Context Graph: 捕捉决策轨迹
上下文图 (Context Graph) 并非更智能的数据库,也不是“代理的内存”,更不是简单地将工具与 MCP 连接起来。它是一种用于捕获决策轨迹的基础设施,将观察结果与行动联系起来的推理过程。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
过去 20 年来,企业软件的构建一直围绕着一个理念:存储最终状态。
CRM 系统存储交易金额。工单系统存储“已解决”状态。Git 存储最终代码。数据库存储当前状态。
这种方法造就了万亿美元公司。
但人工智能打破了人类是推理层的假设。
如果期望智能体做出决策,他们需要的不仅仅是数据访问权限。他们需要了解决策过程。
这就是上下文图的用武之地。
1、上下文图
上下文图 (Context Graph) 并非更智能的数据库,也不是“代理的内存”,更不是简单地将工具与 MCP 连接起来。
上下文图是一种用于捕获决策轨迹的基础设施——它将观察结果与行动联系起来的推理过程。
想想更少的记录和更多的先例。
记录系统告诉你发生了什么,而上下文图告诉你为什么会发生。
2、核心问题:我们只构建了时间的一半
每个系统都基于两个时钟运行:
- 状态时钟——当前状态是什么
- 事件时钟——发生了什么,按什么顺序,以及为什么发生
我们为前者构建了庞大的基础设施。
而对于后者,我们却几乎没有。
你已经知道的例子
- Git 显示 timeout=30s,但没有说明为什么从 5s 改成了 30s
- CRM 显示“已关闭,已丢失”,但没有说明“我们是备选方案”
- 工单显示“已解决”,但没有说明调查路径
- 合同显示“60 天终止”,但没有说明背后的权衡取舍
推理过程存在这些地方:
- Slack 讨论
- 会议记录
- 人类记忆
然后它消失了。
当人类作为推理层时,这种方法行得通。但当需要人工智能进行推理时,它就失效了。
你不会在没有判例法的情况下训练律师学习判决。而我们今天对人工智能系统所做的,正是如此。
3、为什么这在结构上难以实现
上下文图目前还不存在——并非因为我们懒惰,而是因为它们迫使我们直面几十年来一直回避的问题。
3.1 系统并非完全可观测
组织机构存在:
- 遗留代码
- 第三方服务
- 跨系统的涌现行为
你无法对无法完全观测到的事物进行清晰的建模。
3.2 没有通用模式
每家公司都有自己的本体。
- B2B 中的“客户”≠ 市场中的“客户”
- DevOps 和安全领域中的“事件”含义不同
- “审批”在不同环境中运作方式也不同
试图预定义全局模式总是会失败。
3.3 一切都在变化
你记录的不是一个静态系统,而是每天都在变化的事物。
大多数知识管理失败的原因在于,它们将此视为静态摄取问题:
“收集文档 — 构建图 — 稍后查询”
但文档是冻结的状态。
事件时钟是过程,而过程是动态的。
4、关键洞察:让智能体发现结构
与其预先定义组织结构,不如让智能体在工作中发现它。
智能体已经能够做到模式无法做到的事情:
- 识别相关实体
- 发现关系
- 导航未知系统
- 随着信息的变化而调整
当智能体解决问题时,它会在系统中移动:
- 读取配置
- 查询数据库
- 检查日志
- 创建工单
- 与 API 通信
这种移动就是组织状态空间中的轨迹。
而轨迹就是数据。
5、从随机游走到有信息游走
在图学习中,有一个强大的理念:
你不需要知道图的结构就能学习它。你只需要足够多的游走次数。
5.1 经典示例:node2vec
node2vec 通过执行随机游走并学习哪些节点共现来学习图嵌入。
- 局部随机游走——学习相似性(同质性)
- 全局随机游走——学习角色(结构等价性)
不同团队的两名工程师可能永远不会接触到相同的系统,但他们在不同的子图中扮演着相同的角色。
随机游走通过统计方法发现这一点。
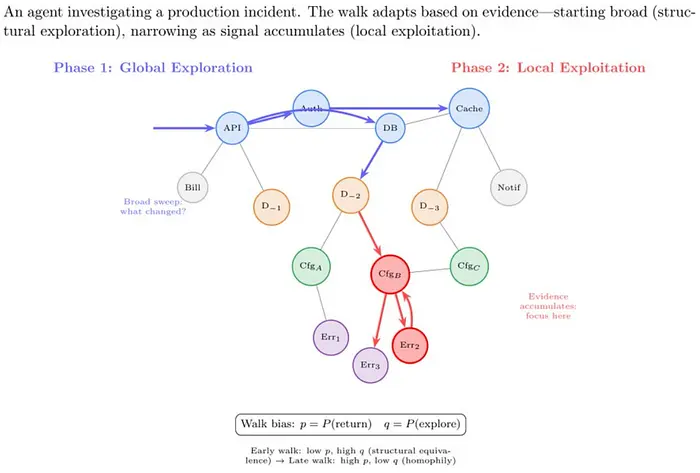
5.2 智能体优于随机游走
智能体不会漫无目的地游荡。它们带着意图进行游走。
示例:生产事故调查
从广泛入手
- 最近发生了哪些变化?
- 部署了哪些服务?
缩小范围
- 哪些配置发生了变化?
- 哪些请求失败了?
深入挖掘
- 特定的代码路径
- 特定的客户
这是一种有偏的随机游走,在以下两者之间切换:
- 全局探索
- 局部推理
这才是我们想要的信号。
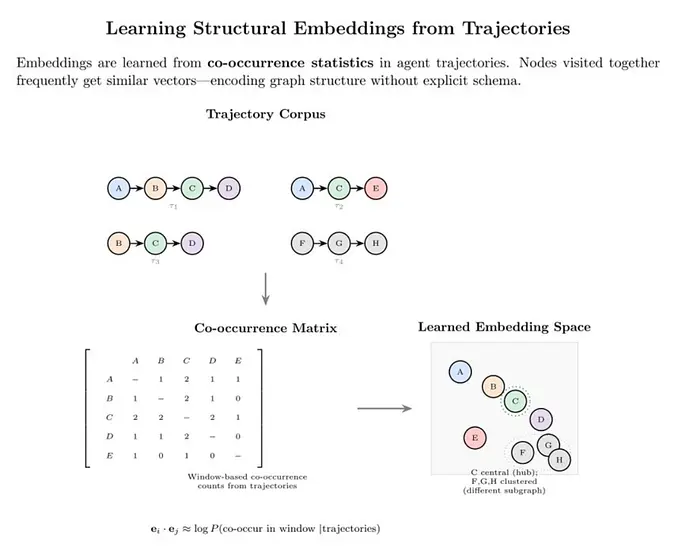
6、嵌入的不是意义,而是结构
如今大多数嵌入都是语义嵌入。
它们回答:
“哪些事物具有相似的含义?”
上下文图需要结构嵌入。
他们的回答是:
- 决策过程中哪些实体相互关联?
- 哪些事件先于哪些结果?
- 哪些路径在不同的问题中反复出现?
示例
trajectory = [
"deployment_2024_12_17",
"service_payments",
"feature_flag_fast_checkout",
"customer_segment_enterprise",
"incident_timeout_error"
]一条轨迹是弱的。
一万条类似的轨迹揭示:
- 脆弱的配置
- 风险功能交互
- 隐藏的依赖关系
模式源于使用。
事件时钟是最终结果。其经济性在于:
- 部署代理来解决问题
- 记录它们的轨迹
- 这些轨迹构建上下文图
- 更好的上下文 — 更好的代理
- 更好的代理 — 更多的部署
- 更多的部署 — 更丰富的上下文
图并非手动构建。
它是有益工作的最终结果。
7、上下文图作为世界模型
这正是该理念的强大之处。
世界模型是对以下内容的学习表示:
- 实体
- 动态
- 执行操作时发生的情况
在机器人学中,世界模型模拟物理现象。
在组织中,“物理现象”指的是决策动态:
- 审批如何传播
- 变更如何引发事件
- 配置如何交互
- 故障如何扩散
成熟的上下文图可以成为一个模拟器。
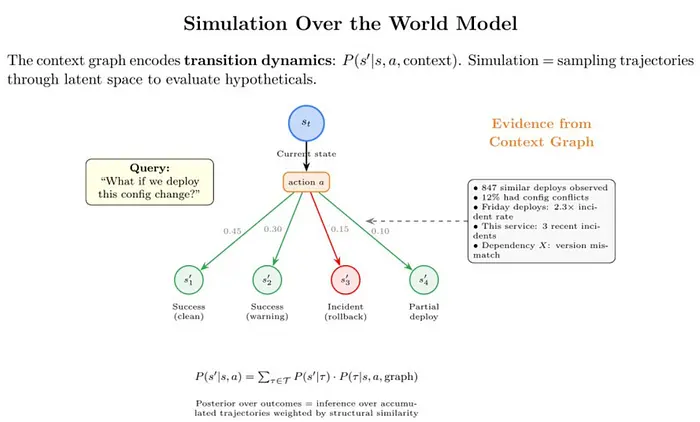
8、模拟即测试
如果你的系统无法回答:
“如果我们执行 X 会发生什么?”
……那它就只是一个搜索索引。
例如,在 PlayerZero,模拟会预测假设的变化:
- 给定当前配置
- 给定功能标志
- 给定用户行为模式
它们预测:
- 故障模式
- 爆炸半径
- 受影响的客户
这并非魔法。这是基于累积轨迹的推理。
9、为什么这对持续学习至关重要
关于人工智能的局限性有很多争论:
“模型无法在工作中学习。”
这种说法忽略了一些关键因素。
与其不断地重新训练模型:
- 保持模型不变
- 扩展其推理的世界模型
智能体的改进并非因为权重改变,而是因为:
- 证据不断积累
- 推理变得更加丰富
- 模拟变得更加精确
这与人类经验相符。
资深员工的思维方式并无不同,他们只是见识过更多情况。
他们可以模拟各种结果:
“如果我们周五部署,值班人员将会受到影响。”
这就是一个世界模型。
10、上下文图的真正需求
要构建一个上下文图,必须解决三个问题:
- 捕获事件时钟:推理必须被视为一等数据。
- 让模式成为输出:本体从代理的轨迹中涌现,而非预先设计。
- 构建世界模型,而非检索系统:如果你能模拟“如果……会怎样”,你就构建了一些东西。
下一代平台不会通过以下方式取胜:
- 在记录系统中添加人工智能
- 加快检索速度
- 无限扩展模型
它们将通过构建智能叠加的基础设施来取胜。
部署的代理不仅执行操作,还会留下结构。
系统不仅记住事实,还会记住原因。
模型是引擎。
上下文图是使模型发挥作用的世界模型。
原文链接:How to Build a Context Graph?
汇智网翻译整理,转载请标明出处
