体验Gemma 4上的Claude Code
想象一下,在Nvidia GPU上运行Claude Code和Google的Gemma 4编程模型——还有比这更好的吗?

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | ONNX模型库 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Google Gemma 4是最新的AI编程模型,正在掀起热潮,所以我在Claude Code上试了试。
结果没有让我失望。
如果你读过我的上一篇Gemma 4发布文章,你就知道我对这个新的Google开源编程模型已经很兴奋了。
但我无法充分测试它,因为在本地运行31B模型需要强大的硬件。
这周情况改变了。
Ollama现在通过与NVIDIA在Blackwell GPU上的合作伙伴关系在云端运行Gemma 4。一个命令,你就可以使用一个在LiveCodeBench上得分80%、在AIME 2026上得分89.2%的模型进行编程。
多亏了Ollama,我们正在慢慢远离运行新AI模型所需的复杂硬件,正如我在评测他们的Ollama Launch功能时所说。
对于Gemma 4,你只需要ollama launch claude --model gemma4:31b-cloud,然后就可以运行了。
我花了几个小时测试这个组合
- 256K上下文窗口可以处理大型代码库而无需分块
- 原生函数调用与Claude Code的代理工作流配合良好
- Apache 2.0许可证意味着没有限制。
在本文中,我将带你了解设置过程,运行真实的编码测试,并分享我对这个组合的诚实体验。
1、Gemma 4完美适配Claude Code
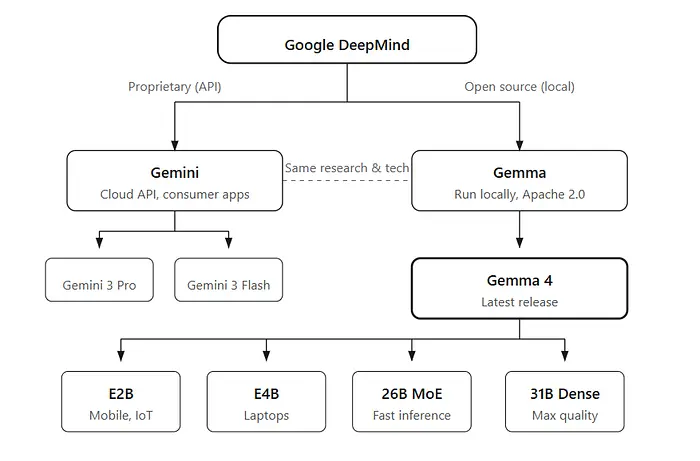
Google基于与Gemini 3相同的研究构建了Gemma 4。区别在于你可以自己运行它——本地或通过Ollama Cloud。
Claude Code用户:
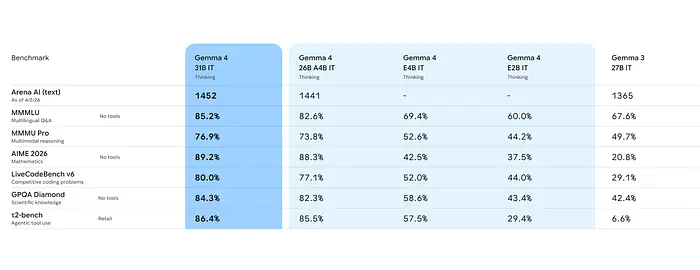
31B模型在基准测试中表现出色:
- LiveCodeBench v6: 80%——这是开源代码SOTA
- AIME 2026: 89.2%——比Gemma 3在同一测试中的20.8%大幅提升
- Codeforces ELO: 2150——竞技编程水平
- MMLU Pro: 85.2%——强大的通用推理能力
作为参考,这些数字在几个月前还是专有模型的前沿水平。
1.1 上下文窗口
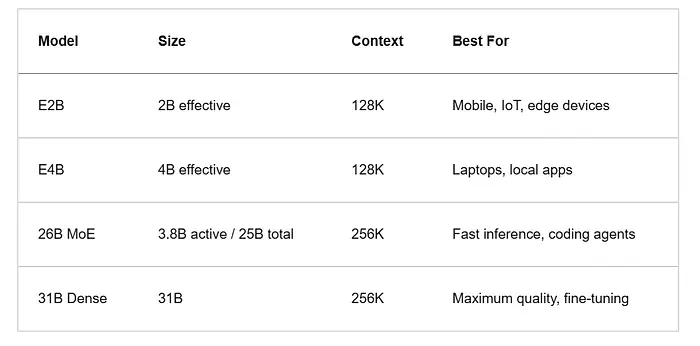
31B和26B模型支持256K令牌。较小的E2B和E4B边缘模型最高可达128K。
在实践中,你可以在一次提示中传递整个代码库而无需分块。当模型可以一次性看到所有内容时,多文件重构变得更加顺畅。
1.2 原生函数调用
Gemma 4开箱即用地支持结构化工具使用。
这对Claude Code的代理工作流很重要;模型可以快速轻松地调用外部工具、API并执行多步操作。
1.3 Apache 2.0许可证
与之前带有自定义许可证的Gemma版本不同,
Gemma 4采用Apache 2.0许可证。对商业使用、微调或部署没有限制。与Qwen和大多数开放权重生态系统类似的条款。
2、Ollama Cloud Gemma 4 Claude Code
这正是没有高端GPU的开发者所需要的。
在本地运行31B模型需要20GB+显存。26B MoE需要18GB。不是每个人都有这样的硬件。
Ollama与NVIDIA合作,在云端Blackwell GPU上运行Gemma 4。你可以获得完整的31B模型而无需硬件要求。
设置只需要一个命令:
ollama launch claude --model gemma4:31b-cloud
云模型自动以完整上下文长度运行。你不需要像本地模型那样配置上下文设置。
3、使用Claude Code设置Gemma 4
Gemma 4可在Ollama上使用,具有云集成。一个命令即可让你运行起来。
3.1 先决条件
在开始之前,确保你有:
- Ollama v0.15+已安装
- Claude Code v2.1+已安装
- Ollama Cloud账户
3.2 安装Ollama
如果你还没有安装Ollama:
Mac:
brew install ollama
Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows: 从ollama.com下载安装程序并运行它。
验证安装:
ollama --version
3.3 安装Claude Code
如果你已经安装了Claude Code,请跳到第3步。
Mac/Linux:
curl -fsSL https://claude.ai/install.sh | bash
Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
验证安装:
claude --version

你应该看到2.1.92或更新版本。
3.4 拉取Gemma 4云模型
ollama pull gemma4:31b-cloud
云模型注册很快,因为推理发生在NVIDIA的Blackwell GPU上。
3.5 使用Gemma 4启动Claude Code
以下是命令:
ollama launch claude --model gemma4:31b-cloud
Ollama在幕后处理API配置。你不需要手动导出环境变量或设置基础URL。
3.6 验证设置
一旦Claude Code运行,检查状态:
/status
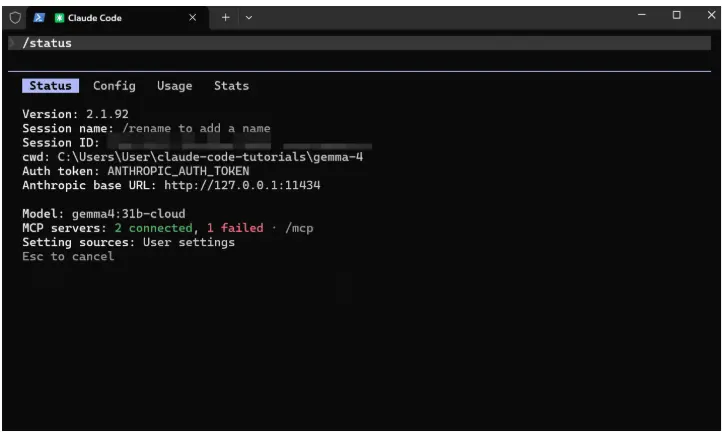
你应该看到:
- 模型:gemma4:31b-cloud
- Anthropic基础URL:http://127.0.0.1:11434
- 认证令牌:ANTHROPIC_AUTH_TOKEN
3.7 测试提示
一旦你确认正在使用Gemma 4模型,你现在可以运行测试提示:
4、了解云模型
Gemma 4在Ollama Cloud上远程运行,而不是本地运行。
以下是它的含义:
- gemma4:31b-cloud: 通过Ollama的云在NVIDIA Blackwell GPU上运行
- 256K上下文窗口: 完整上下文长度,无需配置
- 无需本地GPU: 繁重工作在NVIDIA的服务器上完成
你的代码和提示被发送到云端进行处理。如果你正在处理专有代码库,请记住这一点。
5、本地模型选项
如果你有硬件并且更喜欢本地推理:
# 适用于笔记本电脑(10GB+显存)
ollama pull gemma4:e4b
ollama launch claude --model gemma4:e4b
# 适用于工作站(18GB+显存)
ollama pull gemma4:26b
ollama launch claude --model gemma4:26b
# 适用于最高质量(20GB+显存)
ollama pull gemma4:31b
ollama launch claude --model gemma4:31b
本地模型给你隐私和零延迟,但需要大量显存。
6、实际编码测试
我运行了一些测试,看看Gemma 4在真实编码场景中的表现如何。
6.1 复杂应用构建(一次性完成)
与我之前的GLM文章相同的方法。
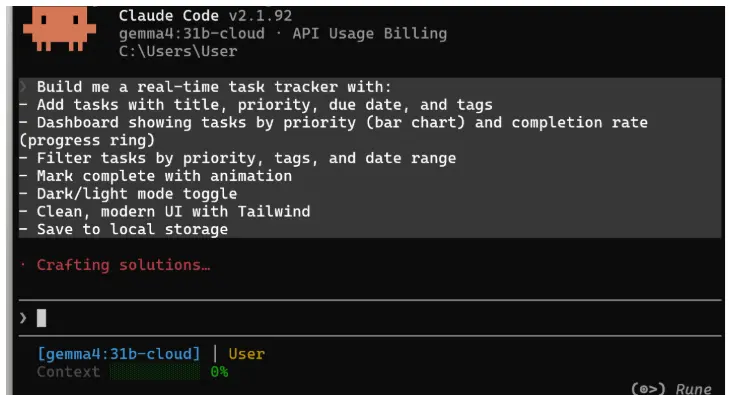
以下是我的提示:
为我构建一个实时任务追踪器,包含:
- 添加带有标题、优先级、截止日期和标签的任务
- 显示按优先级(条形图)和完成率(进度环)显示任务的仪表板
- 按优先级、标签和日期范围筛选任务
- 带动画的标记完成
- 深色/浅色模式切换
- 使用Tailwind的简洁现代UI
- 保存到本地存储
Gemma 4激活了自动驾驶模式,并使用规划代理在编写任何代码之前分解任务。
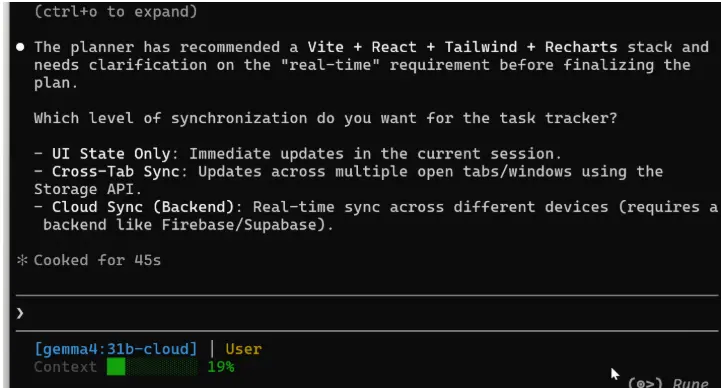
它选择了Vite + React + Tailwind + Recharts作为技术栈。然后它问了一个关于"实时"含义的澄清问题——仅UI状态、跨标签同步还是云同步。
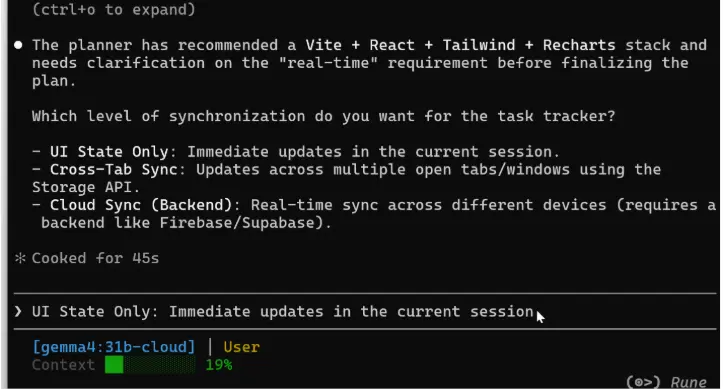
这不是我要求的东西。模型将复杂请求分解为阶段,并在继续之前要求澄清。
在选择仅UI状态后,Gemma 4构建了完整的应用程序。
- 组件组织良好
- 图表正确渲染
- 深色模式一次成功
一次性完成一个带有图表、筛选、动画和本地存储持久化的工作应用程序。代码结构简洁,Tailwind类遵循一致的模式。
6.2 多文件操作
256K上下文窗口应该有助于多文件重构。
我要求Gemma 4将一个现有的JavaScript项目重构为TypeScript:
将此项目重构为使用TypeScript而不是JavaScript。
更新所有文件,添加正确的类型,并确保一切仍然正常工作。
Gemma 4在所有文件中保持上下文。当它在更新导入时,它记得那些类型。
6.3 终端操作
我测试了基于终端的编码能力:
使用TypeScript、ESLint、Prettier和Jest设置一个新的Node.js项目。
正确配置所有配置文件,并添加用于开发、构建、测试和lint的npm脚本。
tsconfig.json、.eslintrc、.prettierrc和jest.config.js都能协同工作而没有冲突。
6.4 观察
测试期间有几件事脱颖而出:
- 自动规划: Gemma 4将复杂任务分解为阶段。它使用规划代理在编写代码之前分解需求。
- 澄清问题: 当需求不明确时,模型会问聪明的问题。
- 代码质量: 生成的代码很简洁。组件组织良好。
- 上下文保留: 多文件操作运行顺畅。
- 速度: 云端推理很快。
7、最终想法
Claude Code上的Gemma 4提供了速度和良好的性能。Google发布了一个严肃的开源代码模型。
基准测试转化为真实性能。Ollama Cloud集成消除了硬件障碍。
如果你一直在等待一个与Claude Code配合良好的Google模型,这就是它。
原文链接:I Tried Gemma 4 On Claude Code (And Found New FREE Google Coding Beast)
汇智网翻译整理,转载请标明出处
