ACE:智能上下文工程
ACE 展示了一条全新的发展路径:模型通过不断演化上下文来提升自身性能,而非重新训练权重。
AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
如果模型能够通过不断演化其上下文而非权重来实现持续的自我改进,那会怎样?
这正是智能上下文工程 (ACE) 所实现的。
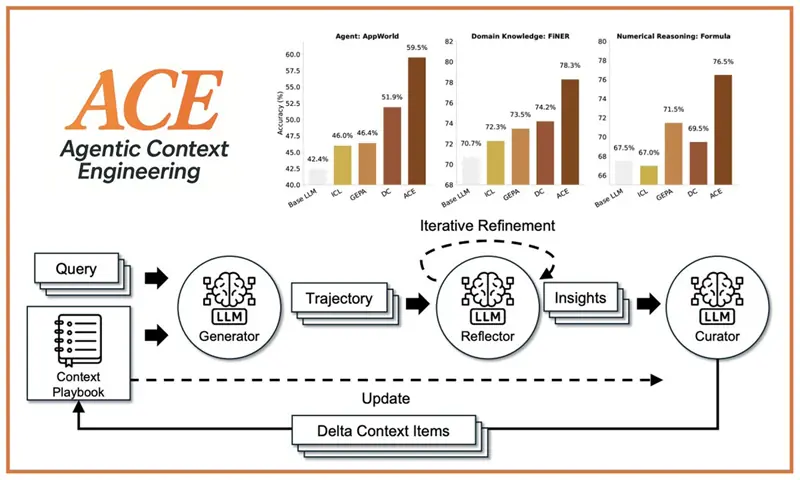
ACE 是一个全新的框架,它将模型的上下文视为一个鲜活的、不断演化的剧本——通过生成、反思和策略性管理,随着时间的推移而不断改进。
结果令人惊叹:
- 智能体任务性能提升 10.6%
- 金融推理能力提升 8.6%
- 延迟降低 86.9%,成本降低 83.6%
- 适用于任何 LLM(开源或闭源)
- 生成易于理解的学习结果,并支持选择性遗忘
这是一种无需调整权重即可实现 LLM 自监督学习的方法。
在本文中,我将用简单的语言解释 ACE,并提供示例和代码,以便您了解其工作原理以及如何立即使用它。

1、ACE 解决了什么问题?
当前的 LLM 自适应方法通常依赖于:
- 微调,成本高昂且耗时
- 长时间的系统提示,随着时间的推移会失效
- 临时记忆,容易出现噪声或冗余
ACE 通过建立一个结构化的、不断演进的上下文(即“剧本”)来解决所有这三个问题。每次模型出错或识别出新模式时,该剧本都会变得更加智能。
可以把它想象成用于逻辑推理的 Git。
ACE 不会重写提示,而是根据智能体学习到的内容进行增量更新——即小的、有针对性的修改。
2、ACE 的工作原理
ACE 使用三个智能体角色运行,每个角色都有特定的任务:
生成器:
- 处理任务,生成推理路径,输出错误和成功结果。
反射器。读取这些路径并提取:
- 有用的策略
- 模式
- 陷阱
- 需要避免的错误
管理员。使用以下方法更新剧本:
- 去重
- 修剪
- 合并
- 有益/有害的计数器
这确保了剧本稳步增长,并且永远不会变成无用信息。
3、行动手册概览
行动手册就是一个不断更新的结构化文本文件:
## STRATEGIES & INSIGHTS
[str-00001] helpful=5 harmful=0 :: Always verify data types before processing.
[str-00002] helpful=3 harmful=1 :: Consider edge cases in financial data.
## FORMULAS & CALCULATIONS
[cal-00003] helpful=8 harmful=0 :: NPV = Σ(Cash Flow / (1+r)^t)
## COMMON MISTAKES TO AVOID
[mis-00004] helpful=6 harmful=0 :: Don't forget timezone conversions.每个要点包含:
| 字段 | 含义 |
|---|---|
| ID | 稳定参考 |
| helpful/harmful | 计数随时间更新 |
| Content | 实际策略、洞察或公式 |
这使得“模型学习”可审计、可编辑和可解释。
4、ACE 的突破性意义
无需微调:
- ACE 仅使用提示和上下文演化即可调整模型。
极其高效。与强大的基线模型相比:
- 延迟降低 82.3%(离线)
- 延迟降低 91.5%(在线)
- 令牌成本降低 83.6%
高性能:
- 在 AppWorld 的复杂测试用例中,使用更小的开源模型,性能优于 GPT-4.1。
适用范围广泛:
- OpenAI、Together、SambaNova、DeepSeek、本地 LLM——ACE 与模型无关。
易于扩展:
- 只需三个函数即可接入新的领域。
5、安装和使用 ACE
克隆仓库:
git clone https://github.com/ace-agent/ace.git
pip install -r requirements.txt
cp .env.example .env
# Add your API keys to .envACE 基本设置:
from ace import ACE
from utils import initialize_clients
api_provider = "sambanova" # or openai / together
ace_system = ACE(
api_provider=api_provider,
generator_model="DeepSeek-V3.1",
reflector_model="DeepSeek-V3.1",
curator_model="DeepSeek-V3.1",
max_tokens=4096
)
config = {
'num_epochs': 1,
'max_num_rounds': 3,
'curator_frequency': 1,
'eval_steps': 100,
'online_eval_frequency': 15,
'save_steps': 50,
'playbook_token_budget': 80000,
'task_name': 'your_task',
'json_mode': False,
'no_ground_truth': False,
'save_dir': './results',
'test_workers': 20,
'use_bulletpoint_analyzer': False,
'api_provider': api_provider
}离线适配:
results = ace_system.run(
mode='offline',
train_samples=train_data,
val_samples=val_data,
test_samples=test_data,
data_processor=processor,
config=config
)在线适配:
results = ace_system.run(
mode='online',
test_samples=test_data,
data_processor=processor,
config=config
)仅评估:
results = ace_system.run(
mode='eval_only',
test_samples=test_data,
data_processor=processor,
config=config
)6、金融示例:FiNER / XBRL 公式
ACE 包含一个现成的运行器:
python -m finance.run \
--task_name finer \
--mode offline \
--save_path results或者在线运行:
python -m finance.run \
--task_name finer \
--mode online \
--save_path results或者仅评估:
python -m finance.run \
--task_name finer \
--mode eval_only \
--initial_playbook_path results/.../best_playbook.txt \
--save_path test_results7、将 ACE 扩展到你自己的领域
您只需实现一个轻量级的数据处理器。
最小示例:
class DataProcessor:
def process_task_data(self, raw_data):
return [{
"context": item["ctx"],
"question": item["q"],
"target": item["answer"],
"others": {}
}]
def answer_is_correct(self, predicted, ground_truth):
return predicted.strip() == ground_truth.strip()
def evaluate_accuracy(self, preds, truths):
correct = sum(self.answer_is_correct(p, t) for p, t in zip(preds, truths))
return correct / len(preds)完成此操作后,ACE 将处理:
- 并行评估
- 精选更新
- 剧本演化
- 日志记录
- 检查点
- 精选差异
其他一切都是自动的。
8、ACE 代表模型自适应的未来
ACE 展示了一条全新的发展路径:模型通过不断演化上下文来提升自身性能,而非重新训练权重。
这意味着:
- 更经济
- 更快速
- 更易于解释
- 更易于控制
- 更易于部署
随着 LLM 从基础聊天机器人发展为完全自主的系统,像 ACE 这样的框架将变得至关重要。
如果无权重学习成为标准,ACE 将是迈向这一目标的重要一步。
原文链接:Agentic Context Engineering (ACE): The Powerful New Way for LLMs to Self-Improve
汇智网翻译整理,转载请标明出处
