30秒估算LLM显存需求
别再谷歌搜索"这个模型能装进我的 GPU 吗?",这个公式每次都能让你一目了然

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每隔几天,就会有人在 ML Discord 上发布同样的问题:"我能在两张 3090 上运行 70B 模型吗?" 回复总是含糊不清。"取决于量化。""也许用 GGUF?""试试看再说。" 没人给出明确的答案——因为大多数人没有一个清晰的心理模型。
令人沮丧的事实是,确实存在一个明确的答案。一个公式可以解释 2026 年你将遇到的每种格式、每种量化方案和每种运行时。不是查找表。不是电子表格。一个公式。
读完本文后,你将能够在 30 秒内,在脑海中估算任何模型、任何格式的显存需求。有更好的方法。一个公式。这就是你真正需要的全部。
1. 你真正需要的那个公式
核心洞见是,模型的内存占用只由两件事决定:它有多少参数,以及每个参数用多少位存储。

就是这样。这个单一等式适用于 FP16、BF16、FP8、INT8、GPTQ、AWQ、NF4 以及每种 GGUF 变体——基本上你会用到的每种格式。唯一变化的变量是每个权重的位宽。
"÷ 8" 从何而来?
简单的单位换算: 一个字节有 8 位,内存以字节(然后是千兆字节)计量。所以一个 16 位权重占用 2 字节,一个 8 位权重占用 1 字节,一个 4 位权重占用 0.5 字节。乘以参数数量,除以十亿(将字节转换为 GB),你就得到了答案。
2. 要记住的三个锚点
你不需要记住代数形式的公式。只需内化三个锚点。其他一切都是这些的变体:

FP16 = 2×FP8 = 4×4-bit 其他所有都在它们之间插值。每次将位宽减半,内存就减半。这不是巧合。这正是公式预测的。
BF16 与 FP16 占用相同的内存;它只是以不同的方式分配这 16 位(更多范围,更少精度)。内存计算相同,所以它们共享同一个锚点。
超激进的量化方案,3 位和 2 位,甚至更低,但对输出质量有显著代价。对于大多数生产工作负载,4 位是质量明显下降之前的实用下限。
3. GGUF:中间格式解释
GGUF 格式不使用整数位宽。它们使用混合精度方案,以不同粒度量化不同层,产生介于干净锚点之间的有效每权重位数。以下是每种常见变体每十亿 GB 的成本:

注意它们如何干净地位于锚点之间。Q6_K 刚好在 FP8 之下。Q4_K 刚好在理论 4 位下限之上。Q2_K 接近但未达到 2 位区域,因为"K"分组为更好的质量保留增加了少量开销。
注意到的模式: 每降低一步质量(Q6 → Q5 → Q4 → Q3 → Q2)每十亿参数节省约 0.1-0.15 GB。在 70B 模型上,这就是每步 7-10 GB 的差异——当你试图装入单张 GPU 时,这是有意义的。
4. 真实模型尺寸转换
让我们将公式应用到人们实际运行的模型尺寸。这些数字是抽象数学变成具体硬件决策的地方:

盯着 70B 这一行看一秒钟。在 FP16 中,它需要 140 GB——在考虑其他任何东西之前,仅权重就需要两张 80 GB H100。在 4 位中,它压缩到 35-40 GB,可以装入单张 48 GB GPU 并留有一些余量。这就是量化的威力:你将相同的模型从双 GPU 设置变成单 GPU 设置。
405B 这一行出于不同原因很有启发性。即使在 4 位,你也要看 200+ GB。那最少需要三张 80 GB H100,仅用于权重。现在你明白为什么人们要么激进地量化,要么用张量并行在 GPU 间分片,或者干脆说"上云吧。
5. 实例演练:自己动手计算
让我们在几个现实场景上练习公式,这样你可以自己应用而无需查找任何东西。
场景 A:在游戏本上运行 Llama 3.1 8B Q4_K_M
你有一台带 12 GB 显存 GPU 的笔记本。你想使用 llama.cpp 和 Q4_K 量化本地运行 Llama 3.1 8B。它能装下吗?
公式: 8B × 0.56 GB/B (Q4_K) = ~4.5 GB 用于权重。加 20% 开销 → ~5.4 GB 总计。12 GB 显存 − 5.4 GB = 为 KV 缓存和上下文留出舒适的 6.6 GB 余量。
结果: 是的,轻松。你甚至可以推送到 32K 上下文并留有余量。
场景 B:在单张 A100 80GB 上运行 FP8 的 Mistral 70B
你可以访问云 A100 80 GB 实例。你想运行 70B 模型的 FP8,以获得比 4 位更好的质量。它能装入单卡吗?
公式: 70B × 1 GB/B (FP8) = ~70 GB 用于权重。为运行时加 15% 开销 → ~80.5 GB。刚好在卡容量的边缘,技术上超出了卡的容量。
结果: 不行。你需要要么量化到 4 位(~40 GB),要么使用两张 A100 进行张量并行。
场景 C:在两张 3090(共 48 GB)上运行 FP16 的 13B 模型
你有两张 RTX 3090(每张 24 GB,通过流水线并行组合为 48 GB)。你想运行 FP16 的 13B 模型以获得最大质量。
公式: 13B × 2 GB/B (FP16) = ~26 GB 用于权重。加 25% 开销(批处理、长上下文的 KV 缓存)→ ~32.5 GB。这在两张卡上留下 15 GB 空闲。
结果: 是的,轻松,即使有长达 ~32K token 的上下文窗口。
6. GPU 现实检验:什么真正能装下
将公式转化为人们实际拥有的硬件。这些数字仅用于模型权重;我们接下来会涵盖开销税。
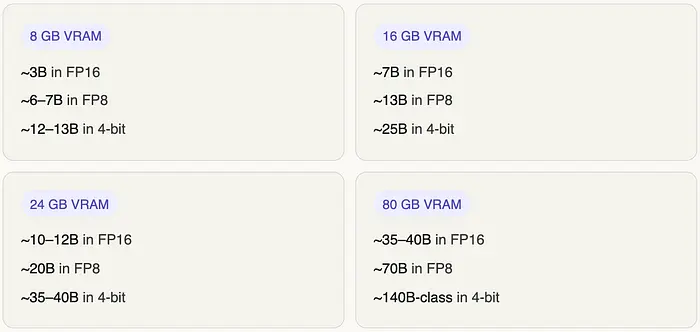
一个有用的模式:显存翻倍让你在相同格式下将模型尺寸翻倍,或在保持相同模型的情况下提升一级精度。一张 24 GB 卡运行 FP16 的 13B 模型等同于一张 12 GB 卡运行 FP8 的 13B 模型;相同模型,不同格式,对硬件的相同成本。
7. 没人谈论的显存税
这里是陷阱:即使权重数学说装得下,你第一次运行就会崩溃。那是因为权重只是显存账单的一部分。
经验法则: 总是为权重尺寸之外预留 10-30% 的额外显存。对于长上下文(32K、128K+)、高并发或智能体工作流,预留更多。
吞噬你剩余余量的隐形杀手:
- KV 缓存: 随上下文长度增长,在 32K 或 128K token 时爆发。这是长上下文工作负载的 #1 意外杀手。
- 激活值, 因运行时和优化级别而异,在某些执行路径下会激增。
- 框架开销: Transformers、vLLM、TensorRT-LLM 和 llama.cpp 都有自己的内存税。
- CUDA 图: 用预留内存换取更好的延迟和吞吐量稳定性。一个值得了解的刻意权衡。
KV 缓存值得特别关注,因为它是最令人惊讶的罪魁祸首。在 128K 上下文中使用大模型,KV 缓存可能消耗比权重本身更多的内存。这就是为什么许多生产部署使用比模型技术上支持的更短的上下文窗口——这是一个刻意的内存权衡,不是能力限制。
"如果你只预算权重,你在运行第一个 token 之前就已经内存不足了。"
8. MoE 陷阱
混合专家模型比近年来任何其他架构变化都更让更多人困惑。困惑总是以同样的方式开始:有人看到"8×7B"就本能地认为"56B 参数"。

在典型的 MoE 设置中,即使一层中有 8 个专家,每个 token 也只激活 1-2 个专家。所以一个"8×7B"模型在推理期间的计算成本可能只有 ~12B 模型,但你仍然需要在内存中保存所有 56B 参数(或在 GPU 间分片)。
这创造了一种不寻常的情况:MoE 模型的运行速度比其总参数数量暗示的更快,但托管成本并不更低。内存成本追踪总参数。计算成本追踪激活参数。如果你混淆两者,你的估计会在一个或另一个方向上严重错误。
实际含义: 估算 MoE 模型的显存时,在公式中使用总参数数量。估算延迟或吞吐量时,使用激活参数数量。永远不要混淆。
9. 为什么 GGUF 不是魔法作弊码
GGUF 在在线讨论中被视为压缩奇迹,一种在消费级硬件上运行本应无法装入的模型的方法。值得精确说明 GGUF 实际是什么和不是什么。
GGUF 是一种文件容器格式与量化策略的结合,针对 llama.cpp 风格的推理引擎和 CPU+GPU 混合执行进行优化。它确实非常擅长其设计目标。它实现的内存数字是真实的,在该运行时内。
问题是可移植性。将 GGUF 模型移到不同的推理框架,会发生两件事之一:要么框架原生支持 GGUF 量化(越来越常见),要么必须反量化权重才能运行,此时你的内存占用急剧增加,可能回到 FP16 领域。
关键规则: "它装在 6 GB 里"不是普遍真理。它是运行时特定的真理。引用 GGUF 内存数字时始终指定运行时。相同的 Q4_K_M 文件在 llama.cpp 与在加载时反量化的框架中可能有非常不同的占用。

此外,GGUF 的混合 CPU+GPU 执行意味着你可以将一些层卸载到系统内存,这就是为什么你会看到 llama.cpp 配置在"16 GB GPU"上运行 70B 模型。技术上正确,但你为此付出了每秒 token 的代价。GPU 层运行快;CPU 层运行慢几个数量级。根据你的用例,这种权衡可能可接受也可能不可接受。
10. 唯一重要的心理模型
没有需要记忆的巨型兼容性矩阵。没有需要保持书签的查找表。只需一个等式和三个数字,加上判断力。
- 从公式开始:显存 ≈ 参数 (B) × (位 ÷ 8)
- 选择你的精度锚点:FP16 → ×2,FP8 → ×1,4-bit → ×0.5,GGUF 变体 → 使用每十亿表
- 加上开销税:标准工作负载 +10-30%,长上下文或高并发 +40-50%
- 检查你的硬件:能装下吗?如果不能,拉哪个杠杆:进一步量化、在 GPU 间分片,还是上云?
一旦你内化这个,某些东西会转变。你停止问,"我能运行这个吗?" —— 一个被动的、不确定的问题。你开始问,"我想如何运行这个?",一个主动的、面向设计的问题。你开始在有意识地在质量、内存、速度和成本之间做权衡,而不是只是希望事情能工作。
那就是用大语言模型构建真正变得有趣和真正好玩的时候。公式没有消除复杂性。它给你一个基础,让你能真正理解这种复杂性,而不是在凌晨 2 点你的 pod 崩溃时感到惊讶。
去构建一些能装下的东西。

用聪明的方式思考 GPU 内存。
原文链接:GPU Memory Math for LLMs: 2026 Edition
汇智网翻译整理,转载请标明出处
