多租户智能体:比我想的难
一份经过实战检验的企业级 Agent 编排蓝图,从微服务拆分到沙箱隔离再到 Kubernetes 生产部署。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
如果你正在构建可以执行代码、调用 API 或访问文件系统的 AI Agent,你一定已经遇到了 Agent 基础设施的核心矛盾:如何给 AI Agent 真正的工具,而不把王国的钥匙交给它?
对于笔记本电脑上的单个开发者来说,这是可以管理的。但是,当你需要支持多个团队、多个租户或多个客户时——每个都运行自己的 Agent 会话,拥有自己的密钥和工具权限——这个问题就变成了一个基础设施设计挑战。
在过去的几个月里,我构建并实战检验了一个处理这种情况的生产架构。在这篇文章中,我将分享这些模式、权衡和惨痛教训,以便你可以将其应用于自己的部署。这不是理论——这是一份在 Kubernetes 上运行多租户 Agent 工作负载的实战指南。
让我们从底层开始构建。
1. 核心原则:拆分 Agent 生命周期
团队在部署 AI Agent 时犯的最大错误是构建单体应用。他们将入站 API 处理程序、LLM 客户端、会话存储、工具执行引擎和调度逻辑塞进一个服务中。这对演示有效,但在规模上会崩溃。
相反,将 Agent 生命周期拆分为五个不同的服务,每个服务都有单一职责:
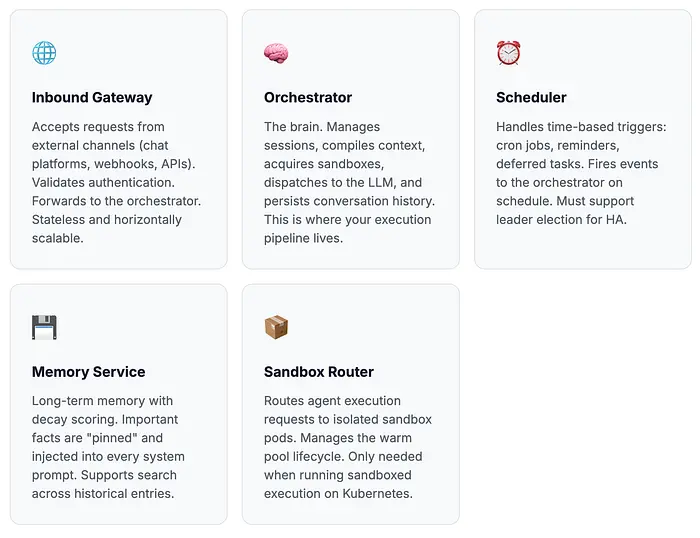
为什么是五个服务而不是三个或七个?这种拆分映射到 Agent 生命周期的自然边界:入口(Gateway)、编排(Orchestrator)、时间(Scheduler)、状态(Memory)和隔离(Sandbox)。每个都可以独立扩展、部署和调试。
💡 专业提示:资源效率:
如果你用 Rust 或 Go 等系统语言构建这些服务,整个控制平面可以在 2 vCPU 和 2GB RAM 以下运行。你的入站网关可能只需要 32-128MB 内存。与基于 Java 或 Python 的替代方案相比,这非常精简,意味着你的基础设施成本主要由 LLM API 调用决定——而不是你自己的控制平面。
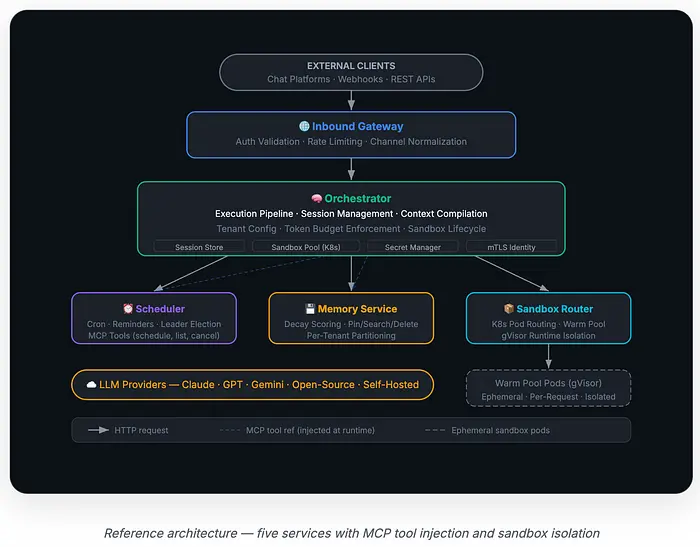
2. 架构概览
以下是五个服务如何连接的。箭头表示服务之间的 HTTP 调用;虚线表示编排器注入到每个 Agent 会话中的 MCP(模型上下文协议)工具引用:
3. 执行流水线:消息到达时会发生什么
编排器的核心是一个确定性执行流水线。每个 Agent 请求——无论是用户消息触发、Webhook 调用还是定时 Cron 任务——都经过相同的步骤序列。这种一致性是不可妥协的;正是它防止了安全绕过、过时上下文和会话损坏。
以下是我推荐的流水线:
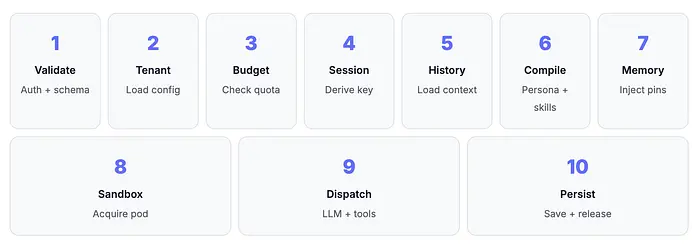
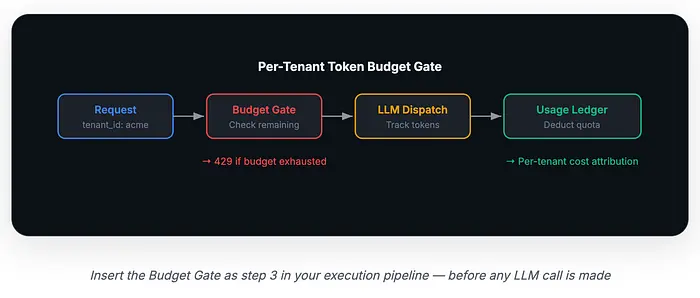
注意第 3 步——预算检查。在任何多租户系统中,你需要在向 LLM 分发请求之前执行每个租户的令牌预算。如果你在 LLM 调用之后检查配额,一个失控的租户已经消耗了你共享的 API 配额。我是在惨痛教训中学到这一点的。
⚠️ 顺序很重要
身份验证必须在租户解析之前进行。租户解析在会话派生之前。会话加载在上下文编译之前。如果你打破了这个顺序,就会创建微妙的安全漏洞,下游步骤会使用过时或未授权的上下文进行操作。使流水线保持顺序和确定性。
3.a 会话键设计
你的会话键格式决定了对话的范围。我推荐一种可组合的格式:
[tenant:]channel:chat_id[:thread:thread_id][:sender_id]
这种单一格式无需单独的代码路径即可处理多种隔离模式:

4. 多租户:做好隔离
多租户是共享 Agent 基础设施中最难的问题。你需要在四个维度上进行隔离:
4.a. 配置隔离
每个租户应该有一个专用配置文件,指定其 LLM 模型、系统人设、活动技能、会话范围和令牌限制。将这些存储在类似 /data/tenants/{tenant_id}/config.json 的路径中,并使用可配置的 TTL(生存时间)缓存在内存中——例如 60 秒。TTL 是指缓存值在被认为"新鲜"的持续时间,过期后需要重新读取。你的服务从磁盘读取配置一次,在接下来的 60 秒内从内存提供服务,然后在下一次请求时重新读取。这保持了快速的性能,同时仍能在合理的时间窗口内获取配置变更。
{
"model": "claude-sonnet-4-5-20250929",
"persona": "You are a helpful engineering assistant...",
"skills": ["code-review", "jira-integration"],
"session_scope": "per_user",
"max_tokens_per_turn": 8096,
"monthly_token_budget": 10000000
}
4.b. 会话隔离
会话数据必须按租户分区。在云对象存储上,使用类似 gs://{bucket}/tenants/{tenant_id}/sessions/ 的前缀结构。永远不要仅依赖应用层逻辑——使用存储级别的路径隔离,这样即使代码中有 bug,也不会将一个租户的对话历史泄露给另一个。
4.c. 内存隔离
如果你构建一个长期记忆服务(你应该这样做),从每个请求中派生租户上下文,而不是从部署时的环境变量。一个常见的反模式是在部署时设置 MEMORY_TENANT_ID=default,并希望运维人员记得在每个部署中更改它。相反,在请求头中传递租户 ID,并在存储层按租户分区内存存储。
4.d. 令牌预算执行
在共享基础设施中,一个嘈杂的租户可能耗尽所有人的 LLM API 配额。在你的编排器执行流水线内部实施每租户令牌预算门控:
5. 沙箱隔离:预热池模式
当你的 Agent 可以执行任意代码——运行 shell 命令、调用 API、写入文件——你需要超越标准容器的执行隔离。在生产中有效的模式是 gVisor 沙箱化的 Kubernetes Pod 的预热池。
5.1 为什么选择 gVisor?
标准容器共享宿主机内核。一个容器中的内核漏洞会危及整个节点。gVisor 插入一个用户空间内核(称为"Sentry"),在系统调用到达宿主机之前拦截它们。这提供了强隔离边界,而无需完整硬件虚拟机的运维开销。

对于大多数企业部署,gVisor 是最佳平衡点。它由 Kubernetes 集群运维管理,支持自动扩缩容,并提供有意义的隔离。将 Firecracker 保留用于超高安全合规要求。
5.2 预热池状态机
在每个请求上冷启动沙箱 Pod 会增加 5-15 秒的延迟。相反,维护一个预启动的空闲 Pod 预热池。当请求到达时,你"获取"一个预热的 Pod(将其状态更改为 Active),将 Agent 会话分派给它,完成后将其"释放"回预热状态:
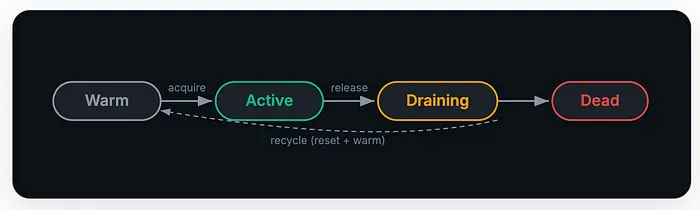
使用 Kubernetes 标签跟踪 Pod 状态(sandbox-state=warm、sandbox-state=active),并实现会话亲和性,使同一对话的后续消息路由到同一个 Pod。
⚠️ 关键:回收 Pod 中的跨租户数据泄露
当预热池 Pod 从租户 A 回收到租户 B 时,几类状态可能会存活并跨租户泄露。这是一个租户数据泄露漏洞。攻击面包括:
- 工作区文件——租户 A 创建的任何文件、临时数据或工作区制品都保留在 Pod 的文件系统上。
- 环境变量——如果你的编排器将租户特定的密钥(API 密钥、数据库凭据)作为环境变量注入,租户 B 的 Agent 可以运行
printenv读取它们。永远不要将密钥作为环境变量注入——使用临时卷挂载的密钥文件,或运行时从保险库获取。 - 后台进程——如果租户 A 的 Agent 启动了一个长时间运行的脚本,它可能在租户 B 的会话开始时仍在运行。在回收时,向所有非系统进程发送
SIGKILL。 - 已安装的包和系统修改——如果 Agent 运行
pip install或npm install,这些包会持久化在容器的可写层中。使用只读根文件系统,仅通过emptyDir将工作区目录设为可写。 - 网络连接池——到外部 API 或数据库的开放连接可能保留在池中,并以租户 A 的认证上下文被重用。在释放时排空所有连接。
- Shell 历史和凭据缓存——Bash 历史(
~/.bash_history)、SSH 已知主机和 git 凭据缓存在执行期间累积。
缓解选项(选择一种):
- 销毁并替换(最安全)——不回收 Pod。会话结束时完全删除 Pod,并在后台启动新的替代品。没有状态能存活。如果你异步预创建替代品,用户不会注意到补充延迟。
- 释放时擦除文件系统(实用)——在将 Pod 转回"Warm"之前,擦除工作区(
rm -rf /workspace/*),清除/tmp,终止所有进程,重置环境变量,并排空连接。比完全替换更快,但需要相信你的擦除在上述所有攻击向量上是全面的。 - 临时卷(两全其美)——将工作区挂载为 Kubernetes
emptyDir卷。当 Pod 被删除或重启时,kubelet 会自动擦除该卷。结合选项 1,这为你提供了基础设施级别的清理保证,无需自定义脚本。
对于受监管环境,推荐组合是选项 1 + 3 + 只读根文件系统。对于成本敏感的部署,如果结合 gVisor 隔离和彻底的进程清理,选项 2 是可接受的。
6. 通过 MCP 暴露工具,而非原生代码
这可能是最有影响力的设计决策。与其将工具直接构建到 Agent 二进制文件中,不如将每个能力作为 MCP 服务器暴露——一个 Agent 通过 HTTP 调用的轻量级 JSON-RPC 2.0 端点。
你的编排器的上下文编译器应在运行时将 MCP 服务器引用注入每个 Agent 会话:
// Context Compiler injects these into every SessionRunRequest
mcp_servers: [
{ name: "memory", url: "http://memory-svc/mcp", tools: 7 },
{ name: "scheduler", url: "http://scheduler-svc/mcp", tools: 11 },
{ name: "channels", url: "http://gateway-svc/mcp", tools: 4 }
]
这给你带来三个巨大的优势:
- 网络隔离——工具调用是跨越网络边界的 HTTP 请求,而不是本地函数调用。你可以对每个工具调用进行防火墙、限流和审计。
- 独立部署——无需重新部署编排器或 Agent 沙箱即可发布新工具。
- 可组合性——不同的租户可以在不更改代码的情况下获得不同的 MCP 工具集。租户 A 获得代码执行工具;租户 B 仅获得只读搜索工具。
7. 安全态势:实用检查清单
以下是我在生产部署中使用的安全检查清单。其中一些是基本要求;其他是团队通常会跳过然后后悔的:
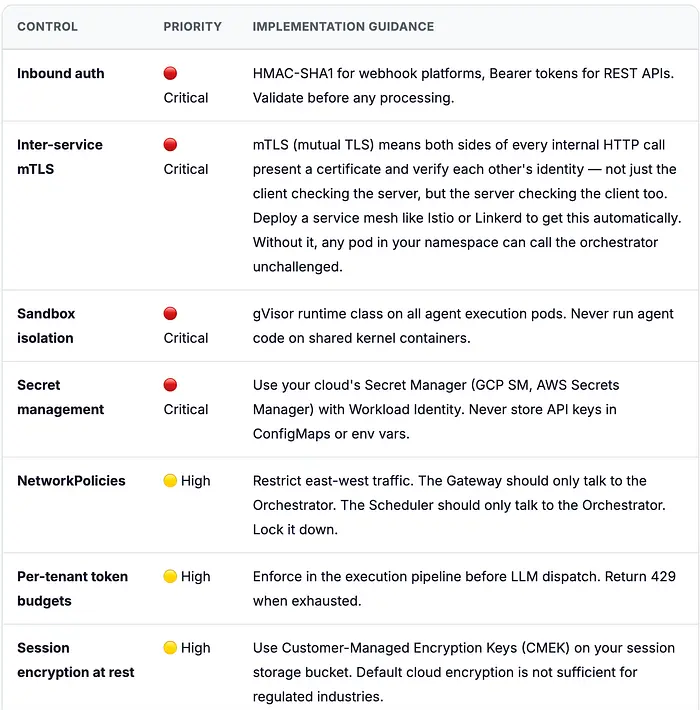

💡 最常被跳过的控制:
服务间 mTLS(双向 TLS)。大多数团队在网关验证入站请求,但然后假设集群内的所有流量都是可信的。这是危险的错误。在标准 HTTP 中,只有客户端验证服务器的身份。
使用 mTLS,双方都提供加密证书——因此编排器可以验证"这个请求确实来自网关,而不是一个恶意 Pod"。否则,你命名空间中任何被攻破或错误配置的部署都可以直接 POST 到编排器并触发 Agent 执行。服务网格(Istio、Linkerd)透明地添加 mTLS——无需代码更改,只需一个安装命令——并永久解决这个问题。
8. 调度器设计:领导者选举陷阱
如果你构建一个调度器服务(定时触发的 Agent 运行需要它),你会遇到一个经典的分布式系统陷阱:扩展调度器会产生重复的任务触发。
解决方案是领导者选举。在任何时候,只有一个调度器副本应该是活动的"计时器"。Kubernetes Lease API 原生提供了这个功能,无需外部依赖:
// Pseudo-code: K8s Lease-based leader election
let lease = kube::Api::<Lease>::namespaced(client, "your-namespace");
loop {
if try_acquire_lease(&lease, "scheduler-leader", pod_name).await? {
// I'm the leader — tick and fire due jobs
tick_and_fire_due_jobs().await;
} else {
// Standby — wait and retry
sleep(Duration::from_secs(15)).await;
}
}
还要实现一个最小触发间隔(例如 5 秒)作为去重保护。如果领导权转换发生在计时中间,你不希望同一个任务被触发两次。
9. 存储和状态:云原生后端
每个有状态服务(编排器会话、调度器任务、记忆条目)都应支持两种存储后端:
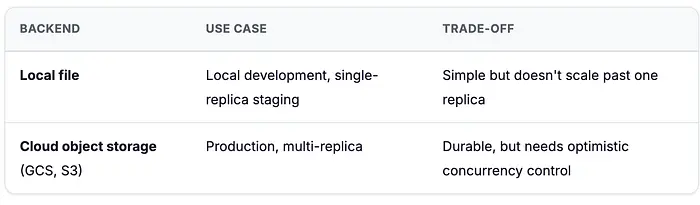
对于云存储,实现乐观并发控制。以下是它解决的问题:假设两个编排器副本几乎同时收到同一对话的消息。两者都读取会话文件,两者都追加新消息,然后两者都写回。第二次写入默默地覆盖了第一次——那条消息永远丢失了。这被称为丢失更新。
修复依赖于代数(GCS)或 ETags(S3)——每次对象更新时都会改变的版本戳。流程如下:
1. Pod A reads session.json → gets generation = 5
2. Pod B reads session.json → also gets generation = 5
3. Pod A writes with precondition "only if generation == 5"
→ ✅ Succeeds! Generation is now 6.
4. Pod B writes with precondition "only if generation == 5"
→ ❌ FAILS! Generation is 6, not 5.
5. Pod B retries: re-reads (generation=6), merges, writes "only if generation == 6"
→ ✅ Succeeds!
核心思想:你永远不锁定文件——这就是为什么它被称为"乐观的"。你假设不会发生冲突,如果在写入时发生了就检测到。在冲突时最多重试 3 次。这种方法轻量级,适用于云规模,不需要任何外部锁定服务。
💡 GCS FUSE 技巧
如果你的记忆服务使用基于文件的存储,并且想在 Kubernetes 上运行而不修改代码,可以通过 GCS FUSE 挂载 GCS 存储桶。
你的服务写入看起来像本地文件系统的内容,但数据落在持久的云存储中。零代码更改。
10. Kubernetes 生产部署
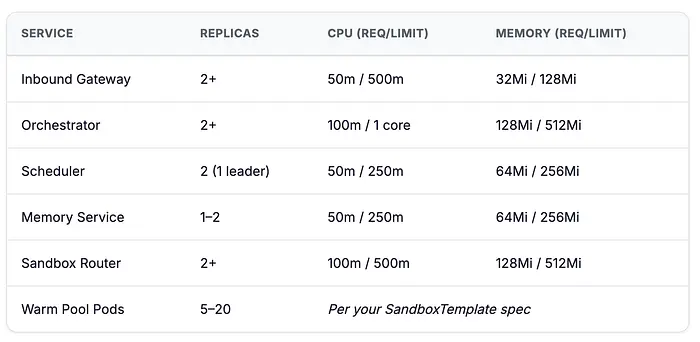
资源规划
如果你的服务是用编译语言(Rust、Go)构建的,你会惊讶于你需要的资源如此之少:
多区域考虑
对于生产 SaaS,将无状态服务(Gateway、Orchestrator、Sandbox Router)部署在至少两个区域,放在全球 HTTP(S) 负载均衡器后面。有状态服务(Scheduler、Memory)可以以主被动模式运行,配合跨区域存储复制。
不要犯把所有东西放在单个区域的错误。区域性的云故障会同时使所有租户瘫痪。
CI/CD 流水线
这些服务的推荐流水线:

在构建时使用特性标志来包含云特定功能(例如 GCS 存储、K8s 沙箱池)。你的本地开发构建应该可以使用基于文件的存储和内存沙箱——不需要云依赖。
11. LLM 提供商抽象
不要硬编码单一的 LLM 提供商。在干净的接口后面,支持多个后端,这样你可以切换提供商、使用回退链或让租户选择自己的模型:

通过配置按名称显式解析提供商——而不是根据环境中碰巧存在哪些凭据。这避免了当环境中有多组凭据可用时的混淆。
12、关键要点
- 拆分为五个服务——Gateway、Orchestrator、Scheduler、Memory、Sandbox。每个独立扩展。
- 使执行流水线确定性——Auth → Tenant → Budget → Session → Context → Sandbox → LLM → Persist。永远不要跳过步骤。
- 使用 gVisor 隔离,而不仅仅是容器——标准容器共享宿主机内核。gVisor 提供有意义的隔离,而无需完整虚拟机的运维成本。
- 使用预热池——预启动沙箱 Pod 以避免 5-15 秒的冷启动。实现 Warm → Active → Draining → Dead 状态机。
- 通过 MCP 服务器暴露工具——网络隔离、独立部署、可审计。永远不要将工具嵌入 Agent 二进制文件中。
- 在 LLM 分发之前执行每租户预算——而不是之后。令牌预算执行是一个流水线步骤。
- 部署服务网格——内部 mTLS 是最常被跳过且最具影响力的安全控制。
- 从隔离边界开始,然后添加 LLM 能力。 困难的部分不是让 Agent 变得智能——而是让基础设施变得可信。
我在这里概述的架构是在生产中运行多租户 AI Agent 基础设施的结果。本指南中的所有内容并不都适用于你的用例——你的规模、合规要求和团队规模都会影响权衡。但这些模式是可移植的:服务拆分、确定性流水线、沙箱隔离和基于 MCP 的工具将无论你的云提供商或 LLM 供应商如何,都能很好地为你服务。
原文链接: How to Deploy Multi-Tenant AI Agent Infrastructure That Actually Scales
汇智网翻译整理,转载请标明出处
