为数据分析管道增加编排层
在为企业合规分析构建的原型系统中,编排层位于用户界面和现有分析工具之间。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
多年来,仪表板一直是与数据交互的主要界面。它们呈现指标、可视化趋势,并通过图表和过滤器支持决策。但它们也要求用户解释结果、提出后续问题并手动调查根本原因。
如果这个调查层可以由系统驱动呢?
这就是编排变得关键的地方。
Agentic AI 系统通常以 tool calling 或大语言模型来描述。然而在实践中,决定性的转变不是工具本身——而是增加了一个编排层,它可以协调这些工具、决定下一步做什么,并迭代优化响应。
1、仪表板呈现数据,Agent 协调数据上的工作流
而且越来越多地,最接近数据的人——那些已经编写查询、定义指标并理解领域的人——正在构建这个协调层。不是因为工具需要深厚的 AI 专业知识,而是因为难点从来不是模型。永远是知道要对数据问什么问题以及按什么顺序问。
在我们继续之前,以下是核心论点的五个要点:
- Tool calling 是访问。编排是控制。能调用函数的 LLM 不是 Agent。能决定调用哪些函数、按什么顺序调用、以及如何处理结果的 LLM——那才是 Agent。
- 核心架构是一个循环——决定、执行、观察——可以用不到 40 行 Python 实现,并适用于任何 chat-completion LLM。
- 你不需要新组件。大多数数据团队已经有了 SQL 查询、管道和预计算的 ML 输出。编排协调你已有的东西。
- 在受限的企业环境中,领域特定工具优于通用插件。有清晰契约的精选工具胜过广泛工具包。
- 在原型中,需要约 15 分钟仪表板导航的多步骤调查在不到 30 秒的对话交互中完成。
2、Tool Calling vs 编排
许多现代系统支持 tool calling——LLM 调用预定义函数(如 SQL 查询或 API 端点)的能力。这很有用,但它本质上是单步执行:选择一个函数、运行它、返回输出。没有迭代、没有结果评估、没有自适应跟进。
编排不同。它管理工具如何跨多个步骤使用。如果说 tool calling 是单一反射,编排就是推理循环——有时称为 ReAct(推理和行动)模式:
- 解释用户的目标- 决定下一步行动(工具 + 参数)
- 执行工具- 观察结果- 用新证据更新上下文
- 重复直到目标满足——或达到轮次限制
这将执行从静态管道转变为有状态的决策过程。系统不再一步回答问题——它动态构建工作流,其中每一步都由前一步的结果提供信息。
在代码中,核心循环很紧凑:
def run_agent(goal, tools, call_llm, execute_tool, max_rounds=6):
messages = [
{"role": "system", "content": build_prompt_from(tools)},
{"role": "user", "content": f"Goal: {goal}"},
]
for round in range(1, max_rounds + 1):
response = call_llm(messages) # DECIDE
parsed = extract_json(response)
if parsed.get("action") == "final_answer":
return parsed["answer"] # DONE
action = parsed["action"]
params = parsed.get("params", {})
result = execute_tool(action, params) # EXECUTE
messages.append({"role": "assistant", "content": response})
messages.append({"role": "user", # OBSERVE
"content": f"Result of {action}:\n{result}\n\n"
f"Continue reasoning or return final_answer."})
return synthesize_from_partial_results(messages)
这与模型无关。它适用于 OpenAI、Anthropic、Databricks Model Serving 或任何支持 chat completions 的 LLM。智能不在循环结构中——而在 LLM 在每一步决定做什么,以及工具及其输出如何设计。
3、从分析管道到 Agentic 系统
Agentic 系统中使用的组件并不新鲜。大多数数据团队已经有了:
- 针对仓库表的 SQL 查询
- 转换和聚合数据的管道
- 预计算的 ML 输出(预测、评分、分类)
- 分析转换和 KPI 逻辑
这些不是需要获取的前提条件。它们是大多数分析组织中已经存在的资产。构建这些管道的团队——理解连接、边界情况、WHERE 子句中嵌入的业务逻辑——已经拥有了谜题中最难的部分。直到最近,他们还没有的是让这些资产在运行时组合的协调机制。
改变的是这些组件如何被协调。
没有编排:
> 用户 → 查询 → 结果
有编排:
> 用户 → 编排层 → 工具₁ → 评估 → 工具₂ → 评估 → … → 综合答案
4、实践中的架构
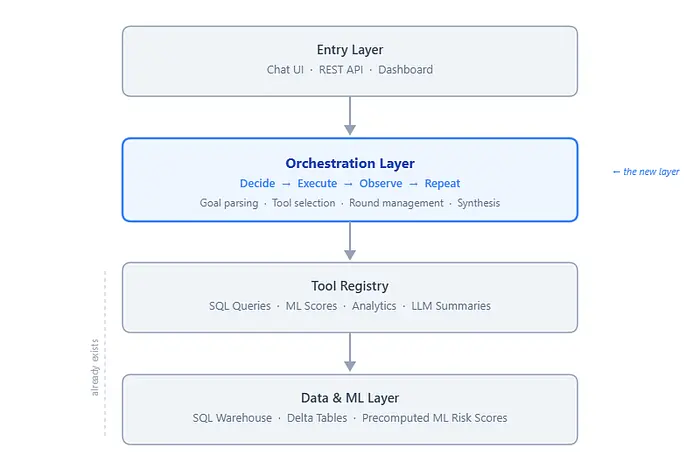
在为企业合规分析构建的原型系统中,编排层位于用户界面和现有分析工具之间。
系统有四层,每层有清晰的职责:
- 入口层——通过聊天 UI、REST API 或仪表板进行用户交互。
- 编排层——多步推理循环:目标解析、工具选择、轮次管理和结果综合。
- 工具层——约 20 个领域特定函数,提供对数据和计算的结构化访问,包括 SQL 支持的查询和 LLM 辅助的摘要。
- 数据与 ML 层——持久化和推理基础:SQL 仓库表、预计算的 ML 风险评分和 Delta 表。
5、工具作为单一注册表
一个关键的架构选择:所有工具定义在一个单一注册表中,它同时驱动 LLM 的 system prompt 和执行分发器。
TOOL_REGISTRY = [
{"name": "get_weekly_kpis",
"description": "Compliance KPIs for a specific week.",
"params": [{"name": "week_ending", "type": "date"}]},
{"name": "get_risk_scores",
"description": "ML-predicted risk levels for entities.",
"params": [{"name": "level", "type": "High | Medium | Low | All"}]},
{"name": "get_entity_history",
"description": "Recent activity history for a named entity.",
"params": [{"name": "name", "type": "string"}]},
{"name": "get_approval_flags",
"description": "Approvers with anomalous delay rates.",
"params": []},
# …
]
system prompt 在启动时从这个注册表生成。当 LLM 推理要调用哪个工具时,它看到的描述与分发器能执行的内容完全匹配。在一个地方添加工具;prompt 和分发逻辑保持同步。文档和实现之间没有漂移。
6、ML 作为数据,而非端点
第二个设计选择是将 ML 输出视为数据资产而非实时推理端点。风险评分由批量训练作业产生(在我们的案例中是对历史合规模式的随机森林),并写入表中。编排层像查询任何其他数据源一样查询该表。
这保持了 Agent 延迟较低,将 ML 生命周期与 Agent 生命周期分离,并提高了可观察性——你可以查询 Agent 使用的相同评分来验证其推理。
6、实践中的编排循环
抽象的架构很简单。以下是当经理提问时编排实际做的事情:
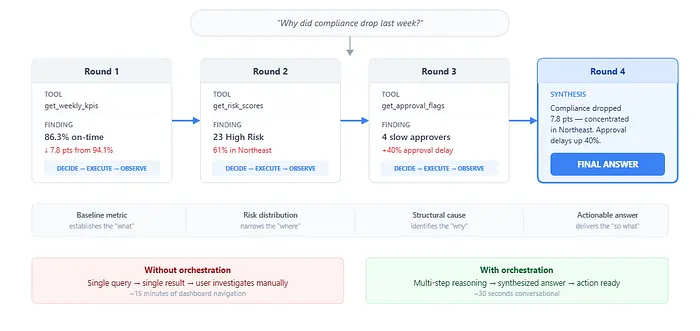
> *"为什么上周合规率下降了?"*
**第 1 轮 - 建立基线。**
LLM 选择 `get_weekly_kpis(week_ending="2026-03-07")`。
→ total_records: 847 | on_time: 731 (86.3%) | late: 93 | missing: 23 上一周: 94.1% - 下降 7.8 个百分点
系统现在知道合规率下降了,但数字不是解释。它继续。
**第 2 轮 - 识别下降集中在哪里。**
LLM 选择 `get_risk_scores(level="High")`。
→ 23 个实体标记为高风险 区域分布:东北地区占 23 个中的 14 个(61%) 平均连续迟到周数: 3.2
数据显示了地理集中性。东北地区占比过高。
**第 3 轮 - 调查结构性原因。**
LLM 选择 `get_approval_flags()` 来检查问题是在提交端、审批端还是两者。
→ 4 位审批人迟到率 >50%(过去 4 周) 其中 2 位在东北地区 平均审批延迟同比增加约 40%
现在 Agent 有了因果链:东北地区的审批延迟与合规率下降相关。
**第 4 轮 - 综合并回答。**
LLM 返回 `final_answer`:
>*合规率从上周的 94.1% 下降到 86.3%(-7.8 个百分点)。
下降集中在东北地区,该地区占 23 个高风险实体中的 14 个。
两位东北审批人的迟到率超过 50%,平均审批延迟比前一周增加约 40%。
建议:本周优先跟进东北经理的审批流程。*
这个答案需要四次操作,每次都建立在前一次之上。没有单一工具调用能产生它。调查路径——基线 → 风险分布 → 审批分析 → 综合——从数据中涌现,而非来自预定义的工作流。
执行相同调查的人类分析师会打开仪表板、按周过滤、扫描 KPI 瓷砖、切换到风险视图、按区域过滤、打开审批人报告、交叉引用两个视图并起草摘要。那至少是 15 分钟的手动导航。编排的 Agent 在不到 30 秒内完成了它。
7、编排不太有效的地方
编排最适合具有清晰分析路径的调查性问题——可以分解为数据检索和比较的问题。当问题需要主观判断或数据无法捕获的组织政治、仓库尚未反映的实时数据、或超出相关性的因果推理时,它变得不太有效。
承认这些边界很重要。编排扩展了分析系统能自主做的事情。它不能替代人类对模糊或高风险决策的判断。
8、塑造系统的设计决策
- 每轮一个工具。模型被指示每个 LLM 响应调用一个工具。这使循环可预测、可调试且易于记录。代价是延迟——4 工具调查需要 4 次 LLM 往返。在实践中,大多数查询在 2-3 轮内解决,我们的 p95 响应时间保持在 8 秒以下。
- 有界的轮次。无界循环是可靠性风险。如果 LLM 混淆了,有界的循环(我们用 6 轮)确保系统仍然返回有用的东西。当达到上限时,系统从收集到的任何内容综合摘要,而不是返回错误。
- 服务器端日期解析。早期且持续的问题:LLM 幻觉日期。"上周"可能产生两周前的星期五。我们通过在服务器端确定性地解析所有时间引用来解决这个问题。LLM 仍然选择调用哪个工具并解释用户意图——我们只覆盖具体日期。这种混合模式(LLM 负责推理,确定性代码负责事实)被证明是必不可少的。
- 格式化输出优于原始 JSON。早期工具实现返回原始 JSON。我们切换到带有上下文注释的格式化文本表(例如,"per server calendar"、"(14 of 23)"),LLM 综合质量显著提高。当工具输出类似于人类分析师在工作笔记中写的、而不是 API 会返回的东西时,LLM 推理得更好。
9、观察结果
在几周内迭代了编排设计、工具库和前端。原型的观察:
多步骤调查时间从约 15 分钟下降到约 30 秒。需要导航仪表板、过滤视图和交叉引用报告的查询变成了单一的对话交互。
10 个标准合规问题中有 8 个无需人工干预即可回答。KPI 摘要、风险识别、审批人分析和经理简报自主解决。两个失败涉及模糊的时间引用——后来通过服务器端日期解析解决了。
每查询平均轮次:2.1。标准查询最大值:4。简单问题(KPI 查找)在 1-2 轮内解决。调查性问题("为什么 X 下降了?")需要 3-4 轮。
20 个领域工具覆盖了完整的分析面。我们从 8 个开始,增加到 20 个。最后的添加是细化(拆分同一指标的周度与范围变体),而非新功能。工具数量不是瓶颈——工具设计才是。每个工具的质量更多取决于对数据和业务上下文的理解,而非任何 LLM 特定的知识。
10、入门指南
如果你想在自己的分析数据上试验编排,这是一个实用的起点。
- 识别 3-5 个高频查询。从你的团队已经在回答的问题开始——分析师每周一运行的那些、每个冲刺刷新的仪表板。每个都变成一个工具:带清晰描述、类型化参数和 SQL 支持实现的命名函数。
- 实现循环。使用本文中的决定-执行-观察模式。它适用于任何 chat-completion LLM。循环与模型无关;智能来自工具和 LLM 对它们的推理。
- 尽早添加护栏。三个会节省调试时间的护栏:服务器端确定性日期解析、轮次上限(6 是好的默认值,到达时进行部分综合)、以及工具白名单以便只有注册工具可以执行。
- 迭代工具输出格式。工具返回给 LLM 的文本比你预期的更重要。带行数、日期范围和简要注释的干净表格比原始 JSON 产生更好的综合。
11、值得考虑的框架和工具
- LLM——OpenAI、Anthropic、Databricks Model Serving 或本地模型。任何 chat-completion API 都可以。
- 数据——Databricks SQL、SQLAlchemy 或直接针对仓库的 REST API。
- 编排——ReAct 循环约 40 行。LangChain 和 LlamaIndex 提供 Agent 抽象,但对于领域特定工具,自定义循环提供更多控制和更少的调试层。
- 前端——Flask 或 Streamlit 用于原型;React 用于生产。
- MCP(模型上下文协议)——将工具包装为 MCP 服务器使它们可被多个 AI 客户端(Cursor、Claude Desktop 等)访问,而无需耦合到单一提供商。
12、结束语
Agentic AI 系统通常与高级模型或新框架相关联。在实践中,核心架构转变更简单且更根本。
编排引入了一个控制层,决定使用哪些工具、按什么顺序、基于哪些中间结果。它将分析系统从静态管道转变为动态的、目标驱动的工作流。
从仪表板到 Agent 的转变不是替换现有组件。而是引入一个能协调它们的层——一个像分析师一样对数据推理的循环,但更快,且不需要用户知道去哪里看。
组件是熟悉的。架构是一个循环。重要的工作在于工具设计、护栏以及保持系统扎根于它能实际接触的数据的纪律。
随着 Agentic 系统成熟,竞争优势将不属于拥有最强大模型的人。它将属于对自己的数据、领域以及编码了多年机构知识的分析工作流有最深理解的人。编排层只是让这种理解变得可组合。
从循环开始。其余随之而来。
原文链接: Orchestration: The Layer That Transforms Dashboards into Agents
汇智网翻译整理,转载请标明出处
