neo4j图驱动的AI代理记忆库
neo4j-agent-memory是一个Neo4j实验室项目,提供基于图形的短期、长期和推理代理记忆。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
AI代理正在改变组织的工作方式——但它们有记忆问题。询问代理关于上周的对话,你会得到一片空白。在整个组织部署多个代理,它们无法分享它们学到的东西。当出现问题时,没有审计轨迹解释代理为什么做出那个决定。
业界认识到图数据库对于AI代理记忆至关重要。像Zep、Cognee、Mem0和其他公司已经使用Neo4j构建了令人印象深刻的系统来存储对话和实体知识。但构建有效的上下文图需要三种记忆类型协同工作:
- 短期记忆用于对话历史和会话状态
- 长期记忆用于实体、关系和学到的偏好
- 推理记忆用于决策跟踪、工具使用审计和溯源
大多数现有实现涵盖前两个——但跳过推理记忆。没有它,你就无法解释决策、从经验中学习或调试意外行为。
今天我们发布 neo4j-agent-memory,这是一个Neo4j实验室项目,提供所有三种记忆类型。从我们与构建生产AI代理的客户直接合作开发的最佳实践中汲取经验,它是一个开源Python库,与现代代理框架集成——LangChain、Pydantic AI、LlamaIndex、OpenAI Agents、CrewAI等——并将你的整个上下文图存储在Neo4j中。
1、看看它的实际效果:Lenny的记忆
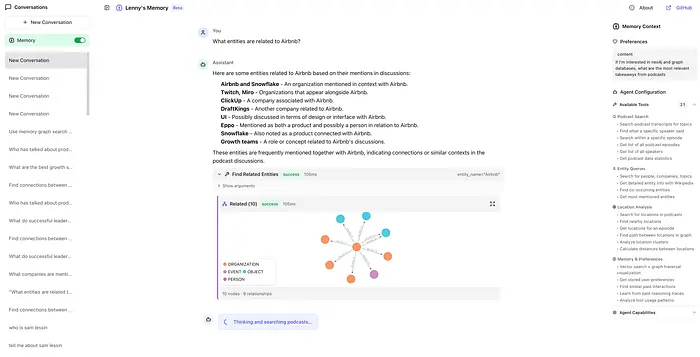
为了用具体示例演示这个项目,我们构建了Lenny的记忆,一个加载了300+播客节目的演示应用,来自流行的Lenny的播客,并让你通过具有完整记忆的AI代理来探索它们。
我们将节目加载到neo4j-agent-memory中,提取了客人、公司、主题、地点及其关系。然后我们用Pydantic AI构建了一个聊天代理,具有19个专业工具,使用所有三种记忆类型。
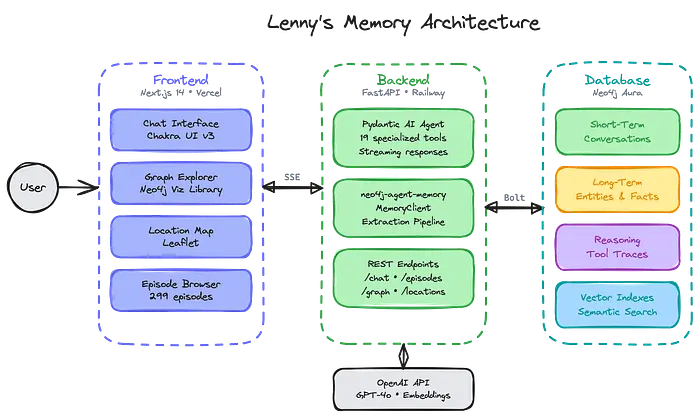
@neo4j-labs/agent-memory包的Lenny的记忆演示应用架构询问人们及其想法:
"Brian Chesky关于招聘说了什么?"
代理搜索Brian Chesky出现的每个节目,找到他关于招聘的引用,并综合出一个答案——带有节目引用,以便你可以深入挖掘。
探索连接:
"哪些客人同时讨论了产品市场匹配和定价?"
这不仅仅是关键词搜索。代理遍历实体(人、公司、概念)及其关系的知识图谱,以找到有意义的交集。
获得个性化推荐:
"根据我所问的,我应该听哪些节目?"
代理记住你的对话历史和学到的偏好,用它们来定制推荐。
查看知识图谱:
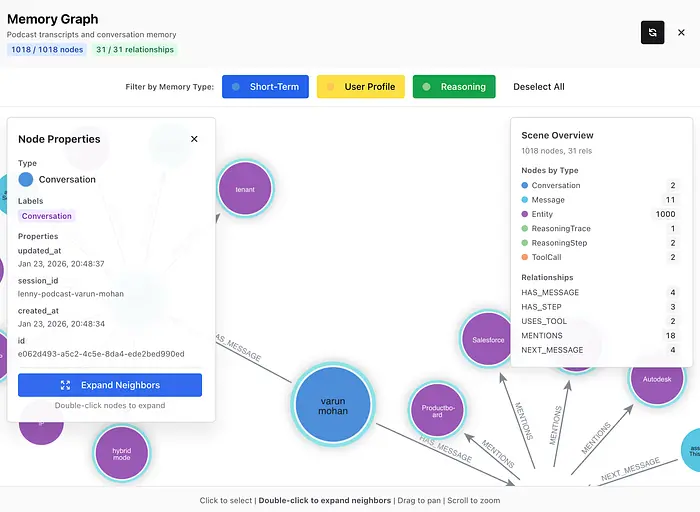
交互式可视化让你探索客人、公司和主题如何连接。双击节点展开关系。按实体类型筛选。查看维基百科丰富的卡片以获取上下文。
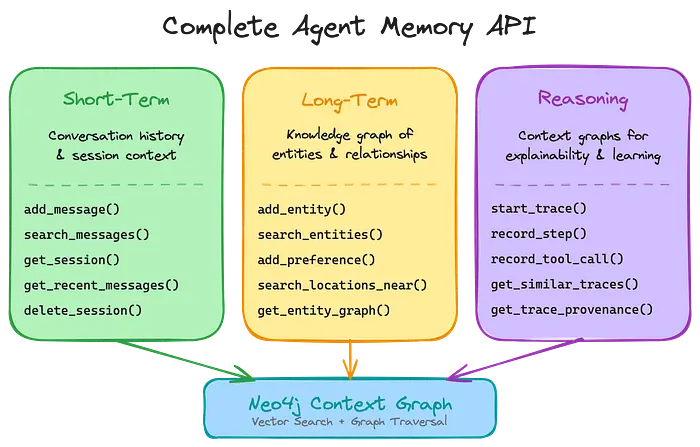
2、上下文图的三种记忆类型
上下文图需要所有三种记忆类型才能完整。大多数现有解决方案涵盖前两个——但跳过推理记忆,这对于可解释性和从经验中学习至关重要。
2.1 短期记忆:刚刚发生了什么
你对话中的每条消息都存储在上下文中——谁说的,什么时候,之前发生了什么。这让代理能够保持连贯的多轮对话,并引用你聊天的早期部分。
# 代理在聊天时存储每条消息
await memory.short_term.add_message(
session_id="user-123",
role="user",
content="Brian Chesky关于文化说了什么?",
metadata={"source": "chat"}
)
# 并且可以搜索你的对话历史
results = await memory.short_term.search_messages(
"创业文化",
session_id="user-123",
limit=10
)
在Lenny的记忆中,这为对话流程提供动力——代理知道你两条消息前问了什么,并可以在此基础上构建。
2.2 长期记忆:代理知道什么
这里变得有趣了。长期记忆提取并存储实体及其关系的知识图谱。播客中提到的每个客人、公司、主题和地点都成为一个节点。关系连接它们:Brian Chesky 创立了 Airbnb。Airbnb 位于 旧金山。Brian在第45期 讨论了 "招聘"。
# 实体使用POLE+O模型自动类型化
#(人、组织、地点、事件、对象)
entity, dedup = await memory.long_term.add_entity(
name="Brian Chesky",
type="PERSON",
description="Airbnb的联合创始人兼CEO"
)
# 地理空间查询在半径内查找地点
nearby = await memory.long_term.search_locations_near(
latitude=37.7749,
longitude=-122.4194,
radius_km=50
)
2.3 推理记忆:缺失的部分
这是大多数记忆实现所缺乏的。 每当代理推理一个问题——规划步骤、调用工具、评估结果——那个跟踪就被记录下来。下次它面临类似任务时,它可以参考什么有效。
from neo4j_agent_memory import StreamingTraceRecorder
# 记录代理的推理过程
async with StreamingTraceRecorder(
memory.reasoning,
session_id="user-123",
task="查找关于定价策略的节目"
) as recorder:
step = await recorder.start_step(
thought="我应该搜索与定价相关的内容",
action="search_episodes"
)
await recorder.record_tool_call(
tool_name="search_episodes",
arguments={"query": "定价策略"},
result=[{"title": "第45期:给你的产品定价"}],
status=ToolCallStatus.SUCCESS,
duration_ms=145
)
# 之后:查找类似的成功推理
similar = await memory.reasoning.get_similar_traces(
task="查找关于货币化的内容",
success_only=True
)
在Lenny的记忆中,在回答每个问题之前,代理检查它是否之前解决过类似问题。如果它找到了关于*"定价策略"问题的好方法,它可以重用那个模式来回答"货币化"*问题。
3、为什么推理记忆能够实现可解释性
推理记忆不仅仅帮助代理学习——它使AI决策透明且可审计。
每个推理跟踪捕获完整链:
- 哪条消息触发了任务,
- 代理在想什么,
- 它调用了哪些工具(带参数和结果),
- 方法是否成功了。
这个结构支持强大的查询:
// 查找特定答案背后的推理
MATCH (m:Message {content: "Brian关于招聘说了什么?"})
-[:TRIGGERED]->(t:ReasoningTrace)
-[:HAS_STEP]->(s:ReasoningStep)
-[:USED_TOOL]->(tc:ToolCall)
RETURN s.thought, tc.tool_name, tc.arguments, tc.result
// 审计哪些数据源影响了决策
MATCH (t:ReasoningTrace)-[:HAS_STEP]->()-[:USED_TOOL]->(tc:ToolCall)
WHERE t.task CONTAINS "recommendation"
RETURN tc.tool_name, count(*) AS usage, avg(tc.duration_ms) AS avg_latency
数据溯源是内置的。当代理做出声称时,你可以通过推理步骤追溯它到特定工具调用和数据源。这对于受监管行业、调试意外行为和建立用户信任很重要。
可解释性变得可查询。不要将代理视为黑盒,你可以问:"你为什么推荐这个节目?"并得到具体答案——不是事后合理化,而是导致决策的实际推理跟踪。
推理记忆还支持持续改进。通过分析成功与失败跟踪中的模式,你可以识别哪些工具对哪些任务最有效,代理在哪里挣扎,以及如何优化提示或工具设计。
4、实体提取管道
加载播客节目意味着提取数千个实体——客人、公司、概念、地点。仅用LLM调用做这件事会很慢且昂贵。
所以我们构建了一个多阶段管道:
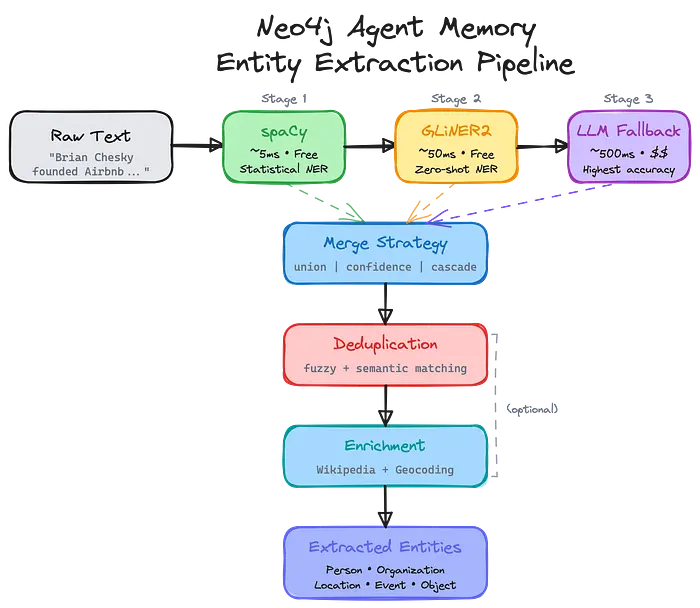
- spaCy(~5毫秒,免费):快速统计NER捕捉常见实体
- GLiNER2(~50毫秒,免费):具有领域特定模式的零样本NER
- LLM回退(gpt-4o-mini)(~500毫秒,成本):复杂情况的最高准确性
该管道还处理去重("Brian"与"Brian Chesky"是同一个人吗?)、关系提取和可选的维基百科丰富。
from neo4j_agent_memory.extraction import ExtractorBuilder
extractor = (
ExtractorBuilder()
.with_spacy(model="en_core_web_sm")
.with_gliner_schema("podcast", threshold=0.5) # 可用8个领域模式
.with_llm_fallback(model="gpt-4o-mini")
.with_merge_strategy("confidence")
.build()
)
result = await extractor.extract(
"Brian Chesky于2008年在旧金山创立了Airbnb"
)
# 提取:人(Brian Chesky)、组织(Airbnb)、
# 地点(旧金山)、事件(创立,2008)
5、图模式
以下是三种记忆类型如何在Neo4j中连接:
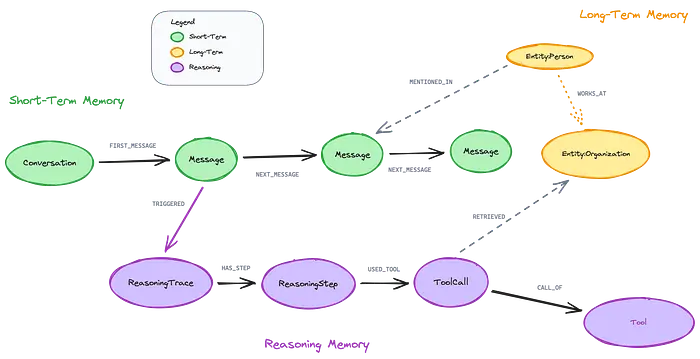
这个模式的力量在于所有三种记忆类型都通过共享节点连接。一条消息触发推理跟踪,该跟踪使用检索实体的工具,这些实体在其他消息中被提及。
这种互连支持溯源查询,如*"显示影响此推荐的所有实体"或"哪些推理模式导致最高用户满意度"*。
6、与AI代理框架集成
neo4j-agent-memory的一个关键设计目标是与团队已经在使用的框架和平台无缝集成。它不是强迫你重写代理架构,而是插入到现有工作流程中。
from neo4j_agent_memory.integrations.pydantic_ai import create_memory_tools
tools = create_memory_tools(client)
agent = Agent(model="gpt-4o", tools=tools)
from neo4j_agent_memory.integrations.langchain import Neo4jAgentMemory
memory = Neo4jAgentMemory(client, session_id="user-123")
chain = ConversationChain(llm=llm, memory=memory)
from neo4j_agent_memory.integrations.openai_agents import Neo4jMemoryTool
tool = Neo4jMemoryTool(client)
agent = Agent(tools=[tool])
还支持:LlamaIndex、CrewAI以及任何接受自定义工具或记忆后端的框架。
集成处理复杂性的
- 异步操作,
- 流式响应,
- 和上下文管理
所以你可以专注于代理的逻辑而不是记忆管道。
7、为什么基于图的记忆对组织很重要
向量数据库解决了AI记忆问题的一部分——它们实现了对过去交互的语义搜索。但它们将每条信息视为孤立的嵌入,错过了使知识有价值的连接。
基于图形的记忆捕捉向量无法捕捉的内容:
关系是一等公民。当Brian Chesky提到Airbnb的文化时,那不仅仅是文本——那是通过创立关系连接的人和组织,对话存储为溯源。查询图谱以查找"由也讨论定价策略的客人提到的所有公司"*,你会得到精确的答案,而不是模糊的相似性匹配。
知识在代理之间复合。当一个代理了解到用户偏好详细的技术解释时,那个偏好存储在图中。查询相同数据库的其他代理无需重新训练或提示工程就能继承该知识。
决策变得可审计。这是推理记忆发挥作用的地方。受监管行业需要解释AI决策。有了图中的所有三种记忆类型,你就有了完整的审计跟踪**:哪些数据源通知了决策,代理采取了哪些推理步骤,以及类似方法在过去是否成功。
**洞察从结构中浮现。**图分析揭示了扁平数据中不可见的模式:哪些主题聚集在一起,哪些实体桥接不同对话,哪里存在知识差距。
这些洞察既代理行为和业务战略都通知。
Neo4j-agent-memory提供所有三种记忆类型,图建模、向量索引和查询优化都为你处理。
8、为什么图正在AI代理记忆中获胜
市场已经验证了图数据库作为AI代理记忆的基础。
看看新兴的格局。
- Zep使用知识图为AI助手构建长期记忆,连接用户、会话和事实。
- Graphiti来自Zep创建时间知识图,跟踪信息如何随时间演变。
- Cognee使用图构建代理可以推理的结构化记忆层。
- Mem0提供个性化的AI记忆,具有基于图的实体关系。
- LangMem来自LangChain将代理体验存储为连接的内存图。
这些工具认识到扁平存储——无论是关系表还是向量嵌入——都无法捕捉知识的相互关联性质。
当代理需要回答 "客户在Q3预算担忧的背景下关于定价说了什么?"时,你需要遍历关系,而不仅仅是查找相似的文本。
但构建有效的上下文图需要所有三种记忆类型。 大多数实现涵盖短期(对话)和长期(实体)——但跳过推理记忆。在没有记录代理如何思考问题的情况下,你留下了一个无法的上下文图:
- 解释代理为什么做出特定决策
- 从成功(和失败)的方法中学习
- 使用完整溯源调试意外行为
- 根据实际有效的内容改进代理性能
Neo4j-agent-memory提供所有三种。短期、长期和推理记忆——连接在从问题到答案的完整溯源的单个图中。
9、从客户模式到开源构建块
我们一直与构建生产AI代理的团队直接合作。我们在实施中看到的重复模式启发了neo4j-agent-memory:
每个人都构建相同的三个层。无论是客户服务机器人还是研究助手,生产代理都需要对话历史(短期)、实体知识(长期)和推理跟踪。与其每个团队重新发明这种架构,我们将其打包。
推理记忆是事后的想法——直到它不是。团队从对话和实体开始,然后意识到他们无法调试代理行为或解释决策。之后添加推理记忆意味着将溯源改装到现有模式中。从第一天就构建它要干净得多。
实体提取是瓶颈。团队要么过度依赖昂贵的LLM调用,要么在提取质量上投资不足。多阶段管道——快速统计NER、零样本模型、LLM回退——代表了我们看到的最佳成本/质量权衡。
框架集成是入门标准。没有人想重写他们的代理架构来添加记忆。与LangChain、Pydantic AI、LlamaIndex、OpenAI Agents和CrewAI的集成意味着你可以增量采用neo4j-agent-memory。
Neo4j-agent-memory不是专有平台——它是编码这些最佳实践的开源库。按原样使用它,分叉它,或将其作为自己架构的参考实现。目标是降低在Neo4j上构建生产质量AI代理记忆的障碍。请向仓库提供反馈。
10、自己运行它
尝试现场演示
体验neo4j-agent-memory的最快方式是托管演示:
在你自己的项目中使用库
neo4j-agent-memory项目可通过pip和其他流行的Python包管理器获得。
pip install neo4j-agent-memory
# 可选依赖
pip install neo4j-agent-memory[extraction] # 实体提取
pip install neo4j-agent-memory[langchain] # LangChain集成
pip install neo4j-agent-memory[all] # 一切
快速开始:
from neo4j_agent_memory import MemoryClient, MemorySettings
settings = MemorySettings() # 从环境读取
async with MemoryClient(settings) as memory:
# 存储对话
await memory.short_term.add_message(
session_id="demo",
role="user",
content="我对产品市场匹配感兴趣"
)
# 学习偏好
await memory.long_term.add_preference(
category="topics",
preference="产品市场匹配",
context="用户表达了兴趣"
)
# 为你的LLM提示获取上下文
context = await memory.get_context("创业建议")
原文链接: Meet Lenny's Memory: Building Context Graphs for AI Agents
汇智网翻译整理,标明出处
