Harness工程:代码编辑工具
对于"如何改变内容"这个简单问题的"最佳解决方案",没有真正的共识。这些工具中没有一个给模型一个稳定的、可验证的标识符来标识它想要更改的行,而不浪费大量上下文并依赖完美回忆。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
现在的对话几乎完全是关于哪个模型在编码方面最好,GPT-5.3还是Opus。Gemini对比这周发布的任何东西。这种框架越来越误导人,因为它把模型当作唯一重要的变量,而实际上瓶颈之一是更平凡的东西:Harness(工具框架)。
它不仅是你获取用户第一印象的地方(是不受控制地滚动,还是像黄油一样顺滑?),它也是每个输入token的来源,是模型输出与工作区变更之间的接口。
我维护着一个"业余爱好项目"oh-my-pi,它是Mario Zechner出色的开源编码代理Pi的一个分支。到目前为止,我已经编写了约1,300次提交,主要是当我看到痛点时进行一些改进(~~或者当自闭症发作,我看到通过N-API嵌入更多Rust的机会,因为"调用rg感觉不对"~~)。
你问为什么要费这个劲?Opus可能是一个很棒的模型,但Claude Code直到今天还在从子代理输出中泄露原始JSONL,浪费了数十万token。我可以说,"去它的,子代理现在输出结构化数据"。
工具模式、错误消息、状态管理——所有介于"模型知道要改什么"和"问题已解决"之间的内容。这正是实践中大多数失败发生的地方。
由于它是模型无关的,它是一个很好的测试平台,因为模型只是一个参数。真正的变量是你拥有难以想象控制权的Harness。
不管怎样,让我告诉你昨天我改变的这一个变量。
1、编辑工具!
在我解释我构建了什么之前,值得了解一下当前的技术水平。
Codex使用apply_patch:它接受一个字符串作为输入,这本质上是一个OpenAI风格的diff。Harness不依赖结构化模式,而是期望这个数据块遵循严格的规则集。由于OpenAI的人毫无疑问是聪明的,我确信在GPT的Codex变体的LLM网关处,token选择过程被偏向于适应这种结构,类似于JSON模式或必需工具调用等其他约束的工作方式。
但是把这个给任何其他完全不知道它的模型?补丁失败率飙升。在我的基准测试中,Grok 4的补丁失败率是50.7%,GLM-4.7的是46.2%。这些不是坏模型——它们只是不会说这种语言。
Claude Code(和大多数其他工具)使用str_replace:找到精确的旧文本,替换为新文本。思考起来很简单。但模型必须完美地重现每个字符,包括空格和缩进。有多个匹配?被拒绝。"在文件中未找到要替换的字符串"错误非常常见,以至于它有自己的GitHub问题汇总帖(+27个其他问题)。不是最佳的。Gemini基本上做同样的事情加上一些模糊空格匹配。
Cursor训练了一个单独的神经网络:一个微调的70B模型,其全部工作是将草稿编辑正确地合并到文件中。Harness问题如此之难,以至于资金最充足的AI公司之一决定再投入一个模型,即使如此,他们在自己的博客文章中也提到"对于400行以下的文件,完全重写整个文件优于aider风格的diff。"
Aider的自己的基准测试显示,仅格式选择就使GPT-4 Turbo从26%变为59%,但GPT-3.5使用相同格式只得了19%,因为它无法可靠地生成有效的diff。格式与模型一样重要。
JetBrains的Diff-XYZ基准系统地证实了这一点:没有单一的编辑格式在所有模型和用例中占主导地位。EDIT-Bench发现只有一个模型在现实编辑任务中达到60%以上的pass@1。
如你所见,对于"如何改变内容"这个简单问题的"最佳解决方案",没有真正的共识。我的看法: 这些工具中没有一个给模型一个稳定的、可验证的标识符来标识它想要更改的行,而不浪费大量上下文并依赖完美回忆。它们都依赖于模型重现它已经看到的内容。当它做不到时——它经常做不到——用户就会责怪模型。
2、Hashline!
现在耐心听我说。如果当模型读取文件或grep某些内容时,每行都带有一个2-3个字符的内容哈希标记:
11:a3|function hello() {
22:f1| return "world";
33:0e|}
当模型编辑时,它引用这些标签—— "替换行2:f1,替换范围1:a3到3:0e,在3:0e之后插入。"如果文件在最后一次读取后发生了变化,哈希值(乐观地)不会匹配,编辑在任何内容被破坏之前就会被拒绝。
如果它们能回忆起一个伪随机标签,很可能它们知道自己在编辑什么。那么模型就不需要重现旧内容,或者天哪空格,来证明一个可信的"锚点"来表达它的更改。
3、基准测试
由于我主要关心的是现实世界的性能,测试用例的生成方式如下:
- 从React代码库中随机选取一个文件。
- 通过我们可以预期其逆操作的编辑引入变异,框架为bug(例如运算符交换、布尔翻转、差一错误、可选链移除、标识符重命名)。
- 用普通英语生成问题描述。
一个平均的任务描述看起来像这样:
修复`useCommitFilteringAndNavigation.js`中的bug
一个guard子句(早期返回)被移除了。
问题在`useCommitFilteringAndNavigation`函数中。
恢复缺失的guard子句(带早期返回的if语句)。
自然,我们不期望这里达到100%的成功率,因为模型可以提出一个独特的解决方案,不一定与原始文件完全相同,但这些bug足够机械,大多数时候,修复就是我们的变异被还原。
每个任务3次运行,每次运行180个任务。每次都是新的代理会话,四个工具(读取、编辑、写入)。我们只是给它一个临时工作区,传递提示,一旦代理停止,我们就与格式化前后的原始文件进行比较。
十六个模型,三种编辑工具,结果是明确的:patch对几乎所有模型来说都是最差的格式,hashline对大多数模型来说匹配或优于replace,最弱的模型获益最大。 Grok Code Fast 1从6.7%提高到68.3%,提升了十倍,因为patch失败得如此灾难性,以至于模型的实际编码能力几乎完全被机械编辑失败所掩盖。MiniMax翻了一倍多。Grok 4 Fast的输出token减少了61%,因为它不再在重试循环中燃烧token。
4、所以呢?
Gemini的成功率提高了8%,这比大多数模型升级带来的提升都大,而且它花费了零训练计算量。 只是一点实验(和约$300的基准测试费用)。
通常模型在理解任务方面并不不稳定。它在表达自己方面不稳定。你在为起落架责怪飞行员。
5、关于厂商的一点看法
Anthropic最近屏蔽了OpenCode,这是一个非常受欢迎的开源编码代理,通过Claude Code订阅访问Claude。
Anthropic的立场"OpenCode逆向工程了一个私有API"表面上是公平的。他们的基础设施,他们的规则。但看看这个行动传递的信号是什么:
不要构建Harness。用我们的。
不只是Anthropic。在写这篇文章时,Google完全禁止了我的Gemini账户:
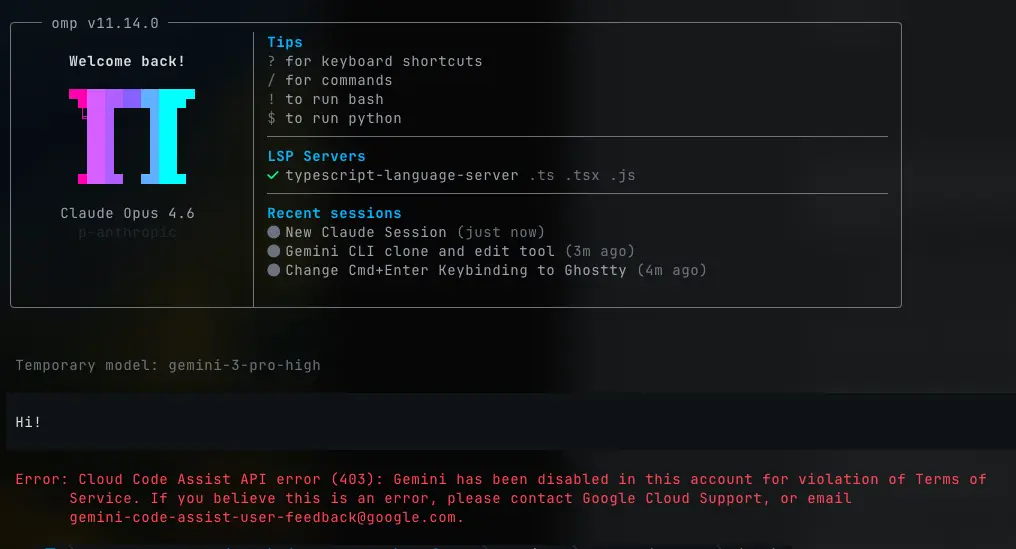
不是速率限制。不是警告。禁用。因为运行了一个基准测试——同一个基准测试显示Gemini 3 Flash用一种新技术达到78.3%,比他们最好的尝试高出5.0个百分点。我甚至不知道为什么。
这就是为什么这是倒退的。我刚刚展示了一种不同的编辑格式将他们自己的模型提高了5到14个百分点,同时将输出token减少了约20%。这不是威胁。这是免费的研发。
没有厂商会为竞争对手的模型做Harness优化。Anthropic不会为Grok调优。xAI不会为Gemini调优。OpenAI不会为Claude调优。但开源Harness为所有这些模型调优,因为贡献者使用不同的模型并修复他们个人遇到的失败。
模型是护城河。Harness是桥梁。烧毁桥梁只是意味着更少的人愿意跨越。认为Harness已经解决,甚至无关紧要,是非常短视的。
6、结束语
我来自游戏安全背景。作弊者对生态系统的破坏性极大。当然,他们被封禁、追捕、起诉,但众所周知的秘密是,最终安全团队会问,"酷!想告诉我们你是怎么绕过的吗?"然后他们就加入了防御。
当有人弄乱你的API,并设法用他们的工具聚集了大量关注时,正确的回应是"告诉我们更多",而不是"让我们大规模封禁他们数千人;想要解封请私信求情"。
Harness问题是真实的、可衡量的,它是现在创新杠杆最高的地方。"酷演示"和"可靠工具"之间的差距不是模型魔法。它是工具边界上仔细的、相当无聊的经验工程。
Harness问题终将解决。问题是由一家公司私下为一个模型解决,还是由一个社区公开为所有模型解决。
基准测试结果不言自明。
原文链接: I Improved 15 LLMs at Coding in One Afternoon. Only the Harness Changed.
汇智网翻译整理,转载请标明出处
