上下文就是新的训练
表格基础模型用可编辑的推理时数据取代了重新训练

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
表格基础模型如TabPFN和TabICL不需要进行训练就能执行回归或分类。它们所做的是所谓的上下文学习。过去作为训练数据的东西现在变成了预测时的上下文数据。
本文探讨了上下文数据的概念,并将其与"经典"训练数据进行对比。从训练数据转向上下文数据是否改变了我们的建模方式?它是否实现了某些新功能?
让我们深入探讨。
1、训练 vs 上下文
对于传统机器学习(线性回归、XGBoost、SVM),训练数据塑造模型。特别是对于树模型,这一点非常直观:改变训练数据,你可能会得到一棵不同形状的树。拟合一个线性回归模型,权重(系数)就成为训练数据的函数。
表格基础模型则不同。预训练完成。没有经典的训练步骤。预测通过上下文学习进行。使用TFM预测时,你需要同时提供"训练"数据(即上下文)和测试数据。通过多个步骤,表格单元格被嵌入,通过注意力机制和全连接层,TFM通过关注其他单元格并计算来丰富单元格表示。所有这些都基于模型在预训练中学到的内容。训练和测试数据点可以关注训练数据点,但不能关注其他测试数据。y_test的单元格嵌入用于预测或分类。如果你想了解更多关于表格基础模型如何工作的内容,请查看我的TabPFN架构文章。
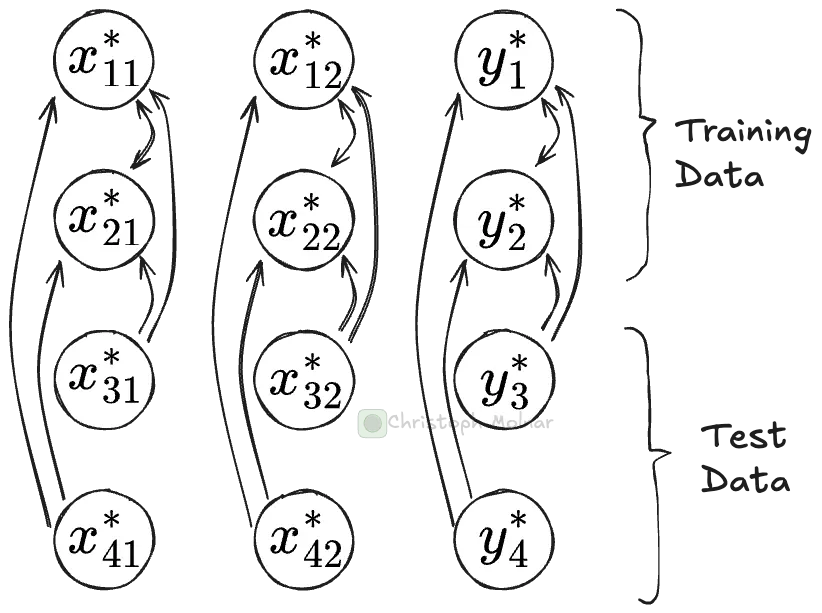
数据点注意力。单元格可以关注同一列中的其他单元格。但它们只能关注训练数据中的单元格,不能关注测试数据中的单元格。
那么当我们改变上下文数据时会发生什么?模型权重不会改变。唯一改变的是模型输出的预测:因为上下文变了,嵌入会改变,可以关注的数据点集合也会改变。
但除了不影响模型之外,将"训练"数据视为上下文数据真的值得思考吗?
我在接下来两节中告诉你的并不新鲜:你也可以做传统ML并将其称为上下文而不是训练。把所有东西包装在一个函数里,.predict()实际上做了fit+predict。只是,有些东西使得将上下文数据而不是训练数据来思考是值得的:使用更小数据集的能力和必要性(TFM在小数据上表现良好),以及训练成本倒置——训练成本实际上消失了(忽略预训练),预测变成了昂贵的步骤。
2、更小、更智能的上下文
使用表格基础模型进行预测相对昂贵。特别是如果你总是使用所有训练数据作为上下文。TabICL的推理运行时复杂度为O(n² + nm²),其中n是上下文+测试的行数,m是列数。由于它在行数上是二次的,当我们增大数量级时绝对会爆炸:训练数据行数增加10倍意味着运行时间增加100倍(假设训练数据量远大于测试数据量,且远大于特征数)。二次缩放强烈激励我们使用更小的上下文数据集。
对于小上下文有一个更乐观的前景:表格基础模型在较小数据上表现得特别好。这是它们通常优于大多数其他方法的领域。也许是因为对于较小的数据,预训练中学到的归纳偏置能够发挥优势。
无论如何,我们可以考虑缩减数据。当我实验表格基础模型时,我有时会对数据进行下采样以改善运行时间,但代价是预测性能下降。
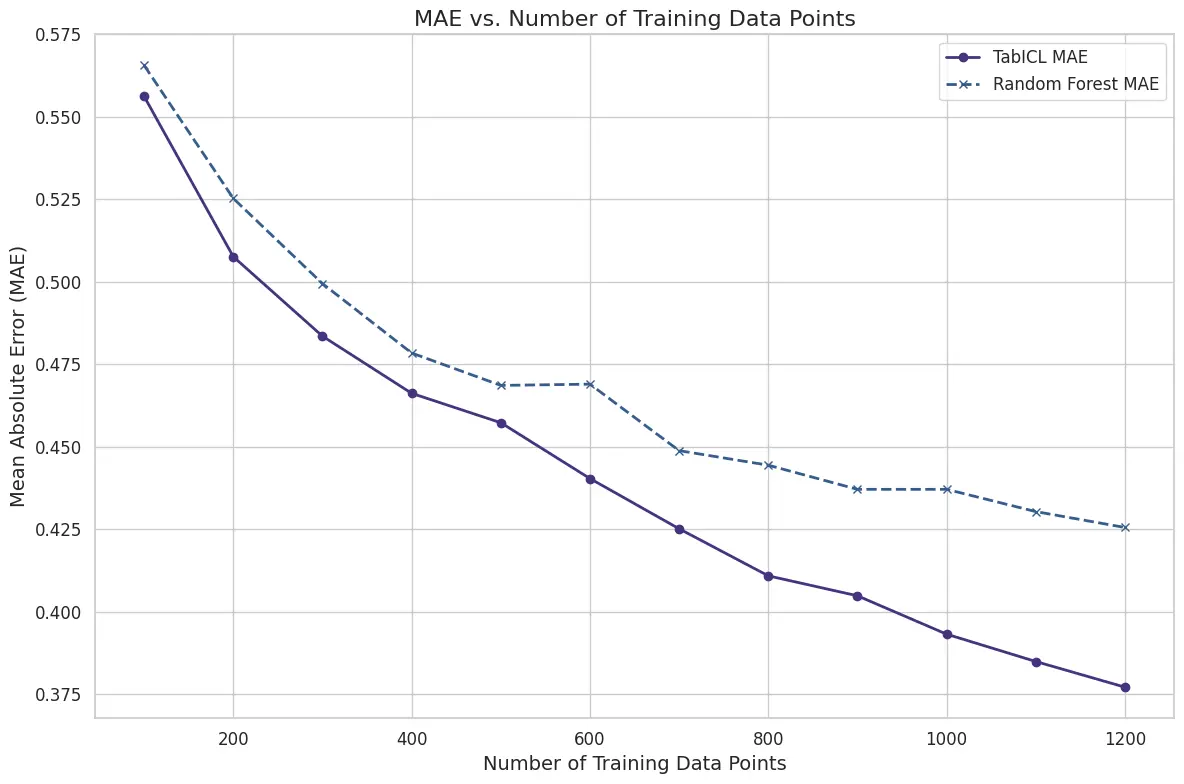
例如,下图显示了预测葡萄酒质量的平均绝对误差,比较了TabICL和随机森林。TabICL模型使用700个上下文数据点获得了与随机森林使用1200个训练数据点相同的性能。然而,将TabICL的上下文数据增加到完整的1200个数据点会给我们带来MAE的大幅提升。如今1200个数据点很容易被TFM处理。问题是,例如,从100万下采样到1万个数据点是否会导致预测性能的相关损失。
我们也可以在缩减上下文时更聪明一些:
- 这篇论文建议对每个测试数据点使用kNN模型来决定上下文。论文中一个有趣的引用:"因此我们相信,使用附近的点作为上下文是表格数据分类的良好归纳偏置。"
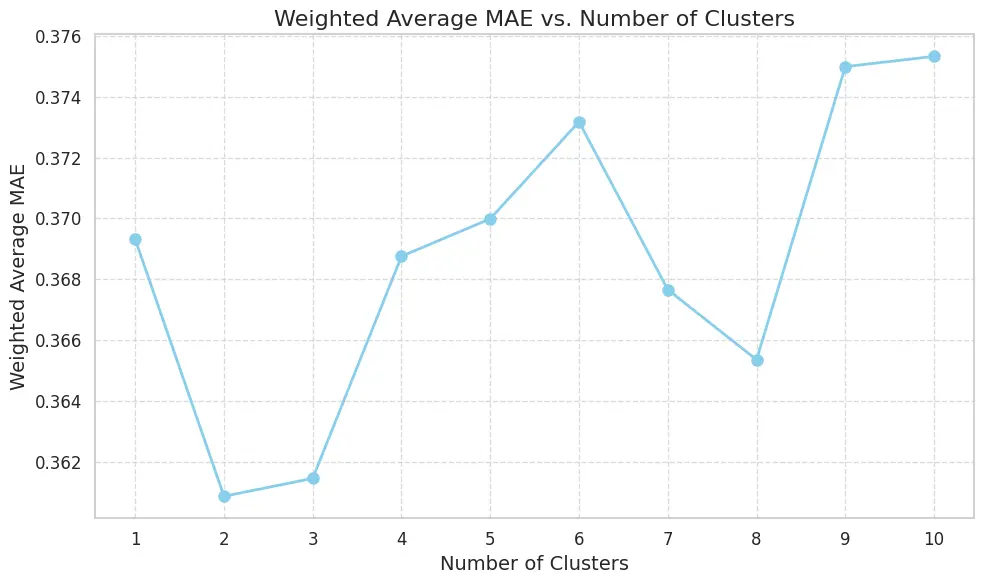
- 另一篇论文建议对训练数据进行聚类。对于测试数据中的一个数据点,检查它属于哪个聚类,然后使用相应的训练聚类作为上下文。
- 你可以将训练数据减少到代表性数据点。
下图展示了聚类方法:使用2或3个聚类实际上比使用所有数据略微更高效。
同样,所有这些方法在经典的训练-测试方案中也是可能的,但使用表格基础模型时,我们更有动力减少上下文大小,同时TFM模型在较小数据上表现相当好。
3、上下文变更就是新的重新训练
通过上下文学习,训练和推理之间的成本倒置了:训练成本接近于零,而推理变得更加昂贵。
这对可解释性、特征选择和鲁棒性分析等主题有影响。例如,在模型无关的模型可解释性中,我们有依赖打乱特征列的方法,但也有一个版本依赖于移除该列并重新训练模型。我在以下文章中涵盖了这个内容:
在一般情况下,需要重新训练的方法现在变得便宜得多,相对于需要使用同一模型预测两次的方法。通常,重新训练是昂贵的。但对于TFM,重新训练归结为调整上下文数据。重新训练的成本接近于零,我们只需为使用TFM进行预测付费。
4、TFM的上下文工程?
到目前为止,我们涵盖了为了更好的缩放而需要更小的上下文以及某些事后方法成本的变化。感觉不太像从经典的训练+预测范式转变了多大。我仍在努力理解上下文数据的框架。我们在不必考虑超参数调优、模型选择、交叉验证等方面获得了很大的灵活性。以下是关于上下文范式可能实现或简化的一些思考:
- 想象一个用户请求完全删除他们的数据。你的模型训练过的数据。从传统ML模型中移除它们需要重新训练,但对于TFM来说,只需从上下文中移除他们的数据即可。
- 想象一个预测任务,只有最近30天的数据是相关的,因为数据分布正在漂移。TFM没问题,我们可以直接使用滑动上下文窗口。
- 上下文数据使得按请求定制上下文变得更容易。例如,仅包含某个地区或客户细分数据的上下文,甚至按用户定制。
- 如果你必须移除被污染/错误/有问题的数据,只需从上下文中删除这些行。
- 特化变得容易得多。想象你有一个在银行应用中对交易进行分类的全局模型。然后用户自己对某些项目进行分类。这些可以简单地添加到上下文中。
- 定制化也被简化了。继续以交易为例,用户可以说:不要从旧交易中学习(=从上下文中移除行),或者不要使用商户名称作为特征(=从上下文中移除列)。
这些都不是真正全新的。但我仍然觉得将数据视为上下文数据而非训练数据非常令人耳目一新。而且我觉得我还没有完全掌握上下文思维方式。
原文链接: Context is the new training
汇智网翻译整理,转载请标明出处
