用Splunk分析AI机器人流量
当LLM访问你的网站时会发生什么?

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
毫无疑问,大型语言模型(LLM)正在慢慢取代传统搜索。现代用户的旅程越来越不是从传统搜索引擎如Google开始,而是由用户向ChatGPT、Perplexity、Claude或Gemini提问开始——而这些AI系统会代表你进行"暗网浏览"(我不知道这是否是有效术语,但我喜欢这么说!)
现代用户旅程现在看起来是这样的:👤 用户在LLM中提问 → 🤖 LLM爬取相关网站 → 🌐 用户获得综合答案 → 🧭 LLM可能向用户展示你网站的推荐链接 → ⏰ 用户通过LLM推荐到达你的网站并参与内容
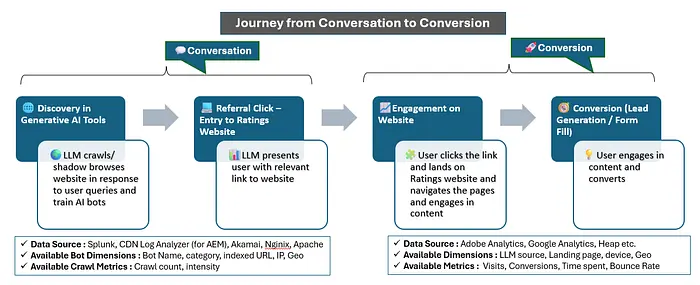
但这里有个问题: 当LLM爬取你的网站时,它们不会触发你基于JavaScript的分析标签(如Adobe Analytics或GA4)。所以,虽然你的仪表板可能显示"0次会话",但你的Web服务器日志却在静默记录着一切。
你的Apache或Nginx访问日志是金矿——包含机器人和用户的所有请求。如果你的组织有Web服务器日志分析工具如Splunk,你可以解码这些数据,以了解LLM如何爬取你的网站、它们在读取什么,以及这如何影响你在AI生态系统中的可见性。
0. 为什么这很重要
随着LLM驱动的流量增长,了解哪些页面被AI模型索引和引用至关重要。如果你的关键内容没有被爬取或引用,你在"AI优先"的新搜索世界中将面临隐形风险。
示例日志行
以下是标准Apache访问日志中LLM爬取的样子:

198.215.99.26 - - [30/Sep/2025:23:26:40 -0400] "GET /guest/article123 HTTP/1.1" 200 220 416 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 "-" "Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot" 640 438
host = ip-10-164-170-239.ec2.internal
让我们来解析:
- IP: 198.215.99.26
- 时间: 30/Sep/2025:23:26:40 -0400
- 请求的URL: /guest/article123
- LLM爬虫: ChatGPT-User/1.0
- 用户代理字符串: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; ChatGPT-User/1.0; +https://openai.com/bot
这将其识别为ChatGPT的爬虫。还有更多信息,如状态码、协议等。你也可以解码用户代理以获取设备、操作系统等信息。
Web服务器日志中还隐藏着更多有价值的信息——远比大多数人意识到的要多。Splunk现在提供Dashboard Studio,可用于使用这些数据创建引人入胜的视觉故事。
我写这篇文章不仅是为了分享我的发现,而且是为了展示一些想法和现成的查询,你可以调整这些来在Splunk中构建自己的GenAI机器人分析仪表板。
你可以从日志中创建的报告包括:
- 🤖 机器人爬取信息 — 数量、类别和爬取频率,随时间变化的趋势
- 📄 爬取内容分析 — URL、图片、PDF,甚至blob资产(是的,认真地说!)
- 🌍 地理位置洞察 — 这些爬取来自世界何处
- ⏰ 日期/时间趋势 — 机器人何时最活跃地爬取你的网站,以及它们多久返回一次
一旦你建立了这个结构,你可以使用Splunk查询更深入地研究,以发现模式,衡量可见性,并识别LLM最感兴趣的内容。让我们深入一些示例查询。
对于下面列出的所有查询,我使用默认的index和source值。请根据你的设置替换为正确的值。
这是一个简单的查询,你可以用它来识别你是否已有数据。
Index="prod" source="access_combined_prod" chatgpt
运行过去24小时并观察是否有任何事件。尝试详细模式以获得更好的答案。如果有,那么你可以继续构建如下所示的仪表板。
1. 获取机器人总点击量
Index="prod" ("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Claude" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| stats count AS total_hits
此查询将为你提供符合LLM点击条件的事件总数用于所选时间范围。你可以将其保存在仪表板中。不要忘记将source与Input时间范围绑定以获取动态日期。
2. 获取不同LLM的机器人点击量
Index="prod"
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Claude" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| rex field=_raw "(?<genai>(ChatGPT|GPTBot|openai|Claude-SearchBot|Claude-User|ClaudeBot|PerplexityBot|Perplexity-User|Anthropic|Perplexity|Cohere|Gemini|AI21|Google-Extended|BingPreview))"
| stats count BY genai
| sort -count
此查询从已知的LLM机器人中提取所有请求,并统计每个机器人产生了多少次点击。我的日志中没有"user-agent"作为字段之一,因此我使用正则表达式提取LLM源名称并存储为"genai"列。
示例输出
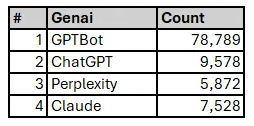
上述查询的示例输出
3. 将机器人分类为不同类型
一旦识别,你可以对机器人进行分类以获得更丰富的见解。我发现这部分非常有趣,因为它显示了不同类型的LLM如何不同地消费内容。详细分析超出了这篇文章的范围,但如果有人有更多问题,我很乐意进一步讨论。我列出了示例查询和一些你可能通过此分析发现的机器人类型。
Index="prod"
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Claude" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| eval BotCategory=case(
like(_raw,"%GPTBot%") OR like(_raw,"%Google-Extended%") OR like(_raw,"%BingPreview%") OR like(_raw,"%Claude%") OR like(_raw,"%Anthropic%") OR like(_raw,"%Cohere%") OR like(_raw,"%AI21%") OR like(_raw,"%Perplexity%"), "Training Bot",
like(_raw,"%ChatGPT-user%") OR like(_raw,"%OpenAI-SearchBot%") OR like(_raw,"%Perplexity-user%") OR like(_raw,"%Claude-user%"), "User Query Bot",
like(_raw,"%searchbot%"), "Search Query Bot",
true(), "Other"
)
| stats count BY BotCategory

识别的LLM机器人类型
4. 提取访问最多的URL
想知道哪些页面对LLM最有吸引力吗?
index="prod"
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| rex field=_raw "\"GET\s(?<url>[^\s]+)"
| stats count BY url
| sort -count
你可以看到每个机器人爬取了多少唯一URL以及频率——帮助你了解LLM爬取中哪些内容主题正在流行。
你可以通过添加每种机器人类型使用的唯一URL数量、前10个URL、按URL的机器人爬取趋势等来进一步推进此分析。你甚至可以按网站部分或页面类型对爬取的页面进行分组,并用机器人类别进行增强。这将为你提供关于什么内容被呈现给什么样的机器人的丰富见解。
5. 机器人爬取趋势
使用以下查询获取每日机器人爬取趋势。你可以按需要限制或扩展机器人。
index="prod"
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Claude" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| timechart span=1d count BY bot
/*change to monthly trend*/
| eval month=strftime(_time, "%B %Y")
| stats count AS hits BY month
你可以获取数月的机器人趋势,以查看你的内容增加/减少。你也可以用timechart替换为获取月度趋势。
6. 识别机器人活动的国家
你可以使用用户代理中的IP地址提取国家。在下面的查询中,我还添加了访问的唯一URL数量以及总点击量。你可以根据报告要求调整查询。你可以在Splunk dashboard studio中使用Choropleth或地图来有效地可视化这些信息。
Index="prod"
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "Claude" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| rex field=_raw "(?<url>GET\s+\S+)"
| rex field=_raw "(?<useragent>\"[^\"]+\")"
| rex field=_raw "(?<clientip>\d+\.\d+\.\d+\.\d+)"
| iplocation clientip
| stats dc(url) as UniqueURLs count as TotalHits by Country
| sort -TotalHits
7. 估算平均爬取深度、最大深度
此查询提取平均爬取深度,这会让你深入了解每个机器人如何爬取你的内容。
index=prod
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "OAI-SearchBot" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| rex field=_raw "(?<clientip>\d{1,3}(?:\.\d{1,3}){3})"
| rex field=_raw "(?<genai>ChatGPT|GPTBot|OpenAI-SearchBot|OAI-SearchBot|Perplexity|Claude|Anthropic|Cohere|AI21|Google-Extended|BingPreview)"
| rex field=_raw "GET\s+(?<URL>\S+)"
| search NOT URL="*/robots.txt" NOT URL="*favicon.ico" NOT URL="*/wp-admin/*"
| eval BotName=case(
like(genai,"%GPTBot%"),"GPTBot",
like(genai,"%ChatGPT%"),"ChatGPT-User",
like(genai,"%OpenAI-SearchBot%") OR like(genai,"%OAI-SearchBot%"),"OpenAI-SearchBot",
like(genai,"%Perplexity%"),"Perplexity",
like(genai,"%Claude%") OR like(genai,"%Anthropic%"),"Claude/Anthropic",
like(genai,"%Cohere%"),"Cohere",
like(genai,"%AI21%"),"AI21",
like(genai,"%Google-Extended%"),"Google-Extended",
like(genai,"%BingPreview%"),"BingPreview",
true(),"Other"
)
| bin _time span=10m
| stats dc(URL) as crawl_depth count as total_hits by BotName, clientip, _time
| where crawl_depth > 0
| sort -crawl_depth
| stats avg(crawl_depth) as avg_depth, max(crawl_depth) as max_depth by BotName
| sort -avg_depth
使用以下方法从分析中排除robots.txt请求:
| search NOT request="*/robots.txt"
奖励:爬取深度指标
要查看每个机器人在单次爬取中访问了多少页面:
("ChatGPT" OR "GPTBot" OR "OpenAI" OR "OAI-SearchBot" OR "Anthropic" OR "Perplexity" OR "Cohere" OR "AI21" OR "Google-Extended" OR "BingPreview")
| rex field=_raw "(?<clientip>\d{1,3}(?:\.\d{1,3}){3})"
| rex field=_raw "(?<genai>ChatGPT|GPTBot|OpenAI-SearchBot|OAI-SearchBot|Perplexity|Claude|Anthropic|Cohere|AI21|Google-Extended|BingPreview)"
| rex field=_raw "GET\s+(?<URL>\S+)"
| search NOT URL="*/robots.txt" NOT URL="*favicon.ico" NOT URL="*/wp-admin/*"
| eval BotName=case(
like(genai,"%GPTBot%"),"GPTBot",
like(genai,"%ChatGPT%"),"ChatGPT-User",
like(genai,"%OpenAI-SearchBot%") OR like(genai,"%OAI-SearchBot%"),"OpenAI-SearchBot",
like(genai,"%Perplexity%"),"Perplexity",
like(genai,"%Claude%") OR like(genai,"%Anthropic%"),"Claude/Anthropic",
like(genai,"%Cohere%"),"Cohere",
like(genai,"%AI21%"),"AI21",
like(genai,"%Google-Extended%"),"Google-Extended",
like(genai,"%BingPreview%"),"BingPreview",
true(),"Other"
)
| bin _time span=10m
| stats dc(URL) as crawl_depth count as total_hits by BotName, clientip, _time
| where crawl_depth > 0
| sort -crawl_depth
这个指标特别有见地——高爬取深度可能表明对你的网站内容有强烈兴趣。
8、结束语
建议
- 每月监控LLM机器人模式以发现爬取行为的变化。
- 提高LLM可发现性——确保你的内容可访问、加载快速且语义丰富。
- 更新元数据和schema.org标记以提高AI引用质量。
- 将来自chatgpt.com或perplexity.ai的推荐流量与潜在客户相关联以衡量真正的ROI。
当我开始探索这些日志时,我感到不知所措,但同时也很兴奋地看到可以从中提取这么多信息。这些查询应该能很好地帮助你在机器人探索之旅上有一个良好的开端。我将在这里结束这篇文章,但请随时让我知道你的想法、其他查询或你想深入研究的某些细分领域。我非常感兴趣了解这些数据如何塑造你的内容策略。
我对此做了进一步分析,并分析了来自LLM的推荐流量,我是用Adobe Analytics做的。我也会很快发布另一篇关于此的文章。
是的,而这只是开始!🚀
原文链接: GenAI Bot Traffic Analysis Using Splunk
汇智网翻译整理,版权归作者所有,转载需标明出处
