我的多智能体数据管道
我构建了多个AI智能体来自动化大约 80% 的数据管道胶水工作。不是完全自主。不是炒作。只是围绕无聊、可重复任务的紧密范围的自动化。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署 | Tripo 3D | Meshy AI
一个新的 CSV 会落在 S3 中。我会下载它,扫描缺失的列,将其与我们的规范模式进行比较,编写一个快速转换脚本,健全性检查聚合,然后为利益相关者起草一个简短摘要。这些都不是智力困难的。只是重复的。到了周四,我会为不同的来源再次这样做。
工作并不复杂。它是令人疲惫的。认知成本不在于编写代码——而在于一遍又一遍地做出相同的小决策。
最终,我停止优化 SQL 查询,开始优化决策循环。
这是可重现的多代理 AI 工作流程演练,我构建了它来自动化大约 80% 的数据管道胶水工作。不是完全自主。不是炒作。只是围绕无聊、可重复任务的紧密范围的自动化。
1、问题:人类胶水工作
在自动化之前,我的每周管道是这样的:
- 验证新数据(模式漂移、必需列)
- 将新字段映射到规范模式
- 建议简单的转换
- 运行异常检查
- 编写简短摘要报告
每周花费时间:~10 小时。
不是因为系统脆弱。因为人类充当了胶水。
消耗不是技术困难。它是:
- 重新评估模式不匹配
- 决定
total_amt是否映射到total_amount - 重新检查 17% 的激增是合法的还是损坏的
- 重复编写类似的报告
这是一种结构化的、可重复的决策制定,代理系统实际上有意义的地方。
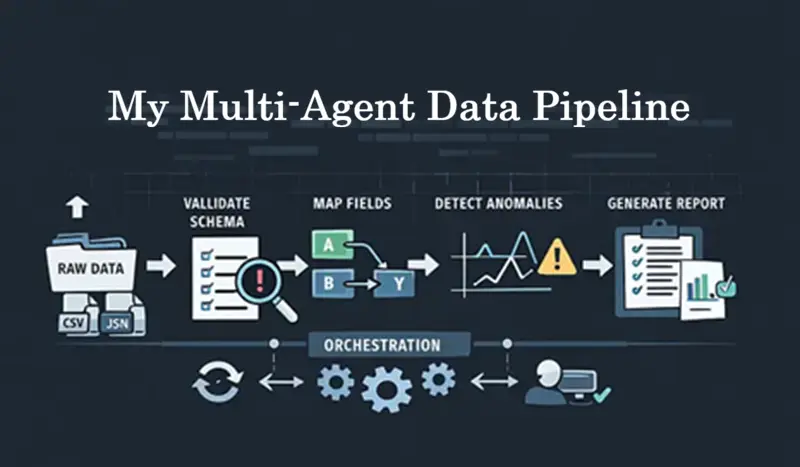
2、架构:小代理,清晰边界
我没有构建"超级代理"。我构建了具有窄责任的小代理。
- 摄取验证代理
- 模式映射代理
- 异常检测代理
- 报告代理
没有代理拥有工作流程。
每一个:
- 接受结构化输入
- 产生严格验证的 JSON
- 具有单一责任
ASCII 图表:多代理流程
[Raw Data]
|
[Validator Agent]
|
[Schema Agent]
|
[Anomaly Agent]
|
[Report Agent]
每个阶段都是确定性的。编排层决定顺序和重试。
这不是自主混乱。它是结构化流程。
3、编排器:无混乱的控制
编排器故意无聊。
它处理:
- 排序
- 重试
- 模式验证
- 升级
这里是 Python 中的简化版本:
def run_pipeline(data):
validated = validator.run(data)
mapped = schema_agent.run(validated)
anomalies = anomaly_agent.run(mapped)
report = reporter.run(anomalies)
return report
在生产中,每个 .run():
- 验证 JSON 模式
- 应用重试策略
- 记录提示 + 响应
- 跟踪延迟
编排器从不委派控制。代理不互相调用。所有交接都是明确的。
代理 1:摄取验证器
责任:
- 检查必需列
- 检测模式漂移
- 标记格式错误的记录
它接收:
{
"columns": ["order_id", "total_amt", "created_at"],
"sample_rows": [...]
}
结构化提示风格:
prompt = f"""
You are a data ingestion validator.
Required columns: {required_columns}
Incoming columns: {incoming_columns}
Return JSON:
{{
"missing_columns": [],
"unexpected_columns": [],
"is_valid": true|false
}}
"""
使用严格模式解析:
from pydantic import BaseModel
class ValidationResult(BaseModel):
missing_columns: list[str]
unexpected_columns: list[str]
is_valid: bool
response = llm.invoke(prompt)
result = ValidationResult.model_validate_json(response)
如果 is_valid 为 false,管道停止。
没有猜测。没有自动修复。
代理 2:模式映射代理
责任:
- 将传入列映射到规范模式
- 建议转换
示例输出:
{
"mappings": {
"total_amt": "total_amount"
},
"transformations": {
"total_amount": "float(value)"
},
"confidence": 0.92
}
护栏:
- 规范模式是固定的并注入
- 代理不能发明新的规范字段
- 置信度 < 0.8 触发人工审查
示例调用:
mapping = schema_agent.run({
"incoming_columns": incoming_columns,
"canonical_schema": canonical_schema
})
if mapping.confidence < 0.8:
escalate_to_human(mapping)
这是幻觉早期发生的地方。护栏修复了它。
代理 3:异常检测代理
这个代理有两层:
- 统计预检查(代码)
- 推理层(LLM)
首先,确定性阈值:
def precheck(metrics):
alerts = []
if metrics["daily_revenue_change"] > 0.25:
alerts.append("Revenue spike > 25%")
return alerts
然后上下文推理:
prompt = f"""
Metrics:
{metrics}
Existing alerts:
{alerts}
Explain whether anomalies appear legitimate.
Return JSON:
{{
"summary": "",
"severity": "low|medium|high",
"confidence": 0-1
}}
"""
回退行为:
result = anomaly_agent.run(data)
if result.confidence < 0.7:
result.severity = "needs_review"
代理从不单独决定。它在确定性检查之上分层推理。
4、故障处理和护栏
每个边界验证输出。
ASCII 图表:护栏循环
[Agent Output]
|
Validate
|
Retry / Escalate
策略:
- 格式错误的 JSON 自动重试 2 次
- 严格的 Pydantic 验证
- 低置信度升级
- 版本化提示
- 记录输入 + 输出
这将脆弱的提示变成了受控组件。
5、之前 vs 之后:真正的影响
这是部署此 AI 数据管道自动化后发生的变化:
- 手动时间:10 小时/周 → 2 小时/周
- 模式映射错误:~12% → ~3%
- 审查周期:从 3 轮减少到 1 轮
- 吞吐量:每月上线的数据源约多 2 倍
最大的收获不是速度。它是一致性。
系统每次都以相同的方式做出相同的决策。
6、碰到了哪些问题
这并不顺利。
早期失败:
- 幻觉规范字段
- 过于自信的映射
- 列名奇怪时的提示脆弱性
- JSON 格式漂移
修复:
- 显式模式注入
- 置信度评分
- 严格的 JSON 解析
- 确定性预检查层
- 代理之间的硬边界
只有当我们像不可靠的微服务一样对待代理时,系统才变得稳定。
7、为什么这对管道有效
管道是结构化的。
它们有:
- 已知的模式
- 重复的任务
- 可验证的输出
- 确定性阶段
这使它们成为多代理 AI 工作流的理想选择。
当任务模糊且无界时,代理系统失败。当自主权受到限制且输出可验证时,它们成功。
这是应用于无聊决策的可重现 AI 工作流程代码。
8、这会失败的地方
这种方法在以下情况下崩溃:
- 高歧义领域(法律解释)
- 有责任的高度合规工作流程
- 超低延迟系统
- 实时事务处理
它不适用于创造性推理或开放式判断。
它是用于结构化胶水工作。
9、代理的可观测性
没有可观测性的代理变得无法调试。
ASCII 图表:可观测性层
[Agent] -> [Logs]
-> [Metrics]
-> [Trace]
我们跟踪什么:
- 提示版本
- 输入负载哈希
- 输出 JSON
- 每个代理的延迟
- 重试计数
- 升级率
我们还分类错误:
- 解析失败
- 低置信度标志
- 漂移检测不匹配
这使系统可维护。
10、使其工作的设计原则
三件事很重要:
- 小代理
- 确定性编排
- 在每个边界验证
没有代理拥有管道。
没有隐式链接。
没有静默失败。
这不是关于 LLM 代理后端炒作。它是关于减少结构化系统中的重复决策制定。
11、最终反思
工作流程并不消除工程师。
它消除了工程师必须第五十次决定 total_amt 可能意味着 total_amount 的部分。
这里最强大的自动化不是智能。
它减少人类必须做出相同决策两次的次数。
原文链接: How I Built a Multi-Agent AI Workflow That Automates 80% of My Data Pipeline
汇智网翻译整理,转载请标明出处
