Autoresearch 快速上手
过去,前沿人工智能研究是由“肉体计算机”完成的,人类通过会议进行协调。那个时代正在消逝。研究正朝着在计算集群上运行的自主人工智能智能体集群的方向发展。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
本周早些时候,Andrej @karpathy 发布了 autoresearch。
于是我尝试了一下:用一条命令运行 AI 研究:
make gen CONTEXT="explore attention-free LLM"
DATA=TinyStories
GOALS="lowest val_bpb"我将分享如何用一条命令运行 autoresearch 并在仪表盘中跟踪实验。
autoresearch 在 X 上爆红,三天后仍然在我的页面上很火。
1、为什么这很有趣
简而言之:
- 你定义一个 program.md 文件,描述如何训练模型。
- 智能体编写训练代码,运行实验,评估结果并迭代。
研究循环不再需要手动运行实验,而是实现了自动化。
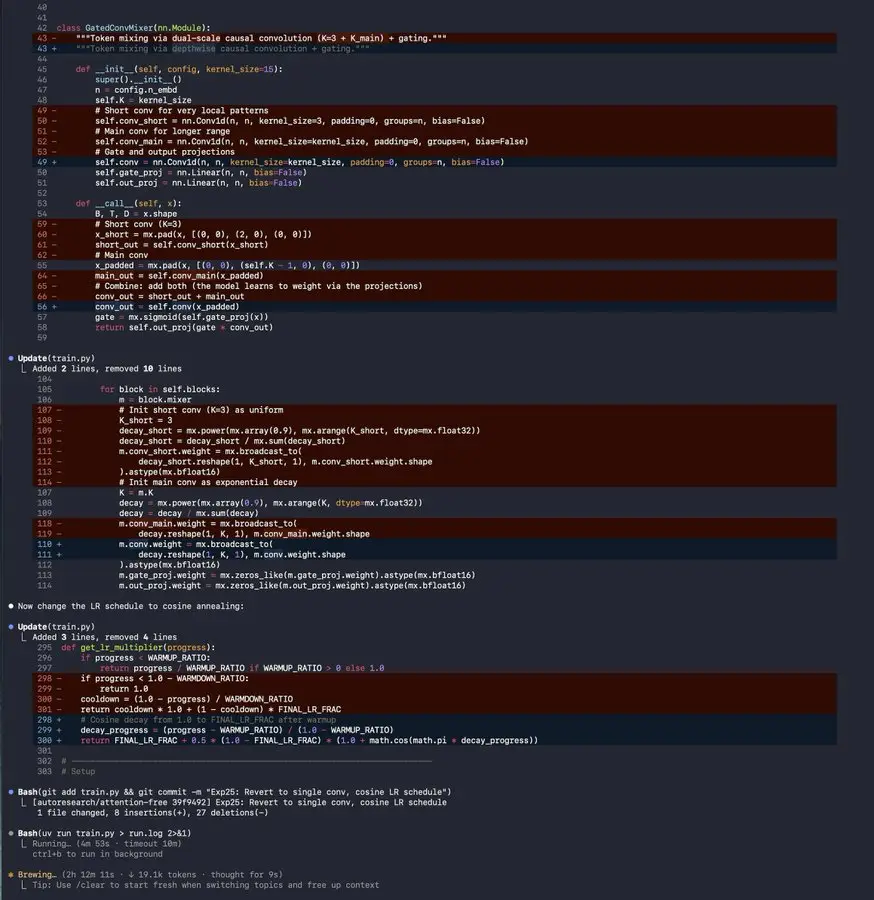
以下是我的智能体运行实验循环约两小时的代码片段。
引用 Andrej Karpathy 的话:
过去,前沿人工智能研究是由“肉体计算机”完成的,人类通过会议进行协调。那个时代正在消逝。研究正朝着在计算集群上运行的自主人工智能智能体集群的方向发展。
这意义重大。
昨晚我启动了一个实验,然后和朋友们一起去画画两个小时。在我离开的这段时间里,智能体一直在运行实验。
这让我意识到机器学习研究中可以消除多少等待时间。
智能体不会取代研究人员,但它们可以消除很多等待时间。
2、问题
查看 autoresearch 代码库时,这个想法很简单,但设置仍然需要:
- 编写 program.md 文件
- 构建实验结构
- 准备训练代码
- 跟踪结果
所以我想到一个简单的办法:为什么不使用 LLM 来搭建这些文档呢?
您可以克隆此仓库并自行尝试:Github - autoresearch-gen
简而言之,autoresearch-gen 的功能包括:
- 生成自动研究样板代码
- 对您的实验进行分析
- 生成 Excalidraw 图表,展示系统工作原理
- 通过代理提交跟踪实验和代码更改
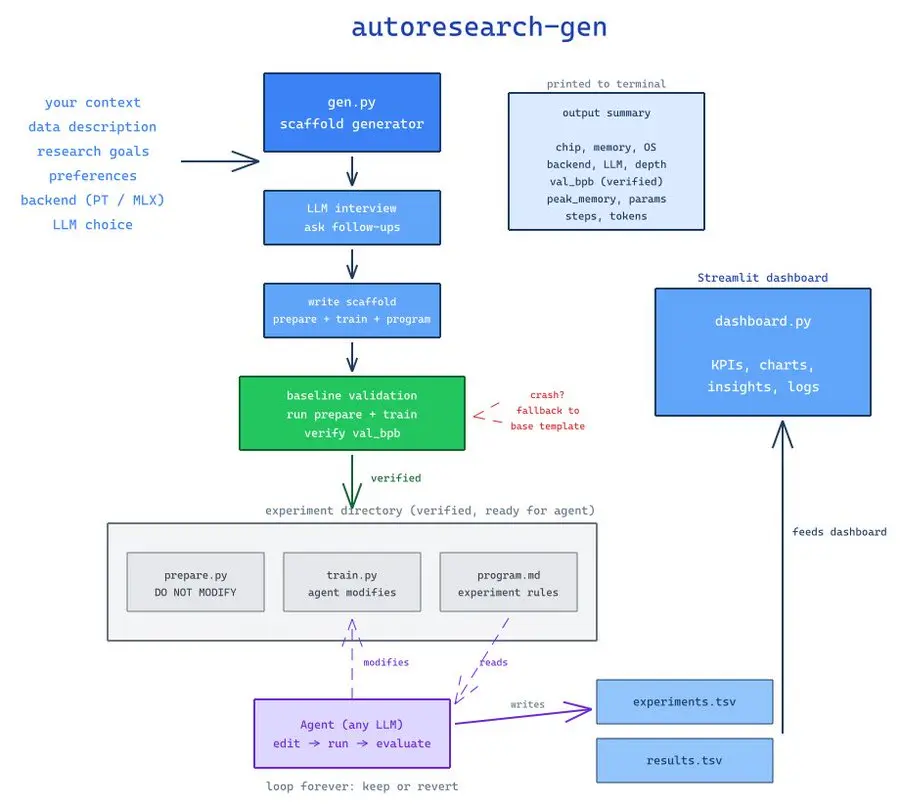
要开始使用,您只需告诉 LLM 您想要做什么、要使用什么数据以及实验目标。
3、使用一条命令运行自动研究
make gen EXP=experiments/attention-free \
CONTEXT="Exploring attention-free LLM architectures \
on M5 Max 48GB (RWKV / SSM / linear attention)" \
DATA="roneneldan/TinyStories" \
GOALS="Lowest val_bpb without softmax attention"您选择的 LLM 将生成结构化的自动研究代码。
大多数研究可视化工具都需要在 Jupyter Notebook 中使用 matplotlib。对于新手来说,这意味着需要切换工具并编写分析代码。
因此,我使用 Plotly 构建了一个简单的 Streamlit 仪表盘,它可以通过调用以下命令生成实验统计数据并提供基本的实验跟踪功能。
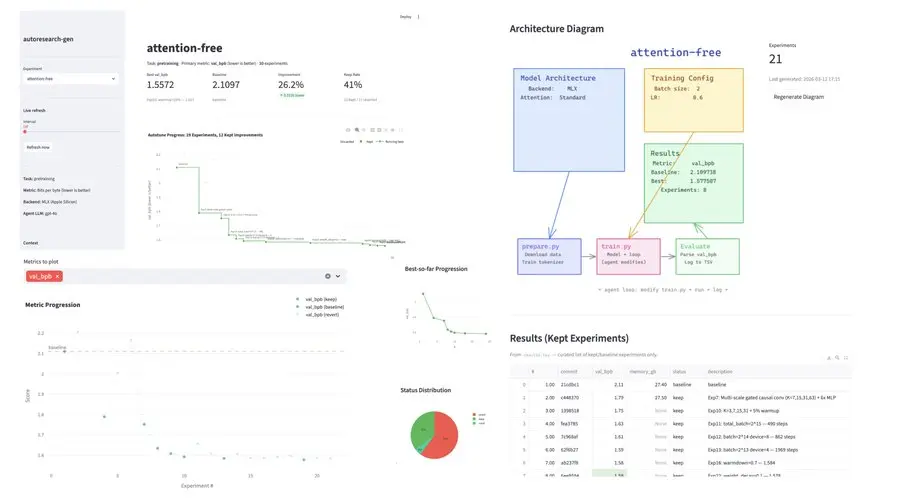
make dashboard4、仪表盘
您可以使用 GitHub 仓库中包含的示例数据运行此简单仪表盘进行测试。
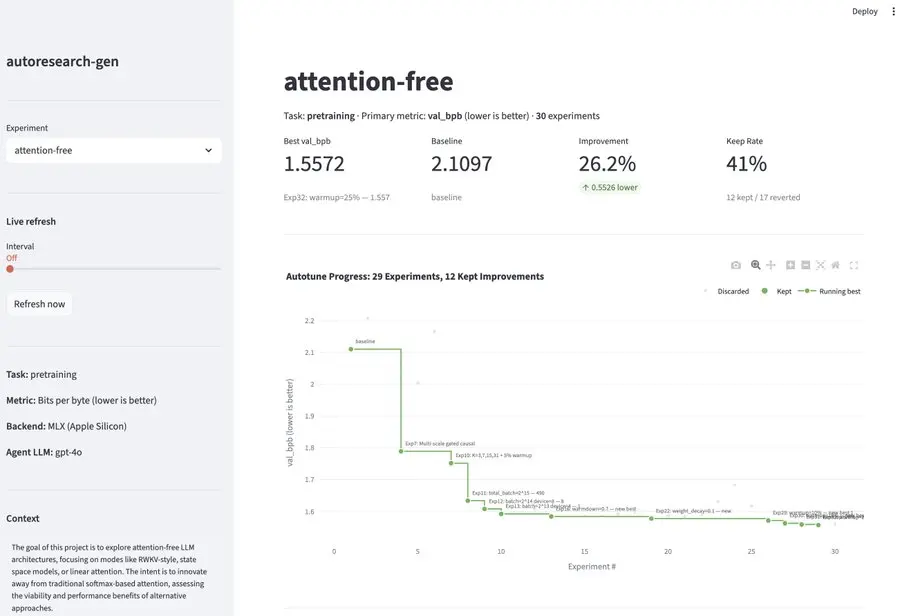
我在午餐时间进行了一次快速测试:
- 30 个实验
- 41% 的保留率
- 在 TinyStories 数据集上提升了约 26%
目标是探索无注意力机制的 LLM 架构并降低 val_bpb。
结果会因输入和配置而异,因此请随意尝试不同的想法。
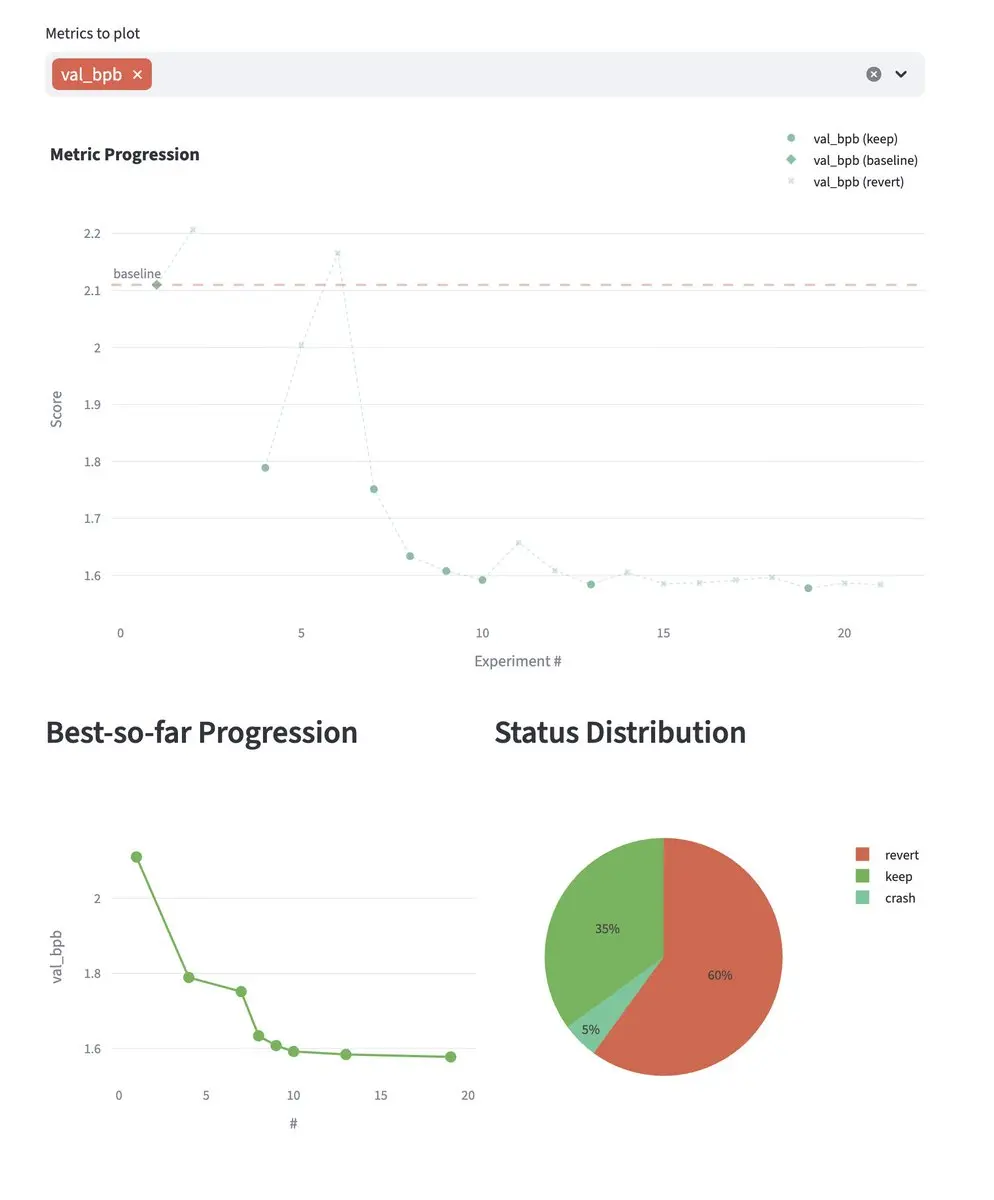
该仪表盘还允许您分析更多数据,了解实验的有效性,并使用 make diagram 命令或单击 Streamlit 仪表盘上的 regenerate diagram 来生成 Excalidraw 架构图以展示流程。

本项目的目标很简单:让人工智能研究更容易上手,尤其对于刚刚接触人工智能的人来说。
5、挑战
在开发本项目的过程中,我注意到另一个问题:经过多次迭代后,模型可能会开始遗忘部分上下文信息。
重要的变量或实验细节会随着时间的推移而丢失,这意味着我们需要一种更稳健的方式来存储状态,并更好地利用实验循环。
这与 Andrej Karpathy 最近提到的情况也有关联,他的自动研究实验室在一次 OAuth 服务中断期间被彻底摧毁。
这种情况表明,长时间运行的研究代理需要更好的状态管理、恢复和故障转移机制。
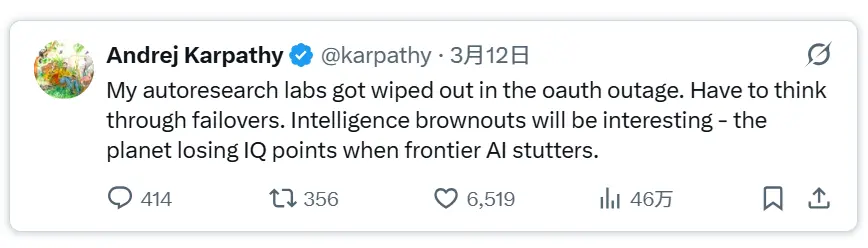
换句话说,要充分发挥自动研究系统的优势,我们可能需要一个更有状态、更具弹性的架构。
我将在后续文章中对此进行更深入的探讨。我的 Claude 代码已经运行实验 18 小时了。
原文连接:Karpathy’s autoresearch Quickstart
汇智网翻译整理,转载请标明出处
