构建生产级语音智能体:综合指南
这里展示的模式来源于生产部署、开源框架以及当今构建语音AI基础设施的团队。无论您是每月处理100个通话的个人项目,还是处理10,000个并发通话的平台,这些模式都适用。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
本文适合已经看过演示并想部署真实产品的工程师。如果您只是连接了一个API,播放了一些音频,就称之为语音智能体——那么实际工作才刚刚开始。
这里展示的模式来源于生产部署、开源框架(LiveKit、Pipecat、Pipecat Flows)以及当今构建语音AI基础设施的团队。无论您是每月处理100个通话的个人项目,还是处理10,000个并发通话的平台,这些模式都适用。
语音AI智能体市场2024年估值24亿美元,预计到2034年将达到475亿美元。Gartner预测到2026年,对话AI将消除800亿美元的呼叫中心劳动力成本。语音AI风投资金从约3.15亿美元飙升至约21亿美元(2022年至2024年间)——两年内增长了近7倍。最新YC批次中22%是语音智能体公司。
1、为什么要用语音?实际案例
AI语音智能体以每次通话0.15-0.50美元的成本实现35-55%的响应率——相比人工客服每次15-30美元,具有24-40倍的成本优势
传统反馈渠道存在根本性的扩展问题。电子邮件调查的响应率仅为5-15%,且回答浅显。网络表单稍好一些。人工电话访谈能提供丰富的数据——40-60%的响应率——但每次通话成本15-30美元且无法扩展。
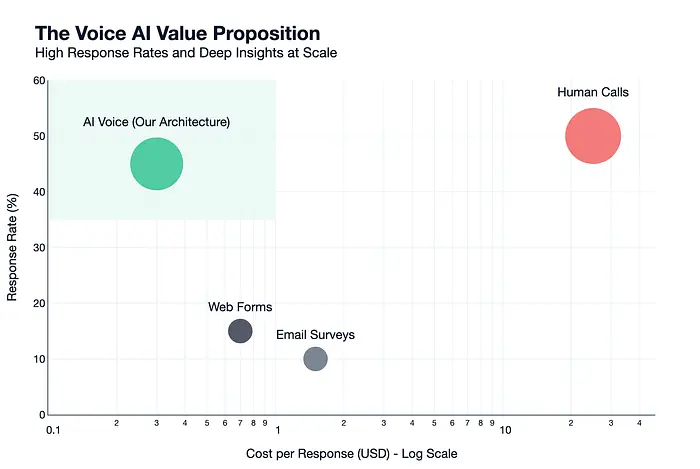
语音之所以有效,是因为人们在交谈时比打字时分享更多。一个能够倾听、适应并提出追问的AI,能够提取任何表格都无法获取的洞察。
投资格局证实了这一点。
- ElevenLabs达到3.3亿美元ARR,以110亿美元估值融资5亿美元D轮。
- SoundHound报告2025年收入1.69亿美元——同比近乎翻倍。
- Wayfaster在招聘筛选中实现90%候选人通过率——从人工筛选的50%提升而来。
Andreessen Horowitz的标志性分析简单明了:
"语音是人类交流中最频繁、信息密度最高的形式,首次实现了可编程化。"
但构建生产级语音AI很难。非常难。原因如下。
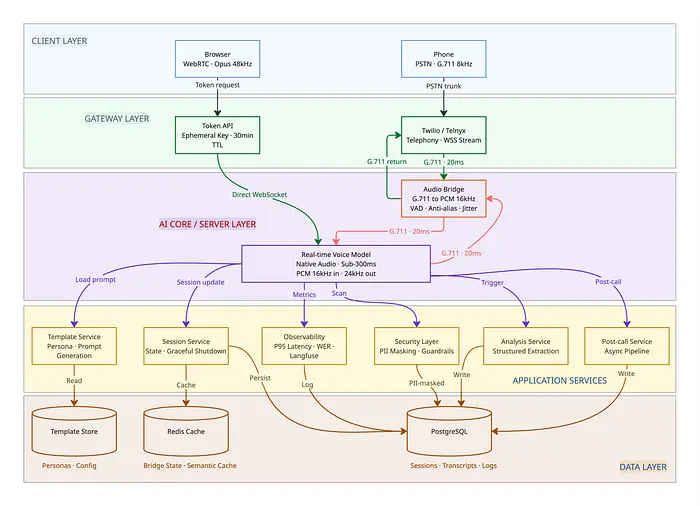
2、系统架构
生产级语音智能体通常服务两个渠道:浏览器(WebRTC)和电话(PSTN/Twilio)。这些渠道有不同的音频路径,但在共享的AI和数据层汇聚。
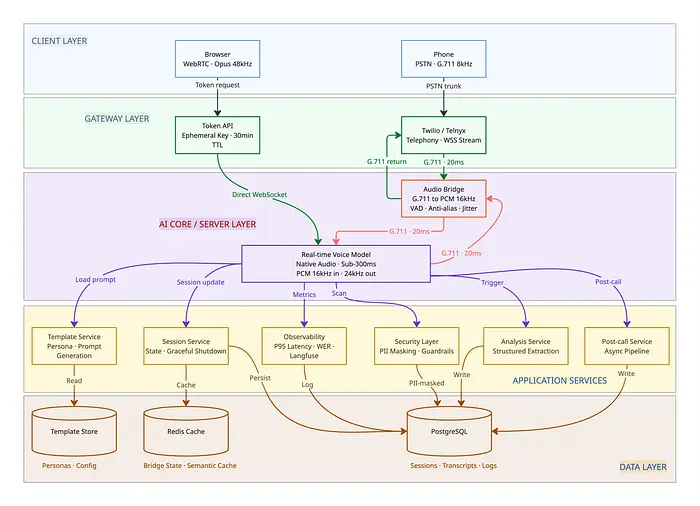
浏览器渠道: 客户端通过WebSocket使用临时令牌直接连接到AI模型。服务器从不接触音频——零服务器端延迟。
电话渠道: 电话提供商(Twilio、Telnyx)将PSTN音频桥接到服务器,服务器实时转码并转发给AI模型。服务器成为关键的中间人。
两个渠道都接入相同的通话后分析管道和会话存储。
3、为什么需要统一服务器?
常见的生产模式在单个进程中运行HTTP、WebSocket处理和后台服务。这看起来不对——大多数指南说要拆分——但这是由硬约束驱动的。
活跃的音频桥接存在于内存中。
每个桥接持有两个WebSocket连接和音频缓冲区。当API调用触发外呼电话时,桥接必须对片刻后接收音频流的WebSocket处理程序可访问。跨进程拆分意味着引入Redis来存储每20毫秒变化一次的状态——对于实时音频来说不可接受。
权衡:粘性会话、每个桥接约2MB、崩溃会断开所有活跃通话(通过优雅关机缓解)。
框架如何不同地解决这个问题:
4、竞争架构
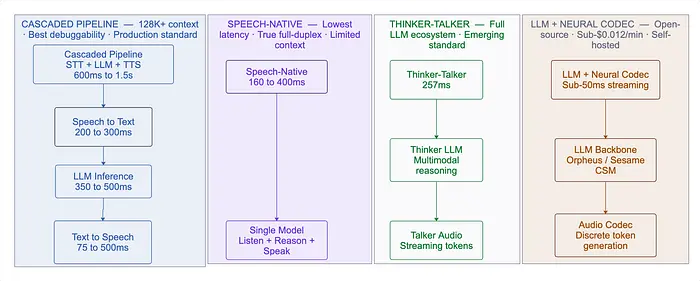
1. 级联管道(STT → LLM → TTS)
仍然是主导的生产架构。三个模型串联。关键优势:原生支持128K+令牌上下文,使RAG和工具调用变得简单。大多数平台——Retell、Vapi、Bland——使用这种方法。端到端延迟:600ms-1.5s。
2. 音频原生/语音原生
像Gemini Native Audio、Moshi和Ultravox这样的模型直接处理语音,无需文本转换。Moshi实现160-205ms延迟,具有真正的全双工能力。Ultravox直接将音频转换为LLM的维度空间,保留了文本转换中丢失的韵律和情感。
权衡是真实的: 有限的上下文窗口、更难的RAG、降低的可调试性。据报道至少有三家公司因合规原因从语音到语音回退——当智能体说错话时,几乎无法了解为什么。
3. 思考者-说话者混合
源自Qwen2.5-Omni:一个多模态"思考者"在隐藏状态空间处理输入,加上一个"说话者"转换为流式音频令牌。继承完整的LLM生态系统,同时产生约257ms的近双工语音。
4. LLM + 神经编解码器(新的开源标准)
第四种架构已成为主导的开源模式:LLM通过神经音频编解码器生成离散音频令牌。单个模型通过改变训练数据处理TTS、ASR和语音到语音。
关键实现:
- Orpheus TTS(Apache 2.0,Llama-3b骨干):25-50ms流式延迟(带KV缓存)、零样本语音克隆、情感标签(
<laugh>、<sigh>、<gasp>)。 - Sesame CSM-1B:双变换器架构,因跨越合成语音的"恐怖谷"而走红。
- Kimi-Audio:1300万+小时预训练,性能超越Qwen2-Audio。
- Cartesia Sonic 3:使用状态空间模型而非变换器——无论对话长度如何,内存使用恒定,3秒音频即可克隆语音。
这些不仅仅是研究产物。使用这些模型的自托管栈可以在单个L40S GPU上以 <$0.012/min运行。
如何选择
- 从级联开始,适合需要合规性和可审计性的企业。
- 使用语音原生,适合自然度最重要的消费产品。
- 考虑LLM+编解码器,如果需要开源灵活性和低于0.02美元/分钟的单位经济性。* 日益流行的混合方案:语音原生模型用于理解,单独的TTS用于受控输出。
5、音频桥接:真正的工程所在
这个组件将生产系统与演示区分开来。
电话网络使用G.711 µ-law——1972年标准化——8kHz采样率。AI模型期望16kHz输入的PCM,返回24kHz输出。桥接实时双向转码,处理完整的电话WebSocket协议。
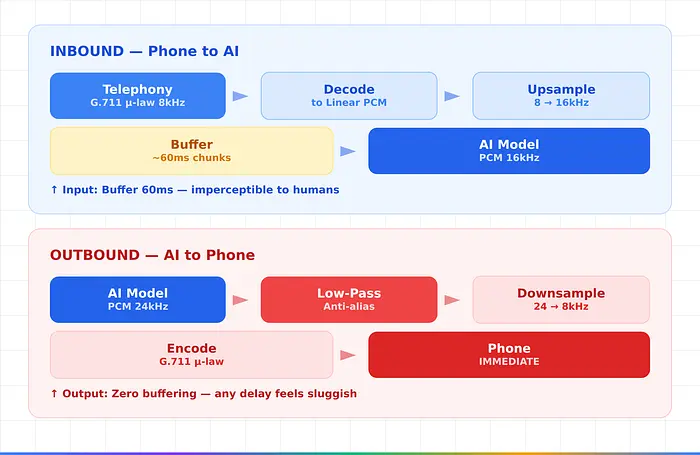
1. PSTN天花板问题
- 这是大多数人都忽略的关键洞察:当呼叫者在PSTN上时,WebSocket和WebRTC提供相同的音频质量——G.711将频率限制在约3,969 Hz。使用Opus的浏览器客户端显示2倍的频率内容。
- 真实世界的A/B测试发现传输层只占总对话延迟的不到5%。瓶颈在于模型,而非管道。
- 编解码器协商: Opus → G.722 → G.711回退(Telnyx)。避免G.729——压缩伪影会降低合成语音质量。
2. 抗混叠是必须的
- 不经过滤就将24kHz降采样到8kHz会产生混叠——频率折叠回可听范围,产生金属伪影。这是DIY语音智能体中最常见的质量问题。
- 解决方案:FIR低通滤波器,截止频率在奈奎斯特频率。预计算系数。使用256条目的µ-law编码查找表——在每秒8,000个样本下,逐样本函数调用会累积。
3. 非对称缓冲
- 电话 → AI:缓冲约60ms。 60ms输入延迟是不可察觉的。
- AI → 电话:零缓冲。 用户感知输出延迟比输入延迟负面约2倍。任何输出延迟都会让AI感觉迟钝。
4. 抖动缓冲区:隐藏的延迟税
这是大多数文章完全跳过的内容。自适应抖动缓冲区可以在任何AI处理开始前消耗50-200ms的300ms延迟预算。 您调整了数周,然后发现您将一半预算给了传输层。
根据ITU-T G.114,150ms单向延迟是"令人反感"的阈值。仅抖动缓冲区就可能消耗其中的三分之一。
5. WebSocket保活:长通话的无声杀手
对于30-60+分钟的通话(在医疗保健、法律、企业CRM中很常见),如果没有适当的保活机制,WebSocket连接会无声地失败。NAT设备、负载均衡器和反向代理强制执行本地测试期间不可见的超时策略。
AWS ALB默认60秒空闲超时。等待中的AI智能体每次通话都会触发这个超时。
生产配置:
- 15秒ping间隔,10秒超时。
- 应用级心跳(不仅是WebSocket Ping/Pong——某些负载均衡器会剥离控制帧)。
- 重连时的完整状态恢复:序列化STT缓冲区位置、对话状态机状态和待处理的TTS块。
没有这个,您最长、最有价值的通话会无声地断开。
6、音频处理管道
转码只是一步。生产系统需要完整的处理链。
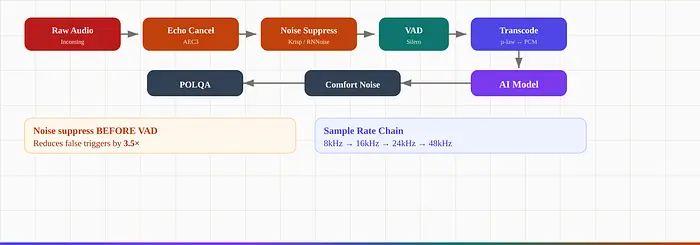
- 回声消除(AEC)。 呼叫者的麦克风捕获的TTS输出会产生触发错误打断的反馈回路。WebRTC有内置的AEC3;电话智能体依赖提供商级的回声消除。
- VAD之前的噪声抑制。 管道顺序很重要。Krisp的测试显示,VAD之前的噪声抑制将误触发率降低了3.5倍。开源替代方案:RNNoise(轻量级)、DTLN(Rust,M1上33ms/秒)。
- VAD配置。 Silero VAD的两个关键参数——
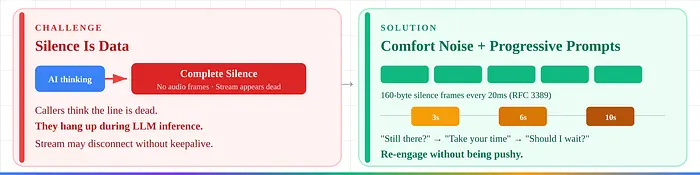
activation_threshold(0.3-0.35)和min_silence_duration(0.2秒)——比任何提示工程都有更大的UX影响。 - 舒适噪声生成。 在LLM推理期间,完全静默会让呼叫者挂断。RFC 3389定义了G.711的舒适噪声。生产系统每20ms发送160字节的静默帧,以表示"线路仍然活跃"(Twilio)。
- 音频质量测量。 使用POLQA(ITU-T P.863),而不是PESQ——PESQ对宽带音频产生错误评分。
7、延迟:语音智能体的生存威胁
在文本聊天中,2秒的响应是快的。在语音中,这是致命的。
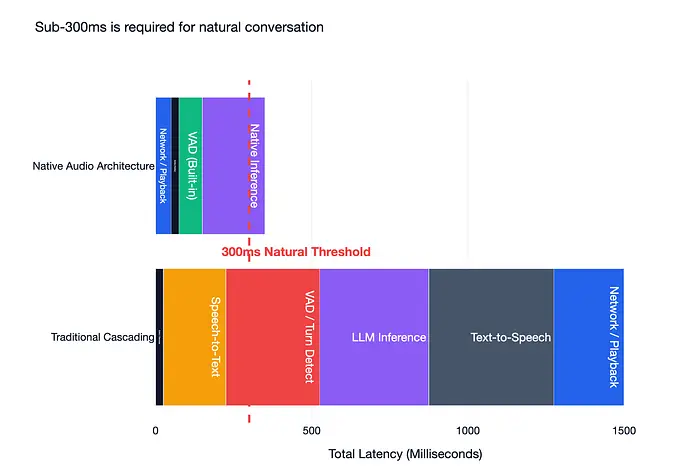
300ms是自然对话的阈值。 超过这个阈值,交互感觉机械。无代码平台在负载下达到3-4秒。
- 传统级联: 1.5-3秒端到端。
- 优化级联(流式Deepgram + Groq/Cerebras + ElevenLabs Flash):约600ms。
- 原生音频: 200-400ms。成本每分钟约高10倍,但完全消除了两个跳转。

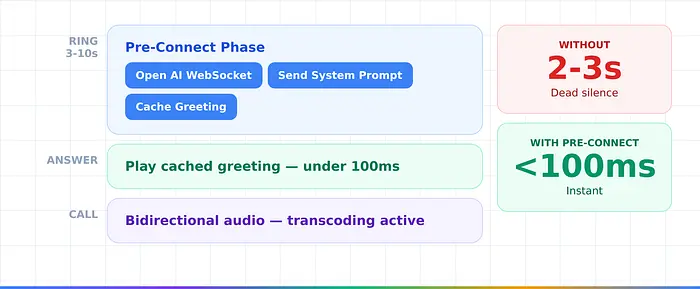
积极预连接模式
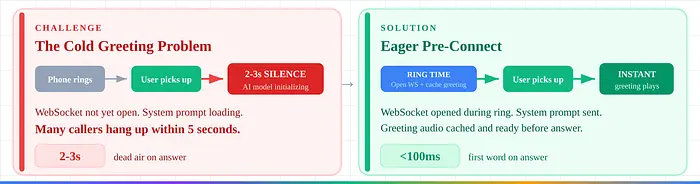
外呼电话有3-10秒的振铃时间——死时间。生产系统利用这个时间:在振铃期间打开AI WebSocket,发送系统提示,缓存问候语。当接听者接听时,AI问候在 <100ms 内播放,而不是2-3秒的沉默。
许多人在5秒内没人说话就会挂断。这个模式完全消除了这个问题。
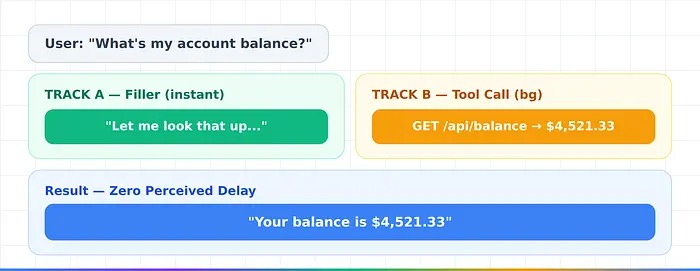
推测性工具调用
工具调用(账户查询、调度)会产生2-5秒的静默间隙。推测性工具调用运行两个并行轨道:轨道A流式播放填充语音("让我查一下..."),而轨道B静默执行工具。填充语音隐藏了1.5-2秒的延迟。仅适用于只读操作。
8、模板系统和对话状态
模板应该驱动每个对话领域——新用例应该是配置更改,而不是代码部署
模板优于代码
每个对话领域应该是配置更改,而不是代码更改。Vapi、Retell AI和Bland AI都遵循这一原则。设计良好的模板定义四层:
- 角色 — 名称、背景、沟通风格、目标。- 部分和问题 — 带有提取字段和后续逻辑的主题。- 风格配置 — 语气、语言规则、响应长度、流程。- 输出配置 — 质量标准、危险信号、升级触发器。
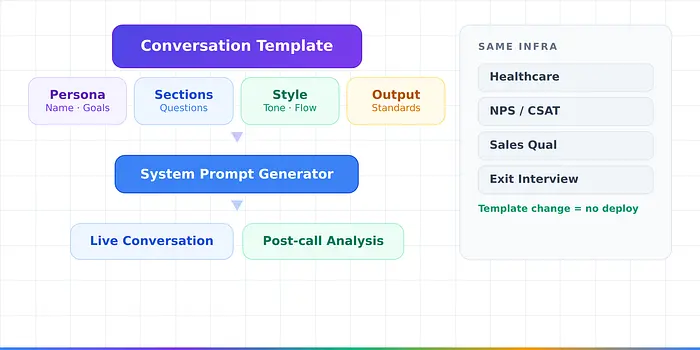
同一个模板既驱动实时对话,也驱动通话后分析——您使用引导对话的相同字段定义来提取结构化数据。
最小模板示例:
persona:
name: "Aka"
role: "客户满意度专家"
tone: "热情、简洁、从不强推"
goal: "了解客户最近购物体验"
sections:
- id: "overall_experience"
prompt: "询问整体体验如何,然后探究具体原因"
extract:
sentiment: "positive | neutral | negative"
primary_reason: "string"
- id: "product_quality"
prompt: "专门询问产品质量"
extract:
rating: "1-5"
issue_category: "packaging | defect | wrong_item | none"
- id: "resolution_intent"
prompt: "如果有问题,询问他们想要什么解决方案"
conditional: "sections.overall_experience.sentiment != 'positive'"
extract:
resolution_requested: "refund | replacement | credit | none"
style:
max_response_sentences: 2
always_end_with_question: true
language: "zh-CN"
output:
red_flags:
- "提到法律行动"
- "极度困扰"
escalate_if_red_flag: true
基于节点的状态机
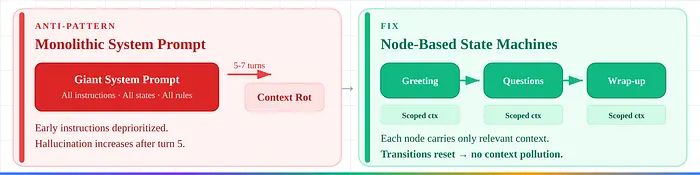
对于复杂的多步骤流程,仅模板不够。Pipecat Flows体现了主导的生产模式:每个节点携带角色消息、任务消息和可用函数。节点转换重置任务上下文,防止上下文污染——早期状态的指令泄漏并导致幻觉。
没有这个,对话质量在5-7轮后会明显下降。
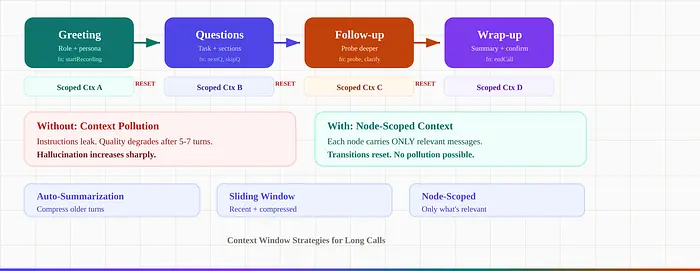
长通话的上下文窗口策略: 自动摘要(压缩早期轮次)、滑动窗口+摘要混合、节点范围上下文(每个状态只携带相关内容)。
9、语音特定的提示工程
语音提示与文本提示有根本不同。核心原因:
语音没有撤销。
阅读文本响应的用户可以重读、跳过或复制。错过AI说话内容的呼叫者要么要求重复(尴尬),要么听错并在错误信息上行动(更糟)。
关于语音优化提示的研究显示,它们产生的响应比文本等效内容短60-70%,对话修复尝试减少约67%。
文本提示 vs 语音提示——相同的意图,不同的写法:
文本版本:
您是一个有用的助手。当用户询问账户余额时,从数据库中检索并提供详细响应,包括当前余额、最近交易和任何待处理费用。使用适当的标题清晰格式化。
语音版本:
您是aka,账单专家。每个响应保持1-2句话。当用户询问余额时,先说余额,然后询问是否需要详情。从不使用格式、列表或过长的数字。始终以问题结束。

最重要的六条规则:
- 响应不超过3句话。 更长就是独白。- 始终以问题结束。 陈述后的沉默会产生死寂。
- 无格式化。 Markdown在音频中毫无意义(ElevenLabs)。
- 关键指令重复两次。 模型在长上下文中降低早期指令的优先级。
- 系统提示不超过2,000令牌。 更大的提示会增加首令牌延迟。
- 渐进沉默提示(3s/6s/10s)。 不强迫地重新激活。
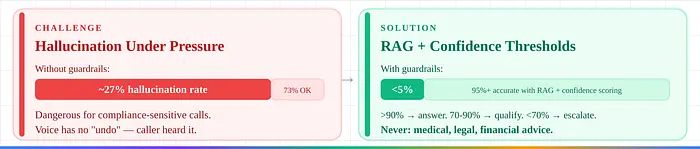
置信度护栏(Vapi):>90% → 直接回答。70-90% → 添加限定词。<70% → 升级。永远不 → 医疗/法律/财务建议。
10、已验证的设计模式
1. 服务层隔离。 SessionService.saveSession()从浏览器(HTTP)和电话(WebSocket)调用——服务不知道传输层。添加WhatsApp或SIP时,添加传输适配器,而不是新逻辑。
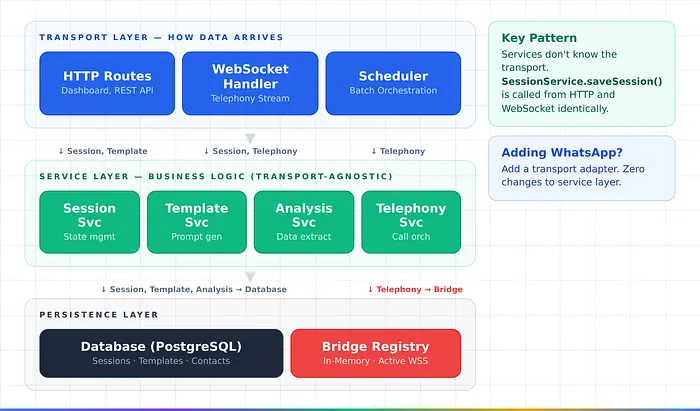
2. 临时令牌模式。 服务器向客户端发放短期、一次性AI令牌。具有服务器端安全性的直接连接延迟。
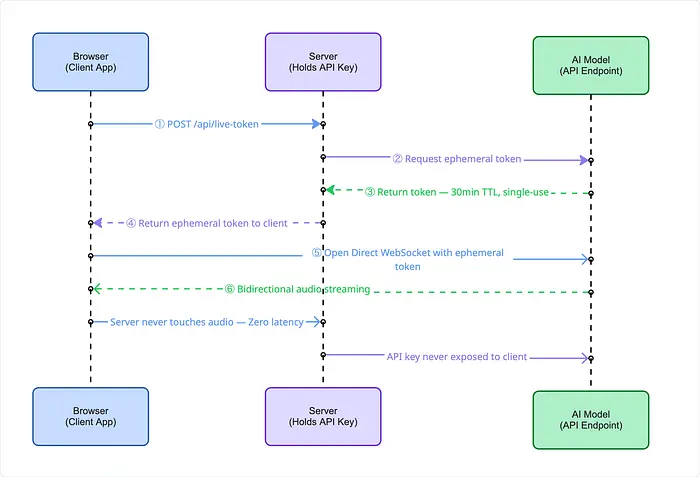
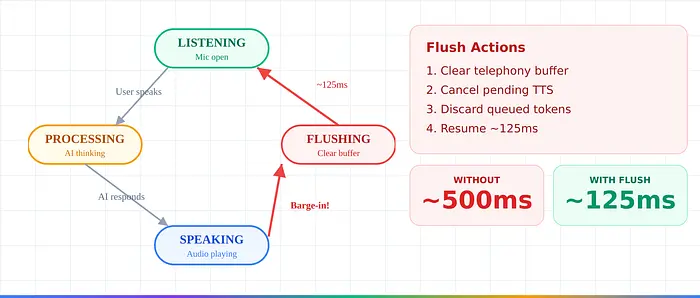
3. 打断状态机。 OpenAI的实时API因过早VAD响应而受到批评。生产打断循环:聆听 → 处理 → 说话 → 清空 → 聆听。清空清除电话音频缓冲区。没有它,旧音频会在用户说话时播放。正确清空:约500ms → 约125ms中断延迟。
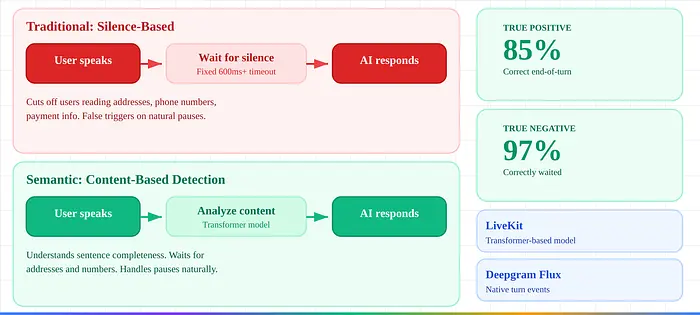
4. 语义轮次检测。 LiveKit的基于变换器的模型分析语音内容,而不仅仅是静默——实现85%真阳性/97%真阴性率。对地址、电话号码和支付信息至关重要。Deepgram的Flux提供原生轮次事件,消除了ASR+VAD+端点拼接。
5. MCP用于工具调用
模型上下文协议已成为语音智能体工具集成的标准中间件。OpenAI发布了完整的MCP驱动语音智能体教程。LiveKit Agents 1.0添加了原生MCP支持。这标准化了工具接口并将智能体逻辑与工具实现解耦——添加新工具无需修改智能体代码。
OpenAI Agents SDK包含VoicePipeline扩展,只需几行代码即可将文本智能体转换为语音智能体。
11、会伤害你的反模式
1. 单体系统提示。 所有指令在一个巨大的提示中。上下文腐烂在5-7轮后降低早期指令的优先级。修复:基于节点的状态机。
2. 从可视化流程构建器开始。 "抵制这种诱惑,至少最初如此。"通用构建器在中断、主题变更和情感升级时会崩溃。修复:基于代码的流程——可测试且版本控制。
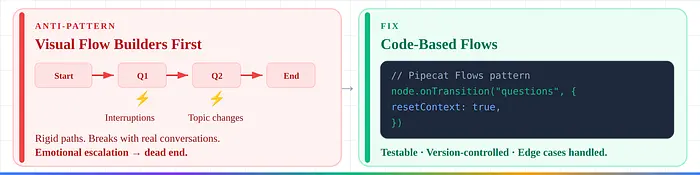
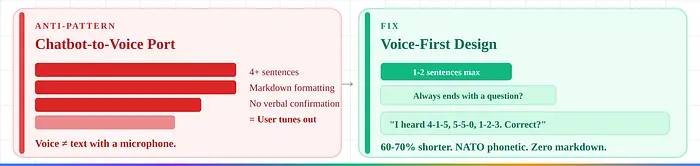
3. 聊天机器人到语音的移植。 语音需要短60-70%的响应、口头数据确认、零Markdown。修复:从头设计语音流程。
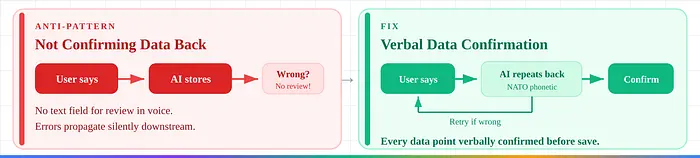
4. 不确认数据。 语音中没有文本字段供审查。使用NATO音标字母表重复捕获的数据。
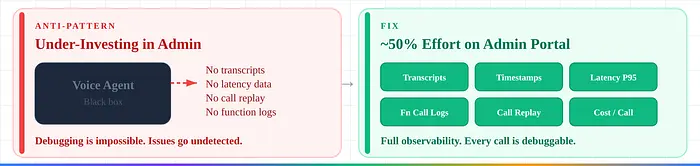
5. 管理工具投资不足。 约50%的开发工作用于管理门户——时间戳、转录、函数调用、延迟分解、重放。没有这个,调试是不可能的。
6. 认为Whisper是完美的
大多数工程师认为幻觉是LLM的问题。这个在您的STT层——而且是无声的。
Whisper是在充满字幕伪影的互联网音频上训练的。当它收到静默时——呼叫者在思考,连接弱——它不会输出无。它从训练记忆中编造短语。最有记录的:从纯静默生成的*"Subtitles by the Amara.org community"*。
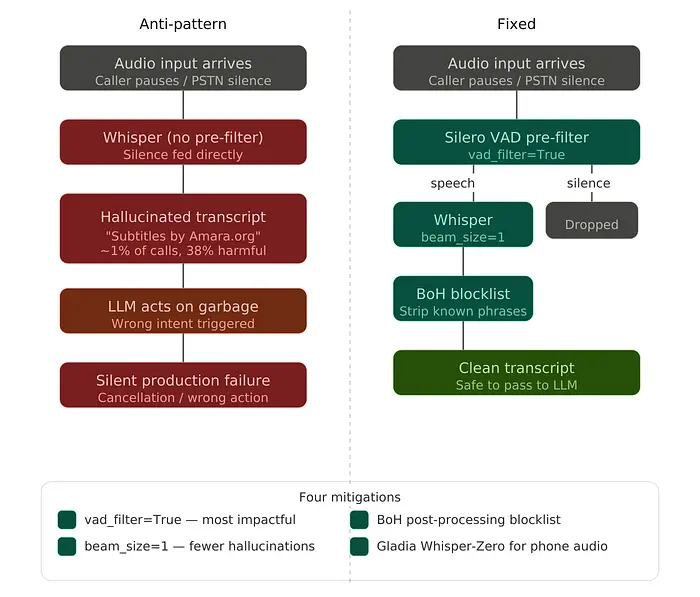
康奈尔研究发现约1%的Whisper转录是幻觉,其中38%明确有害。在语音智能体中,那个幻觉成为您LLM的直接指令。没有错误记录。没有警报触发。
四个修复
vad_filter=True——在Whisper看到之前剥离静默。beam_size=1——更少的幻觉,最小的准确度成本。- BoH黑名单——转录后剥离已知的编造短语。
- Gladia Whisper-Zero——在电话质量音频上重新训练。
12、扩展:从1到10,000并发通话
1. 每实例约500个并发桥接(约1GB RAM)。粘性会话必须。 根据连接数自动扩展,而不是CPU。
2. 标准自动扩展对语音失败——工作者是I/O绑定(等待LLM响应),所以过载时CPU保持低位。使用基于KEDA的自动扩展,基于队列深度。积极扩展(200%/分钟),保守缩减(5分钟稳定期)。

3. 无服务器不起作用——语音需要持久连接。大规模时,将GPU与电话存在点共置(Telnyx的方法)。
13、成本分析和优化
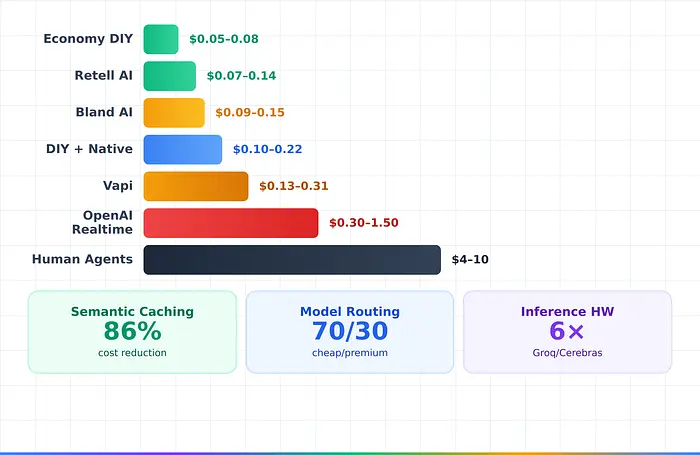
- 每分钟总计:$0.10-0.22(电话渠道,原生音频)。细分:电话($0.013-0.085,Twilio)、AI模型($0.06-0.10,Gemini)、通话后分析(约$0.02)、基础设施(约$0.01)。
- 平台比较: 经济DIY栈:$0.05-0.08/分钟,Retell AI:$0.07-0.14。Bland AI:$0.09-0.15,Vapi:$0.13-0.31。OpenAI实时:$0.30-1.50,人工客服:$4.00-10.00。
14、优化策略
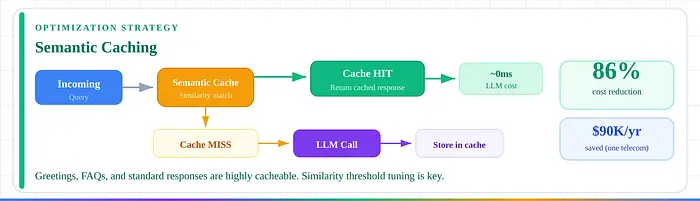
1. 语义缓存。 将LLM成本降低高达86%,适用于重复查询。一家电信公司仅缓存问候语就节省了90,000美元/年。
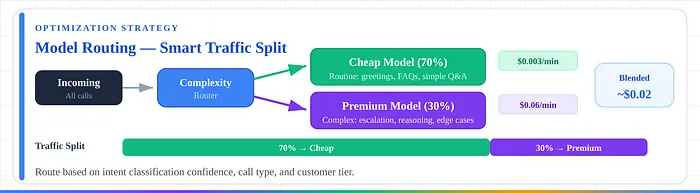
2. 模型路由。 70%的常规通话 → 廉价模型($0.003/分钟);为复杂交互保留昂贵模型。
3. 推理硬件。 Groq为Llama 70B提供约241令牌/秒。Cerebras在相同模型上快约6倍。对于语音智能体,首令牌时间就是一切,专用芯片改变了等式。
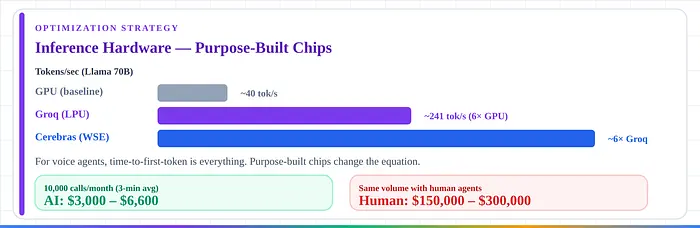
在每月10,000通话(平均3分钟):$3,000-6,600 vs. 人工$150,000-300,000。
15、可观测性:监控重要的东西
标准APM无法检测语义准确度下降、对话漂移或多轮上下文失败。语音AI需要四维监控:
- 延迟 — P50/P95/P99的TTFB,按组件分解。语音延迟是感知性的;P95比平均值更重要。
- 准确度 — 每种语言/口音的WER,意图分类率。
- 对话质量 — 上下文保持、中断处理(<200ms)、打断频率。
- 业务结果 — 包含率、CSAT、每次解决通话的成本(Hamming AI)。
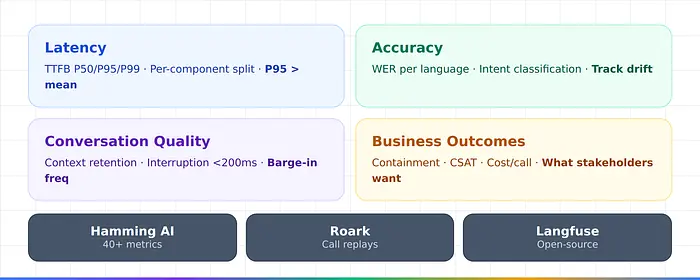
基本工具:Hamming AI(40+指标,与人类评估者95-96%一致)、Roark(生产通话重放)、Langfuse(开源追踪)。
16、没人警告您的挑战
这些不是设计错误——而是生产伏击。与上面的反模式不同,这些挑战来自电话基础设施、人类行为、监管环境和模型限制的交叉点。您会遇到每一个。
1. 冷问候问题。 没有预连接:接听时2-3秒静默。许多人在5秒内挂断。解决方案:振铃期间的积极预连接。
2. 静默就是数据。 舒适帧保持流活跃(Twilio)。渐进提示在3s/6s/10s重新激活。
3. PSTN音频很糟糕。 300-3,400 Hz,8kHz——AM收音机保真度。开发者用WebRTC测试(MOS 4.2-4.7),当电话通话听起来很糟糕时感到震惊(MOS 3.2-3.8)。用实际电话音频测试。

4. 合规不是可选的。 FCC裁定AI语音是TCPA下的"人工"声音。罚款:$500-1,500/通话。30秒内AI披露要求(德克萨斯州SB 140)。HIPAA/GDPR适用于医疗保健和欧盟。

5. 压力下的幻觉。 没有护栏:约27%幻觉率。使用RAG + 置信度阈值:低于5%。
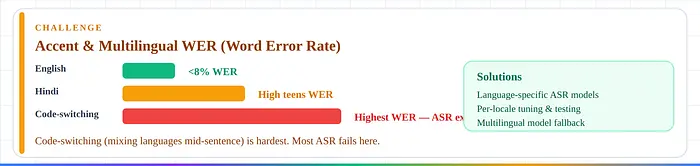
6. 口音和多语言。 英语:<8% WER。印地语:高十几%。语码转换(句中混合语言)是最难的——大多数ASR期望单语言输入。
17、结束语
构建生产级AI语音智能体处于实时系统工程、电话领域知识、AI集成、音频信号处理和全栈开发的交叉点。AI模型可能只占挑战的20%。 另外80%是围绕它的一切。
语音AI领域正在快速发展。模型越来越快。成本在下降——$0.07/分钟 vs. 人工$15+/通话。低于300ms是新标准。
原文链接: Building a Production AI Voice Agent: Architecture, Patterns, and the Hard Problems
汇智网翻译整理,转载请标明出处
