模型蒸馏综合指南
掌握模型蒸馏技术,深入了解Llama 3等LLM的实际应用
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
随着大型语言模型(LLM)膨胀到数千亿参数,一个新的挑战出现了:效率问题。
为每个小任务运行像GPT-4这样的大型模型成本太高、速度太慢,而且过于杀鸡用牛刀。
模型蒸馏是解决这一问题的工程方案,将巨型模型的智能压缩到一个更小、更快、更具成本效益的模型中。
在本文中,我将探讨模型蒸馏的工作原理、常见应用和实际实现技巧。
1、什么是模型蒸馏——理解师生框架
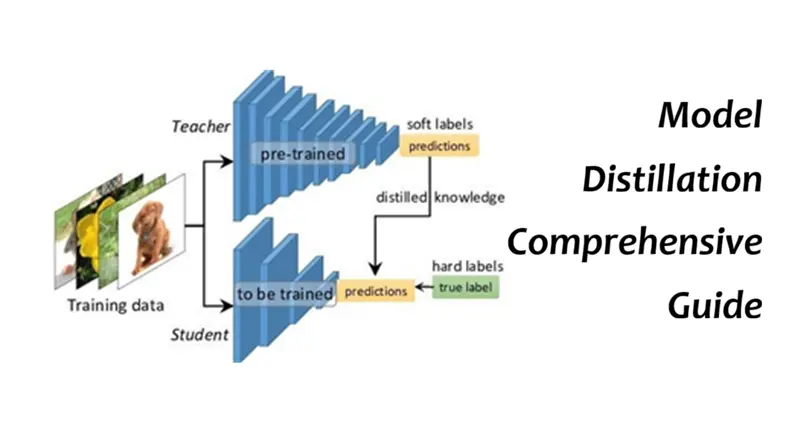
模型蒸馏(也称为知识蒸馏)是深度学习模型工程中的一种压缩技术,其中一个小模型(学生)被训练来重现一个大型预训练模型(老师)的行为和输出。
下图说明了这一概念:
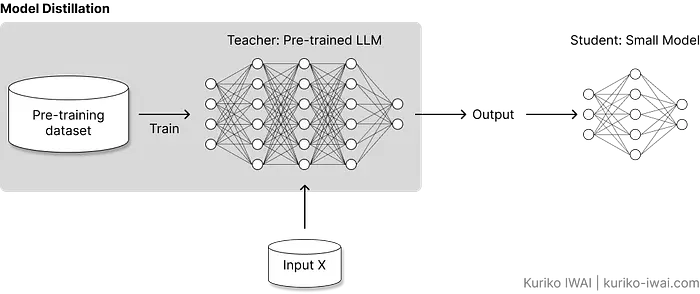
学生模型是根据教师模型的输出(图A中的灰色区域)以及其他取决于蒸馏方案的内部因素进行训练的,而不是从头开始使用原始训练集。
2、工作原理——三种核心蒸馏方案
该技术根据从教师转移到学生的知识部分,进化出三种不同的方法:
- 基于响应:模仿最终答案。
- 基于特征:模仿内部逻辑。
- 基于关系:模仿数据结构。
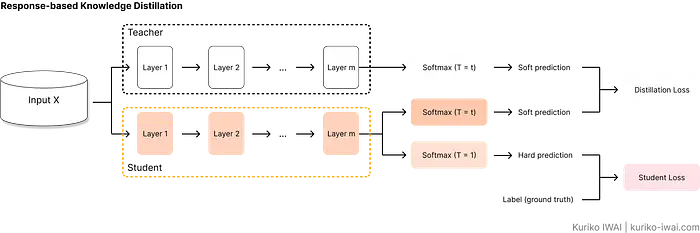
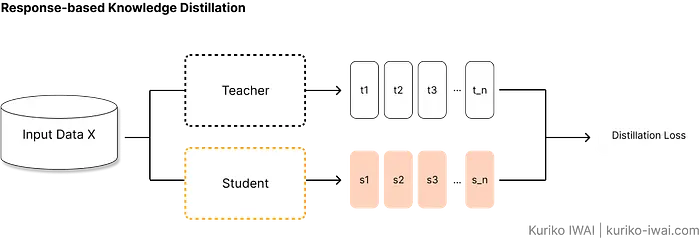
2.1 基于响应的蒸馏
基于响应的蒸馏是最常见的蒸馏形式,学生学习教师模型最后Softmax层生成的概率分布。
下图说明了算法如何评估学生的预测:
目标函数
如图B所示,基于响应的方法在反向传播期间尝试最小化总损失,即蒸馏损失和学生损失的加权平均:
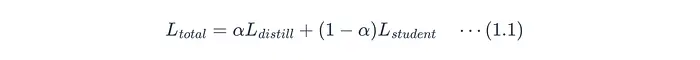
其中:
L_{total}:总损失。α:一个超参数,决定教师指导相对于真实标签数据的相对重要性。L_{distill}:蒸馏损失(图B中的白框)。教师和学生软化输出之间的差异。L_{student}:学生损失(图B中的粉框)。学生预测与真实标签(硬目标)之间的标准交叉熵损失。
该过程有五个明确的步骤:
步骤1. 前向传播
教师模型和学生模型分别执行前向传播,获得logit(原始输出)z_T和z_S。
步骤2. 软化Logit
对z_T和z_S都应用温度参数T来平滑概率分布:
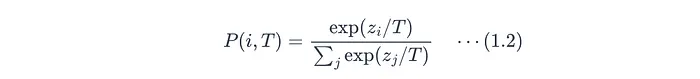
其中:
P(i, T):通过温度T对随机类别i的软化概率。z_i:类别i的logit。T = 1:标准Softmax。T > 1:蒸馏期间使用的软化Softmax。
这一过程使学生模型能够学习错误类别之间的关系,因为随着T增加,概率分布变得更平坦,揭示了教师认为哪些类别与正确类别更相似。
步骤3. 计算蒸馏损失
比较步骤2中的软分布并计算蒸馏损失。
常用方法是使用**KL散度**:
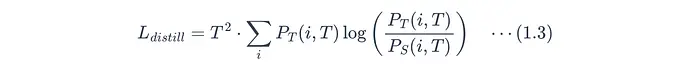
其中:
T:温度参数。P_T(i, T):教师模型生成的第i个类别的Softmax概率,通过温度T调整。计算见公式1.2。P_S(i, T):学生模型生成的第i个类别的Softmax概率,通过温度T调整。计算见公式1.2。
步骤4. 计算学生损失
将学生的原始输出(T=1)与真实标签进行比较。
步骤5. 反向传播
最后,根据公式1.1计算总损失L_{total},仅更新学生的权重。
常见应用
基于响应的蒸馏在分类任务中表现良好。
- 边缘设备:压缩图像分类器(例如,从大型Vision Transformer到小型MobileNet),使其可以在智能手机或物联网传感器上本地运行,无需云端延迟。
- 跨架构迁移:在不同架构之间迁移知识——例如,将CNN(教师)蒸馏到MLP-Mixer(学生)。
- 集成压缩:将10个不同模型(教师)集合的输出平均,然后将其蒸馏成一个单一、快速的学生模型。
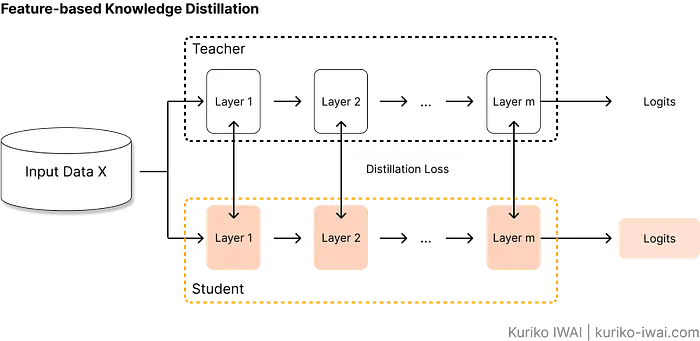
2.2 基于特征的蒸馏(中间层)
基于特征的蒸馏不仅查看最终答案,还使学生模型能够模仿教师的内部表示。
下图说明了算法如何评估学生的预测:
目标函数
核心目标是最大程度减少教师中间特征图与学生对应层之间的差异(图C中的蒸馏损失):
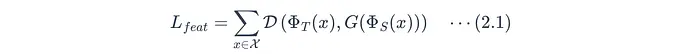
其中:
Φ_T(x):教师模型第n层的激活图。Φ_S(x):学生模型第n层的激活图。G(...):对齐函数,如1x1卷积或线性投影,将学生特征重塑为与教师维度匹配。D(...)**:**距离度量。常用均方误差(MSE),也可以是L1范数或余弦相似度。
与基于响应的蒸馏类似,该技术在反向传播期间尝试最小化公式2.1中的损失,以找到学生模型的最佳内部参数。
特征知识的关键变体
特征蒸馏根据学生模型尝试模仿的内容有三种不同的变体:
- FitNets:尝试模仿教师的隐藏层,利用回归器。
- 注意力迁移(AT):尝试模仿教师的注意力图。
- 因子迁移:尝试从教师特征中模仿有意义的因子,利用编码器-解码器释义器。
主要应用场景
特征蒸馏对于多推理任务很有用,因为它允许学生学习教师的内部逻辑。
其主要应用场景包括:
- 计算机视觉目标检测任务:蒸馏特征图以保留空间信息和对象边界。
- Transformer压缩:将BERT等模型蒸馏到DistilBERT或TinyBERT,通过匹配注意力矩阵和隐藏状态,确保学生保留语言细微差别和上下文关系。
- 跨模态学习:将图像上训练的教师特征蒸馏到深度图或红外数据上训练的学生,帮助学生即使在输入类型有限的情况下也能学习鲁棒特征。
- 小数据迁移学习:允许小型学生模型学习教师的丰富特征层次(在大数据集上预训练),同时避免过拟合。
2.3 基于关系的蒸馏
基于关系的蒸馏将焦点从模型看到什么转移到它如何感知数据的结构。
下图说明了算法如何评估学生的预测:
该方法专注于数据流形的结构,而不是模仿教师的特定层或输出。
例如,在图像分类任务中,本质上学生不是在学习"狗"图像长什么样,而是在学习"狗"离"猫"比离"汽车"更近。
目标函数
关系蒸馏的目标是确保如果教师认为图像A和图像B相似,学生也应该在其自己的特征空间中也将它们映射得更近。
损失函数比较两个模型的相似性矩阵(Gram矩阵)或距离矩阵:
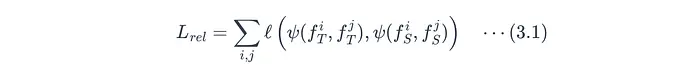
其中:
f_T^i,f_S^i:教师和学生第i个输入的特征嵌入。ℓ(...):惩罚教师相似性得分与学生之间差异的损失函数,例如均方误差(MSE)或Huber损失。ψ(...)**:**相似性函数,例如余弦相似度或欧几里得距离。
关系蒸馏在反向传播期间调整学生模型以最小化公式3.1中定义的损失。
主要应用场景
关系蒸馏允许学生学习数据的底层形状。
而且由于它只计算与教师输出的距离,该方法具有鲁棒性且与模型架构无关。
其主要应用场景包括:
- 图像检索,如图像分类任务或人脸验证。学生学习将狗图像聚在一起,并将它们远离猫图像,例如。
- 零样本/少样本学习:学生可以通过学习已知类别之间的关系,更好地猜测新类别在特征空间中应该位于何处。
- 知识图谱:将实体之间的复杂关系蒸馏到更小、更快的图神经网络(如GNN)中。
3、蒸馏策略
除了蒸馏方案外,还有几个因素决定蒸馏策略:
- 学习源:从教师可用的学习源。
- 结构关系:教师和学生在结构上有多接近。
- 训练方法:学生/教师模型如何训练。
- 任务特定蒸馏。
3.1 学习源
教师的学习源决定了学生能模仿什么。
有两类:
- 黑盒:学生仅从教师的最终文本输出中学习。
- 白盒:学生可以完全访问教师的内部参数和概率。
黑盒
当教师是GPT或Gemini等专有模型时,学生只能通过API访问最终输出。
该方法简单直接,专注于克隆一般预测性能,但学生可能错过教师的推理深度。
- 典型用例:通过API创建小型专业模型。基本聊天机器人微调。
白盒
虽然需要在本地托管教师,但白盒方法允许学生访问教师内部参数以模仿其推理过程。
- 典型用例:将Llama-3 70B蒸馏到本地8B版本。
3.2 结构关系
结构关系指学生和教师模型家族之间的关系,分为三组:
- 同家族:教师和学生属于同一模型家族。
- 跨架构:教师和学生属于不同的模型家族。
同家族
当教师和学生属于同一模型家族时,他们可以实现完美的层对齐,直接将教师的每一层映射到学生。
该方法直接但刚性;应用仅限于特定的模型系列。
- 典型用例:将Qwen-32B蒸馏到Qwen-7B。
跨架构
教师和学生有不同的架构。可能难以收敛。
- 典型用例:将Transformer转换为更快的线性模型。
3.3 训练方法
训练方法的性质决定了学生如何从教师那里学习:
- 离线蒸馏
- 在线蒸馏
- 自蒸馏
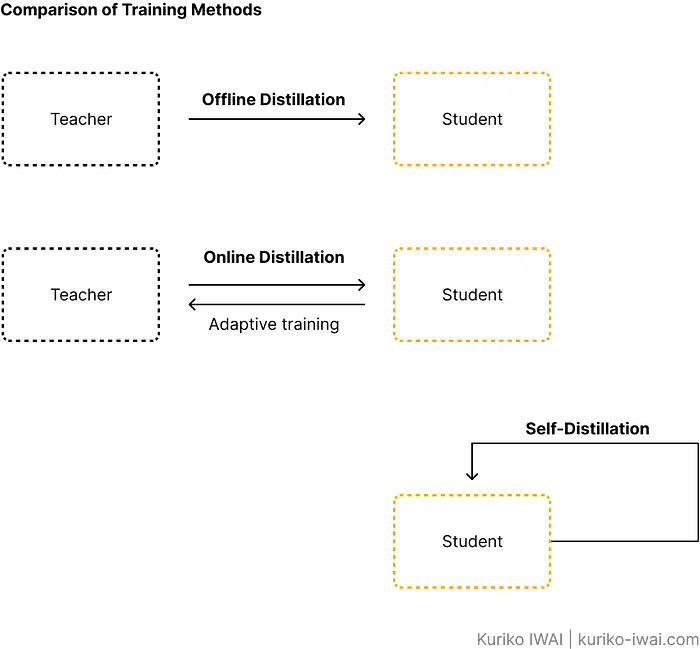
离线蒸馏
离线蒸馏是标准方法,教师一次性创建静态训练集;然后学生在这个数据集上训练。
其学习过程非常稳定,但有时学生无法学习复杂模式。
- 典型用例:标准模型压缩流水线。
在线蒸馏
在线蒸馏同时更新教师和学生;允许教师在训练期间适应学生的学习进度。
当有足够的VRAM和计算资源来训练教师和学生时,该方法具有竞争力。
- 本质用例:研究级联合训练和集成。
自蒸馏
学生通过让其更深层教更浅层来优化自己。
虽然这种方法倾向于强化更深层的错误,但它很方便,因为它不需要任何教师模型。
- 典型用例:DeepSeek风格的内部层优化。
任务特定蒸馏
特定架构需要专门的蒸馏逻辑:
- 序列蒸馏:用于NLP(如DistilBERT),学生学习匹配教师的隐藏状态和注意力头。
- 逻辑蒸馏:用于强化学习或推理任务,学生模仿教师的策略或价值函数。
4、实战模型蒸馏——将GPT-4o蒸馏到Llama 3-1B
在本节中,我将把一个大型GPT-4o模型蒸馏到一个小型学生模型Llama 3-1B,用于边缘设备应用。
蒸馏遵循离线、响应知识蒸馏模式。由于我们无法访问GPT-4o的内部权重,我将其输出蒸馏以生成高质量的指令数据集,然后对学生模型进行SFT。
该过程遵循四个主要步骤:
- 步骤1: 提示GPT-4o总结50,000份法律简报,并附带详细解释。
- 步骤2: 收集教师的输出作为真实标签。
- 步骤3: 使用步骤2中的真实标签数据对学生(Llama 3-1B)进行微调。
- 步骤4: 学生执行推理。
步骤1. 提示Gemini 3.1
第一步是调用Gemini 3.1 API生成输出:
from openai import OpenAI
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
queries = ["Legal text A...", "Legal text B..."]
teacher_outputs = [summarize_with_gpt4o(q) for q in queries]
步骤2. 收集教师输出
教师的输出被结构化并保存在JSON文件中:
import json
dataset = []
for i, (original, summary) in enumerate(zip(queries, teacher_outputs)):
dataset.append({"id": i, "input": original, "teacher_summary": summary })
with open("teacher_data.json", "w") as f:
json.dump(dataset, f)
步骤3. 微调Llama 3-1B
使用步骤2中的数据集,对学生模型Llama 3-1B进行微调:
from trl.trainer.sft_trainer import SFTTrainer
from transformers import TrainingArguments, AutoModelForCausalLM, AutoTokenizer
# load student model and its corresponding tokenizer
model_id = "meta-llama/Llama-3.2-1B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
# instantiate sft trainer
trainer = SFTTrainer(
model=model,
train_dataset=teacher_outputs, # loaded from step 2
processing_class=tokenizer,
args=TrainingArguments(
output_dir="./llama-3-legal-distilled",
per_device_train_batch_size=4,
gradient_accumulation_steps=4,
learning_rate=2e-5,
num_train_epochs=3,
save_steps=100,
logging_steps=10,
bf16=True
),
)
# train the student model on the ground truth teacher_output
trainer.train()
步骤4. 执行推理
最后,学生执行推理以评估结果:
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# trained model
model = trainer.model.to(device)
query = "The petitioner claims a violation of the 4th Amendment..."
inputs = tokenizer(f"Summarize: {query}", return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=200)
现在,这个蒸馏后的1B模型可以达到教师质量的95%,但运行速度快100倍。
5、结束语
模型蒸馏将LLM工程的焦点从"我们能做多大?"转变为"我们能做多小?"
通过有效地将知识从教师转移到学生,AI应用不仅可以智能,而且可持续和快速。
何时转向:蒸馏 vs RAG vs 微调
虽然模型蒸馏是将大型模型缩小到更小、更快版本的强大方法,但它并不总是最佳选择。
在以下五种情况下,其他调整方法(如微调或RAG)更优:
1. 高风险领域专业化——选择微调
蒸馏会导致深度或细微推理的丧失。
虽然蒸馏模型模仿教师的风格,但它可能会失去专业领域所需的精确事实。
全参数或参数高效微调(PEFT)更适合嵌入特定领域知识。
- 用例:医学诊断、法律合同分析或专业工程。
2. 频繁数据更新——选择RAG或上下文工程
蒸馏是一个静态过程;如果信息发生变化,学生必须重新蒸馏,这在计算上很昂贵。
**检索增强生成(RAG)**是更好的选择,因为它允许模型访问新数据而无需任何重新训练。
- 用例:实时新闻机器人、股票市场分析或内部公司wiki。
3. 安全关键应用——选择微调或RLHF
研究表明,蒸馏(尤其是基于logit的)可能使安全护栏退化高达50%。
学生优先模仿性能而不是遵守安全约束。
使用安全标签数据进行直接微调对于维护护栏更可靠。
- 用例:具有严格合规性的面向公众的AI。
4. 计算访问有限——选择PEFT(LoRA或QLoRA)
蒸馏是一种高成本方法,因为大型教师模型必须生成数百万个合成标签,然后从头训练学生。
LoRA或QLoRA更便宜更快,因为它只调整大型模型所有参数的一小部分(<1%)。
- 用例:GPU访问受限的初创公司或研究人员。
5. 弥补巨大能力差距——选择多阶段微调
如果教师和学生之间的差距太大,学生无法有效学习,因为它无法理解教师的复杂性。
在这些情况下,在高质量标签数据上进行**监督微调(SFT)**比试图强迫小型模型模仿大型模型产生更好的结果。
- 用例:尝试将400B参数模型直接蒸馏到1B参数模型。
原文链接: Model Distillation Guide: Compressing LLMs for Edge Efficiency
汇智网翻译整理,转载请标明出处
