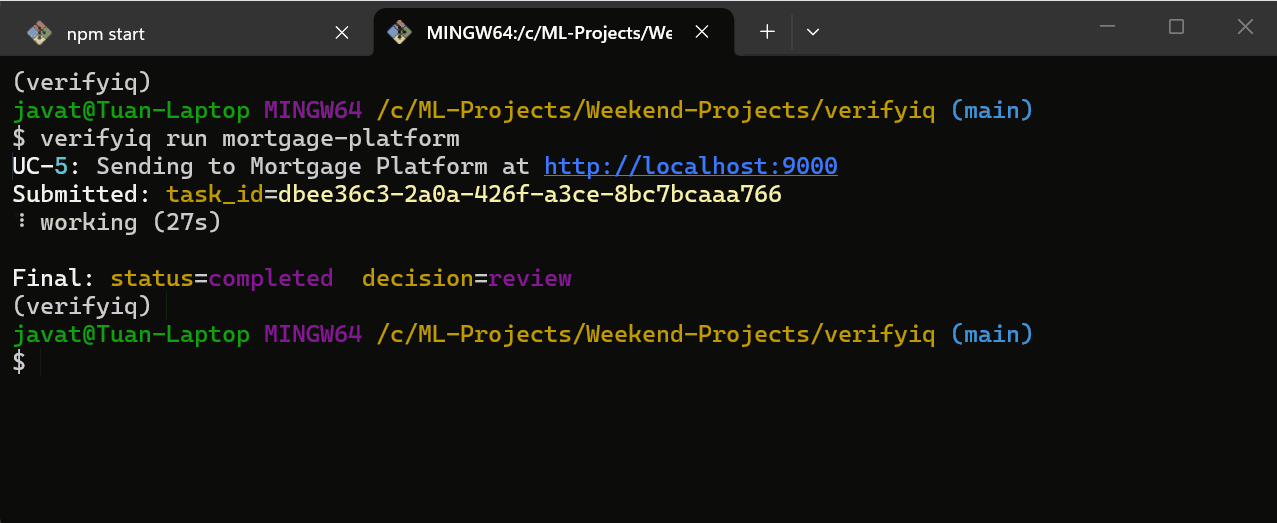
源代码在 GitHub 上。docker compose up,安装 CLI,运行 verifyiq run mortgage-intl。观看智能体注册、被发现、并行扇出并产生风险决策。
原文链接: A Credit Verification Platform Built on A2A Protocol
汇智网翻译整理,转载请标明出处
