AI代理如何排序内容
想象一个企业代理被投入到一个混乱的现实:成千上万的文档、少量的API、半记住的过去对话,以及一个模糊的指令,比如"弄清楚上个季度出了什么问题。"它无法阅读所有内容。它无法做所有事情。它必须决定现在什么重要。
微信 ezpoda免费咨询:AI编程 | Vibe Coding | OpenClaw安装
在某个时刻,每个代理都必须做出选择。
想象一个企业代理被投入到一个混乱的现实:成千上万的文档、少量的API、半记住的过去对话,以及一个模糊的指令,比如"弄清楚上个季度出了什么问题。"它无法阅读所有内容。它无法做所有事情。它必须决定现在什么重要。
那个安静的、不可见的、几乎从未被记录的决定就是内容排序。
不是SEO那种。不是谷歌结果页面那种。是某种更微妙、也更加重要的东西。
1、假设LLM像搜索引擎一样排序
大多数解释都以错误的隐喻开始。它们从网络搜索中借用语言:相关性分数、排序算法、有序列表。这听起来很合理,但在应用于大型语言模型时几乎立即就会失败。
LLM并不是坐在一堆文档之上,从最好到最坏进行排序。它不维护一个源排行榜。在模型内部,没有明确的"前十名"概念。
相反,存在的是概率。
鉴于模型到目前为止所见的一切——提示、检索到的上下文和之前的对话,它预测接下来会发生什么。一次一个token。排序,在这个世界中,不是模型执行的一个步骤。它是从模型采取的路径中产生的东西。
一旦代理进入画面,那条路径就会被重新访问、中断和反复重塑。
2、排序在模型发言之前就开始
在LLM生成其第一个词时,大部分真正的排序工作已经发生了。
检索系统决定哪些文档甚至被考虑。嵌入相似性将语料库修剪到一个可管理的片段。元数据规则悄悄地移除日期范围、权限边界或域约束之外的任何内容。只有几十个块存活。其他一切都消失。
这是第一个也是最不容原谅的排序步骤。
人们花很多时间讨论提示质量。在实践中,检索质量是更难的上限。如果一个文档从未进入上下文,它可能就像不存在一样。没有任何下游推理可以恢复它。
在这个阶段,排序看起来是机械的:余弦相似性、阈值、过滤器。但它已经编码了判断。哪些字段很重要?哪些嵌入是在什么数据上训练的?什么算作"足够新"或"足够权威"而保留?
这些决定定义了代理认为自己操作的世界。
3、在模型内部:软偏好,而不是排序
一旦上下文组装完成,LLM就会做一些类似于排序的事情,而从未明确地执行它。
某些事实比其他事实拉得更重。某些短语锚定推理。早期的token塑造了接下来感觉自然说的东西。自信的陈述倾向于挤掉试探性的陈述,即使两者都出现在上下文中。
没有任何东西是有序的。没有任何东西被评分。然而,偏好出现了。
这就是为什么两个文档可以在上下文中并排坐在一起,而只有一个最终塑造了答案。模型不是在人类意义上"选择"。一条信息只是更适合模型已经开始的轨迹。
这种排序是隐式的和脆弱的。将一段移到上下文窗口的前面,它突然变得更重要。重新措辞一个句子,平衡就会发生转变。如果你期望明确的评分,系统会以感觉不直观的方式变得敏感。
4、代理增加了另一层:作为控制流的排序
代理改变了问题的性质,因为它们不仅仅是消费内容。它们决定接下来做什么。
代理对文档进行排序,但它也对问题、工具、计划和行动进行排序。它决定是再次搜索、调用API、要求澄清,还是完全停止。
这是二阶排序,这是大多数真实系统成功或失败的地方。
代理可能会检索五个相关文档,然后决定只有一个值得仔细阅读。它可能会丢弃它们所有并触发另一个检索循环。它可能会决定没有任何内容像从下游系统提取新数据一样重要。
这些都不看起来像经典排序,但它们对同一件事进行排序。注意力被分配。选项被修剪。路径被关闭。
而且这个排序不是静态的。两个步骤之前重要的事情在工具调用或新约束之后可能变得无关。代理不断重新排序,通常不留任何明确痕迹。
5、记忆改变了风险
一旦代理有了记忆,排序就不再纯粹是情境性的。
现在代理不仅仅是在问"什么对这个任务重要?"它还在隐含地问,"以前什么重要?"
过去互动的摘要、学到的偏好和情景回忆都像预加权上下文一样起作用。它们很早就出现。它们影响框架。它们偏重哪些新信息感觉冗余或可信。
这可能是有用的。这也可能是危险的。
管理不善的记忆会导致代理过度重视过时的假设,轻视新的证据。在实践中,这表现为没有好奇心的自信。代理在应该之前很早就感到确定。
仍然没有排名表。但是行为使优先级显而易见。
6、排序在何处悄悄失败
大多数失败不会自我宣布。
代理自信地回答,而错过了在上游被过滤掉的关键文档。它继续重复相同的解释,因为它的记忆加强了它。它停止搜索,因为第一个结果感觉"足够好"。
这些不是模型失败。它们是排序失败。
升级到更大的模型很少修复它们。如果检索是浅层的、嵌入是过时的,或者代理不知道何时怀疑自己的上下文,你只会得到更快的错误答案。
强大的系统内置了重新排序的机会。它们允许代理扩大搜索、重新审视假设,并注意到何时信心超过了证据。
7、排序是政策,无论你是否这样称呼
在企业系统中,排序决定悄悄地成为治理决定。
哪些文档更受青睐?哪些来源被信任?哪些信号覆盖其他信号?这些选择在人类审查最终答案之前很久就塑造了结果。
将排序视为技术细节,它将消失到基础设施中,带着它的偏见。将其视为政策,它就变得可检查、可调整和可辩论。
这种转变是不舒服的。它也是必要的。
8、真正重要的时刻
回到开场场景:一个代理从数千份文档中选择一份。
没有什么戏剧性的事情发生。没有警报触发。没有分数被显示。但那单一的选择决定了随后的一切——推理、行动以及其他人将依赖的答案。
这就是智能在这些系统中显示自己的地方。不是在雄辩的散文中。不是在聪明的提示中。
在它们关注什么;以及它们悄悄留下什么。
9、深度LLM RAG:向量数学,加上一些修复
查询首先命中一个嵌入存储,如Pinecone或Qdrant。文档通常被分割成大约512个token的块,并使用诸如text-embedding-3-small之类的模型进行嵌入。
相似性使用余弦相似性计算:
score = (query_vec · doc_vec) / (|query| |doc|)
在实践中,系统可能会取分数高于0.75的前八个块并将它们传递到提示中。
向量搜索擅长语义,但它在精确术语方面很弱。这就是为什么许多系统还运行BM25,它使用词频和逆文档频率来捕获关键词匹配。
两种结果通常使用倒数排名融合(RRF)结合:
1 / (60 + rank_position)
所以一个在向量搜索中排名第3、在BM25中排名第1的文档可能最终位于整体顶部。
之后是重排序。一个交叉编码器,如bge-reranker-base,直接对每个查询-文档对进行评分。它较慢(每个块大约50毫秒),但精度提升通常是值得的。
两个在实际系统中起作用的实用调整:
- 使用诸如
e^(-days/30)之类的东西衰减较旧的文档 - 使用固定乘数提升受信任的来源,例如1.3×
示例查询:"电动汽车电池风险"
向量搜索可能会拉入分数在0.81左右的供应商报告。BM25可能会因为强关键词匹配而将关税文档推得更高。重排序然后删除了一个在纸张上看起来相关但不再成立的过时PDF。
即使有所有这些,如果你让LLM这样做,它们仍会将薄弱的来源混合成听起来自信的答案。这个问题不会神奇地消失。
10、代理:循环、判断器和图
代理(AutoGen、LangGraph和类似框架)不仅仅检索一次。它们在过程中保持排序和重排序。
典型的流程看起来像这样:
运行与上述相同的混合检索。
让LLM充当判断器:"对这些1-5进行排序并解释原因。" 它返回结构化输出,如:
[ {"doc": "tariffs.md", "score": 9, "why": "fresh override"} ]
跨步骤组合置信度。例如:
0.9 (retrieval) × 0.85 (verification) × 0.75 (graph support) = 0.57
如果分数低于0.6,代理循环并再次尝试。
添加批评家。一个标记陈旧性("来自2022年?减去20%")。另一个强制执行本体论规则("不允许负面库存")。
基于图的RAG通过对路径而不是块进行评分来进一步推动这一点。
示例:
- 矿产→供应(边分数0.92,最近)* 供应→风险(边分数0.88,权威性)
组合路径得分为0.81。PageRank风格的提升然后有利于连接良好的节点。
简单术语中的权衡:
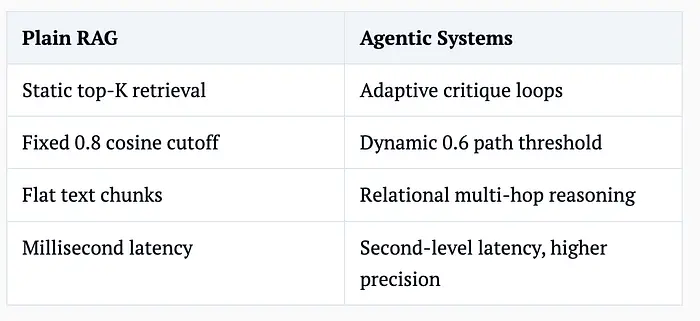
代理更好地处理复杂、高风险查询,但它们花费更多的时间和计算。在实践中,大多数系统两者都使用。
常见的生产分割看起来像这样:
- 85%带有重排序的朴素RAG
- 15%用于合规和风险敏感决策的代理工作流
一条永远不会改变的规则:总是跟踪不确定性。即使错了,LLM听起来也很自信。
这就是它的核心。
原文链接: How LLMs and Agents Rank Content
汇智网翻译整理,转载请标明出处
