Memex:智能体长期记忆
今天,我们将探讨一种名为Memex的新方案,由埃森哲的研究人员开发,它为AI提供了一种保持"桌面整洁"的方式,同时将其所有详细的笔记存储在一个永久的、有组织的"文件柜"中。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
LLM智能体正逐渐成为各类问题的首选解决方案,从编写代码到规划复杂的商务行程。然而,随着任务变得越来越长、越来越复杂,跨越数百个步骤时,它们会遇到一个重大障碍——上下文窗口。
你可以把上下文窗口想象成LLM的工作记忆。就像人一次只能在脑海中记住有限的事情一样,LLM一次也只能处理一定量的文本。
当一个任务持续时间过长时,AI的记忆会被旧的日志、工具输出和过去的思考填满。为了继续工作,大多数AI系统要么开始忘记对话的开头,要么以丢失重要细节的方式对其进行总结。这常常导致AI犯错或重复操作,因为它无法从之前的对话中找到某个特定的证据。
今天,我们将探讨一种名为Memex的新方案,由埃森哲的研究人员开发,它为AI提供了一种保持"桌面整洁"的方式,同时将其所有详细的笔记存储在一个永久的、有组织的"文件柜"中。
1、索引经验记忆
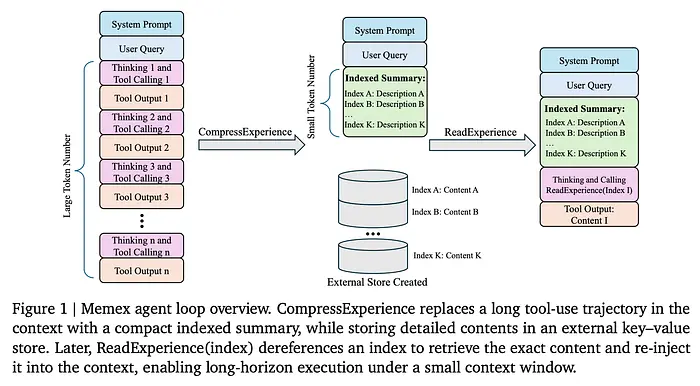
Memex背后的一个关键理念是索引经验记忆机制。Memex智能体不再试图将长对话的每个字都保存在活跃记忆中,而是采取了一种非常人性化的方式:它做有组织的笔记。
当LLM的工作上下文变得过于拥挤时,它会触发一个名为压缩的过程。它会查看一大段对话并创建两样东西:
- 紧凑摘要:一段带有指针的简短描述,记录发生了什么,这段摘要会保留在AI的活跃记忆中。
- 外部存档:原始的、完整保真的交互记录(精确的代码日志或工具响应)被保存在外部数据库中。
至关重要的是,数据库中的每条信息都被分配了一个稳定索引(例如唯一的标签或书签)。
在其摘要中,系统保留了这些索引的映射。之后,如果LLM需要某个之前保存的具体细节(如房间ID或某行代码),它不需要猜测或总结,只需使用索引解引用或获取精确的原始数据,并将其带回"桌面"。
索引经验记忆压缩示例:
压缩前的上下文

压缩后的上下文

2、深入解析:Memex循环如何运作
为了实现Memex,研究人员不仅仅为LLM编写了一套规则列表,而是使用了一个名为MemexRL的训练框架。该框架利用强化学习来教AI如何管理自己的记忆。
1. 决策空间:在Memex中,记忆管理被视为"一等公民动作"。这意味着"保存记忆"(CompressExperience)和"读取记忆"(ReadExperience)是AI选择使用的工具,就像它可能选择使用计算器或搜索引擎一样。AI需要学习何时应该压缩笔记,以及如何命名索引以便日后查找。
2. 奖励塑形:在训练过程中,LLM会根据其表现获得分数。为了鼓励良好的记忆习惯,研究人员添加了三个特定的惩罚项:
- 上下文溢出惩罚:如果系统让工作记忆变得过于满而没有进行压缩,就会受到惩罚。这教会它主动整理。
- 冗余惩罚:如果智能体系统向工具询问它已经看到过的信息,就会受到惩罚。这迫使它使用自己的记忆(
ReadExperience),而不是浪费时间和金钱重复工作。 - 格式惩罚:确保AI正确使用记忆工具,以免系统崩溃。
3. 软触发:Memex使用软触发机制,而不是由计算机程序在固定时间点强制AI压缩记忆。系统会告诉AI当前使用了多少token。然后AI学会自行决定何时到达自然的语义边界(例如完成项目的某一部分),来清理桌面并保存笔记。
3、评估
研究人员在一个非常困难的ALFWorld环境版本上测试了Memex,该环境涉及在虚拟房屋中移动物体。他们对其进行了修改使其更难:AI只允许"看"一次周围环境,之后必须完全依赖记忆来记住所有东西的位置。
结果表明,Memex在长周期任务上取得了巨大进步:
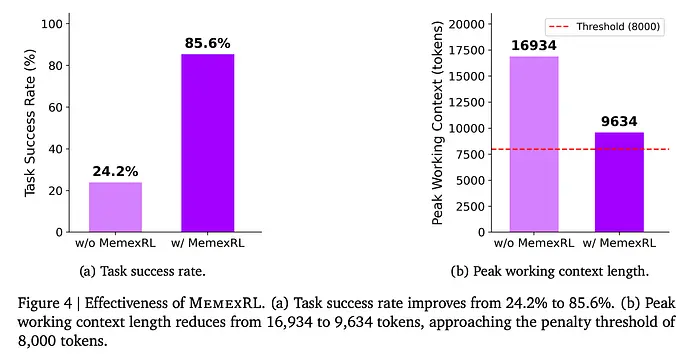
- 成功率:在没有Memex训练的情况下,AI只解决了约24%的任务。学会使用Memex后,其成功率跃升至85.6%。
- 记忆效率:尽管成功率大大提高,AI使用的活跃工作上下文却显著缩小,峰值内存使用量减少了约43%。
- 行为变化:随着训练的进行,AI学会了以更少的次数但更好的质量来压缩记忆。它还将"读取"工具的使用量增加了6到7倍,表明它真正学会了信任和使用自己的笔记。
4、相关工作
Memex建立在LLM记忆领域的几个早期理念之上。MemGPT和MemoryBank等系统是早期为LLM提供长期聊天记忆的尝试。其他较新的方法,如FoldGRPO或AgentFold,使用上下文折叠或摘要来保持聊天简短。
然而,研究人员认为,这些早期方法大多是有损的。它们减少了文本量,但往往会丢弃智能体在复杂工作流中后期可能需要的具体证据(如原始日志或精确ID)。
Memex的独特之处在于,它将原始数据完整地保存在外部存储中,同时保持LLM的思维空间小巧而高效。
5、优缺点
与任何新技术一样,Memex有其优势和权衡。
优点:
- 完整保真:由于它逐字保存原始工件,AI永远不会产生幻觉或忘记过去交互的精确细节。
- 上下文预算:它允许智能体处理那些实际上太长而无法放入任何现代AI上下文窗口的任务。
- 精确检索:与一些使用模糊或基于相似度搜索的系统不同,Memex使用精确索引,使其更加可靠和可审计。
缺点:
- 训练强度:教会AI管理自己的记忆需要复杂的强化学习和专门的奖励设计。
- 工具依赖:AI必须足够聪明以理解如何有效使用
压缩和读取工具,这通常需要中大型基础模型。 - 基础设施:它需要一个外部数据库(键值存储)与AI并行运行以保存"归档"的记忆。
6、未来方向
研究人员将Memex视为一种互补的扩展轴。这意味着,虽然使AI模型更大是改进它们的一种方式,但使它们的记忆系统更好同样重要。
在未来,这种索引式记忆可以用于更长周期的任务,例如在单一软件项目或科学发现上工作数天或数周的智能体。它还可能带来能够通过传递索引和摘要来回共享记忆的智能体。
7、结束语
Memex代表了我们思考AI智能方式的转变。与其要求AI在自己的"头脑"中拥有完美、无限的记忆,Memex为它提供了成为有组织的专业人士的工具。通过将小型的、活跃的工作状态与永久的经验存档分离开来,Memex使AI智能体能够在不被压垮的情况下处理更大的问题。
随着我们迈向一个AI智能体处理复杂工作流的世界,拥有一张整洁的办公桌和一个完美的文件柜将是使它们成为真正可靠的队友的关键。
原文链接: Memex: Giving AI Agents a Permanent Memory for Long Tasks
汇智网翻译整理,转载请标明出处
