Autoresearch:ML研究自动化
一个GPU。一个markdown文件。100次实验,通宵完成。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
在我读博士期间,我大多有一个夜间习惯:晚上9点左右设置一次训练运行。调整一个超参数。也许改变学习率,也许增加注意力头的数量。按下回车键。然后我会坐在那里看一会儿损失曲线,发现已经11点了,去睡觉,第二天早上醒来发现运行在凌晨3点崩溃了,因为内存溢出错误——这个错误我本应该发现的。
第二天,修复bug,再试一次。幸运的话一天一次实验。如果诸事顺利,两次。
现在把这个乘以地球上的每一位ML研究员。我们数以千计的人,坐在终端前,一次手动调整一个变量,运行一次实验,等待,检查,再调整。这就是2026年大多数ML研究仍然运作的方式。
Andrej Karpathy刚刚说:如果电脑自己完成所有这些会怎么样?他发布了一个叫做autoresearch的仓库。它正好解决了这个问题。
1、问题所在:研究是令人尴尬的顺序化
这是ML研究在会议上没有人谈论的脏秘密。你大部分时间不是花在绝妙的想法上。你大部分时间花在这个循环上:改点什么,训练,评估,决定是否有帮助,重复。在我博士期间研究从CT扫描预测昏迷预后时,我有时会花整整一周只是为了找出新架构的学习率和批量大小的正确组合——当在30000个3D CT扫描上训练神经网络时,网格搜索太贵了。
不是因为问题在智力上困难。是因为反馈循环太慢。你改一个东西。你等待。你看结果。你改另一个东西。你再等。
一个AI代理不会吃饭。它不会睡觉。它没有存在危机(据我们所知)。它每小时可以运行12次实验。那大概是一晚上100次。这就是autoresearch所做的。
2、它实际上如何工作
设置简单得近乎可笑。三个文件。
- prepare.py 下载训练数据并训练一个分词器。你只运行一次。
- train.py 是一个约630行的完整GPT训练设置。模型架构、优化器(Muon + AdamW)、训练循环、评估。所有东西都在一个文件里。这是AI代理修改的文件。
- program.md 是一个markdown文档,你可以在其中为代理写指令。把它想象成一份研究简报。"专注于架构变化。""尝试不同的批量大小。""保守一点,一次只改一个东西。"无论你想要什么。
循环是这样的:
- 代理读取
program.md - 代理对
train.py做修改 - 训练正好运行5分钟
- 代理检查验证分数(每字节比特数)
- 如果分数改进了,提交更改。如果没有,回滚。
- 回到步骤1。
就是这样。你去睡觉。你醒来。你的git历史中有100次实验,最好的更改都被保留了。
3、为什么5分钟是天才设计
让我解释为什么固定5分钟预算是如此明智的设计选择,因为它解决了一个大多数人甚至没有意识到存在的问题。
当你比较实验时,你需要公平的基线。如果实验A运行5分钟,实验B运行20分钟,你不能直接比较它们的最终损失。当然运行时间长的会做得更好。这并不能告诉你哪个想法更好。
通过将墙上时钟时间精确固定在5分钟,每个实验都是直接可比较的。代理可以改变任何东西。架构、批量大小、层数、优化器设置,甚至词汇量大小。你仍然可以比较实验1和实验87,因为它们都有相同的时间窗口。
指标是 val_bpb(验证每字节比特数),与词汇量大小无关。所以如果代理决定尝试一个完全不同的分词器,比较仍然是公平的。
有一个权衡。你的结果特定于你的硬件。H100会收敛到与RTX 4090不同的最优设置。但这实际上是一个特性。Autoresearch为你的GPU找到最好的模型。
4、奇怪的部分:你现在在编程Markdown
让我暂停一下。作为一个研究员,我花了数年学习Python、PyTorch、CUDA调试、分布式训练技巧。所有这些都是为了能写出更好的训练脚本。
在autoresearch中,你不写训练脚本。你写一个markdown文件,告诉AI代理如何考虑写训练脚本。
如果你想让代理专注于架构搜索,你更新markdown。如果你想让代理专注于优化器调优,你更新markdown。markdown就是你的研究策略。
Karpathy说当前的program.md已经是"90% AI写的"。所以甚至指令也是部分由AI生成的。人类不再是程序员了。人类是研究主管。你设定议程。代理运行实验室。
这里有一个让我夜不能寐的元问题:如果program.md是真正的产品,而你可以在哪个program.md能带来最快改进上迭代,那么你就在做关于如何做研究的研究。你在优化优化器。如果这种优化本身可以被自动化……
5、Karpathy的通宵结果
他的第一次通宵运行:83次实验,15次保留改进。代理发现了一些东西,比如将总批量大小从524K减半到262K(在相同时间窗口内提供更多训练步骤),调整warmdown schedules,添加warmup,尝试滑动窗口注意力模式,并将RoPE基础频率从10,000调整到50,000。
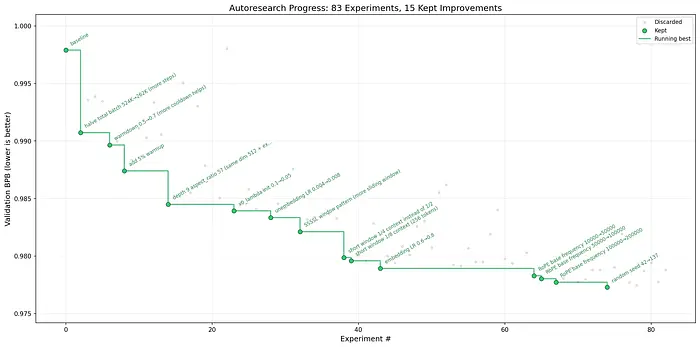
这些不是随机的更改。这些是高级ML研究员会尝试的东西。代理只是以12倍的速度做它们,没有咖啡休息。
他还在8xH100上运行一个更大版本,使用完整的nanochat代码库。276次实验,29次保留改进。他的评论:"我就让它运行一会儿。"
在发布仓库的几天前,他发推文说:"这就是后AGI的感觉。我什么都没碰。brb sauna。"他在开玩笑。但只是部分。
6、它不能做什么(目前)
让我坦诚谈谈局限性。没有实验跟踪。没有Weights & Biases,没有MLflow。对于100次通宵实验,你只能滚动控制台输出和git日志。这很粗糙。
代理不能读论文。它不能从最近的arxiv预印本中查找新的激活函数并尝试它。它只能通过修改代码并检查损失是否下降来发现东西。这是暴力搜索,不是信息研究。
单GPU、5分钟限制意味着你无法探索只在规模化时才有效的想法。混合专家、长上下文训练、分布式分片策略。都不行。
而且代理有时会崩溃。社区已经在提交修复:强制代理实际读取tracebacks,在评估前保存检查点,修复VRAM泄漏。这些是无聊但必要的补丁,将演示与你可以实际通宵运行的东西区分开来。
7、为什么我认为这很重要
我过去几年用旧方式做ML研究。手动。一次一个实验。午夜盯着Weights & Biases仪表盘。调试只在训练运行第3小时才出现的CUDA错误。
autoresearch不会取代研究员。它取代了研究中最繁琐的部分:尝试、评估、重复的苦差事。研究人员仍然决定要探索什么。研究人员写program.md。研究人员早上审查结果,决定进一步调查什么。但是通宵的时间——那些你通常会睡觉或盯着终端的时间——现在属于代理了。
Karpathy在README中写了一个小虚构的前言,设定在一个研究完全由自主代理群体完成的未来。代码库已经被修改得超出人类理解。没有人能验证代理关于其进展的声明是否属实。
他总结道:"这个仓库是这一切如何开始的故事。"两天内近2000颗星。仓库才诞生48小时,已经有macOS分支、社区bug修复和改进代理崩溃恢复的pull requests。
一个每天运行一次实验的研究生现在与每晚运行100次实验的GPU竞争。瓶颈不是计算。不是模型。是你的program.md的质量。
原文链接: Andrej Karpathy's New Project Just Turned One GPU Into a Research Lab
汇智网翻译整理,收费标准标明出处
