FemtoClaw 微型龙虾智能体
你能在价格低于一杯咖啡的芯片上运行 AI 智能体吗?

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
我发现了 Ziboyan Wang 开发的 MimiClaw —— 这是一个在 ESP32-S3 上运行 AI 智能体的精彩项目。MimiClaw 证明了你不需要 Linux 就能和 Claude 或 OpenAI 对话。你可以在裸机 C 语言环境中,在 FreeRTOS 任务上实现这一切。
但 MimiClaw 需要配备 8MB PSRAM 的 ESP32-S3 —— 一块价值 10 美元的开发板,而我手头有一块 ESP-WROOM-32,这是我在 2018 年买的。此外,它还需要 Claude 或 OpenAI 的 API 密钥,但我不想为此付费,因为 OpenClaw 和其他 Claws 项目支持 Ollama、vLLM 或 LM Studio 等本地模型。
ESP-WROOM-32 没有 PSRAM。在 WiFi 和 FreeRTOS 占用份额后,只剩下约 120KB 内部 SRAM。两个 TLS 连接(一个用于 Telegram,一个用于 LLM API)每个都要消耗约 120KB。基本上什么都没剩下。我尝试构建并烧录,但无法烧录到 ESP32,因为它需要 ESP32-S3,所以我遇到了阻碍!
我想在 ESP32 上实现这个目标。一块价值 4 美元的微控制器,拥有约 120KB 的可用内存,看看我能否在如此有限的设备上让它运行起来。我 fork 了 MimiClaw 并添加了 ESP32 支持,它成功了。我称之为 FemtoClaw。
1、FemtoClaw 实际上能做什么
FemtoClaw 是一个运行在裸机 ESP32 硬件上的完整 AI 智能体。以下是它的功能:
- 通过 Telegram 聊天 —— 从手机向它发送消息,获得由 Claude、GPT 或本地 LLM 模型(通过 Ollama 或 LM Studio 提供)驱动的响应
- 搜索网络 —— 使用 DuckDuckGo(零配置)或 Brave Search(需要 API 密钥)
- 记住事物 —— 长期记忆存储在闪存中的 markdown 文件里,重启后仍然保留
- 调度任务 —— AI 创建自己的 cron 作业并自主执行
- 心跳 —— 定期唤醒,检查任务列表,并在未被请求的情况下采取行动
- 读写文件 —— 在板载的 SPIFFS 文件系统上
- 在多个 LLM 提供商上运行 —— Anthropic (Claude)、OpenAI (GPT)、Ollama 和 LM Studio
所有这些功能都使用纯 C 语言实现,运行在 FreeRTOS 上,底层没有操作系统。
2、架构:将智能体塞进 120KB
以下是系统架构图:
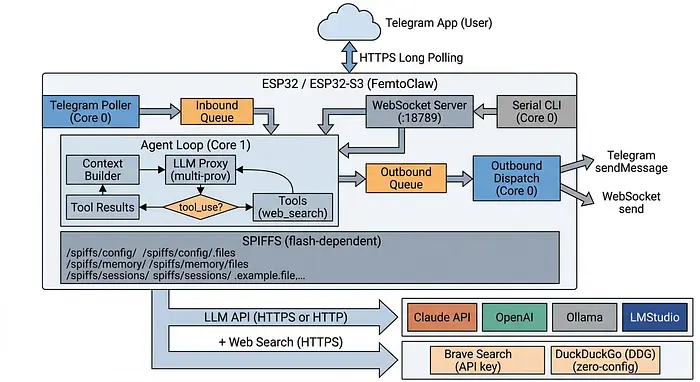
设计将工作分配到两个 CPU 核心:
核心 0 处理所有 I/O —— Telegram 长轮询、WebSocket 服务器、串行 CLI、WiFi 事件和出站消息调度。
核心 1 完全专注于智能体循环。它从入站队列中取出消息,构建系统提示(从闪存加载个性、用户资料、长期记忆和日常笔记),构建消息数组,并进入 ReAct 循环。
ReAct 循环调用 LLM,检查响应是否包含工具调用,执行它们(网络搜索、文件操作、cron 管理),追加结果,然后再次循环 —— 最多 10 次迭代 —— 直到模型完成。
消息通过 FreeRTOS 队列流动。入站来自各个通道,出站来自智能体。清晰的分离,没有共享状态。
3、记忆系统
FemtoClaw 将所有内容作为纯文本文件存储在 SPIFFS 闪存上:
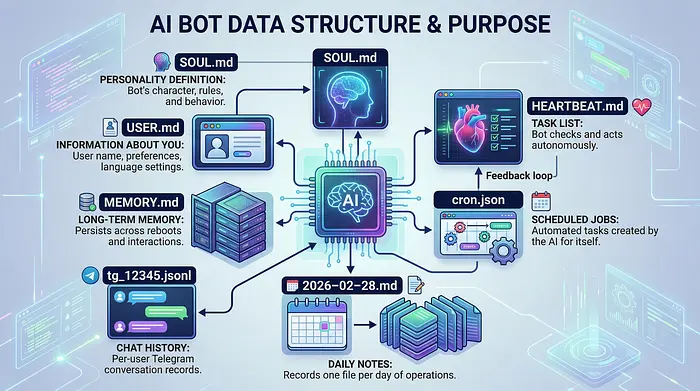
没有数据库。没有 Redis。只是闪存芯片上的 markdown 文件。事实证明这就是你所需要的一切。
4、困难的部分:在没有 PSRAM 的情况下让它工作
在 ESP32-S3(那块 10 美元的开发板)上,你有 8MB 的 PSRAM。这很容易。TLS 缓冲区、JSON 解析、会话历史 —— 把它们全部扔进 PSRAM 就可以继续了。
在 ESP-WROOM-32 上,你没有任何这些东西。以下是内存预算:
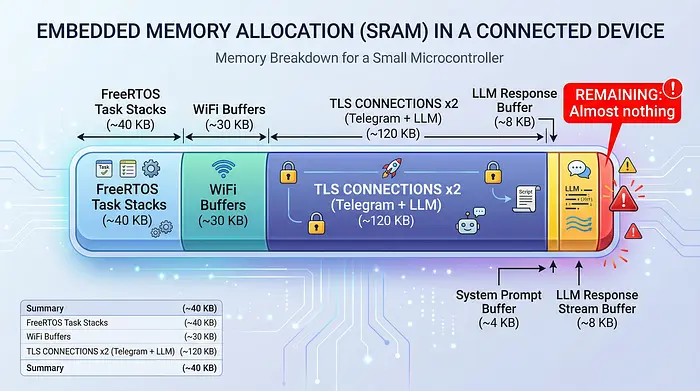
每个缓冲区都必须仔细调整大小。LLM 流缓冲区从 32KB (S3) 降到 8KB (ESP32)。上下文缓冲区从 16KB 降到 4KB。这些数字不是随意的 —— 它们是大量反复试验的结果。
femto_config.h 中的 #if CONFIG_SPIRAM 守卫处理这种分割:
#if CONFIG_SPIRAM
#define FEMTO_LLM_STREAM_BUF_SIZE (32 * 1024)
#else
#define FEMTO_LLM_STREAM_BUF_SIZE (8 * 1024)
#endif
它有效。
5、多提供商 LLM:不仅仅是 Claude
MimiClaw 只支持 Claude 或 OpenAI。我从一开始就想要的是提供商的灵活性以及对本地模型的支持。FemtoClaw 目前支持四个 LLM 后端:
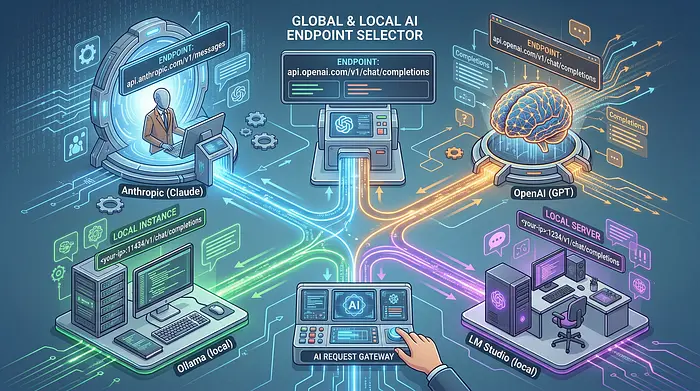
你可以通过串行 CLI 在运行时切换提供商 —— 无需重新烧录:
femto> set_model_provider openai
femto> set_api_base_url http://192.168.1.100:11434
femto> set_model minimax-m2.5:cloud
LLM 代理自动处理所有格式差异。Anthropic 使用 system 作为顶级字段和 input_schema 作为工具。OpenAI 将系统提示放在消息数组中,并将工具包装在 function 对象中。代理在它们之间进行透明转换。
这意味着你可以完全离线地在本地网络上使用 Ollama 运行 FemtoClaw。一块 4 美元的芯片与本地 LLM 对话。无需云端。
6、零配置网络搜索:DuckDuckGo 来救场
MimiClaw 为所有功能都需要 API 密钥。我不想为网络搜索这样做。如果有人买了一块 4 美元的开发板并烧录了 FemtoClaw,网络搜索应该直接工作。
所以我构建了一个在 ESP32 本身上运行的 DuckDuckGo HTML 抓取器。它向 html.duckduckgo.com/html/ 发送 POST 请求,解析原始 HTML 响应,并提取标题、URL 和摘要。
棘手的部分?DuckDuckGo 的 HTML 页面在实际结果开始之前有大约 8KB 的样板代码。在具有 8KB 缓冲区的 ESP32 上,这意味着你的整个缓冲区被标题和导航填充 —— 没有结果。
修复方案是一个流式 HTML 解析器,它会跳过所有内容,直到找到 class="results"。只有那时它才开始写入缓冲区。这个单一优化使 DuckDuckGo 能够在 8KB RAM 上使用。
如果你确实有 Brave Search API 密钥,FemtoClaw 会改用它 —— JSON 解析更清晰、更快。但 DuckDuckGo 开箱即用,这很重要。
7、双目标:一个代码库,两个芯片
FemtoClaw 在同一个代码库中运行在 4 美元的 ESP-WROOM-32 和 10 美元的 ESP32-S3 上。ESP-IDF 构建系统处理目标选择:
idf.py set-target esp32 # $4 板
idf.py set-target esp32s3 # $10 板
S3 获得更大的缓冲区、PSRAM 分配,并有资格使用需要第三个 TLS 连接或更多闪存空间的功能。路线图根据硬件约束将每个计划的功能标记为"两者都支持"或"仅 S3":
两者都支持(4 美元 + 10 美元): 系统信息工具、Telegram 白名单、API 密钥轮换、模型故障转移、webhook 端点、天气工具、Gemini 提供商
仅 S3(10 美元): HTTP 获取、会话压缩、Discord 机器人、Web 仪表板、从 URL 安装技能
ESP32 并没有被削弱 —— 它运行完整的智能体循环、网络搜索、cron、心跳和记忆系统。S3 只是解锁了需要更多 RAM 或闪存的额外功能。
8、我学到了什么
构建 FemtoClaw 教会了我一些代码中不会显现的东西:
限制催生创造力。 当你只有 120KB 时,你不添加功能 —— 你减少浪费。每次分配都会被质疑。每个缓冲区都会被测量。结果是软件只做它需要做的事情,不多不少。
Markdown 作为存储格式被低估了。 SOUL.md、MEMORY.md、日常笔记 —— AI 读写的是人类使用的相同格式。没有序列化层,没有 ORM,没有模式迁移。只是文本文件。
ReAct 模式出奇地可移植。 在云服务器上的 Python 中运行的相同观察-思考-行动循环,在微控制器上的 C 语言中也能运行。LLM 不在乎是什么在调用它。你只需要解析 JSON 和发出 HTTP 请求 —— ESP-IDF 两者都处理得很好。
4 美元的硬件惊人地强大。 ESP32 是为 IoT 传感器和 WiFi 小工具设计的。但通过精心设计,它运行一个完整的 AI 智能体。这感觉像是未来 —— 绝对边缘的智能,在硬件上足够便宜,可以嵌入任何地方。
9、自己试试
FemtoClaw 在 MIT 许可证下是开源的。你需要:
- 一块 ESP-WROOM-32(4 美元)或 ESP32-S3(10 美元)开发板
- 一个 Telegram 机器人令牌(从 BotFather 免费获得)
- 一个来自 Anthropic、OpenAI 或本地 Ollama/LM Studio 实例的 API 密钥
烧录它,发送一条 Telegram 消息,然后看着一块 4 美元的芯片思考。
10、接下来是什么
路线图包括会话压缩(总结旧消息以防止上下文丢失)、Discord 机器人、OTA 技能安装和 Web 仪表板 —— 所有这些都针对 ESP32-S3。对于 ESP32,重点是用现有功能的稳定性和效率。
我也在探索将 Gemini 作为第三个云端提供商和直接天气 API 集成,以减少网络搜索开销。
如果你对嵌入式 AI、边缘计算感兴趣,或者只是享受在不可能小的硬件上让事情工作的挑战 —— 我很乐意听到你的声音。提出问题、提交 PR,或者只是给仓库点星标并关注。
世界上最小的 AI 助手可以放在你的手掌中。而且它的成本比你早晨的咖啡还低。

原文链接: FemtoClaw: I Built the World's Smallest AI Assistant on a $4 Chip
汇智网翻译整理,转载请标明出处
