jina-grep:理解自然语言的grep
jina-grep利用了 LLM 在 CLI 使用中的当前优势,同时避免了向量数据库的臃肿:它为传统文本搜索工具提供了理解自然语言的能力。

AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
Jina AI 刚刚开源了 jina-grep,这是一个命令行工具,可以直接在 Apple Silicon 上通过 MLX 运行语义搜索。该项目利用了 LLM 在 CLI 使用中的当前优势,同时避免了向量数据库的臃肿:它为传统文本搜索工具提供了理解自然语言的能力。
1、三种工作模式
jina-grep 提供三种使用模式:
1) 管道模式:语义重新排序 grep 输出
grep -rn "error" src/ | jina-grep "error handling logic"
2) 独立模式:使用自然语言直接搜索文件
jina-grep "memory leak" src/
3) 零样本分类:为每一行文本分配最匹配的标签
jina-grep -e "database" -e "error handling" -e "data processing" src/
2、性能指标
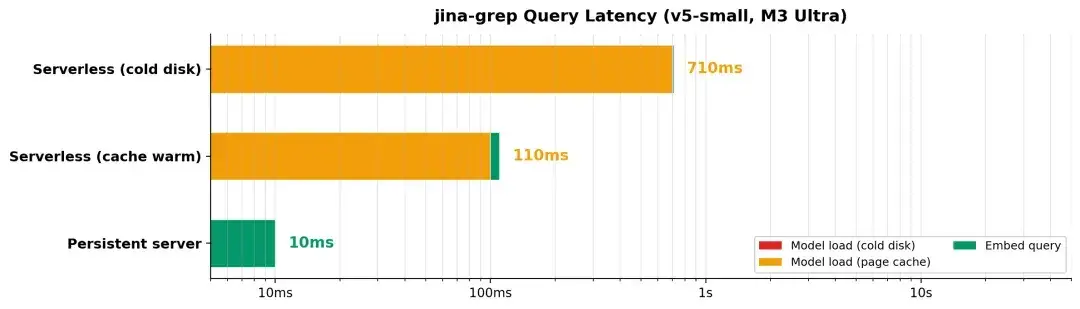
M3 Ultra 上的测试数据显示了令人印象深刻的性能:
- v5-small 模型(677M 参数):每个查询 7ms,峰值吞吐量为 25.3K 令牌/秒
- v5-nano 模型(239M 参数):每个查询 2.9ms,峰值吞吐量为 98.7K 令牌/秒
这种性能水平使本地语义搜索变得实用,作为经典 Unix 哲学和现代 AI 工具之间的桥梁。
3、技术细节
该项目完全基于 MLX 框架构建,不依赖 PyTorch 或 transformers。模型检查点从 HuggingFace 按需加载,支持自动批处理(每个请求最多 256 个输入)。服务器在后台运行,并通过简单的命令行界面调用。
安装很简单:
git clone https://github.com/jina-ai/jina-grep-cli.git && cd jina-grep-cli
uv venv .venv && source .venv/bin/activate
uv pip install -e .
4、实际应用
开发者已经注意到,这个工具可能潜在地取代他们现有搜索工作流的一半。无论是在代码库中搜索特定功能,还是在日志文件中排查问题,语义搜索都提供比传统关键字匹配更准确的结果。
例如,当查找与"指数退避重试机制"相关的代码时,传统的 grep 需要精确的关键字匹配,而 jina-grep 可以理解语义相似性,并在代码中不存在确切措辞时找到相关的实现。
该项目目前需要 Python 3.10+ 和 Apple Silicon Mac,并使用 Apache-2.0 开源许可证。
原文链接: jina-grep: Giving grep a Semantic Search Brain
汇智网翻译整理,转载请标明出处
