智能体间通信实践指南
我经常碰壁。然后我发现了一些改变了我如何思考使用 AI 构建的想法:与其让一个智能体变得更聪明,不如把工作分配给多个智能体,让它们相互交流。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
每个雄心勃勃的 AI 项目都会遇到这样的时刻:你碰壁了。你有一个强大的语言模型,你让它做一些复杂的事情——也许从三十个不同角度研究一个主题,或者从头开始构建整个营销活动——但它就是……无法把所有东西整合在一起。上下文变得太大。任务太分散。输出太泛泛。
我经常碰壁。然后我发现了一些改变了我如何思考使用 AI 构建的想法:与其让一个智能体变得更聪明,不如把工作分配给多个智能体,让它们相互交流。
这就是智能体到智能体(A2A)通信。这是目前 AI 领域最令人兴奋——也是诚实地解释得最少的想法之一。
让我们来分解一下。
1、什么是"智能体"?
在我们讨论智能体通信之前,让我们先对什么是智能体达成共识。
把 AI 智能体想象成一个不仅仅是回答问题的 AI——它采取行动。它可以调用工具、浏览网页、编写代码、读取文件,最重要的是,根据它发现的内容决定下一步做什么。智能体有目标、一组工具,以及如何实现该目标的一定自主权。
单个智能体已经令人印象深刻。但是一个智能体网络——每个都有专门的角色,来回传递信息——才是真正强大的地方。
2、核心思想:协调器和子智能体
大多数多智能体系统都是围绕一个简单的层次结构构建的:
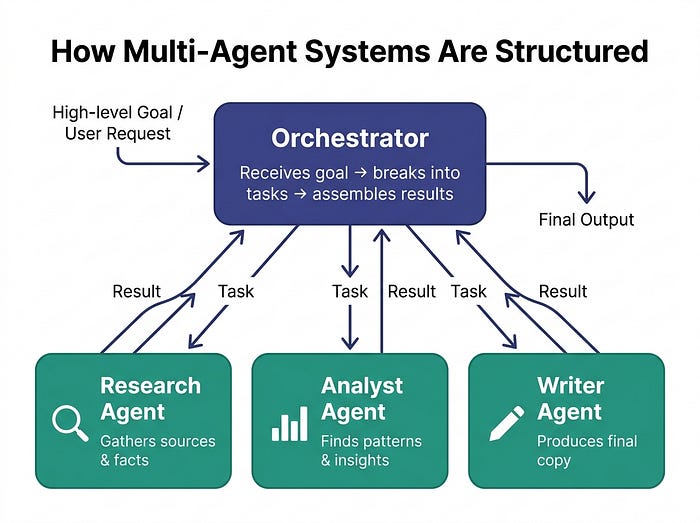
协调器 是协调者。它接收高级目标,将其分解为子任务,将这些任务分配给专门的智能体,然后将所有内容综合成最终结果。
子智能体 是专家。每个都经过优化(通过其系统提示、工具和指令)来做好一件事。研究员。写作者。事实核查员。程序员。
它们之间的通信可以通过几种方式发生:
- 顺序: 智能体 A 完成,将输出传递给智能体 B,B 再传递给智能体 C
- 并行: 多个智能体同时运行,结果被合并
- 反馈循环: 智能体 B 可以将结果发回给智能体 A 进行改进
3、一个真实的例子: 研究流程
假设你想要一份关于"AI 对制药行业影响"的深度研究报告。单个智能体会很吃力——主题太广、来源太多.你可能会得到表面的答案。
这是多智能体系统处理它的方式:
import anthropic
client = anthropic.Anthropic()
# --- 子智能体 1: 研究收集者 ---
def research_agent(topic: str) -> str:
"""搜索并收集关于某个主题的原始信息。"""
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
system="""你是一个研究专家。你的工作是识别
任何给定主题的最重要的主要事实、趋势、统计数据和专家观点。
要彻底。要具体。尽可能引用来源。""",
messages=[
{"role": "user", "content": f"深入研究以下主题: {topic}"}
]
)
return response.content[0].text
# --- 子智能体 2: 分析师 ---
def analyst_agent(raw_research: str) -> str:
"""从原始研究中识别关键洞察和模式。"""
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system="""你是一个分析思考者。给定原始研究,
你的工作是提取 3-5 个最重要的洞察,
识别模式,标记任何矛盾或开放问题。""",
messages=[
{"role": "user", "content": f"分析这项研究并提取关键洞察:\n\n{raw_research}"}
]
)
return response.content[0].text
# --- 子智能体 3: 写作者 ---
def writer_agent(insights: str, topic: str) -> str:
"""将结构化洞察转化为写得好的报告。"""
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
system="""你是一个专业写作者,将分析洞察
转化为清晰、引人入胜的报告。为智能但非专业的
受众写作。使用具体例子。避免行话。""",
messages=[
{"role": "user", "content": f"基于这些洞察写一份关于'{topic}' 的简明报告:\n\n{insights}"}
]
)
return response.content[0].text
# --- 协调器: 将所有内容整合在一起 ---
def research_orchestrator(topic: str) -> str:
print(f"[协调器] 启动关于 {topic} 的研究流程")
print("[协调器] 分派给研究智能体...")
raw_research = research_agent(topic)
print("[协调器] 分派给分析师智能体...")
key_insights = analyst_agent(raw_research)
print("[协调器] 分派给写作智能体...")
final_report = writer_agent(key_insights, topic)
return final_report
# 运行
report = research_orchestrator("AI 对制药药物发现的影响")
print(report)
每个智能体专注于一项工作。协调器将它们粘合在一起。最终输出比任何单个智能体产生的结果都要好得多——因为每一步都在上一步的基础上全神贯注地构建。
4、另一个例子: 营销内容流程
现在让我们看一个营销用例。假设你的团队需要推出一个产品,并制作定位声明、三条社交媒体帖子、邮件主题行和博客标题——所有内容在语调和信息上保持一致。
def marketing_pipeline(product_name: str, product_description: str) -> dict:
# 步骤 1: 策略师智能体定义定位
strategy_response = client.messages.create(
model="claude-opus-4-6",
max_tokens=512,
system="""你是一位资深营销策略师。
为产品定义清晰、引人入胜的价值主张。
输出: 一个 2 句话的定位声明。""",
messages=[{"role": "user", "content": f"产品: {product_name}\n描述: {product_description}"}]
)
positioning = strategy_response.content[0].text
# 步骤 2: 社交媒体智能体使用该定位
social_response = client.messages.create(
model="claude-opus-4-6",
max_tokens=512,
system="""你是一个社交媒体文案撰写者。
基于品牌定位编写 3 条简短有力的社交帖子(Twitter/LinkedIn 风格)
每个帖子应该在角度上各不相同。""",
messages=[{"role": "user", "content": f"定位: {positioning}\n产品: {product_name}"}]
)
social_posts = social_response.content[0].text
# 步骤 3: 邮件智能体制作主题行
email_response = client.messages.create(
model="claude-opus-4-6",
max_tokens=256,
system="""你是一位以高打开率著称的邮件营销专家。
编写 3 个引人入胜的邮件主题行选项。要具体,不要泛泛。""",
messages=[{"role": "user", "content": f"定位: {positioning}\n产品: {product_name}"}]
)
email_subjects = email_response.content[0].text
return {
"positioning": positioning,
"social_posts": social_posts,
"email_subjects": email_subjects
}
result = marketing_pipeline(
product_name="FlowDesk",
product_description="一个 AI 驱动的收件箱,按紧急程度对邮件进行优先级排序并自动起草回复。"
)
for key, value in result.items():
print(f"\n--- {key.upper()} ---\n{value}")
这里的魔法是上下文传播——步骤 1 中定义的定位流向步骤 2 和 3,保持一切一致。不需要为每段内容重新设计提示词。
5、更进一步: 智能体回话
上面的例子是线性流程。但真正的多智能体系统通常涉及反馈循环——一个智能体可以挑战或改进另一个的输出。
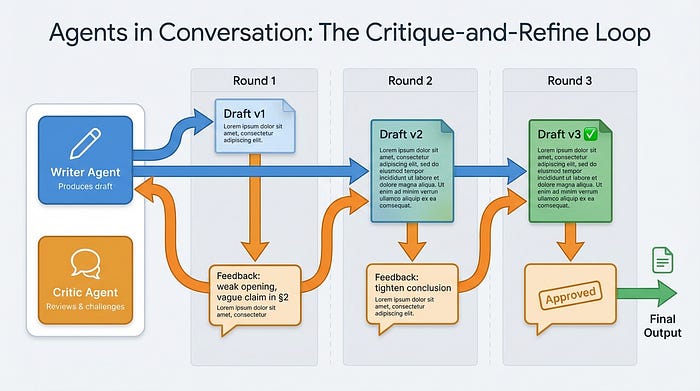
def critique_and_refine(draft: str, task_context: str) -> str:
"""批评智能体审查草稿并发送反馈以供修改。"""
# 批评者审查草稿
critique = client.messages.create(
model="claude-opus-4-6",
max_tokens=512,
system="""你是一个敏锐、建设性的批评家。
你的工作是识别任何写作中的弱点:
逻辑漏洞。模糊的声明。遗漏的角度。薄弱的开头。
要具体。要诚实。建议具体的改进。""",
messages=[{"role": "user", "content": f"上下文: {task_context}\n\n待审查的草稿:\n{draft}"}]
)
feedback = critique.content[0].text
# 原作者根据批评进行修改
revised = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system="""你是一个熟练的写作者。
根据收到的反馈修改你的草稿。
改进它但不要失去你的声音。""",
messages=[
{"role": "user", "content": f"原始草稿:\n{draft}\n\n收到的反馈:\n{feedback}\n\n请修改。"}
]
)
return revised.content[0].text
这本质上是两个智能体在对话——一个写作者和一个批评家——迭代向更好的结果。你可以扩展这个来运行多轮。
6、今天可能做到什么
以下是多智能体系统现在真正能做好的事情:
并行研究和综合。 与其一个智能体费力地一次搜索一个主题,多个智能体可以同时研究不同的子主题,然后一个综合智能体将所有内容整合。顺序需要 10 分钟的事情并行只需要 2 分钟。
角色专业化. 法律审查智能体、语调检查智能体和事实准确性智能体可以各自通过自己的视角评估内容——这是单个通用智能体做不好的,因为它在分散注意力。
长视野任务. 太长无法放入一个上下文窗口的任务可以被分块和分发。每个智能体处理一个切片;协调器组装整体。
质量关卡. 你可以在流程中构建审查智能体——其全部工作是在任何内容到达人类之前捕获错误、不一致或偏离品牌语言的内容。
动态路由. 协调器可以检查传入的任务并决定将其路由到哪个专门智能体,而不是每次都运行所有内容。
7、还不可能做到什么(目前)
诚实很重要,因为围绕多智能体 AI 的炒作是真实的。
真正的跨智能体持久记忆很难. 大多数智能体默认是无状态的。如果智能体 B 需要"记住"智能体 A 在三个任务前发现的内容,你必须明确管理和传递该上下文。没有自动的共享内存。
可靠性随复杂性下降. 智能体之间的每一次跳转都是出错的机会——智能体误解指令、产生意外格式或偏离轨道。长链智能体可能以难以调试的方式失败。
成本快速累积. 每个智能体调用都消耗 token。一个使用大模型的 5-6 个智能体的流程对于简单任务来说可能很昂贵。真正需要工程工作来决定哪些智能体需要大模型,哪些可以使用较小的模型。
协调仍然是手动的. 目前还没有智能体自发自我组织的魔法协议。协调逻辑——谁与谁对话、以什么顺序、使用什么数据——仍然是你编写的代码。
循环依赖和无限循环. 如果智能体 A 等待智能体 B,而智能体 B 等待智能体 A,你就有了死锁。构建适当的超时和回退逻辑是必要的,但经常被忽视。
8、为什么这实际上很重要
这里是真正的价值主张,比你想象的更简单:多智能体系统让你在适当的规模将适当的智能应用于适当的问题。
一个试图同时成为研究员、分析师、作家、批评家和格式化者的单个 AI 就像让一个人成为你整个公司。他们在每件事上都做得还行,但没有一件事做得好。
当你给每个角色自己的智能体——自己的系统提示、自己的工具、自己的关注点——你得到的输出实际上感觉像是专家制作的。因为在某种意义上,它确实是。
做这个的框架正在快速改进。像 LangGraph、CrewAI、AutoGen 和 Anthropic 自己的智能体构建 SDK 这样的工具正在使组合这些系统变得更容易,而无需从头开始编写所有内容。过去需要数周工程时间的事情开始只需要数天。
9、思考你的用例的框架
在构建多智能体系统之前,问自己这三个问题:
1. 任务真的是多步骤的吗? 如果你可以用一个好的提示词和单个智能体解决它,那就这样做。复杂性是有代价的。
2. 子任务需要不同的专业知识或关注点吗? 研究 + 分析 + 写作受益于分离。格式化表格则不需要。
3. 步骤可以并行运行吗? 如果是,多智能体将为你节省大量时间。如果一切都是严格顺序的,好处较小。
如果你对至少两个问题回答是,你可能有一个好的多智能体用例。
10、这一切的发展方向
我们仍处于这个故事的早期章节。现在,多智能体系统需要刻意的工程设计。你设计层次结构、编写系统提示、定义通信流程。
但发展方向是朝着智能体可以相互发现、协商任务并在较少人工脚手架的情况下自我组织的系统发展。 Google 的智能体到智能体(A2A)协议、Anthropic 的模型上下文协议(MCP)以及围绕智能体身份和信任的新兴标准都指向一个未来,AI 智能体网络像微服务一样易于组合。
我们还没有到那一步。但构建块今天已经存在。现在学会良好编排 AI 智能体的团队将在这些系统变得商品化时拥有有意义的先发优势。
单一、包罗万象的 AI 时代正在让位于更有趣的东西:一个协同工作的专门智能协作网络。
老实说?这是其中最人性化的部分。
如果你觉得这有用或对构建自己的多智能体系统有疑问,我很想听听你的意见。这个领域发展很快,现在最好的想法来自正在构建的人。
原文链接:
汇智网翻译整理,转载请标明出处
