智能体记忆:一个数据库问题
对于AI智能体来说,记忆是智能的基础。没有它,即使是最先进的模型也只是一个只有五分钟记忆的聪明人。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
LLM如何忘记东西?
示例:想象你有一个同事,他非常擅长解决复杂的数学问题和编写代码,但有一个主要问题:每次他们离开办公室时,他们的大脑就会被完全清空。每天早上,你必须重新介绍自己,从头解释你的项目,并提醒他们你更喜欢特定格式的报告。虽然他们在当下非常聪明,但与他们一起工作很累人,因为他们没有关于你们共同历史的记忆。
这正是今天大多数AI智能体的状态。我们构建了非常强大的模型,能够推理困难的任务,但对话一结束,智能体就遭受完全失忆。每次新的交互都从零开始,没有关于用户是谁或之前讨论了什么的记忆。
为了从简单的聊天机器人转变为真正有用的数字同事,我们需要解决这个记忆问题。事实证明,解决方案不在于让AI模型变大,而在于将智能体记忆视为一个复杂的数据库问题。
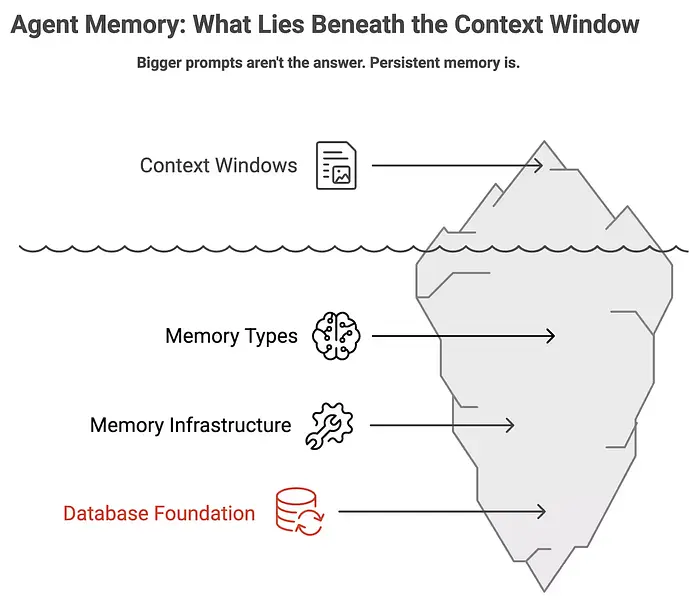
1、记忆不是一张大的"便利贴"
在AI行业中,有一个常见的误解,即更大的上下文窗口(LLM一次能读取的文本量)将解决记忆问题。
尽管一些模型现在可以一次处理数百万个单词,使人们相信基于检索的记忆不再需要。然而,研究人员称此为"记忆幻觉"。
将上下文窗口想象成一张巨大的便利贴。你可以在上面写很多信息,但对话会话一结束,那张纸条就被扔进垃圾桶了。
真正的记忆意味着笔记能够保存下来。仅仅依赖大的上下文窗口是有问题的,因为模型通常在窗口填满之前就变得不可靠了,它们将每条信息(如随机问候)与你的名字同等重要对待,而且每次重新阅读所有内容的成本增长得非常快。
为了为AI智能体构建真正的心智模型,我们必须研究人脑是如何工作的。现代AI框架已经汇聚于四种不同类型的记忆:
- 工作记忆: 这是AI当前正在思考的草稿纸,比如当前对话。
- 程序性记忆: 这是肌肉记忆,包含智能体遵循以完成工作的规则和逻辑。
- 语义记忆: 这是一般知识,如关于用户偏好的事实或长期概念。
- 情景记忆: 这是自传体记忆,允许智能体回忆过去的特定经历,比如三周前的会议。
今天的大多数智能体只有工作记忆。给予它们其他三种记忆需要一个持久化状态,存在于外部系统中,具体来说就是数据库。
2、技术深度探讨:记忆基础设施
构建一个能扩展到企业级别的记忆系统是一个多层次的工程挑战。你不能使用单一的存储范式;你需要三种范式协同工作来模拟人类回忆。
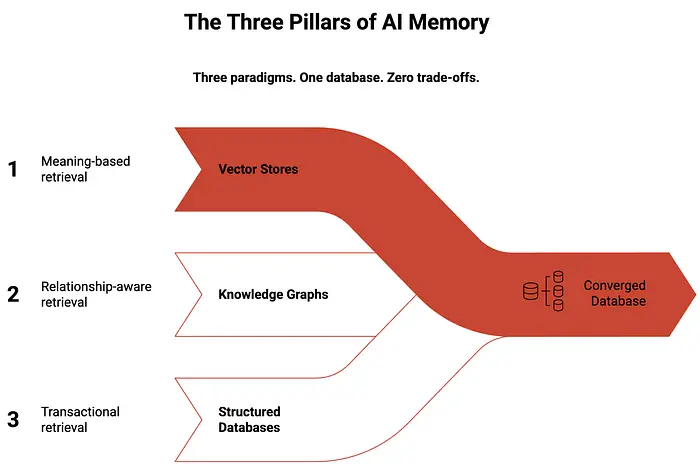
首先,我们使用向量存储来处理语义记忆。这涉及将文本转化为一长串数字,称为嵌入。当智能体需要记住某些东西时,它执行相似性搜索以找到与当前主题在数学上最接近的向量。这对于理解一般含义很好,但在处理特定关系时会遇到困难。
其次,我们需要知识图谱来处理关系。向量搜索可能会告诉智能体你提到了"咖啡",但它不一定记得你"上周二从街角店点了一杯拿铁"。图谱连接这些实体,如人物、动作、物体和时间,从而允许智能体理解事物如何随时间相互关联。
第三,我们需要结构化关系数据库来存储坚实的事实。这包括用户配置文件、账户详情和安全设置。这些是智能体记忆的锚点,确保数据以严格的事务保证进行处理。
在大多数现代设置中,开发者必须将三个独立的数据库拼接在一起才能实现这一目标:一个用于向量,一个用于图谱,一个用于关系数据。这就是融合数据库改变游戏规则的地方。
通过在单一引擎(如Oracle数据库)中运行所有三种范式,智能体的记忆变得更加稳定。每次智能体学习一个新事实时,它可以在一个ACID事务中更新其向量、图谱和结构化记录,确保即使更新的某一部分失败,记忆也不会损坏。
3、永不遗忘的智能体
今天最常见的应用场景是客户服务,占所有AI智能体部署的26%以上。
想象一个客户打电话给支持智能体投诉笔记本电脑坏了。智能体使用其情景记忆回忆起这个客户上个月有类似的问题。它使用语义记忆知道客户更喜欢通过电子邮件而不是电话联系。它使用程序性记忆遵循公司特定的退款政策。最后,它使用工作记忆处理实时对话。
如果没有这种集成的记忆系统,客户每次打电话都必须解释他们的整个历史,导致令人沮丧和缺乏人情味的体验。有了它,智能体就像一个乐于助人的人类助手,真正理解情况。
4、评估
尽管有明显的好处,但从演示智能体转向生产智能体是很困难的。对130位价值十亿美元公司的C级高管进行的调查发现,65%的人将智能体系统的复杂性视为他们部署的最大障碍。虽然智能体使用量在2025年翻了一番多,但绝大多数大型企业仍停留在试点阶段。
原因之一是,在规模上,记忆不再只是一个编码问题;它是一个合规和安全问题。GDPR的被遗忘权等法规意味着AI必须能够应请求从其记忆中选择性地删除用户的个人数据。
与此同时,欧盟AI法案可能要求高风险系统保留10年的审计跟踪。管理删除数据和保留十年历史之间的这种紧张关系需要只有专业级数据库才能提供的架构复杂性。
5、外部智能体记忆的利弊
优点:
- 连续性: 交互成为长期关系的一部分,而不是一系列一次性事件。
- 效率: 将信息存储在数据库中远比每次尝试将数百万个token塞入提示中便宜得多。
- 适应性: 智能体可以基于过去的成功或失败来学习和改变其行为。
缺点:
- 复杂性: 构建一个集成向量、图谱和关系数据的系统在技术上要求很高。
- 安全风险: 如果智能体的记忆没有正确隔离,它可能容易受到记忆投毒的攻击,恶意用户向AI提供虚假信息以破坏其未来的决策。
- 延迟: 检查数据库中的记忆会为每次响应增加少量时间,尽管后台记忆过程可以帮助缓解这一点。
6、睡眠时间及以后
这一切将走向何方?最令人兴奋的趋势之一是睡眠时间计算。这个想法是AI智能体应该在空闲时进行思考,整合它们的记忆,完善它们的知识图谱,并清理不相关的数据。
研究表明,使用这种方法的智能体可以实现18%的准确率提升和2.5倍的成本降低,因为它们不需要实时扫描原始、未组织的数据。
我们也看到了从"检索增强生成"(RAG)向完整上下文记忆的转变。虽然RAG非常适合在文档中查找事实,但记忆是允许智能体理解用户特定上下文的东西。专家预测,到2026年底,记忆将成为最成功的AI智能体的主要差异化因素。
7、最后的思考
对于AI智能体来说,记忆是智能的基础。没有它,即使是最先进的模型也只是一个只有五分钟记忆的聪明人。
为了超越"便利贴"上下文窗口的限制,我们必须接受智能体记忆是一个数据库问题的事实。通过使用能够在一个地方处理向量、图谱和事实的融合数据库,我们终于可以构建不仅能对话,还能真正学习、适应和记住的AI智能体。
原文链接: Agent Memory — A Database Problem
汇智网翻译整理,转载请标明出处
