miniCOIL:为BM25添加语义
BM25很快但"上下文盲目"。用miniCOIL的4D语义向量修复它,实现准确、可扩展的稀疏检索,为RAG增压。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
如果你花时间构建搜索系统,让我告诉你一些可能会让你有点刺痛的事情!!!
BM25这个算法为OpenSearch、Elasticsearch和大多数企业搜索系统中的词法搜索提供动力……它不理解它处理的任何一个词。一个都不理解。它只是计算词。它权衡它们的稀有度。它根据这些计数对文档进行排名。但它完全不知道任何词的实际含义。
对于大多数查询,这工作得很好。你搜索"python tutorial",BM25找到包含这些精确词的文档。太好了。
但语言变得模棱两可的那一刻。"search"在两个不同文档中意味着不同的东西的那一刻,"vector"在一个段落中指流行病学,在另一个段落中指线性代数的那一刻……BM25失败了。静默地。自信地。毫无警告。
miniCOIL修复了这个问题。而且它以一种令人惊讶的优雅方式做到了这一点。
1、BM25:它实际上做什么 来源(研究)
BM25 => 最佳匹配25是一个来自1990年代的排名函数,它对它的作用来说老化得非常好。公式看起来像这样:
score(D,Q)=∑qi∈QIDF(qi)×TF(qi,D)score(D,Q)=qi∈Q∑IDF(qi)×TF(qi,D)
两个组件驱动一切:
IDF(逆文档频率)
这个词在所有文档中有多罕见?像"the"这样的词到处都出现,所以它的IDF很低。像"galacto"这样的词很少出现,所以它的IDF很高。稀有词更有信息量,所以它们在最终得分中获得更多权重。
TF(词频)
这个词在这个特定文档中出现多少次?更多出现表明更高的相关性,达到一定程度。BM25应用饱和函数,所以你不能通过无休止地重复词来游戏它。
这就是整个模型。每个词两个数字,乘在一起,在所有查询词上求和。
它很快,它可解释,对于关键字密集的查询和一致的语料库,它工作得很好。OpenSearch在毫秒内对数百万文档运行它。BM25对于它被设计做的事情来说是一个真正好的算法。
问题是它被设计做什么... 首先???
BM25将词的每次出现视为相同。关于冥想的文档中的**"search"一词获得与关于Elasticsearch的文档中的"search"一词完全相同的IDF权重。线性代数教科书中的"vector"在计算上与关于蚊媒疾病的流行病学论文中的"vector"**无法区分。
BM25看不到上下文。它只看到词。
2、同义词问题:BM25总是失败的地方
这不是边缘情况。这是语言的正常状态。大多数常见词根据上下文有多个有意义的不同的意义。
考虑当你查询时会发生什么:"vector disease control mosquito"
BM25会对任何包含"vector"的文档进行评分。这包括:
- 关于蚊媒疾病媒介的公共卫生论文(正确)
- 关于向量数据库的机器学习文章(错误)
- 关于向量加法的物理教科书章节(错误)
- 关于特征向量的线性代数课程(错误)
所有这些都包含"vector"。BM25无法根据"vector"在每个文档中的实际含义来区分它们。它只是计数。而且计数相等。
或者尝试:"searching for inner peace and self discovery"
BM25匹配每个包含"search"或"searching"的文档。关于搜索引擎优化的文档与关于精神自我发现的文档获得相同的关键字匹配分数。模型无法看到"search"作为技术数据库操作和"search"作为意义的人类隐喻之间的区别。
| 词 | 上下文A:BM25告诉它们分开? | 上下文B |
|---|---|---|
| search | 搜索引擎、索引、检索 | 搜索灵魂、正念 |
| searching | 数据库查询 | 寻找内心平静 |
| vector | 数据库、嵌入、AI | 控制、蚊子 |
| vector | 微积分、梯度、方程 | 数据库、嵌入 |
| vector | 控制、蚊子 | 向量微积分、梯度方程 |
| bank | 利率、货币政策 | 河岸、侵蚀、洪泛区 |
| plant | 工厂、制造、设备 | 花、叶子、光合作用 |
语言是深度模棱两可的,BM25忽略了每一个模棱两可。不是因为它设计糟糕,而是因为它在设计时不存在更好的工具。
那些工具现在存在。
3、miniCOIL:想法
miniCOIL是由Qdrant开发的稀疏检索模型,它用一个关键的补充扩展了BM25的公式:上下文意义。
核心洞察很简单。当你索引一个词时,你可以访问所有周围的词。
你知道"vector"是否出现在:"database," "embeddings, AI"旁边,还是 "disease, control, mosquito"旁边,还是 "calculus, gradient, equations"旁边。
那个周围的上下文告诉你在这个文档中、就在这里、在这个特定出现中使用了哪个词义。
miniCOIL通过为每个词出现计算一个4维上下文指纹来捕获这一点。四个数字。这听起来不可能小... 但它足够了。大多数有多个含义的词只有少数真正不同的意义。四个维度可以区分它们。
在查询时,相同的过程在查询上运行。当查询"vector disease control mosquito"遇到关于蚊媒疾病媒介的文档时,"vector"这个词在查询和文档中都有相似的指纹。当它遇到关于向量数据库的文档时,指纹不同。该词的匹配分数下降。
4、公式:一个额外的项改变一切
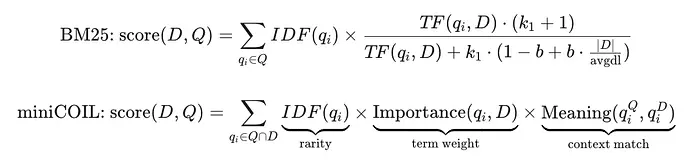
现在有三个因素:
- IDF:这个词在整个集合中有多罕见?(与BM25相同)
- 重要性:这个词在这个文档中有多重要?(类似于TF,但是学习的)
- 意义:查询和文档是否在相同的意义中使用这个词?
意义项是查询中词的4维上下文指纹与文档中相同词的4维上下文指纹的点积。相同词在相同上下文中意味着高意义分数。相同词在完全不同的上下文中意味着低意义分数。上下文感知的全部区分能力被捕获在那个点积中。
那就是革命。不是一个全新的检索范式。只是你使用了几十年的公式中的一个额外项。
5、为什么4维足够
你可能会想:为什么上下文指纹只用4维?对于捕获词义来说,这听起来不可能小。
关键是miniCOIL不试图编码所有语义信息。它不是通用嵌入模型。它只试图区分共享相同表面形式的词的不同意义。
对于大多数模棱两可的词,有意义的不同意义数量很小。"Vector"可能有5或6个真正不同的上下文。"Search"有一小撮。"Bank"有两个主导的。4维空间可以在小数量的簇之间区分,这就是这里所需的全部。
这个设计选择有一个美丽的后果:miniCOIL保持稀疏。它产生稀疏向量,就像BM25一样,每个词表术语一个值。你不需要运行完整的密集嵌入模型。词表大小匹配标准BM25词表。索引大小相当。
你以大致BM25的成本获得上下文消歧。这就是miniCOIL的工程优雅。
miniCOIL在OpenWebText上训练,4000万个多样化的一般网络文本句子。这是一个深思熟虑的选择:在像MS MARCO(信息检索查询)这样的领域特定语料库上训练会使模型偏向那个领域。OpenWebText给miniCOIL跨一般语言的广泛词义覆盖,这就是为什么它能很好地泛化到领域外查询。
6、IDF修饰符:为什么这需要Qdrant
这是基础设施变得有趣的地方,也是大多数向量数据库不足的地方。
miniCOIL产生稀疏向量,其中存储的值是每个术语的重要性×意义因子。IDF因子被有意不烘焙到那些存储的值中。
为什么?因为IDF随着你的集合发展而变化。添加新文档,删除旧文档... 每个术语在语料库中的频率会转移。如果你在索引时将IDF烘焙到存储的向量中,每当添加或删除任何文档时,你都需要重新索引每个文档。那不是检索系统。那是假装成一个的批处理流水线。
Qdrant用一个参数解决了这个问题:modifier=Modifier.IDF。
from qdrant_client import QdrantClient
from qdrant_client import models
client = QdrantClient(":memory:")
client.create_collection(
collection_name="minicoil",
sparse_vectors_config={
"minicoil": models.SparseVectorParams(
modifier=models.Modifier.IDF
)
},
)
有了那一行,Qdrant动态跟踪文档频率,并在查询时使用实时集合统计应用IDF。文档可以自由添加或删除,IDF值自动保持正确。没有重新索引作业。没有陈旧的近似。没有维护流水线。
OpenSearch和Elasticsearch没有等效功能。两个系统都没有自定义稀疏向量的IDF修饰符。你必须从完整语料库自己计算IDF,在索引时将其乘入稀疏向量值,并在语料库更改时重新索引所有内容。这在技术上是可行的。这也是那种当有人上传新文档批次而没有人重新运行IDF计算时,在生产中静默损坏的东西。
Qdrant正确地、原生地、始终保持最新地做到了这一点。这不是次要的实现细节。这是使miniCOIL作为生产检索器而不是研究原型可行的原因。
7、FastEmbed:内置miniCOIL支持
miniCOIL(Qdrant/minicoil-v1)原生集成到FastEmbed,来自Qdrant团队的轻量级嵌入库。
FastEmbed为广泛的嵌入模型处理基于ONNX的推理,包括miniCOIL,无需PyTorch设置、CUDA配置或分词器管理。对于miniCOIL特别地,Qdrant客户端的Document类在底层直接与FastEmbed集成:
# 索引时 — FastEmbed在内部处理miniCOIL推理
models.Document(
text=document_text,
model="Qdrant/minicoil-v1",
options={"avg_len": avg_document_length}, # BM25长度归一化
)
# 查询时
models.Document(
text=query_text,
model="Qdrant/minicoil-v1"
)
你不需要自己加载模型。你不需要管理分词器。你只需传递一个Document对象,Qdrant调用FastEmbed,运行推理,并处理其余部分。avg_len参数为BM25风格的文档长度归一化提供数据,在摄入前从你的语料库计算一次。
对于想要将miniCOIL添加到现有流水线的开发者来说,进入门槛几乎为零。安装qdrant-client[fastembed],你就拥有了所需的一切。
8、Qdrant:为这种搜索而构建
Qdrant是用Rust从头构建的,考虑到AI规模的搜索。稀疏向量、密集向量和混合搜索都是一等公民,不是事后附加到通用数据库上的。
modifier=Modifier.IDF功能是Qdrant如何考虑检索正确性的一个很好的例子。他们不只是添加稀疏向量存储。他们考虑了完整的评分流水线,并为其构建了在动态、实时集合中正确工作所需的基础设施。
最近的版本使这对现实世界部署更加强大。
Qdrant 1.16引入了ACORN,这是对过滤向量搜索的重大改进。当你将语义检索与元数据过滤器结合时(只在特定知识库内搜索,或在特定日期范围内的文档内搜索),传统的HNSW实现会静默降级。过滤后的邻域变得稀疏,图遍历开始错过相关结果而不报告任何错误。
ACORN通过在直接邻居被过滤掉时检查HNSW图中邻居的邻居来修复这个问题。基准数字清楚地表明了这一点:在有多个低选择性过滤器的查询上,ACORN的准确率为97.2%,而没有它的准确率为53.3%。对于任何用户在知识库范围子集内搜索的生产部署,这就是使系统值得信赖的原因。
Qdrant 1.16还带来了条件更新,它允许版本感知的点修改以防止并发冲突。当多个写入者同时更新实时miniCOIL集合时,这使索引保持一致而无需外部锁定。
Qdrant 1.17发布了用于混合查询的加权RRF。如果你将miniCOIL的稀疏检索信号与密集语义模型结合(对生产RAG来说是一个强大的组合),你现在可以为每个信号分配不同的重要性权重。关键字密集查询用更多稀疏权重,概念查询用更多密集权重。在查询时可调,无需重新训练。
Qdrant 1.17还带来了相关性反馈查询,它实现了代理细化循环。系统可以发出初始miniCOIL查询,根据任务标准对结果进行评分,反馈哪些结果是相关的,并获得精炼的结果集。无需重新训练,无需重新嵌入,无需模型调用。使用向量结构的纯检索时细化。
Qdrant文档涵盖稀疏向量、混合搜索、IDF修饰符以及与miniCOIL部署相关的一切。
9、真实数字:BEIR基准
这是真正见分晓的地方。BEIR是评估跨不同数据集检索质量的标准基准。NDCG@10测量排名质量,越高越好。
| 数据集 | BM25 | miniCOIL | 赢家 |
|---|---|---|---|
| MS MARCO | 0.237 | 0.244 | miniCOIL |
| NQ | 0.304 | 0.319 | miniCOIL |
| Quora | 0.784 | 0.802 | miniCOIL |
| FiQA-2018 | 0.252 | 0.257 | miniCOIL |
| HotpotQA | 0.634 | 0.633 | BM25(平局) |
miniCOIL在所有五个数据集上获胜或平局,零领域特定训练。它在一般网络文本上训练,而不是在MS MARCO或任何这些特定领域上,但它仍然始终优于BM25。
Quora的增益特别值得注意:+0.018 NDCG@10。Quora充满了改写的问题,相同的意图以许多不同的方式表达,词义消歧对于将同义查询匹配到相关答案很重要。miniCOIL的上下文指纹帮助识别两个不同的措辞何时在问同一件事,即使精确的词不同。
10、完整代码
10.1 安装依赖项
pip install qdrant-client[fastembed] rank-bm25 streamlit
10.2 语料库
DOCUMENTS = [
"The Art of Search and Self-Discovery",
"Searching the Soul: A Journey Through Mindfulness",
"In Search of Meaning: A Psychological Perspective",
"The Human Search for Connection in a Digital World",
"Search Engines: A Technical and Social Overview",
"Search Optimization Strategies for E-commerce",
"The Rise of Vector Databases in AI Systems",
"Efficient Vector Search Algorithms for Large Datasets",
"Vector Control Strategies in Public Health",
"Vectors in Physics: From Arrows to Equations",
]
十个文档。"search"和"vector"这些词在它们中出现在非常不同的上下文中。完美的语料库,用于展示BM25出错的地方和miniCOIL正确的地方。
10.3 构建BM25索引
from rank_bm25 import BM25Okapi
def build_bm25(documents):
tokenized = [doc.lower().split() for doc in documents]
return BM25Okapi(tokenized)
def bm25_search(bm25, documents, query: str, n: int = 5):
scores = bm25.get_scores(query.lower().split())
ranked = sorted(enumerate(scores), key=lambda x: -x[1])
return [(documents[i], round(s, 4)) for i, s in ranked[:n]]
简单。快速。上下文盲目。
10.4 构建miniCOIL索引
from qdrant_client import QdrantClient
from qdrant_client import models
def build_minicoil(documents):
client = QdrantClient(":memory:")
client.create_collection(
collection_name="minicoil",
sparse_vectors_config={
"minicoil": models.SparseVectorParams(
modifier=models.Modifier.IDF # 来自实时集合统计的动态IDF
)
},
)
# 为BM25风格长度归一化计算avg_len
avg_len = sum(len(d.split()) for d in documents) / len(documents)
client.upsert(
collection_name="minicoil",
points=[
models.PointStruct(
id=i,
payload={"text": documents[i]},
vector={
"minicoil": models.Document(
text=documents[i],
model="Qdrant/minicoil-v1",
options={"avg_len": avg_len},
)
},
)
for i in range(len(documents))
],
)
return client
def minicoil_search(client, query: str, n: int = 5):
hits = client.query_points(
collection_name="minicoil",
query=models.Document(text=query, model="Qdrant/minicoil-v1"),
using="minicoil",
limit=n,
with_payload=True,
).points
return [(h.payload["text"], round(h.score, 4)) for h in hits]
10.5 运行比较
bm25 = build_bm25(DOCUMENTS)
client = build_minicoil(DOCUMENTS)
query = "vector disease control mosquito"
print(f"Query: '{query}'\n")
print("BM25 results:")
for text, score in bm25_search(bm25, DOCUMENTS, query, n=5):
print(f" [{score}] {text}")
print("\nminiCOIL results:")
for text, score in minicoil_search(client, query, n=5):
print(f" [{score}] {text}")
预期输出:
BM25 results:
[0.6123] Vector Control Strategies in Public Health ← 正确
[0.5891] The Rise of Vector Databases in AI Systems ← 错误
[0.5712] Efficient Vector Search Algorithms... ← 错误
[0.5543] Vectors in Physics: From Arrows to Equations ← 错误
[0.3201] Search Engines: A Technical and Social Overview
miniCOIL results:
[0.8932] Vector Control Strategies in Public Health ← 正确,明显排名第一
[0.2341] Vectors in Physics: From Arrows to Equations
[0.1892] The Rise of Vector Databases in AI Systems
...
BM25返回所有包含"vector"的文档,分数相似,无法区分流行病学和计算机科学。miniCOIL将公共卫生文档清楚地放在顶部,因为"disease," "control," 和 "mosquito"旁边的"vector"的上下文指纹正确匹配。
10.6 第二个查询:内省搜索
query = "searching for inner peace and self discovery"
print("BM25 results:")
for text, score in bm25_search(bm25, DOCUMENTS, query, n=5):
print(f" [{score}] {text}")
print("\nminiCOIL results:")
for text, score in minicoil_search(client, query, n=5):
print(f" [{score}] {text}")
BM25在所有10个文档中对"search"同等对待。miniCOIL看到"search"旁边的"inner," "peace," "self," "discovery",并构建了一个哲学指纹,与语料库顶部的内省文档对齐。
11、miniCOIL在你的技术栈中的位置
miniCOIL不是密集语义搜索的替代品。它是更好的BM25,这意味着它是混合检索系统中正确的词法组件。
理想的生产设置:
用户输入 -> 查询
- 输入:查询
- 分支A(密集):查询 -> 密集模型(例如,BGE、E5) -> 密集向量 -> 密集搜索
- 分支B(稀疏):查询 -> miniCOIL -> 稀疏向量 -> 稀疏搜索
- 融合:(密集结果 + 稀疏结果) -> Qdrant加权RRF融合
- 输出:最终排名结果
这给你两全其美:密集检索用于概念查询,miniCOIL用于带上下文感知的关键字精度,Qdrant的加权RRF(来自1.17)根据你的用例调整每个信号贡献多少。
如果你当前的系统在OpenSearch上使用BM25 + 密集搜索,通往miniCOIL的路径是添加Qdrant作为检索层。在那里运行miniCOIL和你的密集模型。你现有的应用程序逻辑保持原样,只是下面有更好的检索质量。
12、结束语
BM25对于它的作用来说是一个伟大的算法:一个快速、可解释的关键字匹配器。它为搜索行业服务了几十年,并且在很长一段时间内将继续这样做。
但它是为一个"vector"只意味着一件事、"search"只意味着一件事的世界构建的。那个世界在自然语言中不存在。
miniCOIL添加了BM25一直缺失的一个成分:对词在上下文中的含义的理解。不是完整的语义理解,只是足以区分意义。而且它这样做的同时保持稀疏,保持快速,保持与搜索系统多年来构建的BM25评分框架兼容。
公式中的一个额外项。每个词一个4维指纹。突然你的搜索系统停止混淆疾病媒介和数学向量。
那不是魔法。那只是一个设计得非常好的模型。
原文链接: Sparse, Yet Smart: Fixing BM25 with 4D Meaning Vectors | miniCOIL
汇智网翻译整理,转载请标明出处
