NanoBot 架构拆解
这是一篇纯粹的架构拆解。没有"2 分钟部署"指南。没有"开箱即用"演示。我们要检查的是 NanoBot 如何使用最小骨架来运行 Agent——并使其可读、可修改和可控。
AI编程/Vibe Coding 遇到问题需要帮助的,联系微信 ezpoda,免费咨询。
当你将 430,000 行代码与 4,000 行代码放在一起比较时,一个自然的问题出现了:什么被删除了?什么被保留了?
这是一篇纯粹的架构拆解。没有"2 分钟部署"指南。没有"开箱即用"演示。我们要检查的是 NanoBot 如何使用最小骨架来运行 Agent——并使其可读、可修改和可控。
让我们从仓库开始:https://github.com/HKUDS/nanobot
1、为什么这很重要:对能力的控制
许多人想要"可用的 Agents",但害怕它们变成黑盒子——不知道何时调用了工具、哪些文件被修改了,或者为什么执行突然偏离了方向。
NanoBot 采用直接的方法:首先将 Agent 构建为最小可行运行时。消息到达 → 上下文组装 → LLM 决策 → 工具执行 → 结果回填 → 响应返回。
它追求三件事:
- 您可以端到端读取整个管道(小代码库)
- 您可以准确定位问题发生的位置(清晰的边界)
- 您可以安全地逐步添加能力(可交换的组件)
2、我的结论
NanoBot 的工作以工程为中心:将 Agent 分解为管道,使用 MessageBus 进行解耦,使用 AgentLoop 驱动核心循环,并通过 Cron/Heartbeat 实现主动性。
最值得学习的不是"它连接到 Telegram/WhatsApp/Slack"——而是这个最小骨架:
- 入口:Channels 将不同的 IM 消息统一为 InboundMessage
- 中心:MessageBus 解耦"接收消息"和"生成响应"
- 核心:AgentLoop 驱动 LLM ↔ Tools 循环
- 上下文:ContextBuilder 将规则/性格/工具描述/技能/记忆组装到系统提示中
- 可扩展性:ToolRegistry + JSON Schema 验证将工具变成可注册、可验证的插件
- 主动性:Cron 处理计划任务,Heartbeat 处理周期性唤醒
如果你想构建一个可控的 Agent,这个结构让你以最小的成本关闭循环,然后逐步添加多模型路由、更强的记忆检索、更严格的权限边界和更可靠的审计重放。
3、OpenClaw 给你产品,NanoBot 给你骨架
如果你研究过 OpenClaw,你会感觉到定位差异。这是一个清晰的细分:
一句话总结:OpenClaw 感觉更像"生产就绪产品",NanoBot 感觉更像"学习和复制的最小运行时"。
TL;DR
- NanoBot 将 Agent 减少到最基本的循环:消息 → 上下文 → LLM → 工具 → 回填 → 响应
- 它使用 MessageBus 进行解耦:Channels 只处理发送/接收,AgentLoop 只处理"思考和执行"
- AgentLoop 是标准的"工具调用循环":LLM 给出工具调用,执行每个调用,将结果作为工具消息回填,LLM 继续
- ContextBuilder 的关键是基于文件的:AGENTS/SOUL/USER/TOOLS/IDENTITY + memory 目录都是版本控制的真相源
- 工具系统不是分散的 if-else:ToolRegistry 统一注册,工具参数使用 JSON Schema 验证,错误收敛为可读字符串
- exec 工具具有粗粒度的安全护栏(危险命令正则表达式阻止 + 可选的工作空间限制),但仍然需要允许列表和审计用于生产
- Session 以 JSONL 格式保存对话历史(易于阅读,易于重放),但默认为
~/.nanobot/sessions,而不是项目工作空间 - Cron/Heartbeat 解决"Agent 在没有人说话时做事情",本质上是向 AgentLoop 提供定时触发器
- README 显示"~4000 行",实际的 nanobot/ 目录总计约 5k 行;差异来自 bridges、channels、cron、tools 和 peripherals 的计数
01 | 正确分类:NanoBot 实际上是什么
将 NanoBot 称为"聊天机器人"低估了它。
更准确的工程描述:一个在你的机器上运行的 Agent Runtime。
它将"对话"升级为"可执行的工作流入口":
- 你从 Telegram/WhatsApp/Slack 发送消息
- LLM 首先决定"是否调用工具、哪些工具、什么参数"
- 工具在本地/受控环境中执行(读/写文件、运行命令、获取网页等)
- 结果回填到 LLM
- 最终答案返回到原始聊天窗口
一旦你稳定了这个管道,其他一切都是附加的。
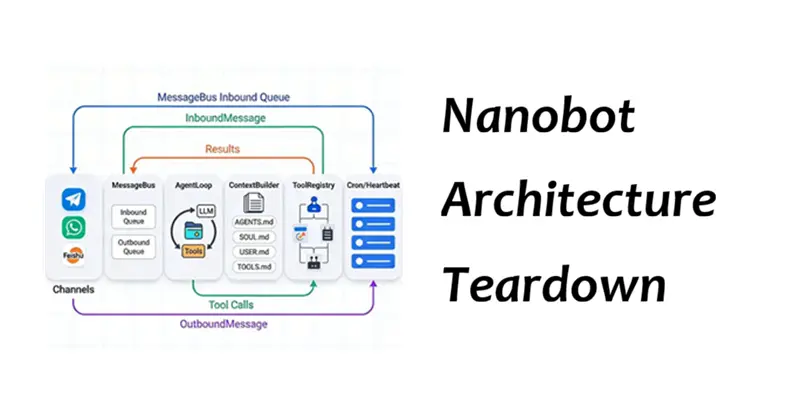
02 | 架构概述:一张图显示数据流
关键不是漂亮的图片——而是每个框都映射到实际的仓库文件:
nanobot/channels/*:通道适配器和启动nanobot/bus/*:消息事件和队列nanobot/agent/loop.py:核心循环nanobot/agent/context.py:系统提示组装nanobot/agent/tools/*:工具系统nanobot/cron/* + nanobot/heartbeat/*:调度和心跳
03 | 核心循环:LLM 不"做"——它决定"做什么"
AgentLoop 逻辑是教科书式的:
- 从入站队列拉取一条消息
- 检索/创建会话,从历史记录中获取最近的 N 条消息
- 使用 ContextBuilder 组装系统提示,然后将历史记录 + 当前消息打包成消息
- 调用 LLM(将工具定义作为函数模式传递给模型)
- 如果模型返回工具调用:执行每个调用,将工具结果作为工具角色消息回填,继续下一轮
- 如果模型停止调用工具:获取最终内容,写入会话,发送到出站队列
它的价值:"思考"和"做"被明确分离。
- LLM 只输出结构化的工具调用
- 工具处理执行
- 结果回填
- LLM 基于"真实结果"继续推理
这比"模型在脑海中想象执行结果"好得多。
关键消息格式:
messages = [system_prompt] + history + [user_message]
assistant -> tool_calls[] # 决定做什么
tool_results -> messages # 将真实执行结果反馈回来
在这个循环中,最重要的不是"更多工具"——而是"工具调用证据链":
- 你看到模型如何决定(消息中的工具调用)
- 你看到工具返回了什么(消息中的工具结果)
- 你看到最终响应看起来是这样的原因(它基于这个证据)
这是可控性的基础:所有关键动作都可以在上下文中重放。
两个实现细节影响你的稳定性:
- 上限:max_iterations 默认为 20,防止模型进入工具调用死循环
- 历史存储:Session 使用 JSONL 格式写入
~/.nanobot/sessions,第一行是元数据,后续行是单独的消息;对调试和重放非常友好
03.1 | MessageBus:为什么添加队列层
许多 Agent 构建者将"接收消息"与"处理消息"混合在一起。问题:
- 不同的通道有不同的消息格式(Telegram 有语音,WhatsApp 有媒体,Slack 有 @mention)
- 处理逻辑需要串行控制(否则对话状态会损坏)
- 当你想要可观察性(日志记录、审计)时,没有地方插入它
NanoBot 的 MessageBus 有两个队列:
self.inbound: asyncio.Queue[InboundMessage] = asyncio.Queue()
self.outbound: asyncio.Queue[OutboundMessage] = asyncio.Queue()
Channels 将各种格式的消息统一为 InboundMessage,并将它们扔入入站队列。AgentLoop 从队列中拉取,处理,并将 OutboundMessage 扔入出站队列。ChannelManager 订阅出站并按通道分发回来。
这种设计的好处:
- Channels 不需要知道 Agent 如何工作
- AgentLoop 不需要知道消息来自哪里
- 想要添加审计、速率限制和优先级吗?在队列层添加
03.2 | 子 Agent 生成:将复杂任务与主对话分离
NanoBot 有一个实用但容易被忽视的能力:spawn。
它不是"多 Agent"宏大叙事;方法很直接:
- 主 Agent 接收任务,发现它太长或太复杂
- 使用 spawn 为特定的隔离工作拉起一个子 agent(比如"先读取这批文件,做一个结构化摘要")
- 子 agent 完成,通过 MessageBus 作为系统消息将结果返回给主 Agent
- 主 agent 更自然地为用户总结结果
SubagentManager 的关键限制:
# 子 agent 没有消息工具,没有 spawn 工具
tools.register(ReadFileTool())
tools.register(WriteFileTool())
tools.register(ListDirTool())
tools.register(ExecTool(...))
tools.register(WebSearchTool(...))
tools.register(WebFetchTool())
这是设计价值:子 agent 有更少的工具,更小的权限,更窄的目标——不会成为第二个全能的黑盒子。
03.3 | Gateway:它同时启动 AgentLoop、Channels、Cron、Heartbeat
当你运行 nanobot gateway 时,它不仅仅是"启动一个机器人"。
它在一个进程中拉起四个部分:
- AgentLoop:消费入站,生成出站
- ChannelManager:按配置启动 Telegram/WhatsApp/Slack,处理出站分发
- CronService:从
~/.nanobot/cron/jobs.json读取/写入计划任务,触发 agent 按计划运行 - HeartbeatService:默认每 30 分钟唤醒一次,让 Agent 读取 HEARTBEAT.md 以检查待处理任务
这就是我称之为最小运行时的原因:它将"持续运行"视为架构的一部分。
04 | ContextBuilder:为什么它也像 OpenClaw 一样使用一堆 Markdown 文件
你会在工作空间中看到一个熟悉的文件组:
AGENTS.md:工作规范(如何做事情)SOUL.md:性格/价值观/边界(如何说话,如何选择)USER.md:用户偏好(你是谁,你在乎什么)TOOLS.md:工具描述(存在什么能力,如何调用)IDENTITY.md:身份(名称、风格)memory/:日常笔记 + 长期信息
ContextBuilder 的工作:将这些"真相源"组装到系统提示中:
BOOTSTRAP_FILES = ["AGENTS.md", "SOUL.md", "USER.md", "TOOLS.md", "IDENTITY.md"]
def build_system_prompt(self, skill_names: list[str] | None = None) -> str:
parts = []
parts.append(self._get_identity())
bootstrap = self._load_bootstrap_files()
if bootstrap:
parts.append(bootstrap)
memory = self.memory.get_memory_context()
if memory:
parts.append(f"# Memory\n\n{memory}")
# ...
return "\n\n---\n\n".join(parts)
这种基于文件的方法的好处:
- 规则是版本控制的:Git 跟踪"何时添加了这个边界"
- 上下文是可控制的:想要 Agent 更克制吗?编辑 SOUL。想要工具更稳定吗?编辑 TOOLS。想要它更好地理解你吗?编辑 USER
- 连续性不依赖对话:丢失的对话不是致命的,文件仍然保留
我更喜欢用一句话理解它:文本 > 大脑。
04.1 | SkillsLoader:渐进式技能加载
NanoBot 的技能系统有一个值得提及的设计点:并非所有技能都立即塞入系统提示中。
def build_skills_summary(self) -> str:
# 只返回技能名称/描述/位置
# Agent 需要时使用 read_file 读取完整内容
这解决了一个真实问题:太多技能会爆炸系统提示。
它的方法:
- 带有
always=true的技能:直接进入系统提示 - 其他技能:只向 Agent 显示摘要(名称 + 描述 + 路径)
- 当 Agent 需要时:使用 read_file 读取完整内容本身
这是"渐进式加载":让 Agent 按需获取,而不是提前给出所有东西。
04.2 | MemoryStore:记事本级别的记忆
MemoryStore 做两件事:
- 日常笔记:
memory/YYYY-MM-DD.md,每天一个文件 - 长期记忆:
memory/MEMORY.md,手动维护的持久信息
def get_memory_context(self) -> str:
parts = []
long_term = self.read_long_term()
if long_term:
parts.append("## Long-term Memory\n" + long_term)
today = self.read_today()
if today:
parts.append("## Today's Notes\n" + today)
return "\n\n".join(parts) if parts else ""
它满足了"让 Agent 记住你告诉它的东西"的基本需求。
但距离"可检索的长期记忆"还有差距。README 路线图也将长期记忆列为待处理工作。
05 | 工具系统:为什么"可控 Agent"不能没有 ToolRegistry + 参数验证
许多 Agent 构建者最终得到越来越混乱的工具,最终变成:
- 一堆分散的函数
- 一堆"如果模型说某些关键词则执行"
- 一堆基于约定的参数格式
NanoBot 的工具系统做对了两件事:
- 工具是"注册表",而不是"松散脚本"
ToolRegistry 统一注册,将所有工具定义打包成模型的函数模式。
def _register_default_tools(self) -> None:
self.tools.register(ReadFileTool())
self.tools.register(WriteFileTool())
self.tools.register(EditFileTool())
self.tools.register(ListDirTool())
self.tools.register(ExecTool(...))
self.tools.register(WebSearchTool(...))
self.tools.register(WebFetchTool())
self.tools.register(MessageTool(...))
self.tools.register(SpawnTool(...))
AgentLoop 不需要知道"存在哪些工具",只知道"所有工具看起来都一样":名称/描述/参数/执行。
- 参数使用 JSON Schema 验证,并且失败也是可读的
工具基类有 validate_params(),根据模式检查类型、必填字段、枚举、最小/最大值等。
这对稳定性至关重要:
- 当模型输出错误的参数时,它不会用异常炸毁整个循环
- 将错误收敛为可读文本,反馈给模型进行更正
- 你可以在日志中看到"哪个字段错了"
05.1 | web_fetch 返回 JSON,而不是"文章正文"
为了避免你认为它是"随机抓取器",我将指出两个细节:
- web_search 使用 Brave Search API,需要
tools.web.search.apiKey(或环境变量BRAVE_API_KEY) - web_fetch 返回值是一个 JSON 字符串,包含 finalUrl、status、extractor、truncated、text 等字段
这对 Agent 至关重要。因为模型需要的不仅仅是"正文"——它需要知道"这次获取实际上得到了什么,它被截断了吗,它重定向到另一个域了吗"。
这是我喜欢的方式:工具输出尽可能结构化,让模型读取"可验证的证据"而不是随机文本。
05.2 | LiteLLM Provider:简单的多模型路由实现
NanoBot 使用 LiteLLM 进行多模型路由:
class LiteLLMProvider(LLMProvider):
def __init__(self, api_key, api_base, default_model="anthropic/claude-opus-4-5"):
# 根据 api_key 前缀确定提供商
self.is_openrouter = api_key and api_key.startswith("sk-or-")
self.is_vllm = bool(api_base) and not self.is_openrouter
支持的提供商:
- OpenRouter(推荐,访问所有模型)
- Anthropic / OpenAI / DeepSeek / Gemini / Groq(直接连接)
- vLLM(本地模型)
配置很简单:
{
"providers": {
"openrouter": { "apiKey": "sk-or-v1-xxx" }
},
"agents": {
"defaults": { "model": "anthropic/claude-opus-4-5" }
}
}
对于本地模型:
{
"providers": {
"vllm": {
"apiKey": "dummy",
"apiBase": "http://localhost:8000/v1"
}
},
"agents": {
"defaults": { "model": "meta-llama/Llama-3.1-8B-Instruct" }
}
}
06 | 主动性:Cron 和 Heartbeat 是两种不同的"唤醒方式"
许多 Agents 在某一点体验很差:它们只等你发送消息。
NanoBot 使用两种机制:
Cron:明确的计划任务
CronService 管理任务,当时机到来时向 Agent 发送"类似用户输入"的消息(agent 轮次),然后可选地将结果传递到指定通道。
你可以把它想象为:将"提醒/例行检查"产品化。
# 添加任务
nanobot cron add --name "daily" --message "Good morning!" --cron "0 9 * * *"
# 列出任务
nanobot cron list
# 删除任务
nanobot cron remove <job_id>
Heartbeat:轻量级周期性唤醒
HeartbeatService 默认每 30 分钟触发一次,但不强制任务——让 Agent 读取 HEARTBEAT.md:
- 如果文件没有任何内容,什么都不做
- 如果它有待处理的项目,按检查清单执行
我真的很喜欢这个设计:将主动性变成"非常便宜的接口",不需要重新发明复杂的工作流 DSL。
06.1 | Channels:更多入口,更严格的边界
从架构角度来看,Channels 的意义不是"连接几个聊天应用"——而是将"入口不确定性"拒之门外。
典型的不确定性:
- Telegram 可能有语音(加上转录)
- WhatsApp 需要桥接(Node 桥)
- Slack 使用长连接(WebSocket)
- 不同的通道有不一致的 sender_id、chat_id 语义
NanoBot 的处理:不要与入口纠缠,统一为 InboundMessage / OutboundMessage。
你需要注意的是配置层的 allowFrom 字段。更多入口会让"你没有计划响应的人也得到了响应"的意外变得更容易。
如果 allowFrom 为空,BaseChannel 逻辑默认为开放。
如果你真的为团队使用部署,建议将"谁被允许触发"视为硬阈值,而不是随意的配置。
06.2 | 三个通道的工程细节
Telegram
- 长轮询,不需要公共 webhook
- 下载的图像/语音/文件进入
~/.nanobot/media - 语音转录是可选的:配置 Groq API 密钥后,它使用 Whisper 转换为文本,然后喂给 Agent
- 发送消息时,将 Markdown 转换为 Telegram 安全的 HTML,失败时回退到纯文本
- Python 端不直接实现协议,通过 WebSocket 连接到 Node.js 桥
- 桥使用 @whiskeysockets/baileys(WhatsApp Web 协议——现实世界的麻烦在这里)
- 语音消息目前不支持从桥端直接下载和转录
Slack
- 使用 WebSocket 长连接,更像企业系统集成
- 有 message_id 去重缓存以避免重新处理(超过阈值时修剪)
- 接收消息后给出反应(如"已读/已处理"信号),然后转发到 AgentLoop
这三个部分的细节解释了一个现实:通道不是"适配完成"——它们强迫你赶上可靠性、权限边界和可观察性。
07 | 什么最值得复制,什么需要谨慎
值得复制:4 件事
- 消息总线解耦:Channels 和 AgentLoop 之间只有 Inbound/OutboundMessage
- 清晰的工具循环:工具调用生命周期(调用 → 执行 → 结果 → 继续)在一个文件中可读
- 基于文件的上下文:工作空间 Markdown 携带稳定的规则和偏好
- 轻量级主动性:Cron/Heartbeat 都向 AgentLoop 发送"下一个输入"
需要谨慎/建议补充:4 件事
- 更强的记忆检索:当前的 MemoryStore 更像"记事本",仍然距离"可检索的长期记忆"很远
- 更严格的权限边界:exec 的正则表达式护栏是必要的但不足;对于生产,最好引入允许列表、双重确认、审计重放
- Session 和可移植性:Session 默认为
~/.nanobot/sessions,对于"将工作区移动到另一台机器"不是很友好 - 异步并发策略:现在是"逐一执行工具调用",足够简单,但对于复杂的编排(并行工具、车道队列、重试策略)需要更多工作
还有一个小陷阱:process_direct() 目前忽略传入的 session_key,导致 Cron/Heartbeat 等"系统触发"的输入可能与你的 CLI 会话混合。
这类问题不难修复,但它提醒你:Agent 稳定性往往不关于模型——而是关于"状态隔离"。
4、为什么我建议阅读一次 NanoBot 代码
许多 Agent 框架让你阅读后更焦虑:更多概念、更多抽象、实际执行管道变得更模糊。
NanoBot 的好处:它将"可用的 Agent"压缩到一个你可以完成阅读的规模。
你不需要将其视为最终解决方案。最好将其视为"最小可行骨架":先关闭循环,然后逐步添加护栏、添加记忆、添加工作流。
这是构建可控 Agents 的正确节奏。
如果你准备好开始阅读,建议这个顺序——基本上不会迷路:
nanobot/agent/loop.py:首先理解主管道nanobot/agent/context.py:然后看如何组装上下文nanobot/agent/tools/*:最后,看工具系统和安全护栏nanobot/cron/* + nanobot/heartbeat/*:理解"主动性"如何连接nanobot/channels/*:当你需要连接新入口时查看
比较图清楚地显示了执行流程——这就是使 NanoBot 成为一个值得学习的最小骨架而不是另一个框架的原因。
关键技术指标(2026 年 2 月):
- 实际代码库:约 3,510 行(核心 agent 代码,通过
core_agent_lines.sh验证) - 启动时间:0.8 秒(vs OpenClaw 的 8-12 秒)
- 内存占用:45MB 基本操作(vs OpenClaw 的 200-400MB)
- GitHub 指标:15.9K 星,2.2K fork,32+ 贡献者
- 最新版本:v0.1.3.post6(2026 年 2 月 10 日)
- 支持的通道:Telegram、Discord、WhatsApp、Mochat、钉钉、Slack、Email、QQ
- 支持的 LLM 提供商:13+,包括 OpenRouter、Anthropic、OpenAI、DeepSeek、Gemini、Groq、vLLM
该架构表明,有效的 AI agent 不需要庞大的框架。通过将 agent 设计减少到基础知识,NanoBot 实现了更快的实验、更容易的调试、更低的资源消耗和更大的执行控制——证明了 99% 的代码减少可以在架构正确时保持完整功能。
原文链接: NanoBot Architecture Teardown: 4,000 Lines Achieving OpenClaw Capability
汇智网翻译整理,转载请标明出处
