我用AI自动化了80%的工作
大多数开发者把AI当作更聪明的Google来用。输入问题。获取答案。复制。粘贴。继续。 那只是一个稍微快一点的剪贴板。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
三个月前,我每天工作10个小时。 邮件、工单、代码审查、研究简报。那种填满日历却不产生任何实际成果的工作。 然后我构建了一些东西。第一个早上我醒来看到六个已处理的任务,感觉真的超现实。
1、"自主AI工作流"到底意味着什么
让我先诚实地说一件事。
"AI代理"这个词被到处抛来抛去,好像它意味着一个什么都能做的机器人。其实不是。自主AI工作流比炒作暗示的更简单也更强大。
它是一个接收触发器、通过LLM处理、并在你不在循环中时执行定义好的动作的系统。
就是这样。触发器 → 思考 → 行动。
就像 事件驱动架构
魔力不在于AI。而在于你如何设计交接。大多数尝试这个的开发者在到达那一步之前就失败了。
2、大多数开发者使用AI的问题
大多数开发者把AI当作更聪明的Google来用。
输入问题。获取答案。复制。粘贴。继续。 那不是工作流。那是一个稍微快一点的剪贴板。
我想要的与众不同。我希望AI坐在我的流程中,观察、处理和行动,这样我就可以专注于那20%真正需要我判断的事情。
以下是我现在的工作流:
- 研究一个主题 → 代理抓取、总结并结构化简报。
- 新客户工单到达 → 代理分类、起草回复、标记边缘情况。
- GitHub上打开PR → 代理审查明显的bug和风格不一致。
这些输出没有一个完美。但每个任务都为我节省了30-60分钟。这累积得很快。
3、技术栈(不废话)
我不会告诉你用无代码工具然后称之为工作流。如果你是开发者,好好构建它。
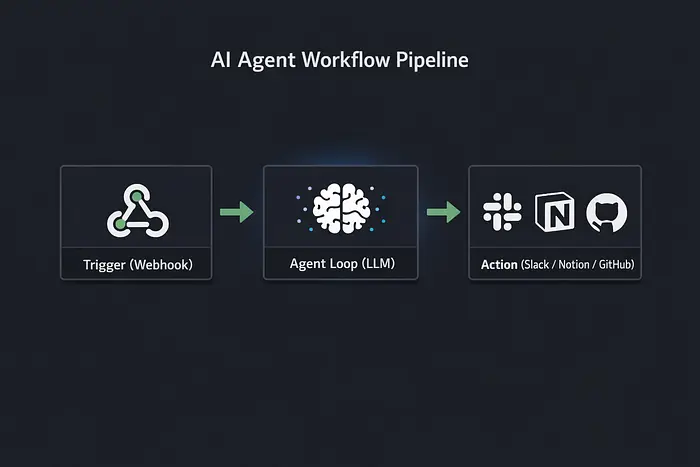
以下是我运行的东西:
- 编排: Claude API (claude-sonnet-4) 通过直接API调用
- 触发层: Node.js + Express webhook端点
- 内存/状态: Upstash Redis用于对话历史和批处理上下文
- 存储: Cloudinary用于文件和图像输入
- 输出目的地: Slack、Gmail、Notion通过webhook或原生API
架构比听起来更简单:
// Simplified agent loop - the core of the system
async function runAgentTask(trigger, context) {
const history = await redis.get(`history:${trigger.id}`) || [];
const response = await anthropic.messages.create({
model: "claude-sonnet-4-20250514",
max_tokens: 1000,
system: AGENT_SYSTEM_PROMPT,
messages: [...history, {
role: "user",
content: context
}]
});
const output = response.content[0].text;
await redis.set(`history:${trigger.id}`, [
...history,
{ role: "user", content: context },
{ role: "assistant", content: output }
]);
return output;
}
AGENT_SYSTEM_PROMPT 这是大部分智能所在的地方。稍后详述。
4、每个人都搞错的部分:系统提示词
这是没人谈论的事情。
大多数开发者把90%的时间花在技术上,10%花在提示词上。应该反过来。
你的系统提示词是你代理的大脑。它定义了它扮演什么角色、可以自主做哪些决策、如何格式化输出、何时行动何时标记为需要人工审查。
我的研究代理的系统提示词看起来像这样:
You are a research assistant embedded in a developer's workflow.
Your job is to take a raw topic or URL and return a structured brief.
Format: Topic → Key Points (5 max) → Gaps in existing content → Recommended angle.
Be specific. Cut everything generic. Flag uncertainty explicitly.
Do not summarize - synthesize. There is a difference.
五句话。一个清晰的输出模式。一个质量指令。
这比"你是一个有帮助的助手"好200倍。
很多开发者忽略了这点: 提示词就是你的产品规格。你花在优化它上的每一小时都节省十小时的糟糕输出。像代码一样对待它,版本控制、测试、迭代。
5、构建触发层(以及没人提到的陷阱)
没有东西唤醒它,代理就毫无用处。
我使用简单的webhook。每个工作流都有自己的端点:
/agent/research— 由Slack命令触发/agent/review-post— 当Notion页面移至"草稿完成"时触发/agent/code-review— 在GitHub PR打开事件时触发
每个webhook接收有效载荷、提取上下文、传递给代理循环、并将结果发回来源。干净。封装好。可调试。
大多数教程在这里就停了。但有一个陷阱。
无状态代理对多步骤任务毫无用处。
如果你的代理记不住五分钟前处理了什么,它就无法跨多个输入进行推理。这就是为什么Redis层不是可选的;它维护每个任务的对话历史,允许代理在之前的上下文基础上构建,而不是每次从头开始。
6、一个周二早上这实际看起来是什么样
上周二,我打开Slack,有11条消息在等待。
代理已经处理了六条。两条有草稿回复等待我批准。三条被标记为需要我的实际判断。
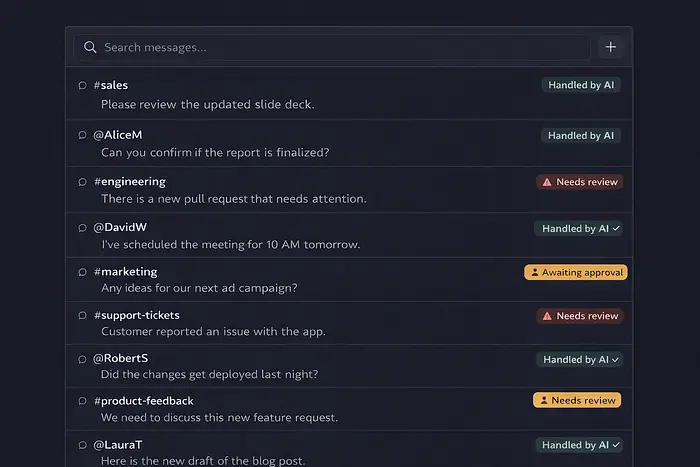
我在过去需要两小时的早晨只花了25分钟。
代理不总是对的。大约15%的输出需要返工。但那仍然比不需要我特定经验的任务少了85%的认知负荷。
根据我的经验,当开发者看到这在生产环境中工作时,他们立即开始想错误的事情——"我如何自动化更多?"更好的问题是:"什么我应该永远不自动化?"
7、你不能跳过的80/20洞察
这是我构建这个系统真正学到的。
目标不是自动化一切。而是识别不需要你的工作。
大多数人假设他们的工作大部分是复杂的。当你逐任务分解时,很大一部分是模式匹配工作——分类输入、总结文档、格式化回复、回复重复的请求类型。
AI擅长模式匹配。你在那里真的不需要。
你不可替代的地方:判断决策、创意方向、关系微妙之处、真正新颖的问题。改变输出的东西是你的特定上下文和经验。
构建你的代理来拥有模式工作。把新颖的工作留给自己。这才是真正的80/20。
从一个工作流开始,而不是一个系统。
选择那个花费你最多时间但需要最少判断的任务。为那一个任务构建代理。让它可靠地工作。然后扩展。大多数开发者因为试图在第一天就构建一个智能通才而停滞不前。正确的做法始终是先做一个专注的专家。架构可以扩展。从小处开始。
三个月前我淹没在不需要我大脑的工作中。 现在我把大部分时间花在确实需要的问题上。
构建代理。释放思考。
原文链接: I Automated 80% of My Workflow With AI
汇智网翻译整理,转载请标明出处
