granite-4.0-1b-speech
高准确度6种语言ASR。双向往返翻译。所有功能集成在一个1B模型中,可在本地运行——基准测试高于8B替代方案。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我已经介绍过几款ASR模型,包括Parakeet、VibeVoice-ASR和Voxtral Mini 4B Realtime。最近,IBM发布了新的granite-4.0-1b-speech模型,该模型不仅支持多语言自动语音识别,还支持双向自动语音翻译。这个模型在ASR场景中表现良好,参数相对较少。
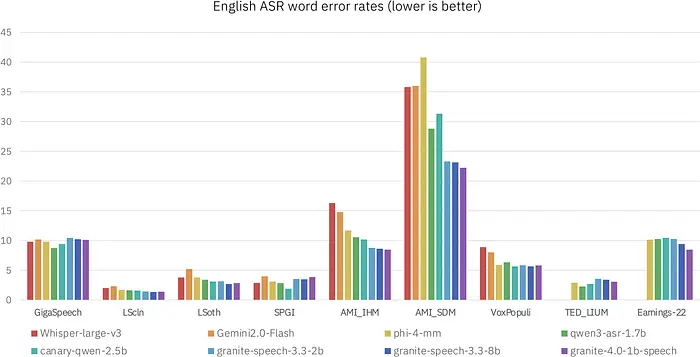
Granite-4.0-1b-speech特性:
- 新增配置关键词列表的功能,以增强名称和首字母缩写词的识别。
- 支持包括英语、法语、德语、西班牙语、葡萄牙语和日语在内的语言。
- 与granite-speech-3.3-2b和granite-speech-3.3-8b模型相比,编码器和解码器经过优化,实现了更准确的转录质量和更快的推理速度。
1、本地部署
官方granite-4.0-1b-speech文档已经描述了如何使用transformers和vLLM部署granite-4.0-1b-speech。本文将介绍如何使用mlx-audio在本地部署granite-4.0-1b-speech。
1.1 配置虚拟环境
uv venv .venv
source .venv/bin/activate
1.2 安装mlx-audio
uv pip install "git+https://github.com/Blaizzy/mlx-audio.git" --prerelease=allow
1.3 下载模型
你可以根据计算机配置和实际需要下载相应的量化模型。
mlx granite-4.0-1b-speech
hf download mlx-community/granite-4.0-1b-speech-8bit --local-dir ./models/granite-4.0-1b-speech-8bit
# 或者
hf download mlx-community/granite-4.0-1b-speech-bf16 --local-dir ./models/granite-4.0-1b-speech-bf16
1.4 运行Granite-4.0-1b-speech模型
ASR(转录)
为了测试Granite-4.0-1b-speech模型的ASR能力,我使用Vidpai内置的Kokoro引擎生成了对话音频。
s0: Hello, how are you today?
s1: I'm doing great, thanks for asking! How about you?
s0: I'm fine too. What are your plans for today?
s1: I'm planning to work on some exciting projects.
生成音频后,将其重命名为audio.wav。当然,你也可以选择任何包含支持语言的音频文件。
from mlx_audio.stt import load
model = load("models/granite-4.0-1b-speech-8bit")
result = model.generate("audio.wav")
print(result.text)
成功运行上述代码后,控制台将输出以下结果:
hello how are you today i'm doing great thanks for asking how about you i'm fine too what are your plans for today i'm planning to work on some exciting projects
与原始文本相比,ASR识别结果正确。对于长音频识别场景,我们可以设置stream参数来启用流式推理:
from mlx_audio.stt import load
model = load("models/granite-4.0-1b-speech-8bit")
for text in model.generate("audio.wav", stream=True):
print(text, end="", flush=True)
值得注意的是,该模型不支持同时包含多种语言的混合音频,否则会在推理过程中抛出解码异常错误消息。
2、AST(语音翻译)
language参数启用语音翻译。可用值为:英语、法语、德语、西班牙语、葡萄牙语和日语。还支持每种语言的语言编码。
LANGUAGE_CODES = {
"en": "English",
"fr": "French",
"de": "German",
"es": "Spanish",
"pt": "Portuguese",
"ja": "Japanese",
}
以下代码将英语音频文件(audio.wav)直接翻译成法语:
from mlx_audio.stt import load
model = load("models/granite-4.0-1b-speech-8bit")
# Translate speech to French (using language code)
result = model.generate("audio.wav", language="fr")
print(result.text)
运行上述代码后,将输出以下结果:
bonjour, comment allez-vous aujourd'hui ? je vais bien, merci pour m'en demander. et vous ? je vais bien, aussi. que pensez-vous de vos projets ?
将上述法语翻译成英语显示内容不完整:
Hello, how are you today? I'm fine, thank you for asking. And you? I'm fine too. What do you think of your plans?
由于我们的产品目前没有这个要求,我没有继续测试。如果你感兴趣,可以尝试granite-4.0-1b-speech-bf16模型或测试更多新的音频样本。
3、结束语
granite-4.0-1b-speech模型的创新之处在于其语音翻译功能,这比先进行转录然后再翻译要方便得多。然而,翻译的准确性仍然需要改进。如果你有多语言语音识别需求,建议你比较Nvidia Parakeet和OpenAI Whisper模型。
原文链接: Stop Overpaying for Inference: The 1B Speech Model That Runs Locally and Outperforms 8B…
汇智网翻译整理,请联系出处
