深入解析Claude工具调用
大多数教程只教你如何调用 LLM API 并打印响应。这篇更深入——我们将把 Claude 连接到真实的工具,让它能实际查找信息、运行计算并自主采取行动。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我们以为机器人坏了。其实没有。
当我在当前工作中第一次开始做 AI 集成时,我们的团队构建了一个内部工具——基本上是坐在语言模型之上的聊天界面。目标很简单:运营团队提问,AI 回答,大家不用再打开五个仪表板只为了查一个数字。
在演示中效果很好。然后团队有人问它:"昨天北方区域来了多少份文件?"
模型说它没有访问实时数据的权限。非常礼貌,但非常自信地错了。
会议室里沉默了一会儿。那种特定的沉默——每个人都在想同一件事,但没人想先说出来。
问题不在模型。模型没问题。问题在于我们给了它一个麦克风但没给腿——它能谈论数据,但没有实际获取数据的方法。我们最终修复了它,虽然"最终"涉及比我愿意承认的更多的 Slack 线程。
修复它的就是 tool calling。这就是本文的主题。不是概念讲解,而是实际实现、让我们栽跟头的东西,以及我对大多数教程在这个问题上略有偏差的一些看法。
从"语言模型"到"AI Agent"的跳跃不在于模型本身。而在于你是否给了它双手。
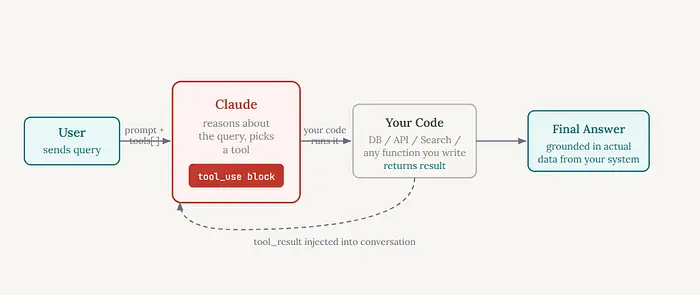
1、当 Claude"调用工具"时实际发生了什么?
在跳到代码之前值得理解这个协议。大多数文章要么跳过这部分,要么用一张看起来很炫但实际没帮助的流程图过度解释。我尽量保持实用性。
你给 Claude 发送一条消息加上一组工具定义。每个工具有一个名称、一个英文描述以及其输入的 JSON schema。Claude 读取用户的消息,决定是否需要工具来回答,如果是,它不回复文本,而是返回一个 tool_use 块:"用这些参数调用这个函数。"
你的代码运行该函数——可以是数据库查询、API 调用、文件读取,实际上任何操作——然后将结果作为 tool_result 发回。Claude 读取它,决定是否需要更多数据或已有足够信息来回答,然后要么调用另一个工具,要么生成最终响应。循环继续直到完成。
值得强调的部分:你不需要写路由逻辑。没有 if user_asks_about_inventory: call_db() 这样的代码。Claude 从对话上下文中判断使用哪个工具、何时使用。这个单一的转变就是基于规则的聊天机器人和真正 Agent 之间的区别。
老实说,第一次看到它正常工作时,我花了大约十分钟试图找到我在哪里意外硬编码了路由。我没有。模型就是……正确地决定了。
2、构建 Agent:分步教程
我们将构建一个带有三个工具的小型研究 Agent:web 搜索模拟、产品数据库查询和计算器。目标是展示 Claude 如何将这些工具串联起来,而你不需要写任何 if-else 路由。
第一步:环境设置
终端:
pip install anthropic
export ANTHROPIC_API_KEY="sk-ant-..."
第二步:定义工具
这是很多人栽跟头的地方。description 字段不仅仅是文档——Claude 读取它来决定是否使用该工具。用你向新团队成员解释工具的方式来写它。如果两个工具有重叠的描述,Claude 会猜错。
Python 文件:tool_definitions.py
tools = [
{
"name": "web_search",
"description": (
"Search the web for current information. Use this when the user asks "
"about recent news, facts you may not know, or anything that needs "
"up-to-date data. Do NOT use this for internal product or inventory data."
),
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query to look up"
}
},
"required": ["query"]
}
},
{
"name": "get_product",
"description": (
"Fetch product details from the internal product database using a SKU. "
"Returns the product name, current price, and available stock count. "
"Always use this — not web_search — for inventory or pricing questions."
),
"input_schema": {
"type": "object",
"properties": {
"sku": {
"type": "string",
"description": "Product SKU, for example: SKU-7742"
}
},
"required": ["sku"]
}
},
{
"name": "calculate",
"description": "Evaluate a math expression and return the numeric result.",
"input_schema": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "A valid Python math expression, e.g. '34 * 149.99 * 0.85'"
}
},
"required": ["expression"]
}
}
]
提示:关于描述质量注意我在 web_search 描述中添加了"Do NOT use this for internal product data",在 get_product 中添加了"Always use this, not web_search"。当工具有重叠的范围时,Claude 需要这些负面约束来正确选择。没有它们,你会在边界情况下看到错误的工具选择。有些人争论说这是一种信号——如果你的工具需要那么多消歧提示,你的工具太多了。老实说,我觉得有道理。尽可能将工具数量控制在 8 个以下。
第三步:编写工具处理器
这些只是普通的 Python 函数。这里的模拟很薄,但形状是一样的,无论你是调用 PostgreSQL、请求 Spring Boot REST 端点还是调用 Lambda。一条规则:始终返回字符串。Claude 期望返回文本,而不是 Python 对象。返回 JSON 字符串,而不是 dict。
Python 文件:tool_handlers.py
import json
def web_search(query: str) -> str:
# Replace with Brave Search, Serper, or Tavily in production
mock = {
"claude tool calling": (
"Claude tool use lets the model call developer-defined functions. "
"Supports parallel calls. Available on claude-sonnet-4 and above."
)
}
for k, v in mock.items():
if k in query.lower():
return v
return f"No cached results for: {query}"
def get_product(sku: str) -> str:
# Replace with your actual DB call — PostgreSQL, MongoDB, whatever
db = {
"SKU-7742": {"name": "Wireless Headphones Pro", "price": 149.99, "stock": 34},
"SKU-1190": {"name": "USB-C Hub 7-in-1", "price": 59.99, "stock": 208},
}
product = db.get(sku.upper())
if not product:
return json.dumps({"error": f"SKU {sku} not found"})
return json.dumps(product)
def calculate(expression: str) -> str:
try:
result = eval(expression, {"__builtins__": {}})
return str(round(result, 4))
except Exception as e:
return f"Calculation error: {e}"
def dispatch(name: str, inputs: dict) -> str:
routes = {
"web_search": lambda: web_search(inputs["query"]),
"get_product": lambda: get_product(inputs["sku"]),
"calculate": lambda: calculate(inputs["expression"]),
}
handler = routes.get(name)
if not handler:
raise ValueError(f"No handler for tool: {name}")
return handler()
关于 calculate() 中的 eval()是的,我知道。带受限 builtins dict 的 eval() 对于你控制输入的内部工具来说足够好。如果用户能以任何方式接触表达式字符串,请将其替换为 simpleeval 或 asteval。我在这里保留它是因为用正确的解析器替换会增加 30 行代码,分散本节真正关注的内容。
第四步:Agent 循环
这是整个事情的核心。只要 Claude 持续返回 tool_use 块,循环就继续运行。一旦它返回 end_turn,那就是最终答案。注意我们如何持续追加到 messages 列表——Claude 需要完整的对话历史(包括工具结果)才能继续正确推理。
Python 文件:agent.py
import anthropic
from tool_definitions import tools
from tool_handlers import dispatch
client = anthropic.Anthropic()
def run_agent(user_message: str, max_iterations: int = 10) -> str:
messages = [{"role": "user", "content": user_message}]
iteration = 0
while iteration < max_iterations:
iteration += 1
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
tools=tools,
messages=messages,
)
# Claude is done — extract and return the final text
if response.stop_reason == "end_turn":
return next(
b.text for b in response.content if b.type == "text"
)
# Claude wants to call tools — run them and collect results
tool_results = []
for block in response.content:
if block.type != "tool_use":
continue
print(f" → {block.name}({block.input})")
result = dispatch(block.name, block.input)
print(f" ← {result[:100]}")
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
# Append Claude's response and our tool results back to the conversation
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
return "Max iterations hit — agent did not complete."
if __name__ == "__main__":
q = (
"How many units do we have for SKU-7742? "
"If we sell all of them at a 15% discount, what is the total revenue?"
)
print(f"User: {q}\n")
print(f"Agent: {run_agent(q)}")
输出是什么样的
控制台:
User: How many units do we have for SKU-7742? If we sell all of them at a 15% discount...
→ get_product({'sku': 'SKU-7742'})
← {"name": "Wireless Headphones Pro", "price": 149.99, "stock": 34}
→ calculate({'expression': '34 * (149.99 * 0.85)'})
← 4334.71
Agent: SKU-7742 (Wireless Headphones Pro) has 34 units in stock.
Selling all 34 at a 15% discount brings the price down to ₹127.49 per unit,
giving a total revenue of ₹4,334.71.
值得停顿一下思考这里发生了什么:没有人告诉 Claude 调用 calculate。没有人写路由逻辑。Claude 看到问题有两部分——查询和数学问题,获取数据,然后自主决定需要计算某些东西才能回答第二部分。这就是 Agent 和普通聊天之间的行为转变。
3、并行工具调用,值得知道,容易错过
这里有个我直到仔细查看响应载荷才注意到的事情。如果用户问"比较 SKU-7742 和 SKU-1190 的库存",Claude 不会发出两个顺序请求。它在同一个响应中、一个 content 数组内同时发出两个 tool_use 块。
Claude 的响应(并行 tool_use 块)
[
{"type": "tool_use", "id": "tu_abc", "name": "get_product", "input": {"sku": "SKU-7742"}},
{"type": "tool_use", "id": "tu_def", "name": "get_product", "input": {"sku": "SKU-1190"}}
]
我们写的循环已经处理了这个——它遍历所有块。但如果你在 for 循环中顺序运行它们,你就是在浪费延迟。使用 asyncio.gather:
Python 文件:async 并行执行
import asyncio
async def run_tool_async(block):
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(None, dispatch, block.name, block.input)
return {"type": "tool_result", "tool_use_id": block.id, "content": result}
# Replace the for-loop inside your agentic loop with:
tool_blocks = [b for b in response.content if b.type == "tool_use"]
tool_results = await asyncio.gather(*[run_tool_async(b) for b in tool_blocks])
就是这样。老实说,在我们的大多数用例中,查询不够重,这个不太重要。但在文档密集的管道中,每次工具调用都在请求 S3 或外部 API 时,这会累积得很快。

4、这在哪里实际被使用
Tool calling 不是玩具功能。以下是我见过或在实际产品中构建过的地方:
- 分析门户: 工具从 S3 获取文档,查询药品数据库,并调用异常评分 API。Agent 在人类不需要手动审查每个行项目的情况下就能发现差异。
- 内部 AI 工作台: 工具包装了不同的 LLM 提供商(Bedrock、OpenAI 等)、文档存储服务和摘要管道。Agent 根据任务类型选择正确的模型。
- 客户支持机器人: 工具包括 get_order_status、apply_refund 和 escalate_to_human。Agent 端到端处理一级查询,无需人工介入。
- DevOps 助手: 工具调用 Kubernetes API、查询 CloudWatch 日志并向 Slack 发布。一些团队用这些进行 on-call 告警分流——Agent 获取上下文并建议可能的原因。
4、真正会咬到你的事情
我会跳过显而易见的,比如"处理你的 API 错误",专注于特定于 Agent 循环的东西,因为有些事情直到你踩到坑才会直觉地理解。
没有迭代上限。 这是首先咬到人的。一个持续返回意外输出的工具可以让 Agent 陷入循环——它调用工具,得到令人困惑的结果,再试一次,同样的结果,重复。上面循环中的 max_iterations 检查不是可选的。设为合理的值,大多数用例 10-15 就行,到达时返回优雅的回退消息。
懒惰的工具描述。 这我已经说了两次,因为它是工具选择出错的根本原因。"获取产品数据"不是描述,是标签。Claude 需要理解何时使用该工具、期望什么样的输入,以及重要的是,何时不使用它。花 10 分钟正确写描述。它节省了数小时调试为什么 Claude 持续调用错误东西的时间。
盲目信任 Claude 的输入。 Claude 生成传递给工具的参数。像对待表单用户输入一样对待这些参数——验证类型、检查范围、清理字符串。有一次模型传递了一个稍微格式错误的 SKU,我们的处理器抛出了一个未处理的异常,破坏了整个循环。返回 JSON 错误字符串而不是抛出异常。
返回巨大的 JSON blob 作为工具结果。 如果你的数据库查询返回 40 个字段的对象,而 Agent 只使用其中 4 个字段,你就是在为每次请求支付 36 个字段的 token 费用。返回前过滤。在我们的一个工作台集成中,将工具结果从完整 API 响应修剪到仅需要的字段,使每次请求的 token 成本降低了近 30%。

5、一些优化和一个不受欢迎的观点
System prompt 优于调整描述。 当你有两个工具有时会让模型混淆时,大多数人的本能是继续编辑工具描述。这在一定程度上有效。但在 system prompt 中添加一行——"对于任何关于库存或定价的问题,始终从 get_product 开始"——更快且通常更可靠。它不漂亮,但有效。
缓存确定性的工具调用。 在多轮对话中,Claude 有时会调用 get_product("SKU-7742") 两次——一次获取价格,后来再检查库存。在分发器级别使用简单的 dict 缓存消除了冗余的数据库访问。不是什么高深的工程,但一旦量上去了你会注意到成本差异。
不受欢迎的观点:tool_choice 强制模式使用不足。 大多数教程甚至官方文档都强调自动模式——Claude 决定一切。这很好。但有很多流程你已经知道第一次工具调用应该是什么——用户问"X 的价格是多少?"肯定首先需要 get_product,毫无疑问。在开头强制调用节省了一次推理往返。人们把强制模式当作作弊,但它只是对你已知的事情明确化。
将工具选择作为独立关注点测试。 这个我真希望有人早点告诉我。写一个小脚本,发送 20-30 个不同的 prompt,断言 Claude 选择了哪个工具。不要把这混入集成测试。工具选择会无声地退化——你调整了一个描述,其他东西坏了,然后你三天后从用户报告中发现。
6、简短版本
如果我必须压缩成简洁的东西:你的工具描述比代码更重要。循环一旦写过一次就很简单。始终限制迭代次数。返回错误字符串,而不是异常。记录工具调用——你会需要那些日志。
在花一小时编辑描述之前,先用 system prompt 引导工具选择。这是踩坑学到的。
7、为什么这比教程更重要
真正让我认真对待这件事的时刻是看着我们的分析 Agent 自主连续调用三个工具——从 S3 获取文档、查询定价数据库、运行异常检查——并标记出人类分析师可能需要在手动审查的第二或第三天才能发现的东西。整个过程不到十秒。
那不是基准测试。那是曾经每天吞噬某人数小时的工作流。
关于 Claude 特别说一句,因为本文覆盖的就是它:工具选择确实很好。比我第一次设置时预期的要好。模型相当保守——不需要时不会调用工具,这对规模化成本很重要。有些模型对函数调用很冲动,你最终为五次工具调用付费而一次就够了。这里没遇到这个问题。
本文的代码接近我实际为新集成会写的东西——去掉模拟,在 dispatch 函数上添加真实的 logger,加上适当的输入验证。将你的实际服务接入处理器,添加反映你领域的 system prompt,你就有了一套经过测试可以投入生产的东西。
选择你的用户最常问的需要真实数据的问题。为它接一个工具。当 Claude 自主串联两次调用的第一次运行时——那就是它停止感觉理论化的时刻。
最后一件事:不要一开始就过度构建工具集。从两三个工具开始,让选择正确,然后添加更多。我见过人们在第一周定义 15 个工具,然后花两周调试为什么 Claude 总是混淆它们。在你理解模型在你特定领域中的选择行为之前,少即是多。
原文链接: How to Build an AI Agent Using Claude API Tool Calling: Step-by-Step with Code
汇智网翻译整理,转载请标明出处
