FineTune Studio:Mac微调AI工具
我想要一件事:拿一个数据集,选一个模型,点击训练,然后得到一个微调好的LLM——全部在我的MacBook Pro上完成。没有云账单,没有Jupyter笔记本,没有YAML配置文件。所以我正在构建它。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
FineTune Studio 是一个桌面应用,可以在Apple Silicon上使用MLX本地微调大型语言模型。它处理一切——从Hugging Face下载模型、准备数据集、运行LoRA/QLoRA训练并显示实时指标、与微调后的模型对话——全部通过可视化界面完成。
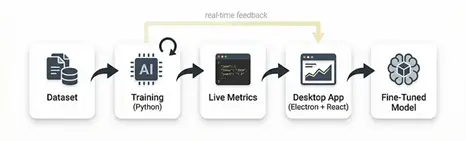
以下是它的工作原理、我构建过程中学到的东西,以及你如何做同样的事情。
1、为什么本地微调很重要
2025年的微调格局是这样的:你要么为云GPU付费,要么在笔记本环境中挣扎,要么用配置文件拼接CLI工具。
但Apple Silicon改变了游戏规则。M系列芯片配备了统一内存——CPU和GPU共享同一块RAM。一台拥有36GB内存的MacBook Pro可以轻松微调7B参数模型。Apple ML研究团队的MLX框架使这一切变得快速且内存高效。
缺失的部分是界面。训练脚本存在,工具链存在,但没有一个应用能把它们整合成一个人类真正想使用的工作流。
这就是我构建的东西。
2、技术栈
FineTune Studio是一个 Electron + React 应用,带有用于ML操作的Python后端。
- 前端:React,基于哈希的路由,自定义CSS设计系统,SVG图表
- 后端:Electron IPC桥接到使用
mlx-lm的Python脚本 - 训练:通过Apple MLX框架实现LoRA和QLoRA
- 推理:使用
mlx-lm.server提供本地模型服务 - 模型:直接从Hugging Face Hub下载
架构有意保持简洁。Electron生成Python子进程进行训练和推理。IPC消息将实时指标(损失、步数、token/秒)从训练循环传回UI,在那里它们渲染为实时更新的图表和进度条。
3、选择模型
应用直接连接到Hugging Face Hub。你搜索一个模型,它会显示可用的模型——名称、大小、下载次数。
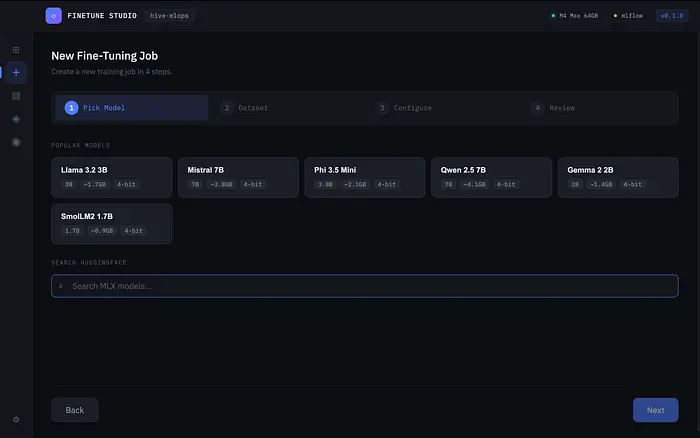
一键将模型下载到本地缓存。应用会跟踪你已经下载的模型,避免重复获取。
我专注于在消费级硬件上与MLX配合良好的模型:
- Mistral 7B — 优秀的通用模型,16GB内存即可运行
- Llama 3.1 8B — Meta最新模型,出色的指令遵循能力
- Phi-3 Mini — 微软紧凑的3.8B模型,出人意料地强大
- Gemma 2 9B — 谷歌的开源模型,基准测试表现强劲
- Qwen 2.5 — 优秀的多语言支持
关键限制是内存。MLX将模型加载到统一内存中,所以你的RAM就是你的VRAM。一个7B模型在4-bit QLoRA下使用约6GB。同一模型的全量LoRA需要约14GB。应用会在你提交前显示这些数字。
4、准备你的数据集
训练框架期望非常特定的格式:带有包含{role, content}对象的messages数组的JSONL。
FineTune Studio自动处理这个。
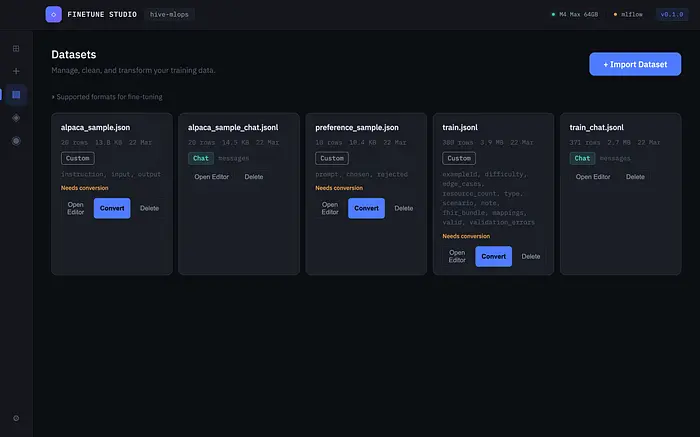
当你导入数据集时,应用检测其格式:
- Chat — 已经有带角色的
messages,可以直接训练 - Completions — 有
prompt/completion对 - Text — 用于继续预训练的原始文本列
- Custom — 有其他列(如
instruction、input、output)
对于自定义格式,Convert按钮打开一个列映射模态框。
你将列映射到聊天角色——哪一列是用户消息,哪一列是助手回复,可选系统提示。实时预览显示转换后的数据确切样子。点击"Convert & Save",你会得到一个新的_chat.jsonl文件,可以直接用于训练。
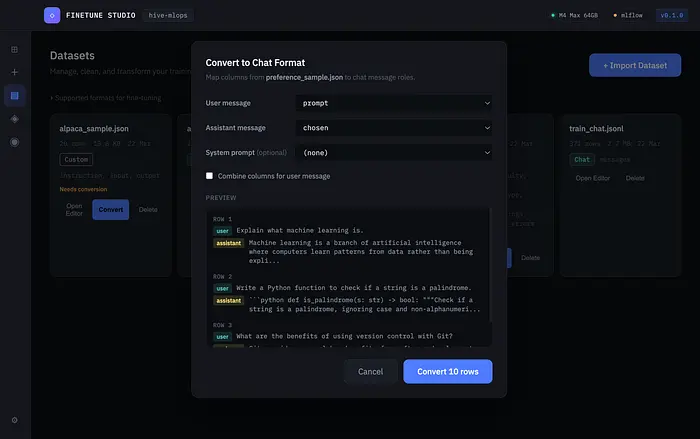
模板模式对于Alpaca风格的数据集非常强大。如果你的数据有instruction和input作为单独的列,你可以写一个模板如{instruction}\n\n{input},应用会将它们合并成单个用户消息。
5、配置和训练
新建任务向导引导你完成配置,并提供合理的默认值。
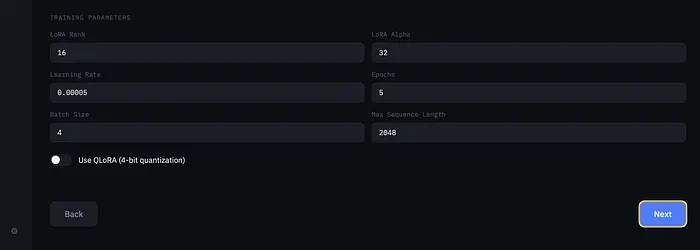
关键参数:
- LoRA Rank(默认:8)— 更高 = 更多容量,更多内存
- LoRA Alpha(默认:16)— 缩放因子,通常是rank的2倍
- Learning Rate(默认:1e-5)— LoRA微调的标准值
- Epochs(默认:1)— 对于指令调优,一个epoch通常足够
- Batch Size(默认:1)— 内存受限时保持为1
- QLoRA — 4-bit量化训练,减少约60%内存使用
QLoRA开关是"能在MacBook Air上运行"和"需要Mac Studio"的区别。对于大多数用例,QLoRA以极低的内存成本产生几乎相同质量的结果。
点击Start Training,任务就开始了。
6、观察学习过程
这是我最自豪的部分。训练不是黑盒。
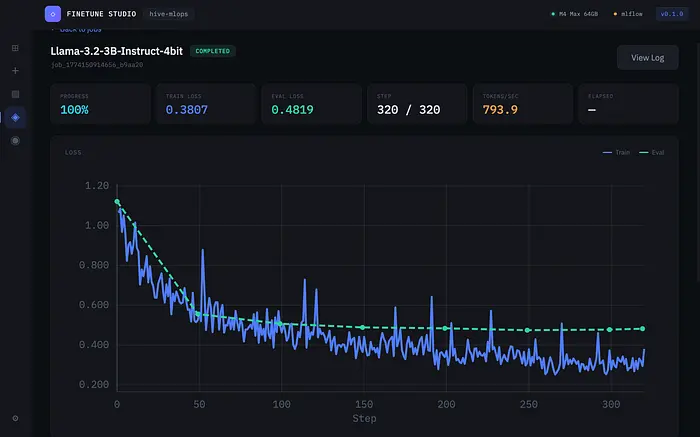
任务详情视图显示:
- 实时进度条和步数
- 训练损失和评估损失实时更新
- 每秒token数吞吐量
- 已用时间
- 损失曲线图 — 训练损失为实线,评估损失为虚线
损失图是自定义SVG组件。没有图表库——只是根据指标流计算路径。每个训练步骤通过IPC发出一个指标事件,图表用新数据点重新渲染。
看着损失曲线实时下降确实令人满足。你能看到模型开始学习你的数据的确切时刻。
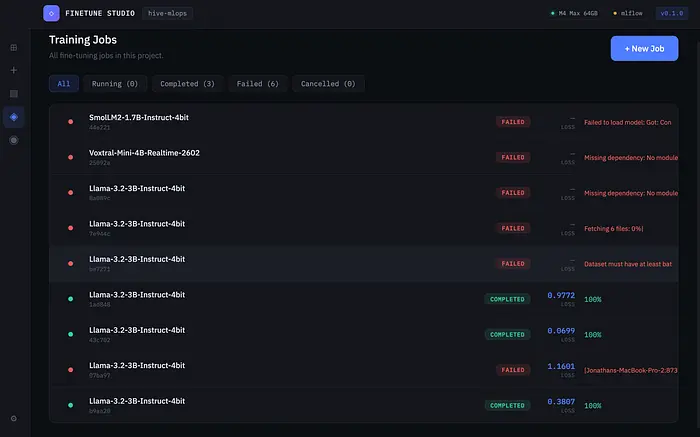
任务列表给你所有训练运行的概览。每行显示模型名称、状态、最新损失,以及运行中任务的迷你进度条。你可以按状态过滤,快速找到已完成的运行。
7、与你的模型对话
训练完成后,你会得到一个LoRA适配器——一个小文件(通常10-50MB),修改基础模型的行为。应用可以在本地提供微调后的模型服务,并给你一个聊天界面来测试它。
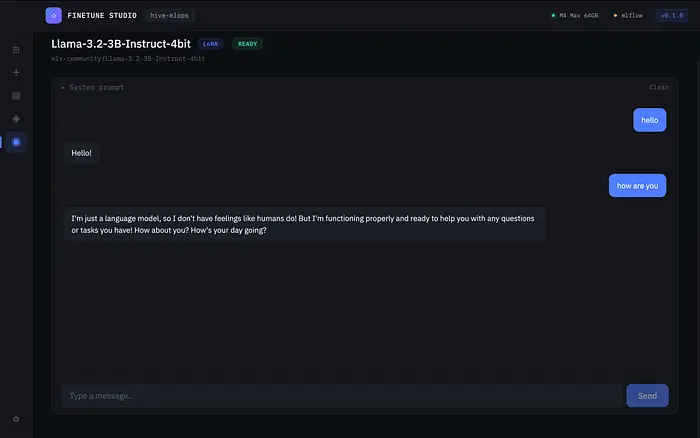
你上传数据,训练20分钟,现在你在与一个了解你领域的模型对话。客户支持数据变成支持机器人。医疗问答变成临床助手。代码示例变成专业的编码助手。
8、构建过程中的收获
- 统一内存是超级能力
Apple Silicon的统一内存架构意味着没有CPU到GPU的数据传输瓶颈。一个7B模型几秒钟就能加载,在M2 Pro上以40-60 token/秒的速度训练。这不是云GPU的速度,但足够快速迭代。10K样本的完整epoch大约需要30分钟。
- LoRA使本地训练变得实用
全量微调一个7B模型需要约28GB(仅模型权重),加上优化器状态。LoRA冻结基础模型,只训练小的适配器矩阵——通常是总参数的0.1-1%。QLoRA更进一步,将冻结权重量化到4-bit。结果:你可以在8GB RAM中微调一个7B模型。
- 数据集才是难点
模型选择和超参数很重要,但数据集决定了90%的结果。我花在构建数据集管道——导入、检测格式、预览、转换、验证——上的时间比训练UI还多。仅列映射转换就处理了数十种边缘情况:嵌套JSON对象、缺失值、多列模板、各种编码。
- 实时反馈改变行为
当训练是一个运行一小时并打印最终损失数字的CLI脚本时,你运行一次然后祈祷。当你实时看到损失曲线时,你在几分钟内就能发现问题。损失提前停滞?停止并调整学习率。损失飙升?你的数据可能有问题。视觉反馈循环让你成为更好的实践者。
- Electron其实挺好的
Electron的批评者会来找我麻烦,但对于这个用例它是理想的。我需要生成Python进程,管理文件系统状态,并渲染响应式UI。Electron给我Node.js进行进程管理,给我React构建界面。应用使用约150MB RAM——与训练期间模型消耗的8-14GB相比微不足道。
9、详细架构
对于想构建类似东西的人,以下是各部分如何连接:
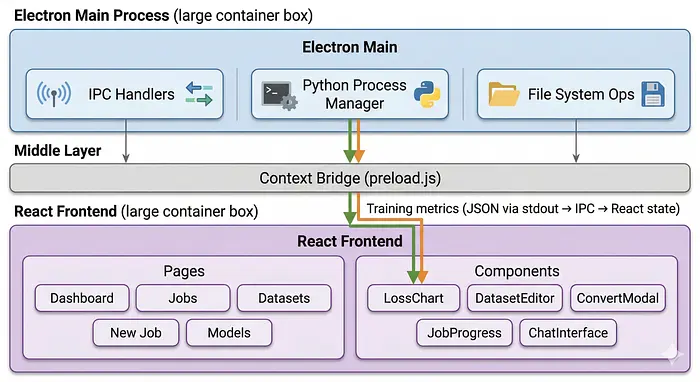
Electron主进程处理所有系统操作——文件I/O、Python进程生成、Hugging Face API调用。预加载脚本暴露一个window.studioAPI供React前端调用。训练指标作为JSON行从Python的stdout通过IPC桥传输到React状态。
10、入门指南
如果你想在Mac上尝试本地微调:
- 硬件:任何Apple Silicon Mac。16GB RAM最低,32GB+推荐。
- 软件:Python 3.11+、Node.js 18+、
mlx-lm包。 - 第一个模型:从Phi-3 Mini(3.8B)或启用QLoRA的Mistral 7B开始。两者都能舒适地运行在16GB内存中。
- 第一个数据集:从Hugging Face获取任何指令调优数据集——
tatsu-lab/alpaca是经典的起点。应用会自动转换它。 - 第一次运行:默认超参数就很合理。只需选择模型、选择数据集,然后点击训练。
你的第一个微调模型将在不到一小时内准备好。从那以后,关键就是数据——为你的用例策划一个特定的数据集,你会惊讶于7B模型适应的速度。
11、接下来的计划
我正在积极构建:
- 适配器管理 — 比较、合并和版本化你的LoRA适配器
- 评估基准 — 不仅仅是损失的自动化质量评分
- 导出到GGUF — 转换微调后的模型以便与Ollama和llama.cpp一起使用
- 多GPU支持 — 在网络上跨多台Mac分发训练
目标是让微调像使用照片编辑器一样平易近人。你有原材料(数据),你有工具(FineTune Studio),输出是一个完全符合你需求的模型。
原文链接: Ship Your Own AI: I Built a Desktop App That Turns Any Dataset into a Fine-Tuned Model
汇智网翻译整理,转载请标明出处
