智能体 Harness 就是架构
我的假设:Agent harness 工程——上下文管理、工具选择、错误恢复和状态持久化的设计——是 agent 可靠性的主要决定因素,而不是模型能力。在能力阈值之上,改进 harness 比更换模型能产生更好的回报。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我在每次工程会议、Slack 讨论和投资人路演中都听到同样的问题:"现在最好的模型是什么——GPT、Claude 还是 Gemini?" 我在过去几个月里构建和调试基于 agent 的系统,我认为这完全是一个错误的问题。证据已经非常明显:决定 AI agent 在生产环境中是否成功的不是它底部的模型,而是围绕它的基础设施。
我将阐述我的假设,用三个独立的案例研究(有已发表数据支持)来验证它,并向你展示行业正在向何处收敛。本文中的每一个声明都有已发表的来源支持——工程博客、同行评审论文,或来自有直接访问权限的媒体报道。
我的假设:Agent harness 工程——上下文管理、工具选择、错误恢复和状态持久化的设计——是 agent 可靠性的主要决定因素,而不是模型能力。在能力阈值之上,改进 harness 比更换模型能产生更好的回报。
简要总结:
- APEX-Agents 基准测试在真实专业任务(银行、咨询、法律)上测试了前沿模型。最佳 pass@1:24.0%。Pass@8:~40%。失败主要是编排问题,不是知识缺口 [1]。
- Vercel 删除了其 agent 80% 的工具(从15个减少到2个)。在一个5查询基准测试中,准确率从80%跃升到100%,token 下降37%,速度提升3.5倍。样本虽小,但方向惊人 [2]。
- Manus 四次重建了他们的 agent 框架,最大的收益来自于删除面向用户的复杂性,同时添加有针对性的基础设施(上下文压缩、logit 掩码)。他们平均每个任务约50次工具调用,并使用文件系统作为外部内存 [3]。
- OpenAI、Anthropic 和 Manus(2025年底被 Meta 收购 [9][19])都独立地得出了相同的见解:更简单的 harness 加上更好的模型胜过复杂的编排 [4][5][6]。
- 结论:假设成立,但有一个重要限定——它适用于模型能力底线之上。在该底线之下,没有 harness 能补偿推理不足。在该底线之上,harness 工程主导结果。
1、定义 Harness
在继续之前,让我定义我所说的harness。OpenAI 最近发表了一篇题为"Harness Engineering"的博客文章 [4],Martin Fowler 发表了对该概念的分析 [7]。这个术语正在获得关注,但这里有一个精确的技术定义:
Agent harness 是一个封装基础模型并控制五个方面的基础设施层:
- 上下文管理——什么进入模型的上下文窗口,以什么顺序,以及什么被驱逐
- 工具选择——模型可以调用哪些能力,以及这些接口如何设计
- 错误恢复——系统如何处理失败的工具调用、推理死胡同和重试逻辑
- 状态管理——agent 如何在回合、会话和上下文窗口边界之间持久化进度
- 外部记忆——如何在上下文窗口之外存储和检索信息
把模型想象成引擎,harness 想象成汽车。行业多年来一直在争论谁拥有最好的引擎。几乎没有人建造一辆能保持在道路上的汽车。
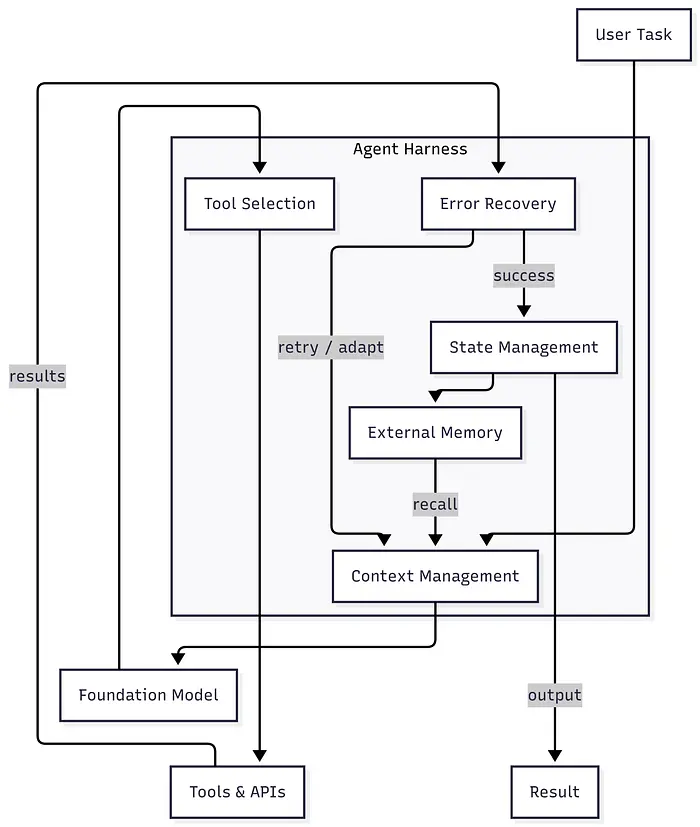
Agent harness 架构组件
2、打破幻觉的基准测试
基准分数和实际性能之间的脱节一直是行业中的一个笑料。模型在编程谜题和多选测试中得分超过90%,但在周二早上分析师做的那种工作上却失败了。
2026年1月,Mercor 发表了APEX-Agents [1],这个基准测试做了一些不同的事情:它在真实专业工作上测试 agents。不是编程谜题。不是琐事。投资银行分析师、管理顾问和企业律师执行的实际任务——这种工作需要人类1-2小时,并在多天接触中涉及浏览文档、电子表格、PDF、电子邮件和日历。
基准测试包含480个任务,跨越33个不同的"世界"——10个银行,11个咨询,12个法律——每个模拟5-10天的客户接触,平均每个世界166个文件。
结果
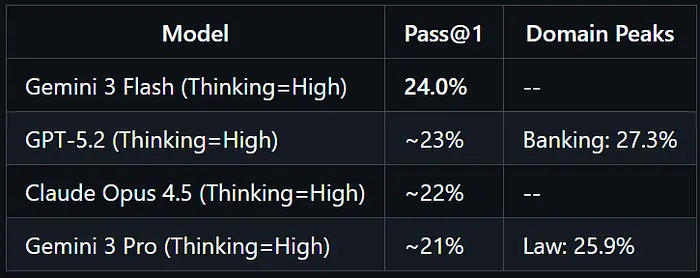
在八次尝试(pass@8)下,最佳模型只攀升到~40%。根据 agent 配置,零分率——agent 在每个评分标准上都失败——在测试配置中范围从40%到62%。超时率(超过250步)对于某些模型达到30%**。
这些数字来自 APEX-Agents 评估框架("Archipelago"),它在沙盒环境中运行每个 agent,具有标准化工具访问、250步限制,以及由领域专家进行的基于评分标准的评分。Pass@1 反映单次尝试;pass@8 取八次独立运行中最好的。上述分数代表测试配置中的最佳结果——个别 harness 设置产生了显著差异。
关键发现:这些失败主要不是知识失败。模型拥有信息并且可以在隔离情况下推理问题。失败是执行和编排问题——agents 在太多步之后迷路,循环回到失败的方法,并在任务中途丢失目标。
这正是 harness 工程解决的失败模式:上下文管理(丢失追踪)、错误恢复(在失败上循环)和状态管理(忘记目标)。
3、Vercel 的反直觉发现:更少的工具,更好的结果
这个案例研究是最直接挑战我个人直觉的。
Vercel 有一个名为 d0 的文本转 SQL agent。架构是标准的,老实说,我会那样构建:为管道的每个阶段提供专门的工具 [2]。
旧架构:15个专用工具
GetEntityJoins LoadCatalog RecallContext
LoadEntityDetails SearchCatalog ClarifyIntent
SearchSchema GenerateAnalysisPlan
FinalizeQueryPlan FinalizeNoData JoinPathFinder
SyntaxValidator FinalizeBuild ExecuteSQL
FormatResults
每个工具都有结构化输入、验证、错误处理和围绕它的提示工程。这是大多数团队构建 agents 的方式——本能是约束模型,调解它的交互,并为每个操作提供专门的接口。
它80%的时间工作(在他们基准测试上4/5)。
新架构:2个工具
然后他们做了一些激进的事情:删除了大部分。新的 agent 恰好有两个工具:
- ExecuteCommand——在 Vercel 沙盒中的 bash 访问
- ExecuteSQL——直接查询执行
agent 现在使用 grep、cat、find 和 ls 来探索代表 Cube 语义层的 YAML、Markdown 和 JSON 文件。每个开发者都已经知道的标准 Unix 工具。
数据
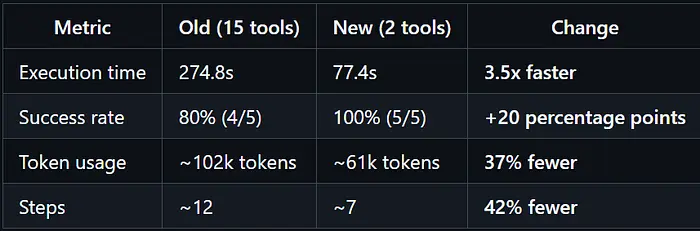
旧系统下的最坏情况:724秒、145,463个 token、100步,并且仍然失败。文件系统 agent 在19步中使用67,483个 token 在141秒内完成了相同的查询——成功。
他们使用的模型:Claude Opus 4.5,在 Vercel 沙盒内运行,可以访问 Vercel AI Gateway。
Vercel 团队发布了一个开源工具(bash-tool)和一篇关于使用文件系统和 bash 构建 agents 的配套文章 [8]。他们的结论:"最好的 agents 可能是工具最少的那些。"
为什么这有效
见解不是工具是坏的。而是当模型已经足够有能力使用通用接口时,专用工具成为瓶颈。每个专用工具都是一个约束点——模型必须学习它的模式,处理它的错误,并决定何时使用它与替代方案。有15个工具,模型花费更多 token 在选择上而不是做上。
通用工具(bash、文件访问)直接映射到模型的训练方式。大多数前沿模型在训练数据中看到了大量的 shell 交互。它们知道如何 grep。它们不知道如何用正确的参数调用 GetEntityJoins。
4、Manus:四次重建和20亿美元的教训
Manus 在2025年初因作为通用 AI agent 而走红。然后它们做大多数公司避免的事情:发布了他们的错误。在他们的博客文章"AI Agents 的上下文工程"[3]中,Ji Yichao "Peak" 详细介绍了他们如何四次重建框架,每次都发现了上下文管理的更好方法。
2025年12月,据 CNBC 和 TechCrunch 报道 [9][19],Meta 以约20亿美元收购了 Manus——证明他们构建的 harness 架构具有超出基础模型的显著生产价值。
他们删除了什么
每次重建都遵循一个模式:删除看起来必要但降低性能的面向用户的复杂性,同时投资于有针对性的内部基础设施(压缩、缓存、logit 掩码),改善模型的操作环境。
- 复杂的文档检索系统——被直接文件访问取代
- 专门子 agents 之间花哨的路由逻辑——被结构化移交取代
- 每个操作的专用工具——被通用 shell 执行取代
他们保留和改进的内容
文件系统即内存:不是将所有东西塞进上下文窗口,agent 将关键信息写入文件并在需要时读取。正如他们描述的那样,文件 "大小无限,天然持久,并且可以被 agent 直接操作" [3]。
待办列表机制:agent 维护一个持久进度文件,在上下文末尾重述其目标,以对抗"迷失在中间"的注意力衰减 [10]。
上下文压缩:输入输出比约为100:1,他们实现了一个压缩层次:
- 原始上下文(首选)——完整工具输出
- 压缩——用压缩版本交换完整结果,同时保留恢复路径(URL、文件路径)
- 总结(最后手段)——仅当压缩不再产生足够空间时
KV 缓存优化:通过维护稳定的提示前缀、仅追加上下文和确定性序列化,他们在缓存的 token 上实现了10倍成本节约(Claude Sonnet 为 $0.30/MTok 对比 $3/MTok 未缓存)[3]。
通过 logit 掩码进行工具管理:不是从提示中动态添加和删除工具,他们使用上下文感知状态机,通过 logit 级别的掩码约束工具选择。三种模式:Auto(模型选择)、Required(无约束)、Specified(通过预填充的子集选择)。
生产规模
他们的 agents 平均每个任务大约50次工具调用。即使有大的上下文窗口(200k+ token),性能在阈值之后下降——不是因为模型"忘记"了早期内容,而是因为上下文窗口中的信噪比崩溃。开始的重要指令被埋在数百个中间工具结果下。
这与 Liu 等人的"迷失在中间"研究 [10] 一致,该研究证明 LLM 表现出 U 形注意力模式——它们强烈关注上下文的开始和结束,但对中间关注不足。Greg Kamradt 的"大海捞针"测试 [11] 在多个前沿模型上经验性地证实了这一点。
5、三种架构,一个方向
现在最经过生产测试的三种 agent harness 是 OpenAI Codex、Claude Code 和 Manus。它们由不同团队以不同哲学独立构建。它们得出了相同的核心见解。
OpenAI Codex:Harness 工程作为一门学科
OpenAI 发表了"Harness Engineering" [4]和"解锁 Codex Harness"[12]——描述一个小团队如何在五个月内使用 Codex agents 构建和发布了一个百万行生产系统。根据他们的博客,工程师没有直接编写源代码;他们从编写代码转向设计 harness 环境、指定意图和审查 agent 生成的拉取请求。
他们的架构强制执行严格的分层依赖模型:
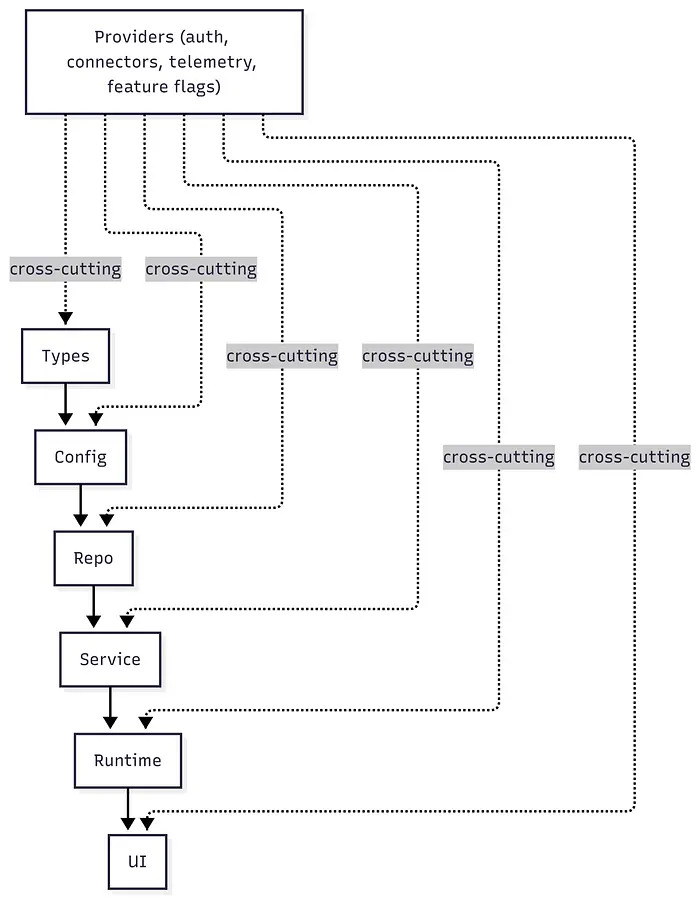
代码只能通过这些层向前依赖。横切关注点(身份验证、连接器、遥测、功能标志)通过单一显式接口进入:Providers。这是应用于 agent 生成代码的经典分层架构——harness 强制执行保持 agent 生产的约束。
Claude Code:最少工具,最大模型智能
Anthropic 在 Claude Code 上的方法刻意最少。核心工具集集中在:
- 读取文件
- 写入/编辑文件
- 运行 bash命令
- 搜索(grep/glob)
大多数智能存在于模型中。可扩展性来自 MCP(模型上下文协议)[13]——一个用于将 Claude 连接到外部工具服务器的开放协议——以及通过 CLAUDE.md 文件的项目级说明。
Anthropic 发表了一篇关于"长期运行 Agents 的有效 Harness"的配套指南 [5],推荐双 agent 模式:
- 初始化 Agent——在首次运行时设置环境(init.sh、进度文件、功能跟踪)
- 编码 Agent——处理增量工作,在会话开始时读取进度文件
他们的关键状态管理工件:用于可重现环境的 init.sh 脚本、用于工作日志的 claude-progress.txt 文件,以及用于版本控制和回滚的 git。约束:每个会话一个功能、增量进度、将代码保持在可合并状态。
Manus:减少、卸载、隔离
Manus 的方法可以用三个词总结:
- 减少——通过压缩和驱逐积极缩小上下文
- 卸载——使用文件系统进行超出上下文窗口的持久内存
- 隔离——将重的子任务委托给子 agents 并拉回摘要
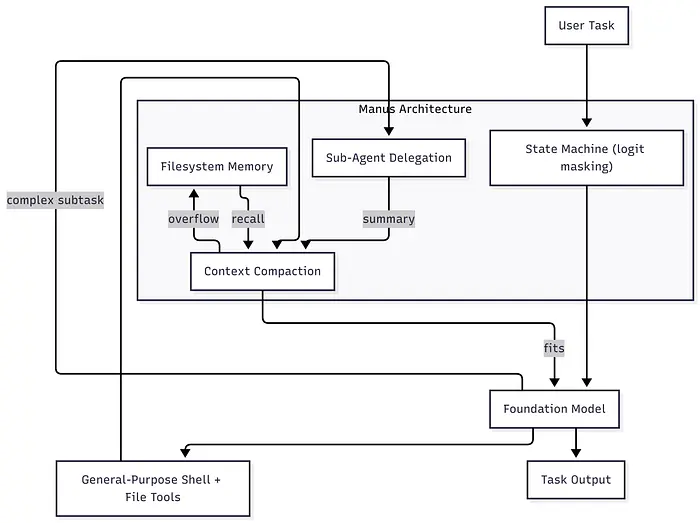
Manus 架构
收敛
三个独立架构。相同方向:
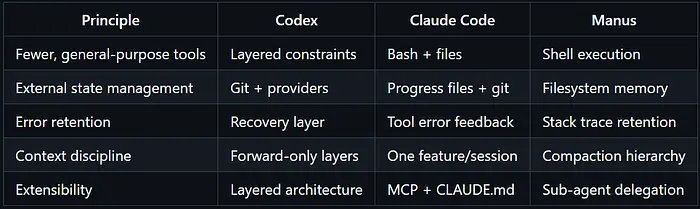
6、苦涩的教训,应用
Richard Sutton 的"The Bitter Lesson"[14] 发表于2019年3月,是现代 AI 中引用最多的文章之一。核心论点:"从70年 AI 研究中可以读出的最大教训是,利用计算的通用方法最终是最有效的,并且有很大的优势。"
Sutton 写的是搜索和学习方法。但这种模式直接映射到 agent harness:

每个被删除的 Vercel 工具、每个被删除的 Manus 检索系统、每个被简单移交取代的路由层——这些都是苦涩教训实时发挥的实例。
我想在这里诚实地谈谈一种紧张关系。对 Sutton 论点的严格解读会预测,harness 工程本身最终会被足够强大的模型淘汰——我们应该只是扩展模型,直到它们端到端地处理长期任务而无需编排脚手架。这个反驳论点是真实的,我认真对待它。Manus 不得不随着模型的发展四次重建他们的 harness,这本身就是模型改进侵蚀 harness 价值的证据。
我的立场是,多步骤执行任务有不可约减的协调要求——上下文管理、状态持久化、错误恢复——这些不是模型要解决的推理问题,而是系统要处理的基础设施问题。模型不需要更"聪明"来将进度保存到磁盘;它需要一个持久化状态的 harness。Harness 本身是一种通用方法:它管理上下文并从错误中恢复,以随模型能力扩展的方式。关键区别是,harness 应该随着模型的改进变得更简单,而不是更复杂。
实际含义:如果每次模型升级都让你添加更多手工编码的逻辑、路由或管道步骤,你就是在逆流而上。为删除而构建。每一块 harness 逻辑都应该是当模型不再需要它时可以删除的东西。如果你的基础设施随着模型的改进变得越来越复杂,你就在过度设计。
这不是一个理论论点。Anthropic 的"构建有效 Agents"指南 [6] 明确推荐在接触复杂的 agent 框架之前,从简单的模式(增强 LLM、提示链)开始。LangChain 从高度抽象链(v0.1–0.2)到 LangGraph 更简单的基于图的组合 [15] 的演变是这种模式的另一个实例。行业正在实时学习苦涩的教训。
智能手机类比
在早期智能手机中,处理器是故事——更快的芯片意味着更好的手机。最终处理器跨过了充足阈值,差异对用户不再重要。差异化转移到操作系统(iOS 对比 Android)、相机软件(计算摄影,而不是传感器)和开发者生态系统。
原始计算能力成为商品。价值转移到基础设施层。
同样的模式在云计算中上演:服务器硬件商品化,价值转移到 AWS 的基础设施抽象。在数据库中:原始存储商品化,价值转移到查询优化和事务管理。在 GPU 中:NVIDIA SKU 之间的原始 FLOPS 商品化,价值转移到 CUDA/cuDNN/PyTorch 软件堆栈。
在 agent 时代,harness 是操作系统。构建优秀 harness 的团队和公司将随着基础模型的不断变化而保持优势。这就是为什么 OpenAI 将 Codex 构建为 harness 产品,而不仅仅是一个模型。这就是为什么据报道 Meta 为 Manus 的 harness 支付了约20亿美元 [9][19],而不是基础模型。
7、生产工程现实
上面的案例研究令人信服,但它们关注能力。生产系统还必须解决可靠性、可观察性、成本和安全性。这些是已发表文献经常强调不足的 harness 关注点。
这不是 ML 系统中的新见解。Sculley 等人的"机器学习系统中的隐藏技术债务"[16] 在2015年证明,ML 模型代码只是生产 ML 系统的一小部分——周围的基础设施占主导地位。Agent harness 是同一模式的最新体现。
上下文窗口经济学
上下文不是免费的。截至2025年中期,Claude Sonnet 未缓存的输入 token 成本为 $3/MTok。Manus 的约100:1输入输出比意味着上下文管理直接决定成本。他们的 KV 缓存优化(稳定前缀、仅追加上下文、确定性序列化)将缓存的 token 减少到 $0.30/MTok [3]。这是纯 harness 优化的10倍成本降低,零模型更改。(价格是时间敏感的——在将这些数字应用于你自己的成本模型之前,请验证当前费率。)
对于平均每个任务50次工具调用的系统,天真的上下文管理很容易将单个任务推到200k+ token。在 $3/MTok 未缓存下,这是每个任务 $0.60。在 $0.30/MTok 缓存下,它是 $0.06。在数百万任务中,这是可行产品和不可持续成本结构之间的差异。
失败模式分类
从 APEX-Agents 分析、Manus 博客文章和 Anthropic 的 harness 指南中,出现了一致的 agent 失败模式分类——每个失败模式都是 harness 问题:
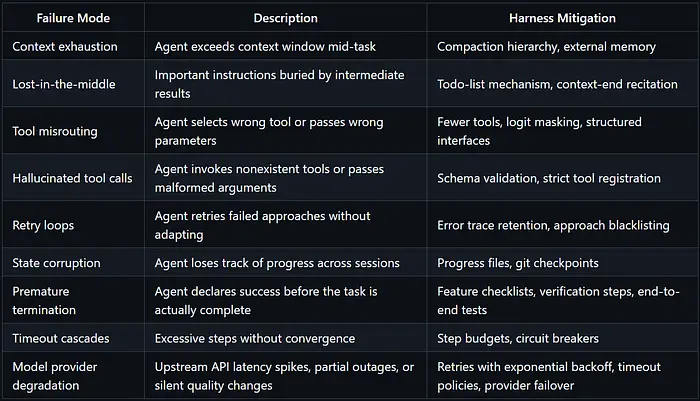
可观察性
"更少工具"方法的一个生产权衡:专用工具产生结构化遥测数据(tool=search_code, query=X, results=N, latency=Yms)。Bash 命令产生非结构化输出,需要解析以提取等效信号。
生产 harness 无论工具设计如何都需要结构化日志记录层:
- 每次工具调用遥测:工具名称、输入哈希、输出大小、延迟、成功/失败
- 上下文利用率跟踪:使用的 token 与预算、缓存命中率、压缩事件
- 任务级指标:总步数、总 token、挂钟时间、结果
- 分布式跟踪:跨越多轮 agent 工作流的 OpenTelemetry 跨度
安全考虑
"给它 bash"方法有一个明显的安全面。Vercel 通过沙盒执行(Vercel Sandbox)解决这个问题。Manus 使用完整 VM 隔离。Claude Code 在本地运行,具有用户控制的权限。
对于生产部署:
- 沙盒化一切:没有隔离的 shell 访问是漏洞,而不是功能
- 最小权限原则:agent 应该只拥有当前任务所需的访问权限
- 审计日志记录:每次工具调用都应该被记录以用于合规和取证
- 输入/输出过滤:上下文窗口中的敏感数据需要在 harness 级别处理
- 出站控制:被操纵的 agent 可以使用合法的工具调用来窃取数据——例如,将敏感上下文编码到 Web 搜索查询参数中。对工具输入的出站监控和内容检查是必要的
- 秘密管理:工具所需的 API 密钥和凭证必须在 harness 级别注入,绝不能暴露在上下文窗口中,否则它们可能通过模型输出泄漏
- 数据治理:当使用文件系统即内存模式时,应用保留策略和数据分类。Agent 编写的文件可能包含 PII、专有数据或需要与任何其他数据存储相同治理的中间推理
8、我的假设在哪里破裂
假设1:"更多工具意味着更多能力"
我发现:Vercel 案例研究直接反驳了这一点。15个专用工具产生了80%的准确率。2个通用工具产生了100%。模型不受工具可用性约束——它受工具复杂性约束。每个额外的工具都会增加决策空间和误路由的概率。
假设2:"上下文窗口现在足够大了"
我发现:即使200k+ token 窗口在生产负载下也会下降。Manus 的50次工具调用会话产生足够的中间内容淹没信号。"迷失在中间"研究 [10] 和大海捞针评估 [11] 证实这不仅仅是轶事。上下文窗口大小是必要的但不充分的——重要的是上下文质量,这是 harness 的责任。
假设3:"苦涩的教训意味着你不应该构建基础设施"
我发现:这是对 Sutton 论点的误读。苦涩的教训说随计算扩展的通用方法获胜。它没有说什么都不做,等待更好的模型。好的 harness 本身是一种通用方法——它管理上下文、从错误中恢复并以随模型能力扩展的方式持久化状态。关键是 harness 应该随着模型的改进变得更简单,而不是更复杂。构建可以逐步删除的基础设施。
假设4:"基准分数预测生产性能"
我发现:APEX-Agents 全面暴露了这一点。在传统基准测试中得分90%+的模型在专业任务上达到24%。差距不是智力——它是执行基础设施。测试隔离推理的基准测试告诉你关于引擎的信息。生产告诉你关于汽车的信息。
9、我的假设正确吗?
结论:正确,但有一个重要限定。
它成立的地方
对于任何基础模型满足能力底线的生产 agent 系统——大约,能够可靠地遵循多步骤指令、通过结构化函数调用使用工具并从单步骤错误中恢复的模型(GPT-4级以上;操作上,你可以通过在10个代表性任务上运行你的 agent 并检查失败是推理错误还是编排错误来测试这一点):
- Harness 工程产生比模型选择更高的边际回报
- 简化 harness 比添加复杂性更频繁地改善结果
- 上下文管理、错误恢复和状态持久化是主要失败点,而不是模型推理
- Vercel(80%到100%)、Manus(迭代简化)和 APEX-Agents(尽管基准测试分数高但约24%)数据都支持这一点
它失败的地方
在模型能力阈值之下,没有 harness 能补偿推理不足。你不能通过 harness 工程让 GPT-3.5 解决 APEX-Agents 咨询任务。Harness 放大模型能力——它不取代它。
此外,对于纯粹推理受限的任务(数学证明、新颖算法设计),模型能力占主导地位。Harness 论点最强烈地适用于长期、使用工具、多步骤执行任务——这正是 agents 被部署到生产中的类别。
我的建议
- 在你自己的系统上运行 Vercel 实验。将你的 agent 剥离到 bash + 文件访问。运行你的评估套件。如果性能改善,你的专用工具是净负面的。如果下降,你的任务确实需要结构化接口。
- 添加进度文件。让你的 agent 维护一个持久待办列表,它在每个操作开始时读取并在结束时写入。这是最简单的可能状态管理,Manus 和 Claude Code 都使用它的变体。
- 测量你的上下文预算。为你的 agent 配置工具以跟踪每个任务消耗的 token。设置预算。当你达到它时,你有一个 harness 问题,而不是模型问题。
- 为删除而构建。每一块 harness 逻辑都应该有到期日。如果下一个模型可以在没有你的脚手架的情况下处理某些事情,删除脚手架。
- 为工具接口采用 MCP。Anthropic 的模型上下文协议 [13] 正成为将 agents 连接到外部工具的事实标准。干净的工具接口比自定义集成更便宜维护。
10、最后的想法
2025年是 agents 的一年。2026年是 harnesses 的一年。
如果你认为 Opus 现在是最好的编码模型,请注意它在 Claude Code、Cursor 和带有自定义 harness 的 API 中的行为不同。模型是相同的。Harness 改变一切。
最大的 AI 公司都在告诉你这一点。OpenAI 发表了"Harness Engineering"。Anthropic 发表了关于有效 harness 的指南。Manus 发表了他们的上下文工程教训(据报道 Meta 为结果支付了约20亿美元 [9][19])。证据并不微妙。
仔细选择你的 harness——无论你是使用 agent 还是构建一个。模型每隔几个月就会改变。Harness 是让它工作的东西。
原文链接: The Agent Harness Is the Architecture (and Your Model Is Not the Bottleneck)
汇智网翻译整理,转载请标明出处
