LLM 参数速查表
每个参数、每个提供商、每个用例——全部汇集在一处,你再也不用去搜索 "top_p vs top_k" 了。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
我大部分时间都在交付多智能体系统。坦白说,前几个月里,每次我打开一份新的 API 文档,都会盯着 temperature、top_p、presence_penalty、frequency_penalty、stop、response_format、reasoning_effort……然后凭感觉调参。
每篇博客都解释 temperature。少数几篇讲 top-p。几乎没有任何一篇文章解释所有参数,而且是跨所有提供商,并附带可以直接用到生产环境的实际配置。
所以我制作了这份速查表——正是我入门时希望拥有的那份。它带有主观判断,面向生产环境,旨在成为你最后一个需要收藏的 LLM 参数参考。

1. 如何使用这份速查表
两条规则让你远离麻烦。
规则 1:一次只改一个参数。 Temperature 和 top_p 都控制随机性。同时调两个就是在自找苦吃——你根本不知道是哪个旋钮在起作用。OpenAI 文档对此说得很直白:"我们通常建议只调整 temperature 或 top_p 其中之一,不要同时调整两者。"
规则 2:从配方开始,不要从零开始。 翻到第 10 节,复制最接近你任务的配方,然后再调整。我每次浪费的调参时间都是从自己拍脑袋选数字开始的。
如果你只打算读这篇文章的 10%,就读第 10 节。如果读 20%,再加上第 11 节。
2. 心智模型:LLM 实际上是如何生成文本的
在任何参数变得有意义之前,你需要对底层发生的事情有一个粗略的了解。LLM 每次生成一个 token,在每一步它都会生成一个巨大的 logits 向量——即其词汇表中每个 token 的原始分数(约 5 万到 20 万个 token)。
以下是这些 logits 在被选取为 token 之前经过的流水线:
┌─────────────────────────────────────────────────────┐
│ Raw logits from the model (one per vocab token) │
└─────────────────────────────────────────────────────┘
│
[ frequency_penalty, presence_penalty ] ← reshape logits
│
[ temperature ] ← flatten or sharpen
│
softmax ← logits → probabilities
│
[ top_k truncation ] ← keep top K only
│
[ top_p truncation ] ← keep cumulative P only
│
[ min_p truncation ] ← drop low-confidence tail
│
sample a token from what's left
│
repeat
你在下面读到的每个参数都是这条流水线上的一个具体站点。一旦你看清一个旋钮在链路中的位置,它的作用就显而易见了。
一个小例子。假设模型正在选择 "The capital of France is" 之后的下一个词。它的原始 logits 可能如下所示:
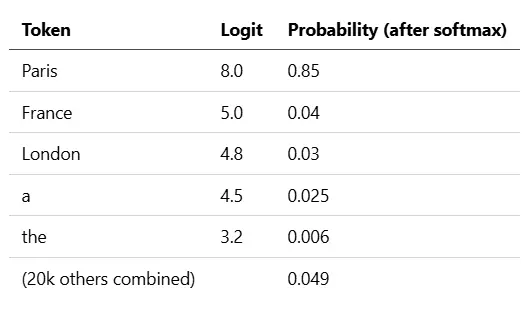
在 temperature=0 时,我们每次都会选 Paris。在 temperature=1.5 时,分布变得扁平,突然 London(或者更离谱的词)就有了真正被选中的机会。在 top_p=0.9 时,我们保留 Paris + France + London(累积 ≈ 0.92)并丢弃其余的。在 top_k=1 时,我们硬性选 Paris。这些操作是组合使用的——这就是整个游戏。
3. 核心采样三件套(加一个)
3.1 Temperature —— 大旋钮
作用: 在 softmax 之前将每个 logit 除以 T。低 T 使分布变尖锐(最高概率的 token 占主导);高 T 使分布变平(更多 token 获得有意义的概率)。
取值范围: 0.0–2.0(OpenAI、Gemini)或 0.0–1.0(Anthropic)。大多数提供商默认 1.0。
心智模型:
0.0→ 近乎贪心。最高概率的 token 每次都赢。0.3→ 非常聚焦。略有变化。0.7→ 平衡。提供商默认值集中在此。1.0→ 创意型。好主意与偶尔的胡言乱语并存。1.5+→ 狂野。适用于纯头脑风暴,对任何需要事实的内容都很危险。
何时调整:
- 事实性任务、信息提取、分类、代码 → 0.0–0.3
- 通用对话、摘要 → 0.5–0.8
- 创意写作、营销文案、头脑风暴 → 0.8–1.2
注意事项:
temperature=0并不保证确定性输出。参见陷阱 #2。- 如果 temperature 为 0,top_p 和 top_k 就无关紧要了——贪心解码无论如何都会胜出。
3.2 Top-P(核采样)—— 智能截断
作用: 按概率降序排列 token,然后只保留累积概率 ≥ P 的最小集合。其余的都置零。
取值范围: 0.0–1.0。OpenAI 和 Anthropic 默认 1.0(不过滤)。
为什么存在: 仅靠 temperature 可能会给奇怪的 token 赋予一些概率。Top-P 动态地截断那个长尾——当模型不确定时集合变大,当模型有把握时集合缩小。
何时调整:
- 如果你正在调整 temperature,保持 1.0 不变。
- 当你需要多样性但要阻止离谱 token 时,使用 0.9–0.95。
- 使用 0.1–0.3 获得聚焦的、切题的输出,而不是降低 temperature。
注意: 不要同时激进地设置 temperature 和 top_p。选一个。
3.3 Top-K —— 硬性上限
作用: 只保留按概率排名前 K 的 token。K=1 就是贪心解码。
取值范围: 1 到无穷大(开源中通常默认 40)。
提供商支持: Anthropic、Gemini 以及每个开源运行时(vLLM、Ollama、llama.cpp)都暴露了它。OpenAI 没有。
何时调整:
- 通常不用动。Anthropic 自己的文档说*"仅推荐用于高级用例"。
- K=40 是配合 temperature + top_p 的合理安全网。
- K=1 只是
temperature=0的另一种说法。
3.4 Min-P —— 2026 年的升级
作用: 与累积概率截断(top_p)不同,min_p 表示"丢弃任何概率小于 P ×(最高概率 token 的概率)的 token"。它会随模型置信度自动缩放。
取值范围: 0.05–0.1 是最佳区间。
为什么重要: 研究表明,在高温下,min-p 比 top-p 产生更连贯的输出,因为它是置信度感知的。当模型确定时,它会自动变得更严格。当模型不确定时,它保持宽松。
提供商支持: vLLM、llama.cpp、Ollama、Hugging Face Transformers。OpenAI、Anthropic 或 Gemini API 中不支持。
何时调整: 如果你运行自己的开源模型,2026 年的共识是 temperature=1.0 + min_p=0.1,完全跳过 top_p 和 top_k。更简单,通常也更好。
4. 长度与停止
4.1 max_tokens / max_completion_tokens
作用: 对模型可以生成多少 token 设置硬性上限。
重要的命名变化: OpenAI 较新的 Responses API 使用 max_completion_tokens。其较旧的 Chat Completions API 使用 max_tokens。Anthropic 使用 max_tokens。Gemini 使用 maxOutputTokens。请查阅你所使用的具体端点的文档。
经验法则: 英语中每个 token 约对应 4 个字符。100 token ≈ 75 个单词。
注意: 在推理模型(o1、o3、R1)上,max_completion_tokens 必须包含推理 token 和可见输出。要设置得宽裕一些,否则你会因为模型把预算花在了思考上而得到截断的答案。
4.2 stop / stop_sequences
作用: 自定义字符串,遇到后立即终止生成。模型不会输出停止字符串本身。
大多数提供商每次请求最多 4 个序列。
实际用途:
- 在
"Observation:"或"\nHuman:"处结束的智能体循环 - 应在下一个示例分隔符处停止的少样本补全* 防止在草稿本式提示中出现失控输出
4.3 n / candidate_count
作用: 在一次调用中从同一提示请求多个独立补全。OpenAI 称之为 n,Gemini 称之为 candidate_count,Anthropic 不直接支持(需要发送多个请求)。
何时有用: 自洽性投票、创意任务的 A/B 生成、类束搜索探索。
警告: 每个补全都要付费。这会快速成倍增加成本。
5. 重复控制
这是大多数人容易搞混的地方。有三种不同的惩罚,它们做的事情不同。
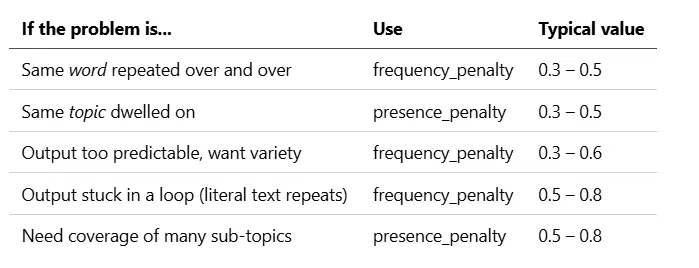
5.1 frequency_penalty(词级别)
作用: 根据 token 已经出现过多少次来进行惩罚。出现次数越多 → 惩罚越大。与计数成比例。
取值范围: -2.0 到 2.0(OpenAI)。正值 = 抑制重复,负值 = 鼓励重复。
用例: 模型在长输出中反复说 "very interesting" 十几次。设置 frequency_penalty = 0.3。
不要超过 ~0.7。 超过后你会开始破坏语法,因为常见词(the、a、and)会被过度惩罚。
5.2 presence_penalty(主题级别)
作用: 对任何出现过的 token 施加一次性固定惩罚。不关心出现了多少次——只关心"我们见过它吗"。
取值范围: -2.0 到 2.0(OpenAI)。
用例: 你希望模型不断引入新的主题/概念,而不是停留在相同的主题上。头脑风暴时设置 presence_penalty = 0.3 – 0.5。
5.3 frequency 与 presence 对比——速查表
5.4 repetition_penalty(开源版本)
一种乘法版本,用于 Hugging Face、vLLM、llama.cpp。典型值 1.1–1.15。超过 1.2 你会看到语法崩溃。
OpenAI 和 Anthropic 不暴露这个——它们使用 frequency/presence 替代。
6. 精细控制
6.1 logprobs
作用: 返回每个生成 token 的对数概率(以及可选的前 N 个备选 token 的概率)。
何时需要:
- 构建分类器并比较标签 token 的概率
- RAG 的置信度估计(低置信度 → 触发回退)
- 调试模型为什么选择了奇怪的东西
提供商现状(2026 年 4 月):
- OpenAI:在 GPT-5 系列和所有推理模型(o1、o3、o4-mini)上已弃用。仍在旧版 GPT-4 系列上有效。如果你依赖 logprobs,你只能留在旧版 OpenAI 模型上,或者选择其他提供商。
- Anthropic Claude:Anthropic 的原生 API 目前不支持 logprobs。
- Gemini:
responseLogprobs: true+logprobs: 1–20。响应包含avgLogprobs和logprobsResult对象。 - 开源(vLLM、Ollama、llama.cpp):始终支持。
这有实际的规划影响。如果你的架构依赖 token 级别的置信度(分类器头、RAG 回退触发器、幻觉检测),请在投入之前检查提供商支持——我亲眼见过团队在迁移过程中撞上这堵墙。
7. 结构化输出与工具使用
三种不同的工具,三种不同的用途。选对那个。
7.1 response_format:json_object
最简单的选项。只保证输出能解析为有效的 JSON。你仍然需要自己验证 schema。
支持:OpenAI(旧版)、Gemini、大多数开源。
7.2 response_format:json_schema(或新 Responses API 中的 text.format)
强制执行特定的 Pydantic/JSON Schema。模型无法生成不匹配的响应。
默认情况下使用这个处理任何提取或分类任务。这过去需要 200 行重试-验证代码。现在它就是一个字段。
重要搭配: strict: true + temperature: 0.0。确定性解码减少方差,schema 强制结构。
7.3 tools / tool_choice —— 函数调用
当模型需要决定调用哪个函数以及使用什么参数时使用。这是用于智能体工作流的——搜索 API、数据库,以及你的应用与之通信的任何外部系统。
tool_choice 选项:
"auto"—— 模型自行决定是否调用以及调用哪个工具"none"—— 不允许使用工具*"required"—— 必须调用一个工具{"type": "function", "function": {"name": "X"}}—— 强制调用指定的那个
经验法则: 如果你想要返回结构化数据,使用结构化输出。如果你想让模型触发一个动作,使用函数调用。
8. 推理模型遵循不同的规则
这是 90% 的 LLM 参数指南中缺失的部分,也是你在 2026 年最需要的部分。
OpenAI 的 o1 / o3 / o4-mini、DeepSeek R1 和 Claude 的 extended thinking 模式会默默地忽略大多数传统采样参数。
8.1 推理模型上被忽略的参数
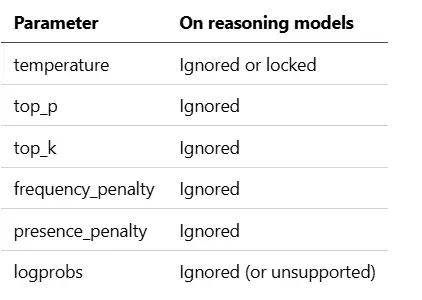
设置了不会报错——只是没有任何效果。我曾在 o3-mini 上浪费了好几个小时调 temperature=0.2,后来才发现这个参数被默默吞掉了。
8.2 你应该调整什么
reasoning_effort(OpenAI):minimal、low、medium、high、xhigh。更高的 effort = 更多的思考 token、更慢的响应、在难题上更好的答案。在 o3 上,只暴露了 low、medium、high。
thinking_budget(Claude、Gemini):对思考阶段的显式 token 上限。
showThinking(DeepSeek R1):将推理过程与最终答案一起返回。
8.3 其他推理模型注意事项
- 它们需要更大的
max_completion_tokens——推理会消耗预算。 - 它们很贵。一次
reasoning_effort=high的调用可能会消耗普通模型 5-20 倍的 token。 - 提示工程的重要性降低了。它们使用 "think step by step" 往往效果更差——脚手架已经在模型中了。
- 适用场景:数学、硬核代码审查、多步规划、模糊决策。不适用:摘要、提取、聊天、便宜模型就能搞定的事情。
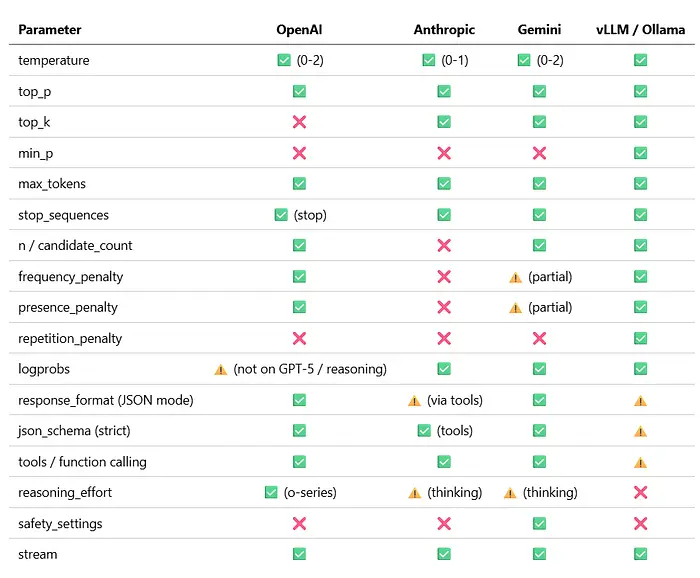
9. 提供商支持矩阵
快速参考。✅ = 支持,⚠️ = 支持但有限制,❌ = 未暴露。
10. 12 个可直接复制粘贴的用例配方
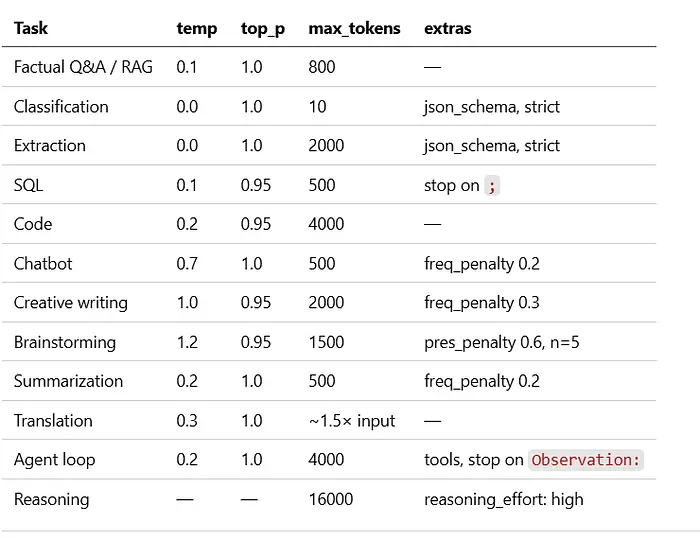
这些是我在生产中实际使用的负载配置。根据你的提供商调整模型名称。
10.1 RAG / 带引用的事实性问答
{
"model": "gpt-5.4",
"temperature": 0.1,
"top_p": 1.0,
"max_tokens": 800,
"presence_penalty": 0,
"frequency_penalty": 0
}
原因: 检索到的上下文应该占主导地位。低 temperature 意味着模型会紧贴文档中的内容。
10.2 分类(例如,意图、情感、安全)
{
"model": "gpt-5-mini",
"temperature": 0.0,
"max_tokens": 10,
"response_format": { "type": "json_schema", "json_schema": { ... }, "strict": true }
}
原因: 确定性、极小的输出、强制的 schema。Schema 将模型约束到你的标签词汇表,不需要任何逐 token 的技巧。
10.3 从杂乱文本中进行 JSON / 结构化提取
{
"model": "gpt-5.4",
"temperature": 0.0,
"response_format": { "type": "json_schema", "json_schema": { ... }, "strict": true },
"max_tokens": 2000
}
原因: 结构是不可妥协的。零 temperature + 严格 schema = 在代码中少验证一样东西。
10.4 SQL 生成
{
"model": "gpt-5.4",
"temperature": 0.1,
"top_p": 0.95,
"max_tokens": 500,
"stop": [";", "\n\n"]
}
原因: 基本确定,给措辞选择留了一点余地。停止序列防止模型自我解释。
10.5 代码生成
{
"model": "claude-sonnet-4-6",
"temperature": 0.2,
"top_p": 0.95,
"max_tokens": 4000
}
原因: 代码需要的是正确而非创意。轻微的 temperature 让模型可以在等价的惯用模式之间做选择。
10.6 聊天机器人 / 客户支持
{
"model": "gpt-5.4",
"temperature": 0.7,
"top_p": 1.0,
"max_tokens": 500,
"presence_penalty": 0.1,
"frequency_penalty": 0.2
}
原因: 跨轮次的自然感觉的多样性。小的 frequency penalty 防止机器人重复开场白。
10.7 创意写作(故事、诗歌、营销文案)
{
"model": "claude-opus-4-7",
"temperature": 1.0,
"top_p": 0.95,
"max_tokens": 2000,
"frequency_penalty": 0.3
}
原因: 完整的创意空间,top_p 过滤长尾 token,penalty 在长输出中保持措辞新鲜。
10.8 头脑风暴 / 创意发散
{
"model": "gpt-5.4",
"temperature": 1.2,
"top_p": 0.95,
"n": 5,
"presence_penalty": 0.6,
"frequency_penalty": 0.3
}
原因: 高 temperature + presence penalty = 跨主题的发散想法。n=5 在一次调用中给你五个独立的尝试。
10.9 摘要(事实性、抽取式)
{
"model": "gpt-5.4",
"temperature": 0.2,
"max_tokens": 500,
"frequency_penalty": 0.2
}
原因: 忠实度第一。温和的 frequency penalty 因为摘要往往容易变得重复。
10.10 翻译
{
"model": "gpt-5.4",
"temperature": 0.3,
"top_p": 1.0,
"max_tokens": "<~1.5× input length>"
}
原因: 需要准确但也允许目标语言中的自然表达。正确设置 max_tokens 很重要——翻译可能比原文更长。
10.11 智能体 / 工具使用循环
{
"model": "claude-sonnet-4-6",
"temperature": 0.2,
"max_tokens": 4000,
"tools": [ ... ],
"tool_choice": "auto",
"stop": ["Observation:"]
}
原因: 智能体应该果断,而不是有创意。低 temperature + 工具 schema + 在下一个观察边界停止。
10.12 推理 / 数学 / 困难问题
{
"model": "o3",
"reasoning_effort": "high",
"max_completion_tokens": 16000
}
原因: 注意缺少了什么——没有 temperature,没有 top_p。那些都会被忽略。只需给模型预算,让它去思考。
11. 9 个生产环境陷阱(以及如何避免)
这些都是我亲自踩过、搞坏过、或者深夜 11 点调试过的问题。
陷阱 1:同时调整 temperature 和 top_p
只选一个。两者都控制随机性,叠加使用会让输出变得难以预测,调试起来非常痛苦。OpenAI 自己的文档明确说了这一点。
解决方案: 决定你要调整的是随机性的程度(temperature)还是分布的尾部截断(top_p),只动那一个。
陷阱 2:认为 temperature=0 是确定性的
并不是。GPU 非结合性、批次不变性、MoE 路由以及偶尔的模型版本热切换都会引入偏差。在长输出中,单个 token 的翻转就能改变剩余的整个响应。
解决方案: 设计你的应用以容忍微小差异。固定模型版本,在测试中针对结构和语义做断言,永远不要依赖精确的字符串相等。
陷阱 3:将 frequency_penalty 设得太高
任何超过 ~0.7 的值都会开始惩罚常见词(the、a、and),因为它们自然会频繁出现。输出会变得语法破碎——你会看到奇怪的选词和缺失的冠词。
解决方案: 保持 frequency_penalty ≤ 0.5,除非你在专门做实验。
陷阱 4:混淆 presence 和 frequency 惩罚
它们解决不同的问题。Frequency = 词语重复。Presence = 话题探索。选错了意味着症状不会消失。
解决方案: 再读一遍第 5.3 节。
陷阱 5:忘记推理模型会忽略采样参数
你在 o3 上设置了 temperature=0.3,输出每次运行都不一样。你以为是个 bug。其实不是——参数被默默忽略了。
解决方案: 在推理模型上,只有 reasoning_effort 和 max_completion_tokens 有效。别调其他的了。
陷阱 6:推理模型上的 max_tokens 设得太低
模型思考了 5000 个 token,试图给出答案,碰到了你 1000 token 的上限,返回截断的输出。你以为模型坏了。
解决方案: 在 o 系列 / R1 上,为你预期的可见答案预留 4-16 倍的 token。
陷阱 7:在没有 schema 的情况下使用 response_format: json_object
你得到了有效的 JSON,但结构是模型随意的想法。下游代码崩溃。
解决方案: 使用 json_schema 配合 strict: true。Schema 就是契约。
陷阱 8:忽略提供商特定的默认值
Anthropic 默认 temperature 为 1.0。OpenAI 也默认为 1.0。但两个模型的内部分布是不同的——两个提供商上相同的 temperature 并不意味着相同的创意水平。
解决方案: 切换提供商时重新调参。不要盲目移植设置。
陷阱 9:不固定模型版本
gpt-5.4 或 claude-sonnet-4-6 背后的基础模型今天的检查点与六个月前不是同一个。你精心调整的参数在行为上可能会漂移。
解决方案: 在生产环境中固定到特定版本(gpt-5.4-2026-03-05,而不是 gpt-5.4)。建立每次模型发布时运行的评估,升级时重新调整参数。
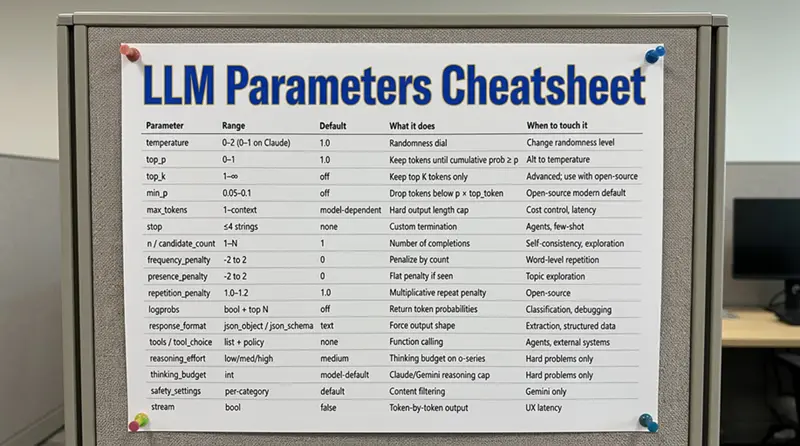
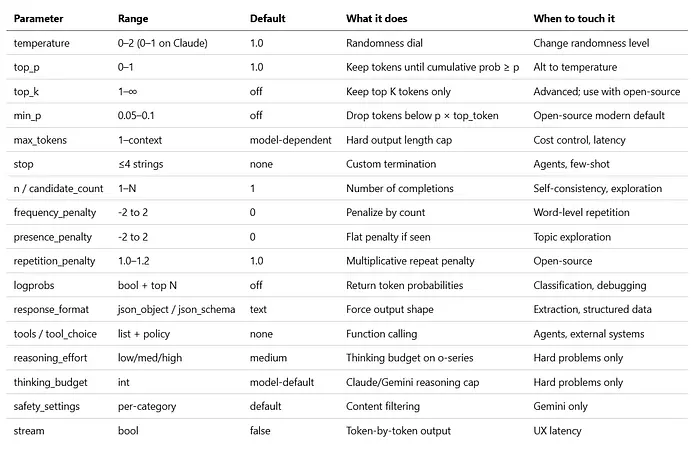
12. 单页快速参考
收藏它。打印它。贴在你的显示器上。
按任务的默认入门套件
13、结束语
参数是杠杆。只需替换三个魔法数字,你就能将 LLM 应用的质量翻倍。但反之亦然——错误的参数会悄悄降低所有下游指标,然后你会怪罪模型。
我认识的最好的工程师对待参数就像对待 SQL 查询计划一样:是需要理解的东西,而不是凭感觉调的东西。
如果这篇文章对你有帮助,我钉在桌上的是第 12 节。从那里开始。复制一个配方。一次只改一个参数。下次你的团队成员问为什么"修好" temperature 后输出变得奇怪时,你就会确切知道该看哪里。
原文链接: The Complete LLM Parameters Cheatsheet 2026
汇智网翻译整理,转载请标明出处
