为AI代理构建自适应检索路由
一个实践指南,教你如何将检索变成可学习的决策层——包含代码、架构和生产权衡。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
向量搜索在“一次查询,一次回答”的工作流中表现很好。但代理式AI系统会在计划中多次检索——早期的小失误会变成累积错误,导致整个任务失败。 本文展示了如何构建一个自适应检索路由,它: 选择关键字、向量或混合检索 使用查询特征(ID、罕见词、长度)做出决策 学习从评估反馈中改进 记录一切以便调试和分析。
点击这里查看Github上的源代码。
1、问题:静态检索在代理工作流中失效
向量搜索 + 原始RAG在工作流简单时表现惊人地好:
用户查询 → 检索 → 生成答案 → 完成
代理系统不是这样的流程。
代理多次在计划中检索:
- 选择使用哪个工具
- 填充该工具的参数
- 验证中间状态
- 从错误中恢复
- 回答后续问题
早期的检索失误不仅产生稍差的答案,还会变成累积错误:
步骤 1:检索错过正确的文档
↓
步骤 2:代理基于错误的上下文推理
↓
步骤 3:代理选择错误的工具 / 错误的操作
↓
步骤 4:下一步检索基于错误的状态
↓
步骤 5:系统偏离真实情况越来越远
↓
结果:任务失败 + 浪费计算 + 用户沮丧
在这种情况下,“更好的嵌入”不是一个完整的策略。 你需要一个系统,可以决定每个步骤如何检索,并随着时间推移改进这个决策。
为什么这很重要
关键洞察: 在代理工作流中,检索不是组件——它是 决策点*。
而决策应该:* 明确(你可以看到选择了什么) 可衡量(你可以评分结果) 可改进(你可以更新策略)
2、解决方案:自适应检索路由
从系统角度来说,学习的检索不是“一种花哨的检索器”。它是将检索视为一个策略的框架:
π(query, context, history) → retrieval_strategy
其中“策略”可以是:
- 关键字/BM25类搜索(精确的词匹配)
- 向量相似性搜索(语义相似性)
- 混合检索(两者结合)
- 元数据过滤
- 时效性偏置搜索
- 图遍历 / 实体检索
核心做法是使这种选择明确,并用以下内容支持:
组件 → 目的
- 查询特征 → 用于路由决策
- 路由器策略 → 选择检索策略
- 检索器 → 获取前k个文档
- 评估器 → 评分检索质量
- 遥测 → 记录决策和结果
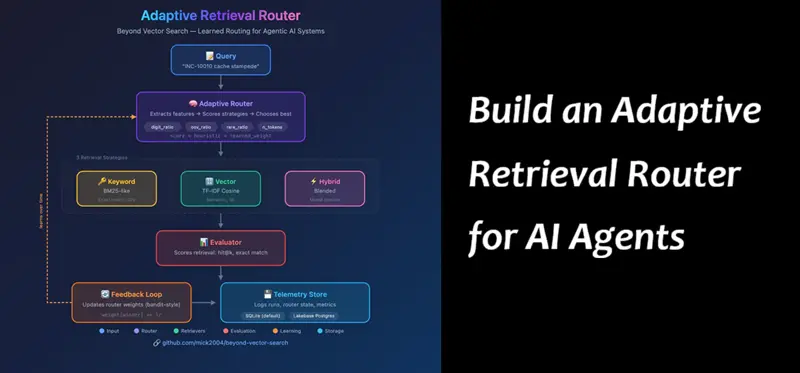
3、架构概述
这是我们要构建的完整流程:

自适应检索路由器架构: 查询 → 路由器(提取特征,评分策略) → 检索器(关键字/向量/混合) → 评估器 → 反馈循环 → 遥测
数据流:
- 查询进入系统
- 路由器提取特征并选择策略
- 检索器(关键字、向量或混合)获取前k个文档
- 评估器对结果进行评分(如果存在标签)
- 反馈循环根据评分更新路由器权重
- 遥测记录一切用于调试和分析
4、查询特征提取
在路由器可以选择策略之前,它需要理解查询。我们实时计算几个特征:

代码:特征提取
# src/beyond_vector_search/text.py
@dataclass
class QueryFeatures:
n_tokens: int
digit_ratio: float # 字符中数字的比例
oov_ratio: float # 不在语料库中的词的比例
rare_ratio: float # 罕见词的比例def extract_query_features(query: str, corpus_stats) -> QueryFeatures:
tokens = tokenize(query)
digit_chars = sum(1 for c in query if c.isdigit())
digit_ratio = digit_chars / max(1, len(query))
oov_count = sum(1 for t in tokens if t not in corpus_stats.vocab)
oov_ratio = oov_count / max(1, len(tokens))
rare_count = sum(1 for t in tokens if t in corpus_stats.rare_terms)
rare_ratio = rare_count / max(1, len(tokens))
return QueryFeatures(
n_tokens=len(tokens),
digit_ratio=digit_ratio,
oov_ratio=oov_ratio,
rare_ratio=rare_ratio,
)
关键洞察: 这些特征计算成本低(无需模型推理),但具有高度预测性。例如,“INC-10010 cache stampede”这样的查询有: 高digit_ratio(ID中有数字) 高rare_ratio(INC-10010出现在非常少的文档中) 低n_tokens(短查询) 这个特征表明“使用关键字搜索!”而这正是路由器将学会的。
示例特征值

5、路由器决策(策略)
路由器接收查询特征并决定使用哪种检索策略。这是策略,我们正在学习。
路由器为每种策略计算得分:
score[strategy] = heuristic[strategy] + learned_weight[strategy]
其中:
- 启发式 = 从查询特征得出的规则得分
- 学习的权重 = 从过去评估结果中学习的偏差
得分最高的策略获胜。
代码:路由器决策
# src/beyond_vector_search/router.py
def choose(self, query: str) -> tuple[Strategy, QueryFeatures, dict]:
"""为给定查询选择检索策略。"""
# 步骤 1:提取查询特征
feats = extract_query_features(query, self.corpus_stats)
# 步骤 2:从特征中计算启发式得分
heuristic_keyword = (
1.25 * feats.digit_ratio # 数字暗示ID → 关键字
+ 1.00 * feats.oov_ratio # OOV词 → 需要精确匹配
+ 1.25 * feats.rare_ratio # 罕见词 → 关键字胜出
+ (0.10 if feats.n_tokens <= 3 else 0.0) # 短查询 → 关键字
)
heuristic_vector = 0.50 * (1.0 - min(1.0, feats.oov_ratio + feats.rare_ratio))
# 向量在词常见时表现最好(语义匹配)
heuristic_hybrid = (
0.75 * (feats.digit_ratio + feats.oov_ratio + feats.rare_ratio)
* (1.0 - feats.digit_ratio)
)
# 混合信号:一些ID + 一些自然语言
# 步骤 3:添加学习的权重
state = self.load_state()
score_keyword = heuristic_keyword + state.weights["keyword"]
score_vector = heuristic_vector + state.weights["vector"]
score_hybrid = heuristic_hybrid + state.weights["hybrid"]
# 步骤 4:选择最佳策略
scores = {"keyword": score_keyword, "vector": score_vector, "hybrid": score_hybrid}
strategy = max(scores, key=scores.get)
return strategy, feats, {"scores": scores, "heuristics": {...}}
关键洞察: 启发式为我们提供了一个合理的起点——在任何学习发生之前,路由器已经做出了合理的决策。学习的权重然后 优化 该行为,基于你的领域实际有效的东西。 这比纯学习(需要大量数据)或纯规则(无法适应)更好。
可视化决策
查询: "INC-10010 cache stampede"
特征:
digit_ratio: 0.25
oov_ratio: 0.33
rare_ratio: 0.67
n_tokens: 3
启发式得分:
keyword: 1.25*0.25 + 1.00*0.33 + 1.25*0.67 + 0.10 = 1.61
vector: 0.50 * (1 - min(1, 0.33+0.67)) = 0.00
hybrid: 0.75 * (0.25+0.33+0.67) * (1-0.25) = 0.70
学习的权重(训练后):
keyword: +0.12
vector: -0.04
hybrid: +0.08
最终得分:
keyword: 1.61 + 0.12 = 1.73 ← 获胜者
vector: 0.00 - 0.04 = -0.04
hybrid: 0.70 + 0.08 = 0.78 → 路由器选择: KEYWORD
亲眼见证
这是当你运行笔记本时的样子:

路由器在行动: 对于查询“pipeline failed for INC-10010 cache stampede”,路由器检测到ID模式并选择混合策略。它检索到确切的事件文档(DOC-010)得分为1.0,加上相关的缓存文档。
6、检索执行(3种策略)
一旦路由器选择了策略,相应的检索器就会运行。我们实现了三种:
策略1:关键字检索器(BM25类)
当它获胜时: 包含ID、代码、罕见词、精确短语的查询。
如何工作: BM25风格的评分,奖励精确的词匹配并带有IDF加权。
# src/beyond_vector_search/retrievers.py
class KeywordRetriever:
"""BM25风格的评分,带有精确的词匹配。"""
def search(self, query: str, k: int = 5) -> list[RetrievalResult]:
query_tokens = tokenize(query)
scores = []
for doc in self.corpus:
doc_tokens = tokenize(doc.text)
score = 0.0
for token in query_tokens:
if token in doc_tokens:
# BM25风格:TF * IDF
tf = doc_tokens.count(token)
idf = self.idf.get(token, 1.0)
score += tf * idf
scores.append((doc, score))
# 返回按分数排序的前k个
scores.sort(key=lambda x: x[1], reverse=True)
return [RetrievalResult(doc=d, score=s) for d, s in scores[:k]]
例子: 查询“INC-10010”找到包含该ID的确切文档。
策略2:向量检索器(TF-IDF余弦相似度)
当它获胜时: 自然语言问题、同义词、语义相似性。
如何工作: 字符n-gram TF-IDF向量 + 余弦相似度。这是密集嵌入的CPU友好替代方案。
# src/beyond_vector_search/retrievers.py
class VectorRetriever:
"""字符n-gram TF-IDF余弦相似度。"""
def __init__(self, corpus: list[Document]):
self.corpus = corpus
# 使用字符n-gram(3-5个字符)构建TF-IDF矩阵
self.vectorizer = TfidfVectorizer(
analyzer="char_wb",
ngram_range=(3, 5),
)
texts = [doc.text for doc in corpus]
self.doc_vectors = self.vectorizer.fit_transform(texts)
def search(self, query: str, k: int = 5) -> list[RetrievalResult]:
query_vec = self.vectorizer.transform([query])
# 余弦相似度
similarities = cosine_similarity(query_vec, self.doc_vectors)[0]
# 前k个
top_indices = similarities.argsort()[-k:][::-1]
return [
RetrievalResult(doc=self.corpus[i], score=similarities[i])
for i in top_indices
]
例子: 查询“如何修复慢查询?”即使没有这些确切的词,也能找到关于查询优化的文档。
策略3:混合检索器(混合)
当它获胜时: 混合ID和自然语言的查询。
如何工作: 同时运行关键字和向量,然后混合得分。
# src/beyond_vector_search/retrievers.py
class HybridRetriever:
"""混合关键字和向量得分。"""
def __init__(self, keyword: KeywordRetriever, vector: VectorRetriever, alpha: float = 0.5):
self.keyword = keyword
self.vector = vector
self.alpha = alpha # 关键字与向量的权重
def search(self, query: str, k: int = 5) -> list[RetrievalResult]:
# 获取两者的结果
kw_results = {r.doc.doc_id: r.score for r in self.keyword.search(query, k=k*2)}
vec_results = {r.doc.doc_id: r.score for r in self.vector.search(query, k=k*2)}
# 归一化得分到[0, 1]
kw_max = max(kw_results.values()) or 1.0
vec_max = max(vec_results.values()) or 1.0
# 混合
all_doc_ids = set(kw_results) | set(vec_results)
blended = []
for doc_id in all_doc_ids:
kw_score = kw_results.get(doc_id, 0) / kw_max
vec_score = vec_results.get(doc_id, 0) / vec_max
combined = self.alpha * kw_score + (1 - self.alpha) * vec_score
blended.append((doc_id, combined))
blended.sort(key=lambda x: x[1], reverse=True)
return [RetrievalResult(doc=self.get_doc(d), score=s) for d, s in blended[:k]]
例子: 查询“解释TID-88410291中的超时错误”需要:
- 关键字来查找特定的事务ID
- 向量来理解“超时错误”
每种策略获胜的情况

7、反馈循环(学习)
这就是使路由器自适应的原因。在检索之后,我们对结果进行评分并更新路由器的权重。
评估循环
对于每个带标签的查询在评估集中:
1. 运行所有3种策略(关键字、向量、混合)
2. 对每种策略进行评分(hit@k:是否检索到了预期的文档?)
3. 更新路由器权重(奖励赢家,惩罚输家)
4. 将所有内容记录到遥测中
代码:离线评估
# src/beyond_vector_search/evaluate.py
def evaluate_all(k: int = 5) -> dict:
"""在所有带标签的查询上运行评估并更新路由器权重。"""
labels = load_labels() # 从data/labels.jsonl加载
router = AdaptiveRouter(...)
keyword = KeywordRetriever(...)
vector = VectorRetriever(...)
hybrid = HybridRetriever(...)
scores = []
for label in labels:
query = label.query
expected_doc_id = label.expected_doc_id
# 运行所有3种策略
kw_results = keyword.search(query, k=k)
vec_results = vector.search(query, k=k)
hyb_results = hybrid.search(query, k=k)
# 对每种策略进行评分(hit@k:如果预期文档在top-k中则为1,否则为0)
kw_score = 1.0 if expected_doc_id in [r.doc.doc_id for r in kw_results] else 0.0
vec_score = 1.0 if expected_doc_id in [r.doc.doc_id for r in vec_results] else 0.0
hyb_score = 1.0 if expected_doc_id in [r.doc.doc_id for r in hyb_results] else 0.0
# 更新路由器权重(类似多臂老虎机)
router.update_from_scores(scores={
"keyword": kw_score,
"vector": vec_score,
"hybrid": hyb_score,
})
# 记录所选策略的分数
chosen_strategy, _, _ = router.choose(query)
chosen_score = {"keyword": kw_score, "vector": vec_score, "hybrid": hyb_score}[chosen_strategy]
scores.append(chosen_score)
# 记录到遥测
telemetry.log_run(query=query, strategy=chosen_strategy, score=chosen_score)
return {
"n": len(labels),
"mean_score": sum(scores) / len(scores),
"router_state": router.load_state().to_dict(),
}
代码:权重更新(多臂老虎机风格)
# src/beyond_vector_search/router.py
def update_from_scores(self, scores: dict[str, float]) -> RouterState:
"""根据策略得分更新路由器权重。"""
state = self.load_state()
# 找到这个查询的最佳策略
best_strategy = max(scores, key=scores.get)
# 更新权重:奖励赢家,惩罚输家
for strategy in state.weights:
if strategy == best_strategy:
state.weights[strategy] += state.lr # 奖励
else:
state.weights[strategy] -= state.lr / (len(state.weights) - 1) # 惩罚
self.save_state(state)
return state
关键洞察: 这是一个 多臂老虎机 方法。每个检索策略是一个“手臂”,我们学习哪些手臂在不同类型的查询中最有效。 随着时间的推移,权重会收敛:weight_keyword对于包含大量ID的查询增加,weight_vector对于自然语言查询增加。
示例:权重演变
初始状态:
weight_keyword: 0.0
weight_vector: 0.0
weight_hybrid: 0.0
经过14次评估查询后:
weight_keyword: +0.12 (赢了8次)
weight_vector: -0.04 (在ID查询中经常输)
weight_hybrid: +0.08 (在混合查询中赢)
查看评估结果
这里是评估循环产生的内容:

评估报告: 在运行完所有14个带标签的查询后,路由器达到了97.9%的平均分数。学习的权重显示路由器是如何适应的:weight_vector: 0.25 增加是因为向量检索在这个语料库中赢得更多。

持久化的路由器状态: 学习的权重存储在遥测数据库(SQLite)中。这个状态在运行之间保持不变,因此路由器记得它学到的内容。你可以看到weight_vector: 0.25, weight_keyword: -0.125, weight_hybrid: -0.125。
8、行业示例:金融科技退款
让我们看看这如何应用于一个现实场景。
场景
一个金融科技支付操作代理帮助分析师调查退款。工作流是多步骤的:

没有自适应路由(失败模式)
步骤 1:对“CB-774193在TID-88410291”进行向量搜索
→ 错过罕见的ID
→ 返回通用的“退款概述”文档
步骤 2:代理基于错误的上下文推理
→ 认为这是一个通用的退款问题
步骤 3:代理选择错误的剧本
→ 推荐“标准争议流程”
→ 但这个案例需要“重复提交”处理
步骤 4:后续检索基于错误的状态
→ 查询错误的案例类型
→ 继续偏离
结果:错误的解决方案,客户升级,需要人工干预
有了自适应路由(成功)
步骤 1:路由器检测到高digit_ratio + rare_ratio
→ 选择KEYWORD检索
→ 找到CB-774193的确切案件记录
步骤 2:路由器检测到自然语言问题
→ 选择VECTOR检索
→ 找到“重复提交”政策文档
步骤 3:路由器检测到混合查询(ID + 语义)
→ 选择HYBRID检索
→ 找到类似案例 + 正确剧本
结果:正确解决方案,无升级,代理下次学习
差异

9、常见错误(以及如何避免)
错误1:优化错误的指标
问题: 你在玩具数据集上优化“精确匹配”。路由器过度拟合到关键字检索,因为你的评估集是ID密集型的。
症状: 离线指标很好,但向量密集的生产查询失败。
解决方法: 使用分层评估:
- 证据检索质量(hit@k)
- 答案忠实度(答案是否使用了证据?)
- 任务成功率(用户是否完成了他们的目标?)
错误2:忽略评估噪声
问题: 你的评估器有噪声(例如,LLM评分有高方差)。由于奖励不一致,路由器波动。
症状: 权重每周翻转。策略不稳定。
解决方法:
- 从确定性的代理开始(精确文档ID匹配)
- 后期添加LLM评分,但要有置信度阈值
- 使用有限更新(限制每次批次的权重变化)
错误3:没有影子模式就部署
问题: 你直接将路由器更新推送到生产。一个边缘情况崩溃了。
症状: 生产指标回归。用户抱怨错误的检索。
解决方法: 仔细推出:
- 仅离线: 在历史数据上训练和评估
- 影子模式: 记录新策略会做什么(不要立即使用)
- 小范围测试: 将5%的流量导向新策略,比较指标
- 默认: 验证后推出到100%
错误4:没有记录足够多的信息
问题: 有些东西坏了,但你无法调试,因为你不知道路由器选择了什么以及为什么。
症状: “它以前有效。” 没有人知道发生了什么变化。
解决方法: 记录一切:
- 查询文本
- 提取的特征
- 选择的策略
- 所有策略的得分
- 检索的文档ID
- 评估得分(如果带标签)
- 时间戳
10、生产中的故障模式
添加路由器 + 反馈循环使检索更强大,但它也创造了新的故障模式:
延迟开销
问题: 评分多个检索器增加了计算和尾延迟。
缓解方法:
- 首先使用廉价特征进行路由(不要运行所有检索器)
- 仅在线运行所选的检索器
- 离线评分所有臂(不在热路径中)
策略震荡
问题: 小数据集或流量模式的变化导致权重“震荡”。
缓解方法:
- 限制更新(限制权重变化)
- 平滑(指数移动平均)
- 最小数据阈值(在N样本之前不要更新)
离线与在线不匹配
问题: 你的离线评估集不代表真实的代理查询。
缓解方法:
- 从生产中记录真实轨迹
- 抽样并标注困难案例
- 持续刷新评估集
指标游戏
问题: 路由器优化一个容易的代理(如hit@k),这与任务成功无关。
缓解方法:
- 分层指标:证据质量 + 答案忠实度 + 任务成功
- 不要优化单一数字
11、测量与防护措施
如果你想让学习的检索真正改善你的代理,要在多个层次上进行测量:
证据质量
- hit@k / recall@k 在带标签的证据上
- 引用覆盖率:答案是否引用了检索的证据?
答案质量
- 忠实度 / 依据性 检查
- 精确匹配(仅适用于玩具或严格领域)
路由器质量
- 遗憾:所选策略 vs 最佳策略(离线)
- 校准:置信度 vs 结果
- 稳定性:策略每周翻转的频率
系统健康状况
- 每个阶段的 p95/p99 延迟
- 每个成功任务的成本(尤其是在多步骤循环中)
- 漂移信号:按段划分的路由分布变化
12、自己尝试(5分钟)
选项A:本地(任何带有Python 3.11+的机器)
# 克隆仓库
git clone https://github.com/mick2004/beyond-vector-search
cd beyond-vector-search
# 安装
pip install -e .# 运行单个查询
python -m beyond_vector_search.run --query "如何修复INC-10010?"# 运行评估(更新路由器权重)
python -m beyond_vector_search.evaluate
预期输出:
{
"query": "如何修复INC-10010?",
"strategy": "hybrid",
"score": 1.0,
"top_k": [
{"doc_id": "DOC-010", "title": "Incident reference INC-10010", "score": 1.0},
...
],
"answer": "INC-10010指的是由于缺少请求合并导致的缓存风暴..."
}
选项B:Databricks
- 在 Databricks Repos 中克隆仓库
- 打开
notebooks/demo.py - 运行全部(默认使用SQLite)
笔记本逐步介绍了每个步骤并附有说明。请参阅路由器决策和反馈循环部分中的截图。
仓库内容
src/beyond_vector_search/ # 包装代码
├── router.py # 自适应路由器(策略)
├── retrievers.py # 关键字、向量、混合检索器
├── evaluator.py # 评分逻辑
├── telemetry.py # SQLite / Lakebase 日志记录
└── run.py, evaluate.py # CLI入口点
data/
├── corpus.jsonl # 200个玩具文档
└── labels.jsonl # 14个带标签的查询
diagrams/
└── architecture.svg # 架构图
notebooks/
└── demo.py # Databricks笔记本
13、结束语:将检索视为策略
代理式AI系统不会因为向量搜索“不好”而失败。它们失败是因为系统将检索视为一个静态原始在一个动态、多步骤决策过程中。
如果你想让代理随着时间的推移不断改进,你需要:

组件目的多种检索策略创建分歧以从中学习路由器能够解释其选择使决策可见遥测使结果可检查安全更新策略的评估循环**学习和改进
仓库有意保持最小,这样你可以清楚地看到“学习的检索”在哪里,并用你自己的数据进行扩展。
原文链接:Beyond Vector Search: Building an Adaptive Retrieval Router for Agentic AI Systems
汇智网翻译整理,转载请标明出处
