Claude Code 自动记忆实测
真正的解锁在于理解自动记忆如何融入更广泛的记忆架构,使 Claude Code 对团队有用,而不仅仅是对个体开发者。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | AI工具导航 | Tripo 3D | Meshy AI
错误不断重复。这周的第三次会话,同样的错误 —— Claude 建议使用 npm install,而我们的整个 monorepo 都在运行 pnpm。我星期一纠正过它。我星期二纠正过它。星期三早上,它又出现了。
"记住我们使用 pnpm,而不是 npm。"
自从为我们的团队采用 Claude Code 以来,我大概输入了第五十次。
就在这时,更新日志通知吸引了我的注意:
"Claude 自动将有用的上下文保存到自动记忆中。"

我花时间在工程师团队中测试了自动记忆 —— 而这个功能本身只是故事的一半。真正的解锁在于理解自动记忆如何融入更广泛的记忆架构,使 Claude Code 对团队有用,而不仅仅是对个体开发者。
我看到的大多数报道都将此视为单个开发者功能。它不是。或者更确切地说,它不应该是。
1、大多数团队弄错的记忆系统
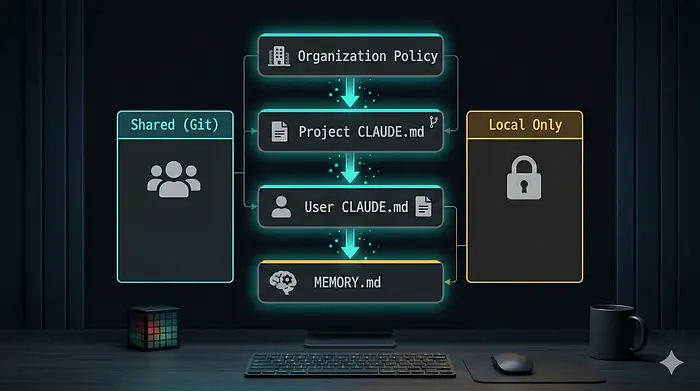
最初困扰我们的是: 自动记忆和 CLAUDE.md 看起来做同样的事情。它们不是。
CLAUDE.md 是你为 Claude 编写的 —— 提交到 Git,与克隆仓库的每个开发者共享。将其视为你团队的章程。自动记忆 (MEMORY.md) 是Claude 为自己编写的 —— 本地存储在 ~/.claude/projects/<project>/memory/,永不接触版本控制。
层次结构在每次会话中以特定顺序加载:
组织策略(企业)
↓
项目 CLAUDE.md(提交到 Git → 与团队共享)
↓
用户 ~/.claude/CLAUDE.md(你的个人默认设置)
↓
MEMORY.md(前 200 行,自动生成,仅本地)
更具体的指令覆盖更广泛的指令。这是大多数文章跳过的部分,也是对团队最重要的部分。
当我的工程师之一发现我们的 GraphQL 解析器测试需要本地 Redis 实例运行时,Claude 会自动保存到他们的 MEMORY.md。但该知识被困在他们的机器上。与此同时,其他三位开发者在接下来的一周碰到了同样的墙。
解决方案不是自动记忆。而是知道何时将自动记忆洞察提升到共享的 CLAUDE.md。
2、实际有效的双层模式
在两个项目上测试三周后,我们采用了一个我称之为*"本地发现,共享编码"*的模式。
第 1 层:让自动记忆做它的事。 每个开发者的 Claude 实例都会累积特定于项目的笔记 —— 调试模式、奇特的测试命令、在负载下超时的 API 端点。这会自动发生。除了启用它之外,不需要任何设置*(默认情况下已启用)*。
第 2 层:每周 CLAUDE.md 提升。 每周五在我们的团队同步期间,我们花 10 分钟审查 Claude 学到了什么。每个开发者运行:
cat ~/.claude/projects/*/memory/MEMORY.md
当我们发现适用于整个团队的模式 —— 我们总是会发现 —— 我们将它们提升到共享的 CLAUDE.md:
# CLAUDE.md(提交到 Git)
## 构建和测试
- 包管理器:pnpm(绝不使用 npm 或 yarn)
- 测试命令:pnpm test:unit(而不是 pnpm test,它运行 e2e)
- E2E 需要本地 Redis:redis-server --port 6380
## 架构决策
- GraphQL 解析器:始终返回类型化的 DTO,绝不返回原始数据库实体
- 错误处理:使用 src/shared/errors 中的 AppError 类
- 认证:JWT 验证在中间件中进行,而不是在解析器中
## 代码风格
- 仅使用命名导入(tree-shaking 兼容性)
- 联合类型首选 const 断言
- 功能模块中没有桶导出(循环依赖风险)
结果: Claude 在每次会话开始时就已经知道我们 个体 需要几周才能发现的东西。
3、自动记忆实际捕获的内容
我在这里有不切实际的期望。在 Brent Peterson 的观察半病毒式传播之后 —— 他发现使用后 MEMORY.md 中只有 12 行,称之为*"配置,而不是学习"* —— 我检查了我的。
他部分正确。在活跃使用生产代码库三周后,我的 MEMORY.md 有 23 行。不完全是一个知识库。
但这 23 行包含的内容:
# MEMORY.md(自动生成)
- 项目使用 pnpm workspaces,包含 3 个包:api、web、shared
- 测试数据库在端口 5433 上运行(不是默认的 5432)以避免冲突
- 部署脚本需要显式设置 AWS_PROFILE=staging
- PR 标题必须遵循约定式提交(由 CI 强制执行)
- src/shared/types/index.ts 是 API 契约的真实来源
单独来看,这些都不具有革命性。总体而言,它消除了每次新的 Claude 会话中扼杀生产力的"冷启动"*问题。在自动记忆之前,重新连接上下文需要在每次会话开始时大约 45 秒的来回对话。现在它是零。
自动记忆做不好的事情:架构推理、权衡讨论或*"为什么"决策。它捕获"什么"* —— 命令、路径、模式。 "为什么"属于 CLAUDE.md,由人类编写。
4、模块化规则:团队没有人使用的功能
.claude/rules/ 目录是团队中最未被充分利用的系统部分。虽然CLAUDE.md 给 Claude 项目范围的指令,但模块化规则让你可以使用 YAML 前言将指令范围限定到特定文件类型:
# .claude/rules/api-standards.md
---
paths:
- "src/api/**/*.ts"
---
# API 开发规则
- 所有端点必须包含 Zod 输入验证
- 使用标准 AppError 格式进行错误响应
- 在每个处理程序上包含 OpenAPI JSDoc 注释
- 速率限制配置放在 src/api/middleware/
# .claude/rules/testing.md
---
paths:
- "**/*.test.ts"
- "**/*.spec.ts"
---
# 测试约定
- 使用 vitest,而不是 jest(2026 年 1 月迁移)
- 工厂函数位于 __fixtures__/,而不是内联
- E2E 测试必须在 afterAll() 中清理测试数据
- 使用 msw 模拟外部服务,而不是手动模拟
这对团队很重要,因为不同的人在代码库的不同部分工作。你的前端工程师会自动加载 React 特定的规则。你的 API 开发者获得验证标准。没有人被不相关的上下文所淹没。
我们从一个 180 行的 CLAUDE.md 转变为一个 40 行的根文件加上 6 个模块化规则。Claude 的输出质量明显改善 —— SFEIR Institute 的培训材料引用了当规则正确限定时,幻觉减少 40%,这与我们的观察一致。更少的不相关指令意味着 Claude 上下文窗口中的噪音更少。
5、新人上手捷径
这是团队角度变得引人注目的地方。上个月我们入职一位新工程师时,她使用 Claude Code 的第一天是这样的:
- 克隆仓库 (CLAUDE.md 和
.claude/rules/随之而来)* - 在项目目录中运行
claude - 开始工作
没有 "让我解释我们如何构建解析器"的对话。没有"实际上,我们使用 pnpm"的纠正循环。没有"测试数据库在不同端口上运行"的调试会话。Claude 已经知道了所有这些内容。
以前使用 Claude Code 入职: 在工具有用之前大约 2 小时。
使用共享记忆设置: 大约 10 分钟。这不是一个我可以科学严谨地证明的指标 —— 它是我们的经验。
6、确实重要的隐私边界
最初让我担心的一件事:
自动记忆仅限本地,但 CLAUDE.md 是共享的。对于跨多个客户或受监管行业工作的团队,这个边界至关重要。
自动记忆尊重 Git 仓库范围。每个仓库在 ~/.claude/projects/<project>/memory/ 获得自己的目录。如果你在客户 A 的代码库和客户 B 的代码库上工作,这些记忆永远不会交叉污染。
对于不应共享的个人偏好 —— 你的编辑器快捷键、你喜欢的注释风格、你的调试怪癖 —— 在项目根目录使用 CLAUDE.local.md。它会自动添加到 .gitignore。
仓库(通过 Git 共享):
├── CLAUDE.md # 团队约定
├── .claude/rules/ # 范围限定的团队规则
└── CLAUDE.local.md # 你的偏好(.gitignored)
本地机器(永不共享):
└── ~/.claude/projects/<project>/memory/
├── MEMORY.md # Claude 的自动笔记
├── debugging.md # 特定主题的笔记
└── api-conventions.md # 特定主题的笔记
这种分离并非偶然。正是这使得系统对于处理敏感项目的团队来说是可行的。
7、在 CI 环境中强制关闭
我们通过艰难的方式学到了这一点。我们的 staging 管道运行 Claude Code 进行自动代码审查,几天后我们发现一个 MEMORY.md 里塞满了 CI 噪音 —— Docker 镜像标签、临时数据库 URL、测试运行器标志。
那些垃圾被加载到每个本地开发会话中,悄悄地降低了 Claude 的建议。
解决方案是一个环境变量:
# CC AUTO-MEMORY 在 CI 中强制关闭
export CLAUDE_CODE_DISABLE_AUTO_MEMORY=1
# CC AUTO-MEMORY 在 CI 中强制开启
export CLAUDE_CODE_DISABLE_AUTO_MEMORY=0
这优先于 /memory 切换和任何 settings.json 配置。
将它添加到你的 CI 配置一次,自动记忆将不再从自动运行中累积笔记。如果你在除开发者本地机器之外的任何地方运行 Claude Code —— CI 管道、staging 环境、自动审查工作流 —— 在做任何其他事情之前设置这个。
8、不足之处
自动记忆在主 MEMORY.md 文件上有硬性 200 行限制 —— 只有前 200 行在会话开始时加载。除此之外,Claude 创建主题文件 (debugging.md、patterns.md),在相关时按需加载。实际上,我还没有达到这个限制,但拥有复杂项目的团队可能会。
更大的限制: 没有机制自动在团队成员之间共享自动记忆洞察。我描述的每周提升到 CLAUDE.md?那是我们发明的手动过程。Anthropic 没有构建团队级别的记忆同步,我不确定他们应该 —— 隐含意义会很快变得复杂。
Git worktrees 获得单独的内存目录,这对于并行功能开发很有用,但意味着基于 worktree 的工作流会碎片化 Claude 的学习。如果你像 Boris Cherny 风格运行 5 个并行会话,每个 worktree 开始时都有略微不同的上下文。
诚实的坦白: 除了我们在两个项目上 7 个开发者的规模之外,我没有测试过这种模式。一个在 15 个微服务的 monorepo 上有 30 人的团队可能需要完全不同的方法。
9、设置检查清单
如果你想为你的团队复制这个,以下是顺序:
第 1 天: 在项目根目录创建一个最小的 CLAUDE.md。包括你的包管理器、测试命令和导致最困惑的三个架构决策。将其提交到 Git。
第 1 周: 让自动记忆自然积累。不要触摸它。让每个开发者构建他们的本地上下文。
第 2 周: 在团队同步中审查每个人的 MEMORY.md。将重复模式提升到共享的 CLAUDE.md。在 .claude/rules/ 中为代码库中产生最多问题的区域创建你的第一个模块化规则。
持续进行: 将 CLAUDE.md 更新添加到你的 PR 模板。当有人发现值得分享的项目怪癖时,它会在代码更改的下一次提交中进入。
模式并不复杂。价值来自于将 Claude 的记忆视为团队知识系统,而不仅仅是个人的生产力黑客。
原文链接: The New Claude Code's Auto-Memory Feature Just Changed How My Team Works — Here Is the Setup I Use
汇智网翻译整理,转载请标明出处
