我让智能体运营X账号
我们是在构建一个负责准备工作、监控你的领域、每天早上把一个队列推到你面前让你批准、编辑或取消的 Agent。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每天早上的流程大致相同。打开 Twitter。浏览一下昨晚发生了什么。找几个值得回复的推文串。起草一篇关于你最近在思考的东西的原创帖子。安排发布时间。稍后回来看看有没有人回复昨天的帖子。回复好的评论。忽略那些引战言论。
轻松的日子大约需要 45 分钟。当时间线内容有趣时,可能接近 90 分钟。
问题是,一个自主系统能否处理搜索、起草和安排发布,同时由你对发布什么保留最终决定权。我们不是在构建一个自动驾驶发推的机器人。我们是在构建一个负责准备工作、监控你的领域、每天早上把一个队列推到你面前让你批准、编辑或取消的 Agent。
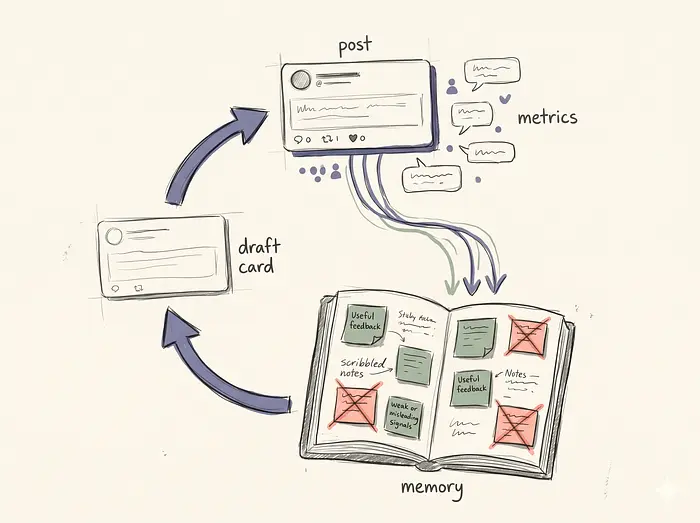
让我们看看日常循环以及数据实际如何流动。
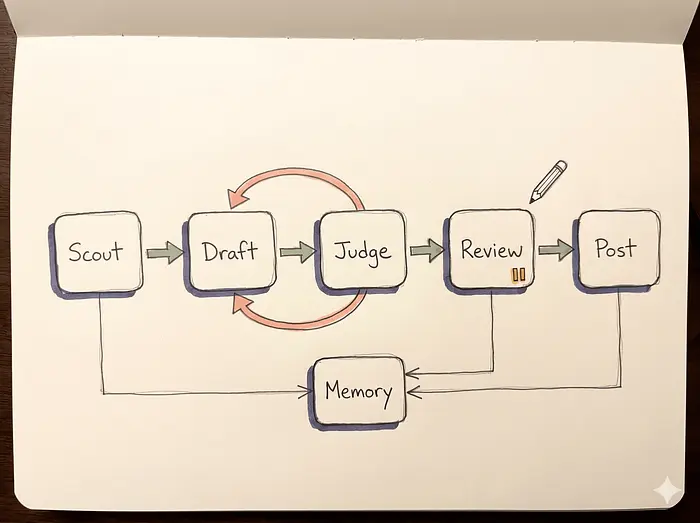
Scout 按计划运行以查找对话,并将其记录到状态内存中。起草管道接手新的机会,检查 Agent 的内存获取过去的反馈,并撰写文本。然后它对自己的工作进行通用 AI 措辞评分,必要时进行重写。幸存的草稿处于暂停执行状态。你通过一个简单的界面审查它们。执行引擎接手已批准的草稿并处理实际的 API 发布。结果和你的手动编辑反馈回内存存储。
0. 基础设施和状态管理
如果你想构建这个系统,你必须从存储层开始。你不能完全在内存中运行一个可靠的 Agent,也不能依赖传递 JSON 文件。系统需要在不同计划的运行之间维护状态,跟踪它已经处理了哪些推文,并记住你上周二为什么拒绝了一份草稿。
在 LangGraph 出现之前,系统需要四个特定的表来跟踪所有内容。有了 LangGraph,其中两个表融入了图的内部状态。以下是完整的结构,让你了解什么被替换了:
CREATE TABLE memory_log (
id INTEGER PRIMARY KEY,
feedback TEXT,
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE publish_log (
draft_id INTEGER,
tweet_id TEXT,
published_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 这两个表被 LangGraph 的 checkpointer 吸收:
CREATE TABLE scout_cache (
tweet_id TEXT PRIMARY KEY,
evaluated_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE draft_queue (
id INTEGER PRIMARY KEY,
status TEXT,
content TEXT,
target_tweet_id TEXT
);
LangGraph 通过 SqliteSaver 这样的 checkpointer 将队列吸收到自己的状态中。这允许我们将流程定义为一个编译后的图,其中队列只是图原生地暂停其执行。我们保留 memory_log 和 publish_log 表用于跨运行的长存储。
与 X API 交互需要仔细的身份验证规划。v2 API 支持 OAuth 1.0a User Context 和 OAuth 2.0 Authorization Code Flow with PKCE。OAuth 2.0 也可以,但它增加了刷新令牌的簿记工作,这对于单用户个人 Agent 来说是不必要的。你可以在开发者门户中直接为自己账户生成 Consumer Key、Consumer Secret、Access Token 和 Access Token Secret。你将这些传递给 Tweepy 库,就立即拥有代表自己进行读写访问的能力。
你需要一些凭证来使本构建中的代码正常工作。以下是运行任何内容之前应设置的 .env.example 文件:
# X API Credentials (OAuth 1.0a User Context)
X_CONSUMER_KEY="your_api_key"
X_CONSUMER_SECRET="your_api_secret"
X_ACCESS_TOKEN="your_access_token"
X_ACCESS_TOKEN_SECRET="your_access_token_secret"
X_BEARER_TOKEN="your_bearer_token_for_search"
X_USER_ID="your_numeric_twitter_id"
# Google Gemini Credentials
GOOGLE_API_KEY="your_gemini_api_key"
1. 语气学习器
我们构建的第一个模块是语气学习器。如果 Agent 写出来的东西像通用的客服代表,那就没有构建它的意义。我们必须从你过去的行为中提取你实际的写作机制。
首先,下载你的 Twitter 存档或使用 API 拉取你最近几百条推文。积极地清理这些数据。去掉转推、没有评论的链接和单词回复。你想要一个包含 50 到 100 条你实际在表达想法的推文数据集。
我们将这些推文通过 LangChain 的 Structured Outputs 喂给 Gemini 2.5 API。我们想要一个严格的 JSON 对象,我们的起草管道可以解析并以编程方式注入到其提示中。
以下是通过整个图的 AgentState,以及语气配置文件提取器。
from typing import TypedDict, Annotated, Literal
from pydantic import BaseModel, Field
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.graph.message import add_messages
import tweepy
class VoiceProfile(BaseModel):
tone: str = Field(description="dry / technical / casual / enthusiastic")
sentence_length: str = Field(description="short, medium, long")
vocabulary: str
common_phrases: list[str] = Field(description="patterns this person actually reuses")
never_uses: list[str] = Field(description="words/tones they avoid")
opening_style: str
closing_style: str
reply_style: str = Field(description="how replies differ from posts")
punctuation: str
emoji_usage: str
capitalization: str
example_tweets: list[str] = Field(description="3-5 representative real tweets")
class Draft(BaseModel):
content: str = Field(description="tweet text; threads use \\n---\\n between tweets")
content_type: Literal["post", "thread", "reply", "quote_tweet"]
target_tweet_id: str | None = None
scout_reason: str | None = None
rewrite_count: int = 0
class AgentState(TypedDict):
messages: Annotated[list, add_messages]
voice_profile: VoiceProfile
niche: str
opportunities: list[dict]
drafts: list[Draft]
current_draft: Draft | None
slop_verdict: Literal["pass", "rewrite", "kill"] | None
slop_reason: str | None
approval: Literal["approve", "edit", "reject"] | None
posted_ids: list[str]
def collect_tweets(user_id: str, bearer: str, n: int = 200) -> list[str]:
client = tweepy.Client(bearer_token=bearer)
out = []
for page in tweepy.Paginator(
client.get_users_tweets,
id=user_id,
max_results=100,
exclude=["retweets"],
):
if not page.data:
break
out.extend(t.text for t in page.data if len(t.text) > 30)
if len(out) >= n:
break
return out[:n]
def build_voice_profile(tweets: list[str]) -> VoiceProfile:
llm = ChatGoogleGenerativeAI(model="gemini-2.5-pro", temperature=0.3)
extractor = llm.with_structured_output(VoiceProfile)
sample = "\n---\n".join(tweets[:100])
return extractor.invoke([
{
"role": "system",
"content": (
"You are a voice analyst. Extract a detailed voice profile from real "
"tweets. Be concrete — avoid vague descriptors like 'professional'. "
"Focus on what makes this person's writing recognizably theirs."
),
},
{"role": "user", "content": f"Tweets:\n\n{sample}"},
])
AgentState TypedDict 是整个图的脊柱。每个节点都从中读取和写入。add_messages reducer 追加到消息列表而不是覆盖它,这在图开始循环时很重要。
with_structured_output(VoiceProfile) 方法在 Gemini、Claude 和 OpenAI 上的工作方式完全相同。

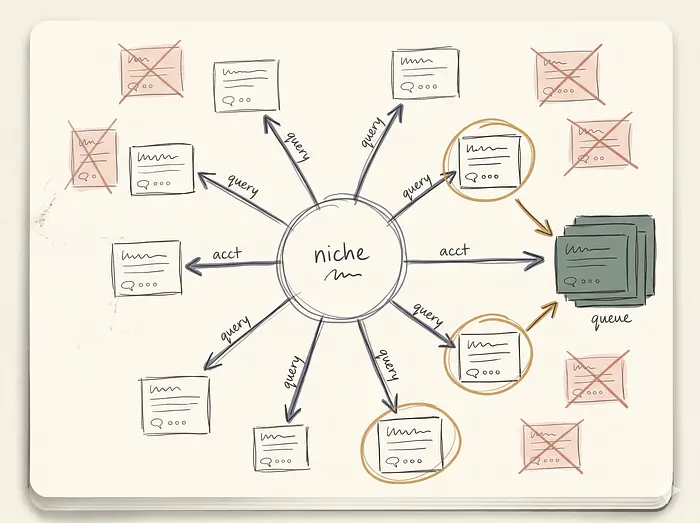
2. 作为 ReAct 子 Agent 的领域 Scout
Agent 需要知道你的互联网角落正在发生什么。由于 API 读取限制,scout 严重依赖于精选的目标账户列表和高度具体的关键词搜索。
scout 不是一个硬编码的搜索循环,而是一个带有两个 X API 工具的 ReAct agent。LLM 从领域描述中选择自己的查询。它可能运行一次搜索,查看结果,然后运行更窄的搜索。文档字符串就是合约。它们是模型在决定调用哪个工具时读取的内容。
from langchain_core.tools import tool
from langgraph.prebuilt import create_react_agent
from langchain_google_genai import ChatGoogleGenerativeAI
from pydantic import BaseModel, Field
import tweepy
import os
def _get_x_client():
bearer = os.environ.get("X_BEARER_TOKEN")
if not bearer:
raise ValueError("X_BEARER_TOKEN missing from environment")
return tweepy.Client(bearer_token=bearer)
@tool
def search_tweets(query: str, max_results: int = 20) -> list[dict]:
"""Search recent tweets (last 7 days) matching a keyword or phrase.
Returns tweets with engagement metrics. Use targeted niche queries —
broad terms like 'AI' return noise.
"""
_x = _get_x_client()
resp = _x.search_recent_tweets(
query=f"{query} -is:retweet lang:en",
max_results=max_results,
tweet_fields=["public_metrics", "created_at", "author_id"],
expansions=["author_id"],
user_fields=["username"],
)
if not resp.data:
return []
users = {u.id: u.username for u in (resp.includes.get("users") or [])}
return [
{
"id": str(t.id),
"text": t.text,
"author": users.get(t.author_id, "unknown"),
"likes": t.public_metrics.get("like_count", 0),
"replies": t.public_metrics.get("reply_count", 0),
"retweets": t.public_metrics.get("retweet_count", 0),
}
for t in resp.data
]
@tool
def get_account_tweets(username: str, max_results: int = 10) -> list[dict]:
"""Get recent tweets from a specific account. Use for followed experts."""
_x = _get_x_client()
user = _x.get_user(username=username).data
if not user:
return []
resp = _x.get_users_tweets(
id=user.id,
max_results=max_results,
tweet_fields=["public_metrics", "created_at"],
)
return [
{"id": str(t.id), "text": t.text, "author": username,
**(t.public_metrics or {})}
for t in (resp.data or [])
]
class Opportunity(BaseModel):
tweet_id: str
text: str
author: str
relevance: float = Field(description="0.0 to 1.0")
action: Literal["reply", "quote_tweet", "note_for_later"]
reason: str
class ScoutReport(BaseModel):
opportunities: list[Opportunity]
trending_topics: list[str]
SCOUT_PROMPT = """You are a niche scout for a Twitter account focused on: {niche}
Your job:
1. Use search_tweets with 3-5 targeted queries in this niche
2. Optionally use get_account_tweets for key accounts in this space
3. Identify the 5-10 tweets with the best engagement opportunity
4. Identify 3-5 trending topics worth writing an original post about
Rank by: active conversation > reach > raw likes. A tweet with 50 replies
beats one with 500 likes and no replies.
When done, return your final report in the exact ScoutReport schema."""
def run_scout(niche: str) -> ScoutReport:
llm = ChatGoogleGenerativeAI(model="gemini-2.5-pro", temperature=0.4)
agent = create_react_agent(
model=llm,
tools=[search_tweets, get_account_tweets],
response_format=ScoutReport,
)
result = agent.invoke({
"messages": [{"role": "user", "content": SCOUT_PROMPT.format(niche=niche)}]
})
return result["structured_response"]
create_react_agent 函数原生处理推理和工具使用循环。在此函数中使用 response_format 在 LangGraph 0.2 及更新版本中可用,保证 Agent 一次性返回工具调用和最终的类型化对象。scout 是一个子 Agent,我们将它包装为主图中的单个节点。
3. 带语气约束的生成器节点
起草管道是撰写文本的地方。它作为图中的一个节点运行,读取状态,将语气配置文件作为硬约束调用 LLM,并将结果写回。
以编程方式撰写好的社交内容需要提示链。我们强制模型从不同角度出发,并严格应用语气约束。我们还查询本地 SQLite 数据库以获取最近的拒绝原因,将它们注入到提示中,以便 Agent 从完全不同运行中的过去错误中学习。
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.types import Command
import sqlite3
import os
GHOST_PROMPT = """You ghostwrite Twitter content for one person in their exact voice.
Not a cleaned-up version. Their actual voice.
Voice profile:
{profile}
Rules:
- Never use phrases from `never_uses`
- Match sentence length, punctuation, and tone exactly
- Replies must add something specific — no "great point" or "love this"
- Threads: hook that earns the scroll, body tweets (one idea each), closer
- Do not hedge. Do not water down opinions.
- For threads, separate tweets with \\n---\\n
Previous rewrite feedback (if any): {rewrite_reason}
Target: {target}"""
def generator_node(state: AgentState) -> Command:
"""Generate a draft. Chooses opportunity from scout or picks a trending topic."""
llm = ChatGoogleGenerativeAI(model="gemini-2.5-pro", temperature=0.8)
writer = llm.with_structured_output(Draft)
previous = state.get("current_draft")
rewrite_count = (previous.rewrite_count + 1) if previous else 0
rewrite_reason = state.get("slop_reason", "none — fresh draft")
# Cross-run learning: fetch past rejections from SQLite
db_path = os.environ.get("DB_PATH", "agent_state.db")
try:
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("SELECT feedback FROM memory_log ORDER BY created_at DESC LIMIT 5")
recent_feedback = [row[0] for row in cursor.fetchall()]
conn.close()
if recent_feedback:
rewrite_reason += "\n\nPast feedback to avoid:\n" + "\n".join(f"- {f}" for f in recent_feedback)
except sqlite3.OperationalError:
pass
if previous and state.get("slop_verdict") == "rewrite":
target = (
f"Rewrite this draft, keeping the same topic but fixing the voice.\n\n"
f"Previous draft:\n{previous.content}\n\n"
f"Content type: {previous.content_type}"
)
draft_type = previous.content_type
target_id = previous.target_tweet_id
else:
opp = state["opportunities"][0] if state["opportunities"] else None
if opp and opp.get("action") == "reply":
target = f"Write a reply to @{opp['author']}:\n\n{opp['text']}"
draft_type, target_id = "reply", opp["tweet_id"]
elif opp and opp.get("action") == "quote_tweet":
target = f"Write a quote tweet for @{opp['author']}:\n\n{opp['text']}"
draft_type, target_id = "quote_tweet", opp["tweet_id"]
else:
topic = state["opportunities"][0]["reason"] if opp else "your niche"
target = f"Write an original post about: {topic}"
draft_type, target_id = "post", None
draft = writer.invoke([
{
"role": "system",
"content": GHOST_PROMPT.format(
profile=state["voice_profile"].model_dump_json(indent=2),
rewrite_reason=rewrite_reason,
target=target,
),
}
])
# We define content_type as required in the Draft schema so the LLM satisfies Pydantic,
# but we explicitly overwrite it here to guarantee the routing logic matches the context.
draft.content_type = draft_type
draft.target_tweet_id = target_id
draft.rewrite_count = rewrite_count
draft.scout_reason = (state["opportunities"][0].get("reason")
if state["opportunities"] else None)
remaining_opps = state["opportunities"][1:] if state["opportunities"] else []
return Command(
update={
"current_draft": draft,
"opportunities": remaining_opps,
"slop_verdict": None,
"slop_reason": None
},
goto="slop_gate",
)
Command 返回值明确规定了如何更新状态以及下一步去哪里。我们将已消费的机会从状态列表中弹出,这样生成器的下一次迭代就会转向新话题。rewrite_count 字段充当断路器。下一个节点使用它在失败次数过多时终止草稿,防止无限生成循环。
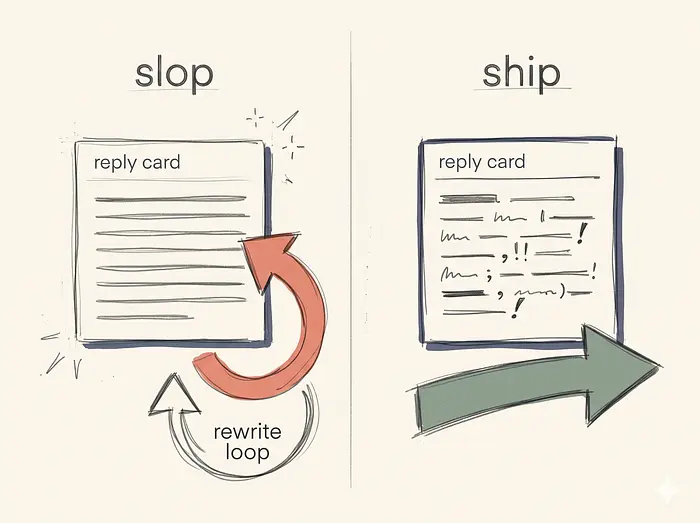
4. 带条件路由的 Slop Gate
在生成之后,管道立即运行反 slop 检查。我们将生成的草稿传递给一个充当编辑器的独立 LLM 调用。
该节点使用一个便宜、快速的模型来产生判定,然后返回一个 Command,路由到三个目的地之一:批准队列、返回生成器进行重写,或直接到图的末端。如果基本的正则表达式捕获到禁用短语,我们会完全跳过 LLM 调用,直接将其退回重写,以节省时间和 API 成本。
from langchain_google_genai import ChatGoogleGenerativeAI
from langgraph.types import Command
from pydantic import BaseModel, Field
from typing import Literal
SLOP_MARKERS = [
"Here's the thing", "It's worth noting", "Let's dive in",
"game-changer", "I'm excited to share", "Unpopular opinion:",
"Let that sink in", "I'll go first", "A thread on", "game changer",
]
MAX_REWRITES = 2
class SlopVerdict(BaseModel):
verdict: Literal["pass", "rewrite", "kill"]
authenticity: float = Field(description="0.0 = slop, 1.0 = authentic")
flags: list[str]
reason: str
def slop_gate_node(state: AgentState) -> Command:
draft = state["current_draft"]
# Short-circuit on obvious slop
regex_hits = [m for m in SLOP_MARKERS if m.lower() in draft.content.lower()]
if regex_hits:
if draft.rewrite_count < MAX_REWRITES:
return Command(
update={"slop_verdict": "rewrite", "slop_reason": f"Used banned phrases: {regex_hits}"},
goto="generator",
)
return Command(
update={"slop_verdict": "kill", "slop_reason": "Failed regex too many times"},
goto="__end__",
)
llm = ChatGoogleGenerativeAI(model="gemini-2.5-flash", temperature=0.0)
judge = llm.with_structured_output(SlopVerdict)
verdict: SlopVerdict = judge.invoke([
{
"role": "system",
"content": (
"You are an anti-slop filter. Detect text that sounds AI-generated "
"or like generic social media content instead of this specific person.\n\n"
"Flag: generic motivational phrasing, essay-like sentences, hedging "
"('arguably', 'some might say'), corporate-helpful tone, wrong emoji "
"patterns, words this person never uses.\n\n"
f"Voice profile:\n{state['voice_profile'].model_dump_json()}\n\n"
"pass = ship it. rewrite = voice off but salvageable. kill = generic slop."
),
},
{"role": "user", "content": f"Draft:\n\n{draft.content}"},
])
if verdict.verdict == "pass":
return Command(
update={"slop_verdict": "pass", "slop_reason": verdict.reason},
goto="approval",
)
if verdict.verdict == "rewrite" and draft.rewrite_count < MAX_REWRITES:
return Command(
update={"slop_verdict": "rewrite", "slop_reason": verdict.reason},
goto="generator",
)
return Command(
update={"slop_verdict": "kill", "slop_reason": verdict.reason},
goto="__end__",
)
使用 gemini-2.5-flash 进行过滤,同时 gemini-2.5-pro 处理生成,有效地分配了工作负载。如果草稿两次失败,goto="__end__" 命令会完全终止图的这个分支。kill 判定会被记录,但不会发布任何内容,系统安全退出。
5. 通过 interrupt() 实现的批准队列
管道已经完成了繁重的工作。它找到了对话,应用了你的语气,并过滤掉了 slop。现在系统暂停了。
interrupt() 函数在此特定节点暂停图,通过 checkpointer 持久化完整状态,并将草稿呈现给人类用户。当你恢复图时,执行从确切的这一行继续。我们还将拒绝路径直接连接到 SQLite 数据库,以便生成器明天能从你的编辑中学习。
from langgraph.types import Command, interrupt
import sqlite3
import os
def approval_node(state: AgentState) -> Command:
draft = state["current_draft"]
human_response = interrupt({
"action_required": "review_draft",
"content": draft.content,
"type": draft.content_type,
"target_tweet_id": draft.target_tweet_id,
"scout_reason": draft.scout_reason,
"slop_reason": state.get("slop_reason"),
"rewrite_count": draft.rewrite_count,
"options": ["approve", "edit", "reject"],
})
action = human_response.get("action")
if action == "approve":
return Command(update={"approval": "approve"}, goto="poster")
if action == "edit":
draft.content = human_response.get("edited_content", draft.content)
return Command(
update={"approval": "edit", "current_draft": draft},
goto="poster",
)
# Log the rejection to SQLite for cross-run learning
reason = human_response.get("reason", "human rejected")
db_path = os.environ.get("DB_PATH", "agent_state.db")
try:
conn = sqlite3.connect(db_path)
conn.cursor().execute(
"CREATE TABLE IF NOT EXISTS memory_log (id INTEGER PRIMARY KEY, feedback TEXT, created_at DATETIME DEFAULT CURRENT_TIMESTAMP)"
)
conn.cursor().execute("INSERT INTO memory_log (feedback) VALUES (?)", (reason,))
conn.commit()
conn.close()
except sqlite3.Error as e:
print(f"Failed to log memory: {e}")
return Command(
update={
"approval": "reject",
"slop_reason": reason,
},
goto="__end__",
)
checkpointer 使中断能够经受进程重启,所以在早晨喝咖啡时审查一批草稿是一个原生功能,而不是你必须从头构建的队列系统。
以下是你如何从一个简单脚本中实际审查和恢复执行:
from langgraph.checkpoint.memory import MemorySaver
graph = build_graph(checkpointer=MemorySaver())
config = {"configurable": {"thread_id": "morning-batch-2026-04-16"}}
result = graph.invoke(initial_state, config=config)
if "__interrupt__" in result:
payload = result["__interrupt__"][0].value
print(f"Review this {payload['type']}:\n\n{payload['content']}\n")
print(f"Scout reason: {payload['scout_reason']}")
choice = input("approve / edit / reject: ").strip()
if choice == "edit":
new_text = input("New content: ")
human = {"action": "edit", "edited_content": new_text}
elif choice == "reject":
human = {"action": "reject", "reason": input("Why? ")}
else:
human = {"action": "approve"}
final = graph.invoke(Command(resume=human), config=config)
print(f"Post
6. 连接完整图和发布
最后一个活跃组件是执行引擎。它处理草稿批准后的 API 发布。
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
import tweepy
import time
import random
import os
def _user_client() -> tweepy.Client:
return tweepy.Client(
consumer_key=os.environ["X_CONSUMER_KEY"],
consumer_secret=os.environ["X_CONSUMER_SECRET"],
access_token=os.environ["X_ACCESS_TOKEN"],
access_token_secret=os.environ["X_ACCESS_TOKEN_SECRET"],
)
def poster_node(state: AgentState) -> dict:
draft = state["current_draft"]
x = _user_client()
posted: list[str] = []
def _post(**kwargs) -> str:
try:
resp = x.create_tweet(**kwargs)
return str(resp.data["id"])
except tweepy.errors.TooManyRequests:
print("Rate limit hit. Exiting poster safely.")
raise
except Exception as e:
print(f"API Error: {e}")
raise
if draft.content_type == "thread":
parts = draft.content.split("\n---\n")
last_id = _post(text=parts[0])
posted.append(last_id)
for body in parts[1:]:
time.sleep(random.uniform(30, 120))
last_id = _post(text=body, in_reply_to_tweet_id=last_id)
posted.append(last_id)
elif draft.content_type == "reply":
posted.append(_post(text=draft.content,
in_reply_to_tweet_id=draft.target_tweet_id))
elif draft.content_type == "quote_tweet":
posted.append(_post(text=draft.content,
quote_tweet_id=draft.target_tweet_id))
elif draft.content_type == "post":
posted.append(_post(text=draft.content))
else:
raise ValueError(f"Unknown content type: {draft.content_type}")
return {"posted_ids": posted}
def scout_node(state: AgentState) -> dict:
report = run_scout(state["niche"])
return {"opportunities": [o.model_dump() for o in report.opportunities]}
def build_graph(checkpointer=None):
g = StateGraph(AgentState)
g.add_node("scout", scout_node)
g.add_node("generator", generator_node)
g.add_node("slop_gate", slop_gate_node)
g.add_node("approval", approval_node)
g.add_node("poster", poster_node)
g.add_edge(START, "scout")
g.add_edge("scout", "generator")
g.add_edge("poster", END)
# generator, slop_gate, approval all use Command(goto=...) for routing
return g.compile(checkpointer=checkpointer or MemorySaver())
if __name__ == "__main__":
profile = build_voice_profile(
collect_tweets(os.environ["X_USER_ID"], os.environ["X_BEARER_TOKEN"])
)
graph = build_graph()
config = {"configurable": {"thread_id": "daily-run"}}
state = graph.invoke(
{
"messages": [],
"voice_profile": profile,
"niche": "AI engineering, agents, RAG, developer tools",
"opportunities": [],
"drafts": [],
"current_draft": None,
"slop_verdict": None,
"slop_reason": None,
"approval": None,
"posted_ids": [],
},
config=config,
)
整个图中只有三条静态边。其他所有转换都是由节点内部动态驱动的。
推文串中推文之间的节奏是一个重要的反机器人措施。在 100 毫秒内发出五个 API 调用会让你的账户被标记。推文之间 30 到 120 秒的随机延迟看起来更像人类。try/except 块专门捕获 TooManyRequests 以优雅地处理 429 状态码。
7. 性能跟踪器和反馈循环
一个 Agent 只有在能够适应时才有用。我们已经介绍了手动拒绝如何通过批准节点更新内存日志,但 Agent 还应该从时间线上实际表现良好的内容中学习。
因为跟踪与发布运行在不同的时间框架上,我们将其作为单独的计划作业而不是图节点来运行。它查询本地 publish_log 数据库,从 X 获取当前指标,并将摘要写回 memory_log 表,以便起草管道明天可以读取。
import sqlite3
import tweepy
import os
def track_performance(db_path: str):
client = tweepy.Client(bearer_token=os.environ["X_BEARER_TOKEN"])
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# Fetch tweets published in the last 48 hours
cursor.execute("""
SELECT tweet_id FROM publish_log
WHERE published_at >= datetime('now', '-2 days')
""")
recent_ids = [row[0] for row in cursor.fetchall()]
if not recent_ids:
return
response = client.get_tweets(
ids=recent_ids[:100],
tweet_fields=["public_metrics", "text"]
)
for tweet in response.data or []:
metrics = tweet.public_metrics
if metrics['reply_count'] > 5 or metrics['like_count'] > 20:
insight = f"High engagement on topic: {tweet.text[:50]}... (Replies: {metrics['reply_count']})"
cursor.execute(
"INSERT INTO memory_log (feedback) VALUES (?)",
(insight,)
)
conn.commit()
conn.close()
如果某个特定的回复格式持续获得零互动,跟踪器会记录一条建议,提示管道尝试不同的方法。如果某个话题可靠地触发高互动,跟踪器会将该洞察插入内存。生成器在启动时读取此表,根据冷指标调整其行为。
8. 可能出什么问题
当你将一个自主系统附加到你个人声誉上时,你必须为失败做好设计。
语气漂移是一个真正的问题。随着时间的推移,Agent 生成的语气可能会偏离你实际的写作风格。如果你偷懒开始批准稍微偏离的草稿只是为了让队列继续前进,反馈循环会学习到这种修改后的风格是可接受的。Agent 慢慢变成你的讽刺漫画。解决方法是每隔几个月清除一次语气配置文件,并在你最新手写的推文上重新运行提取提示。
互动 farming 是另一个风险。Agent 正在优化你告诉它关心的指标。如果一个高度争议的话题获得了很多回复,性能跟踪器可能会告诉 scout 寻找更多争议。你必须在批准队列中主动拒绝廉价的互动诱饵,明确记录原因,以便 Agent 学会避免这种行为。
你还必须精确处理 API 限制。如果你的 Agent 失控并尝试在一小时内回复 200 条推文,你的开发者应用将被暂停。你必须优雅地处理 429 HTTP 状态码。当 Tweepy 抛出速率限制异常时,你的代码应该捕获它并简单地退出脚本,以便它可以在下一次计划运行时重试。
9. 第一版构建路径
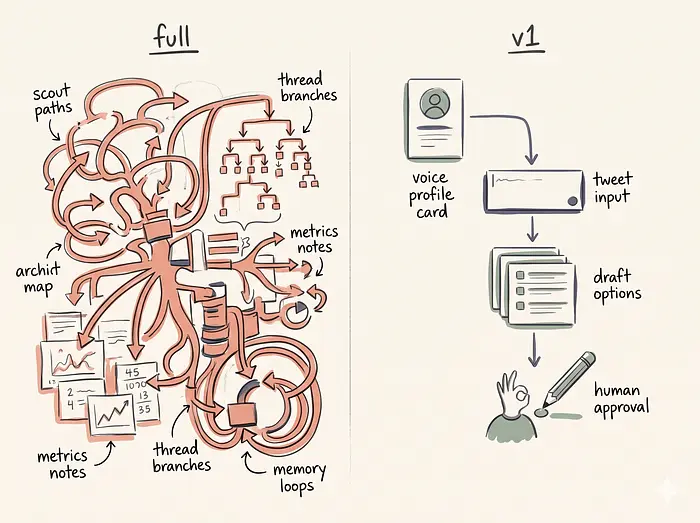
如果你正在看着这个架构并对这么多组件感到不知所措,你需要限制第一版本的范围。不要试图同时构建领域 scout、推文串生成器和性能跟踪器。
最小可行构建只是语气学习器、一个简单的起草管道和批准队列。
首先提取你的语气配置文件并将其保存为文本文件。编写一个 Python 脚本,接收你想要回复的推文的单个 URL。脚本获取推文上下文,将其与你的语气配置文件一起传递给 LLM,并在终端打印三个草稿选项。你选择一个,复制到剪贴板,然后自己粘贴到 Twitter 中。
仅这一项就是一个非常有用的工具。它解决了空白页问题,每天为你节省二十分钟。一旦核心生成循环感觉可靠并且文本听起来确实像你,你可以添加 SQLite 数据库来跟踪状态。然后添加 Tweepy 执行引擎来处理发布。最后,构建 scout 来自动化发现阶段。
构建这个 Agent 并不意味着你停止在互联网上发帖。它意味着你停止做在线的重复性管理工作。你把时间花在阅读上下文和做出编辑决策上,而代码处理轮询、打字和计时。你构建系统,但保留判断力。
原文链接: Building an AI Agent That Runs My Twitter Account
汇智网翻译整理,转载请标明出处
