MLP与ReLU²激活函数的研究

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Transformer MLP层标准的norm()预处理步骤对激活函数行为有着深远的影响,我觉得这个现象足够有趣,值得记录下来。我经常看到人们在讨论激活函数时使用直线数轴f(x)的方式,这给出的直觉与激活函数接受单位球面作为输入时截然不同——而后者正是我们对输入进行归一化时发生的情况。
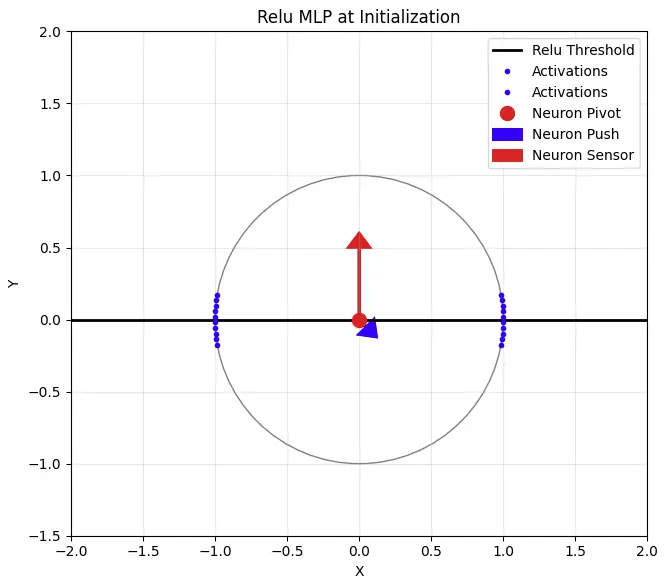
下面展示了单个神经元在输入经过均方根归一化后的Relu MLP中的行为。为简单起见,我将缩放因子除以root(d_model),使得输入位于单位球面上。
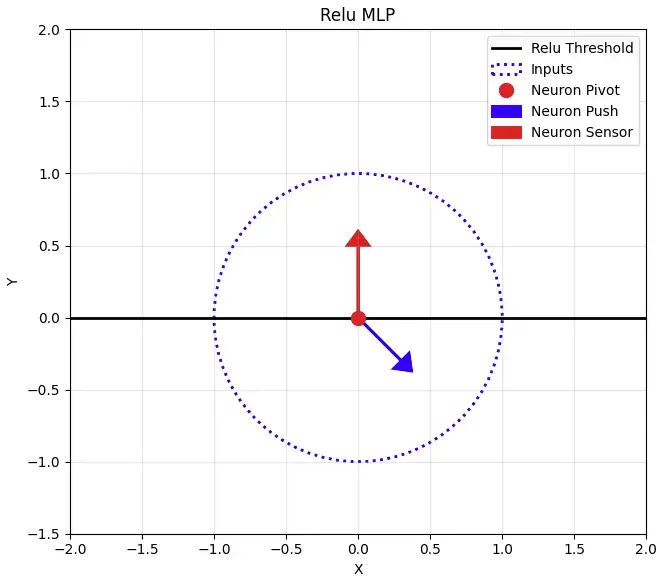
输入由蓝色点表示。这些输入首先被归一化为相同的长度。如果输入被初始化为正态分布,那么这些点均匀地分布在d_model维球面上(顺便说一下,这引发了一个问题:为什么在使用K和Q归一化的模型中,K和Q向量使用均匀初始化而不是正态初始化——似乎这会导致不均匀的初始化)。红色箭头代表神经元输入权重的方向。高对齐度(0,1)的蓝色点有高激活值,正交的蓝色点(1,0)激活值为零。黑线代表Relu(x) = 0的阈值。
神经元的行为是:对于阈值线以上的所有点,计算它们的距离。将蓝色点沿蓝色箭头方向移动this_distance*scalar的距离。在权重更新期间:
- MLP可以同时设置红色和蓝色向量。两个向量都固定在原点,因为模型在MLP中没有偏置项。
- 输入只能沿单位球面移动。这是一个关键限制。
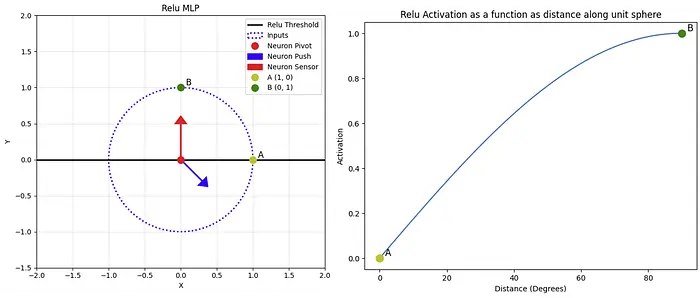
上图展示了激活值如何随输入从A到B移动而变化。这里的关键点是:梯度在A点最高,在B点为零。
ReLU Squared激活的曲线如下:
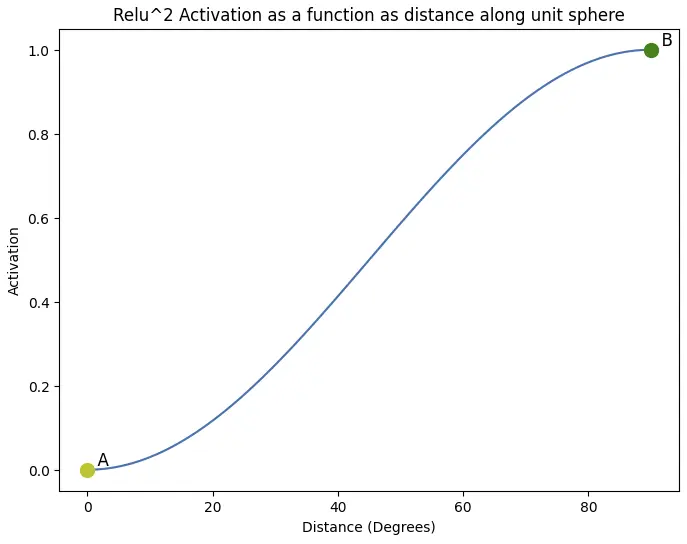
通常我们认为x²在x增大时会快速增加。然而,在B点附近,归一化效应占主导地位并将梯度推向零。从输入数据的角度来看,ReLU²的主要区别在于梯度在A点附近趋近激活零值时会柔和地趋于零。这有两个含义:
- 使用ReLU时,神经元梯度信号对低于0的任何激活值是盲区,每次神经元输入权重更新时,都有可能导致某个激活值突然超过阈值。当这种情况发生时,模型会出现梯度未能预期的离散行为变化。在零附近有非常柔和的梯度意味着这些点只会对模型产生最小的干扰。
- GELU和ELU的柔和左尾使得非常弱激活的token仍然能获得梯度信号来攀升到更高的激活值。ReLU² + norm()的柔和左尾可能实现类似的动态。
ReLU²与门控矩阵与输入投影矩阵绑定的ReGLU是等价的。任何门控激活函数都能实现这种在激活边界附近梯度的柔和化。
1、高维空间中的含义
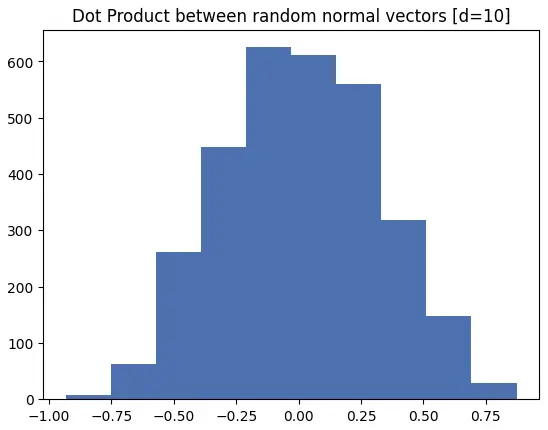
10维空间中具有单位范数的随机正态向量的点积分布如下:
在768维空间中:
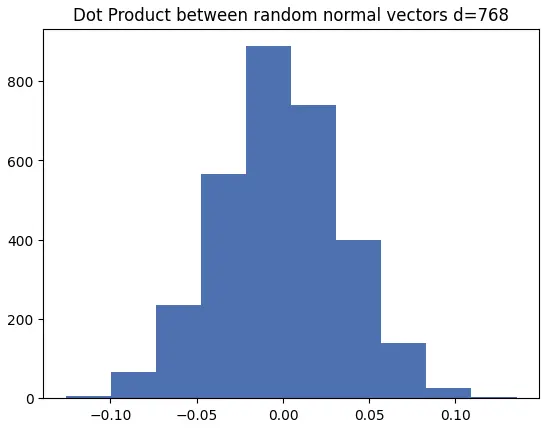
在高维空间中,几乎所有随机向量都大致正交。这意味着当我们初始化一个正态随机嵌入时,视觉效果更像是:(我也降低了"神经元推力"的幅度,以表明mlp_out投影可能被初始化为零)
所有激活值都非常接近ReLU激活阈值。直觉上,球体在赤道附近的表面积比在极点附近更大。每增加一个维度,就多了一个在保持在赤道上的同时可以移动的自由度。
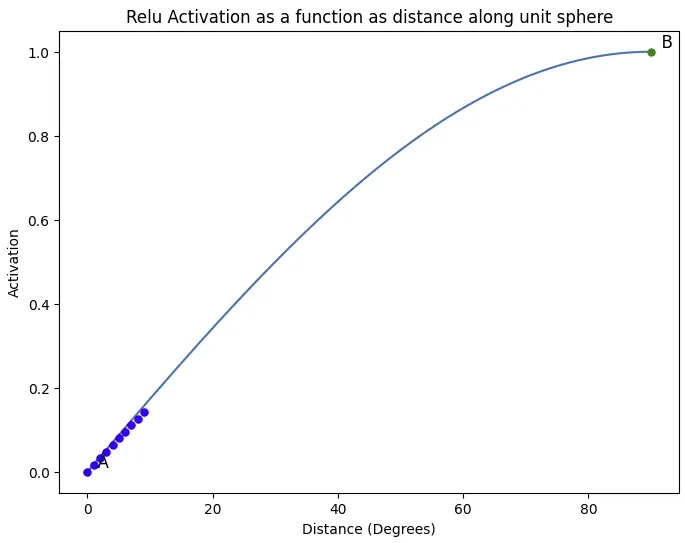
再次展示上图。激活函数在0-10度区域的斜率将决定MLP的初始行为,因为这是所有输入的起始位置。
2、训练过程中的动态
由于每个神经元阈值将输入空间平均一分为二,且输入是随机初始化的,在训练开始时每个神经元对50%的输入产生激活。输入分为三类:
- 当前已激活,希望保持激活(将保持在阈值之上)[零影响]
- 当前已激活,希望移除激活(将降到ReLU阈值之下)[负面影响]
- 未激活,没有梯度信号在这个方向移动。[零影响]
因此,随着时间的推移,存在不对称的梯度压力来减少神经元激活的输入数量。对于第2类输入,神经元产生的上游梯度压力就像波浪将海藻推上岸:海藻最初分散在海洋中,然后聚集在海洋和海岸边界的非常薄的一个流形上。一旦海藻到达海岸,就没有力量将它推回去。
关于高维空间中流形形成的附注:理论上,如果我想以二进制格式最优地压缩信息,我应该使用每个位置0和1期望相等的压缩方案。MLP引起的不对称梯度压力鼓励了流形的形成,这意味着更差的信息压缩。由于注意力层依赖线性变换从残差流中提取数据,残差流不能处于高度压缩的格式。它需要针对线性读取进行优化。我听过类似"智能来自数据的压缩"这样的说法。当前的架构模式创造了不 heavily 压缩数据的强烈动机,而是以线性格式存储,不管好坏。
接下来我观察modded-nanogpt中第一个MLP在前110步训练中激活值的变化。在此阶段,模型已达到约4.5的损失。
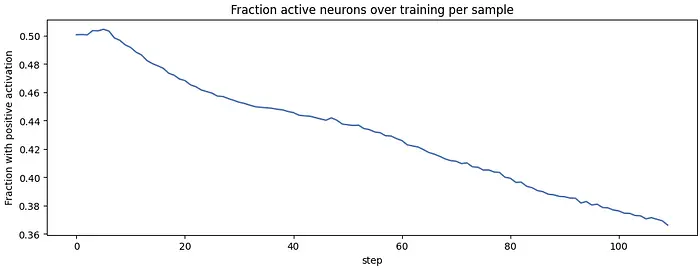
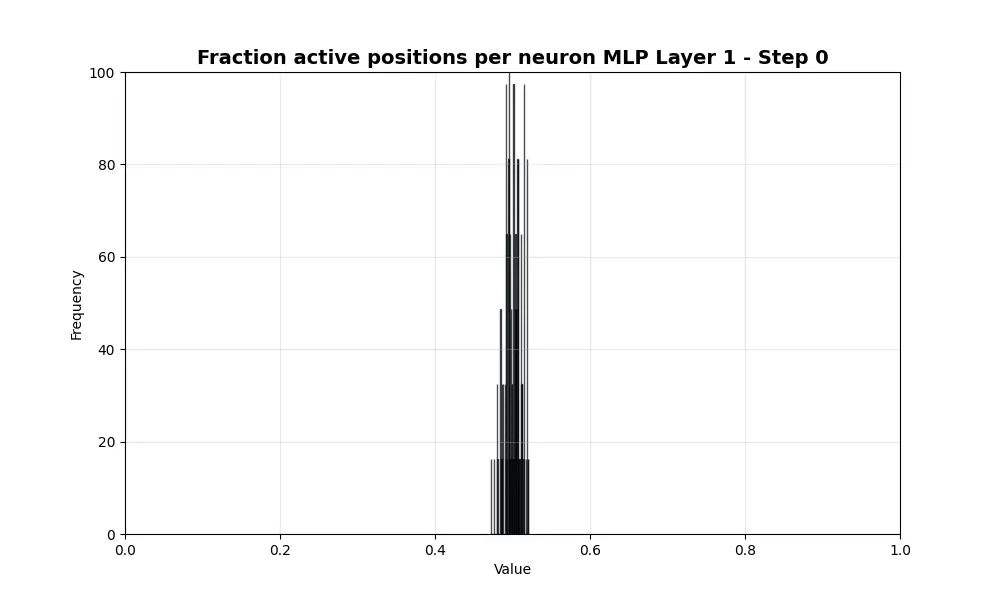
所有神经元是否都经历了从0.5到0.36的相同衰减率?下图显示了每个神经元随时间的演变。直方图中的每一项是一个神经元,x轴显示从128个采样token中激活该神经元的比例。
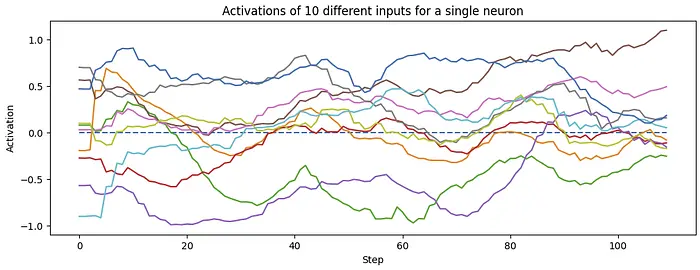
然后我观察单个神经元,看10个不同输入的激活如何随时间变化。(这里我不再按root(d_model)因子缩放。所以图表上的1大约对应上面的1/27)
接下来我放大到激活值随时间的完整分布。
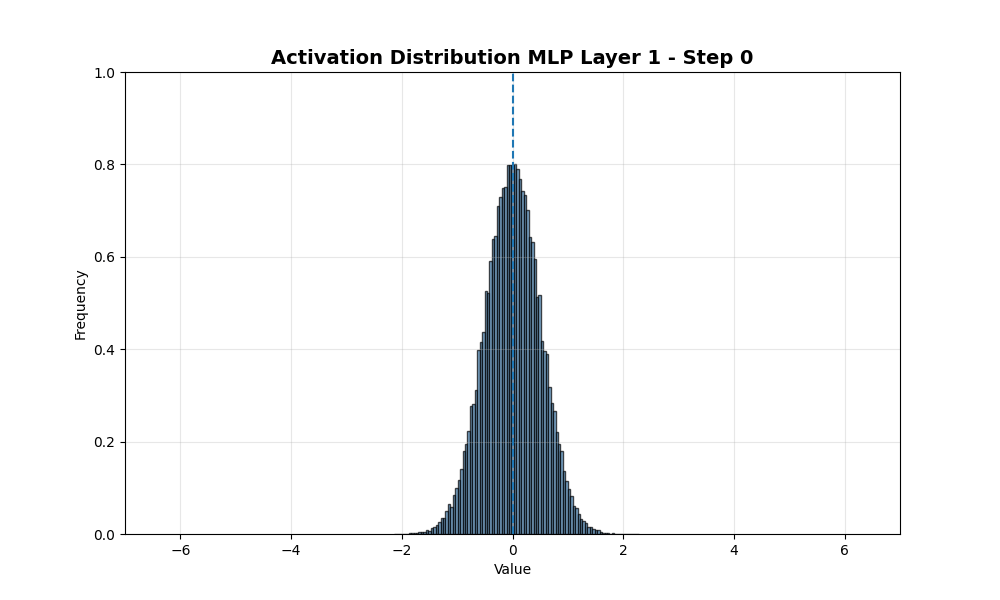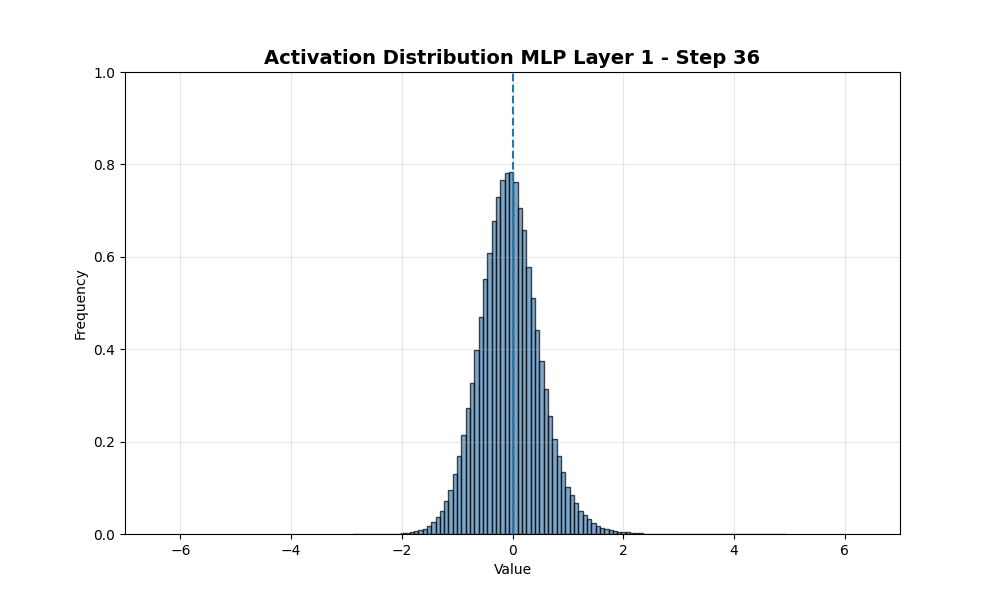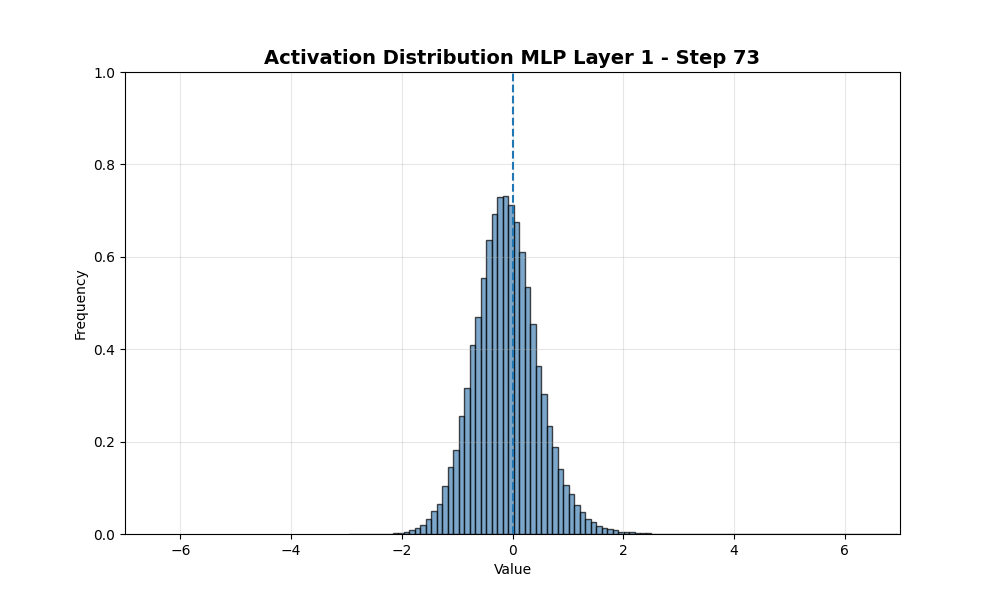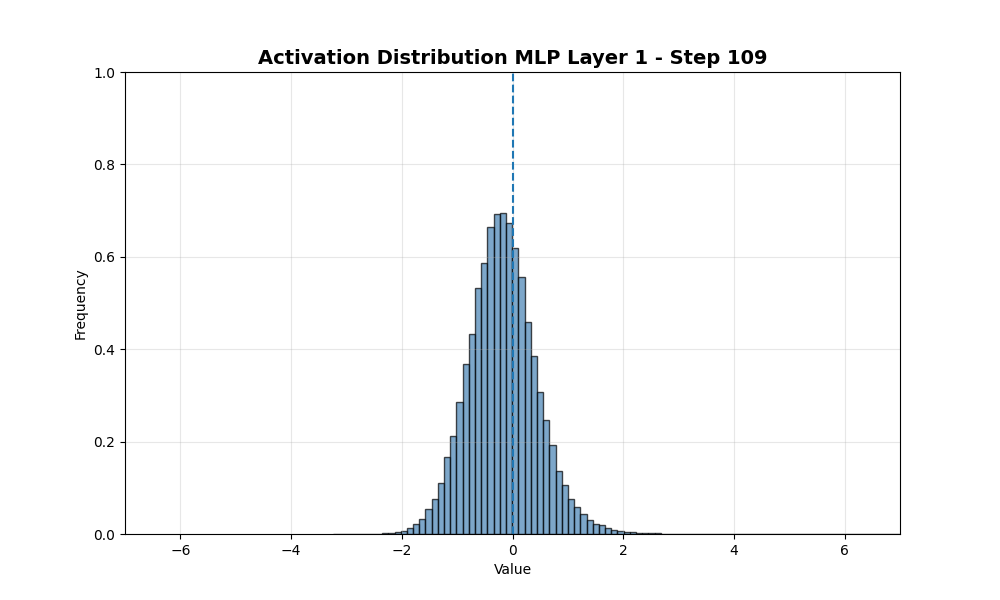
总体而言,分布保持了类似的标准差并向左移动。这个图与我之前做的海藻类比不符……这让我对假设激活值将如何表现更加谨慎……数据并没有在0处的障碍附近聚集。相反,它继续向更负的方向移动。这是什么原因?是否与优化器中的动量项有关?还是因为我在这里对所有神经元分布求和,模式退化为正态分布?接下来我只看排名前100和后100的样本。
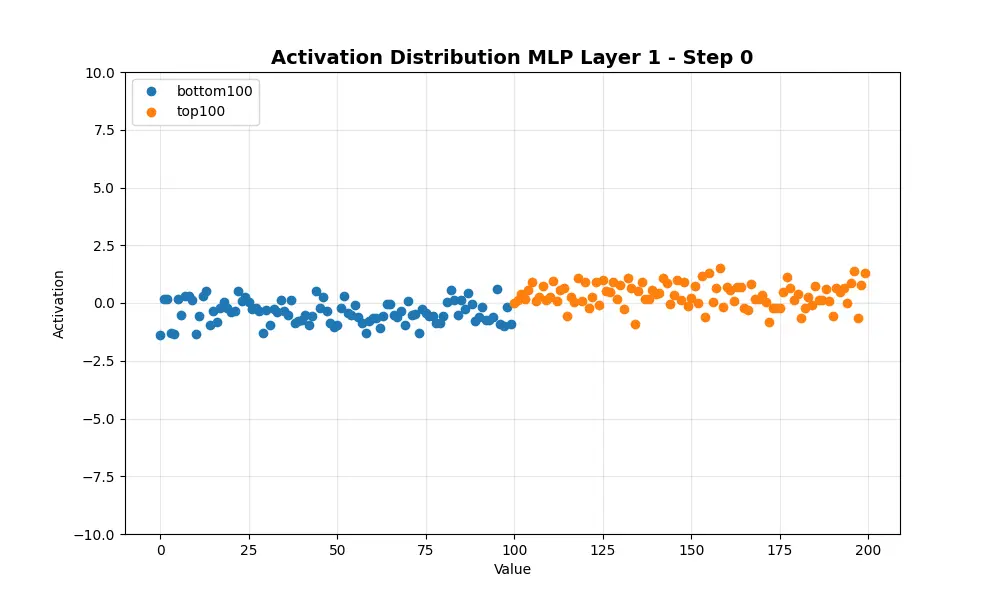
最终获得最高值的激活往往从正值区域开始。最终获得最负值的激活往往从负值区域开始。不过,仍然存在一些交叉。分布在正值侧的方差略高。
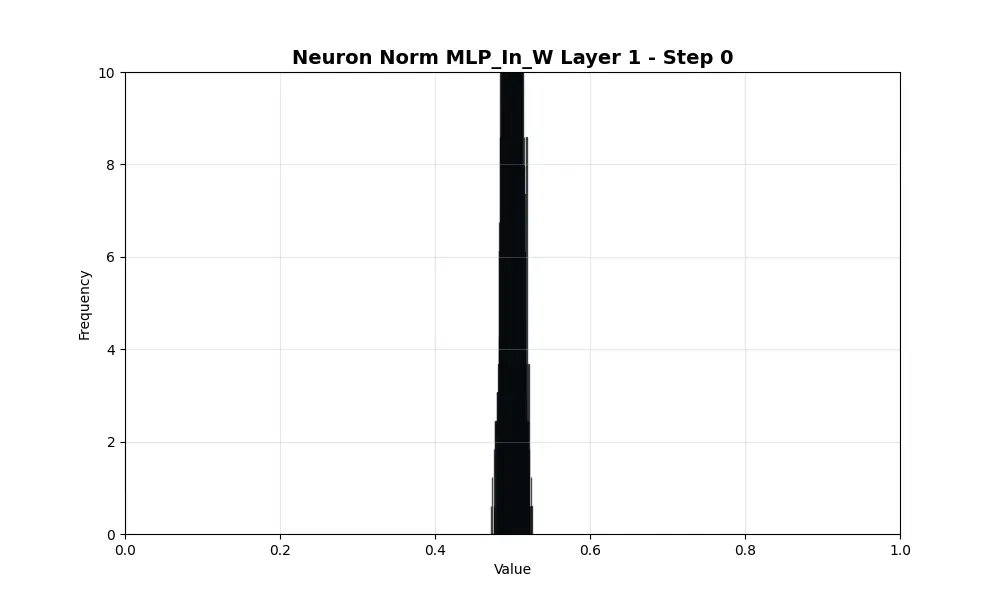
激活幅度不仅取决于数据与mlp_in_projection之间的角度,还取决于mlp_in_projection向量的幅度,而这个向量没有被归一化。这个幅度在训练过程中如何变化?我绘制了前110步训练中所有3000个神经元的幅度变化。
3、优化
我应该寻找哪些洞察来改进模型架构?几个观察:
- 数据都从0-10度的对齐区域开始,因此在选择激活函数时,我可以关注这个区域在输入归一化操作下的行为。
- 随着时间推移,更少的神经元对任何给定输入产生激活。这实际上是否对模型有利并不明显,因为它可能是由ReLU引起的"梯度盲区"导致的。如何思考这个问题?
我对MLP行为的心理模型是:
- 在初始化时,每个神经元随机采样一半的输入token,对每个token有不同的权重。这个子集将具有一些与总体不同的特征。这就是使该神经元独特的原因。
- 然后该子集将被推向神经元确定为对样本最优的方向。(例如,如果我们碰巧采样了描述金融的token,那么神经元将添加一个对应于金融概念的向量)。任何不应该被推向该方向的条目的激活值将被驱动到零。
将每个样本初始化为总体的50%是否合理?改变阈值的一种方法是将ReLU(x)²替换为ReLU(x-c)²。这等价于给MLP输入投影添加偏置,并约束给定MLP的所有d_model偏置项相等。
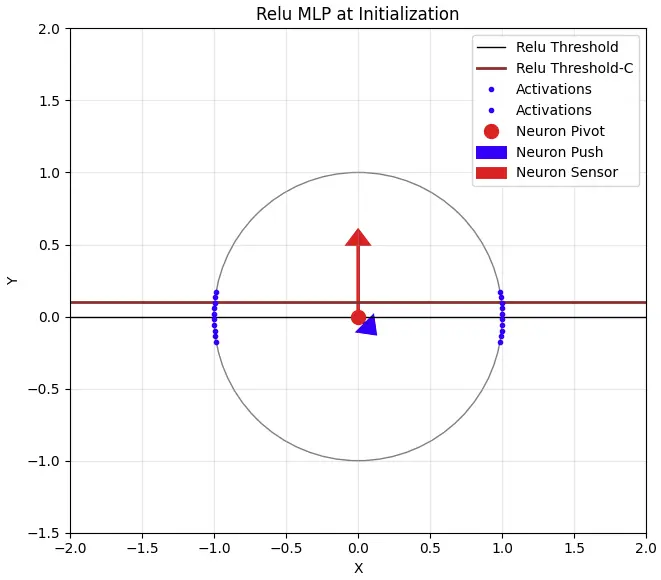
如果我们将阈值提高到上面棕色线的位置,那么在初始化时更少的神经元被激活。这里有几个方案:
- 将C固定为正值,使得每个神经元在初始化时只采样约30%的token。可以假设,如果对大总体的50%进行采样,样本统计量将非常接近总体统计量,神经元之间不会有差异化,直到训练后期才会被激发。大量的小样本可能更容易学习。
- 将C固定为负值,使得每个神经元在初始化时采样约70%的token。这减少了神经元初始的盲区。然而,如果稀疏性在后期确实是有用的属性,我们现在将很难在不将输入限制到输入空间的一个大幅缩减的子集中的情况下实现神经元的稀疏性。
- 让C成为可学习的参数。如果我们从负值开始,那么在初始化时神经元将能看到大量数据点。然后或许C会在训练过程中增大,使神经元能够对哪些数据点激活它更有选择性。
实施方案3:
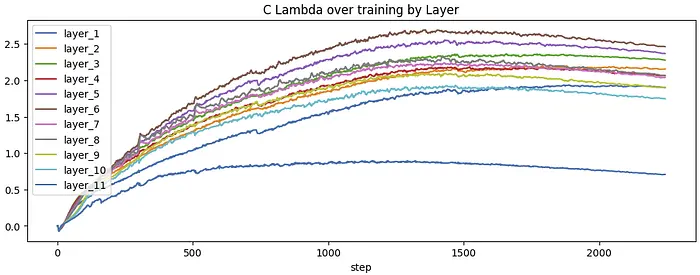
有趣的是,最后一层的C值比其他层小得多。模型最终损失为3.2777,没有明显更好,但也没有经过学习率调优。
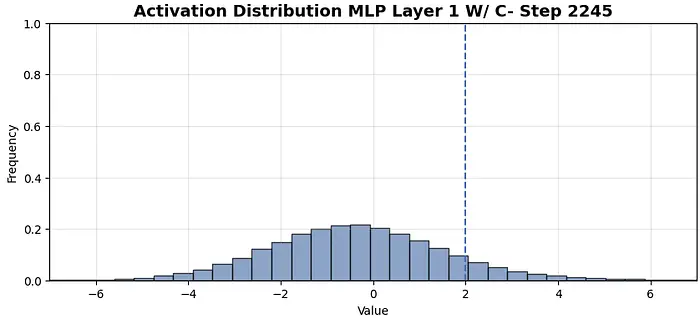
C值为2意味着到第2245步时,任何给定输入只有10%的神经元处于激活状态。
MLP输出投影90%的计算工作是在与零相乘!这看起来极其低效。然而,由于每个位置激活不同的神经元,如何以一种与优化内核兼容的方式利用这种稀疏矩阵乘法并不明显。我需要一个能在稀疏矩阵和稠密矩阵之间执行矩阵乘法的内核,其中稀疏矩阵是激活函数的输出。
以-0.5的初始化值再试一次:
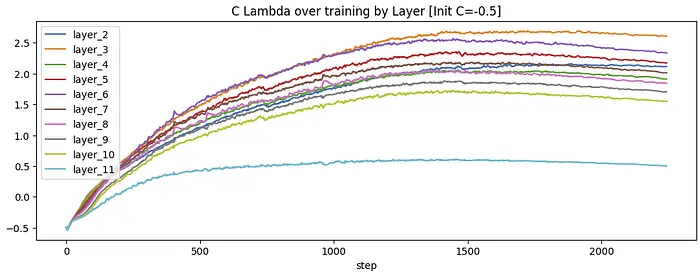
最终损失为3.2787(统计上无差异)。最后一层再次表现出明显不同的行为。重新审视模型架构,最后一层是唯一没有跳跃连接的层。
if i >= n and i<11:
gate = torch.sigmoid(skip_weights[i - n]) # in (0, 1)
x = x + gate * skip_connections.pop()
如果我从第10层移除跳跃连接,它是否表现出类似的模式?答案:不会。
一个奇怪的想法:如果我将输入神经元配对,使每个神经元有一个相反的配对会怎样?例如,当一个神经元输出5时,另一个输出-5。这将让我节省一半的输入计算,以及11*768*3024/2=1200万参数。这也将消除这种稀疏性动态,因为配对将始终覆盖100%的神经元。测试这可能会让我更好地理解稀疏性的价值。实现:
class MLP(nn.Module):
def __init__(self, dim: int):
super().__init__()
hdim = 4 * dim
self.c_fc = nn.Parameter(torch.empty(hdim//2, dim))
self.c_proj = nn.Parameter(torch.empty(dim, hdim))
def forward(self, x: Tensor):
x = F.linear(x, self.c_fc.type_as(x))
x = torch.cat([x, -x], dim=-1)
x = F.relu(x).square()
x = F.linear(x, self.c_proj.type_as(x))
return x
最终损失为3.3136,相当差。运行速度更快但不足以补偿更高的损失。
现在我尝试在两个神经元之间创建大小为1的间隙的C:
class MLP(nn.Module):
def __init__(self, dim: int):
super().__init__()
hdim = 4 * dim
self.c_fc = nn.Parameter(torch.empty(hdim//2, dim))
self.c_proj = nn.Parameter(torch.empty(dim, hdim))
self.c_fc.label='mlp_in'
self.c_proj.label='mlp'
std = 0.5 * (dim ** -0.5)
bound = (3 ** 0.5) * std
with torch.no_grad():
self.c_fc.uniform_(-bound, bound)
self.c_proj.zero_()
def forward(self, x: Tensor):
x = F.linear(x, self.c_fc.type_as(x))
# offset each neuron by 0.5 from midpoint
x = torch.cat([x-0.5, -x-0.5], dim=-1)
x = F.relu(x).square()
x = F.linear(x, self.c_proj.type_as(x))
return x
损失同样为3.31。
如果在初始化时使权重配对,但允许其发散会怎样?表现略差于基线。
随机尝试想法似乎没有带来太多进展。我认为我需要更深入地理解数据。一旦确认保存125步的所有权重没有耗尽我的云预算,我计划扩展到完整运行,以便详细观察每个MLP在整个训练过程中的演化。进一步调查最后一层为什么对C lambda的反应不同可能也是有前景的。另一个方向是挑选激活值最大的神经元,查看触发它们的具体token以及它们在训练过程中的演化。
补充一些来自记录第一层和最后一层MLP 600步激活值的图表。每个图对应一个神经元。每条线是一个token的激活值在训练过程中的变化。
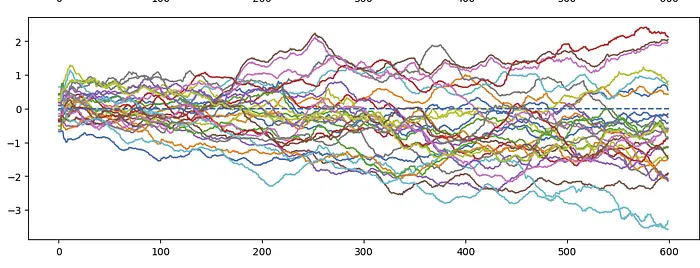
第1层示例:
第12层示例:
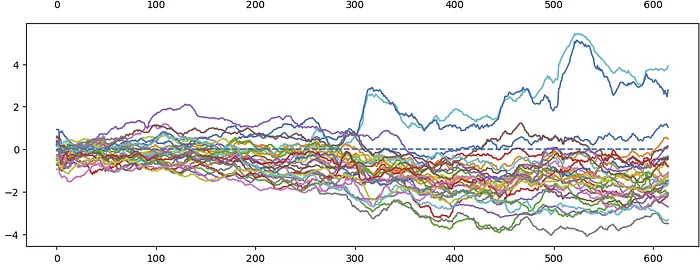
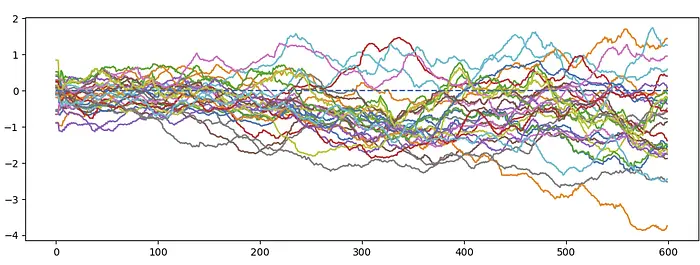
在600步的训练过程中,大约90%的激活值至少有一次跳过ReLU阈值之上。但似乎通常存在一种向下的压力,将激活值推回到阈值之下,使得随时间推移激活数量减少。激活值并不会正好聚集在阈值附近,因为它们通常有大量的抖动。例如,如果一个激活在层中的1000个神经元上是活跃的,那1000个神经元将产生梯度更新,影响休眠神经元中激活的位置。由于神经元输入方向之间并非100%正交,且神经元数量是维度的4倍。
原文链接: An Investigation into the MLP and Relu² Activation
汇智网翻译整理,转载请标明出处
