NOMAD:战时离线智能体
当你依赖的一切都消失时,智能不再是便利,而是生存的关键。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
在降级、断联和资源匮乏的环境中,脆弱的设计毫无容错空间。
每一个缺失的服务都成为故障点,每一秒等待基础设施的时间都是你可能无法承受的损失。
Project N.O.M.A.D. 正是为这种现实而生。
这是一个基于残酷前提设计的AI系统:假设你需要时什么都不存在——没有云端、没有API密钥、没有网络、没有安全网。
人类积累的知识被封存在本地硬盘上,交给模型使用。
Project N.O.M.A.D. 专为现代系统崩溃的环境设计。它集成了本地AI、基于RAG的知识库、离线维基百科、地图和医疗参考。
让我们在世界陷入黑暗之前看看它的样子。
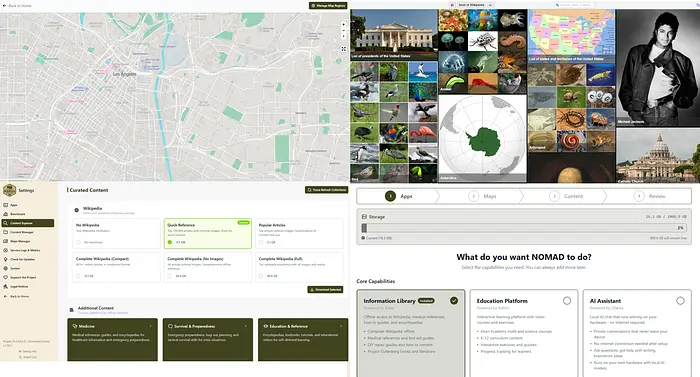
1、内置功能
简而言之,N.O.M.A.D. 提供以下开箱即用的功能:
- AI聊天与知识库:基于Ollama的本地AI聊天,支持文档上传和语义搜索(通过Qdrant实现RAG)
- 信息库:通过Kiwix提供离线维基百科、医疗参考、电子书等
- 教育平台:通过Kolibri提供可汗学院课程及进度跟踪
- 离线地图:通过ProtoMaps下载区域地图
- 数据工具:通过CyberChef提供加密、编码和分析功能
- 笔记:通过FlatNotes提供本地笔记功能
- 系统基准测试:通过社区排行榜进行硬件评分
- 简易设置向导:引导式首次配置及精选内容集合
N.O.M.A.D. 还包括内置工具,如维基百科内容选择器、ZIM库管理器和内容浏览器。
让我们看看它的实际操作。
2、开始使用 Project N.O.M.A.D.
N.O.M.A.D. 提供了适用于任何基于Debian的操作系统(如Ubuntu)的一键安装命令
sudo apt-get update && sudo apt-get install -y curl && curl -fsSL https://raw.githubusercontent.com/Crosstalk-Solutions/project-nomad/refs/heads/main/install/install_nomad.sh -o install_nomad.sh && sudo bash install_nomad.sh

安装完成后,您可以访问 http://localhost:8080
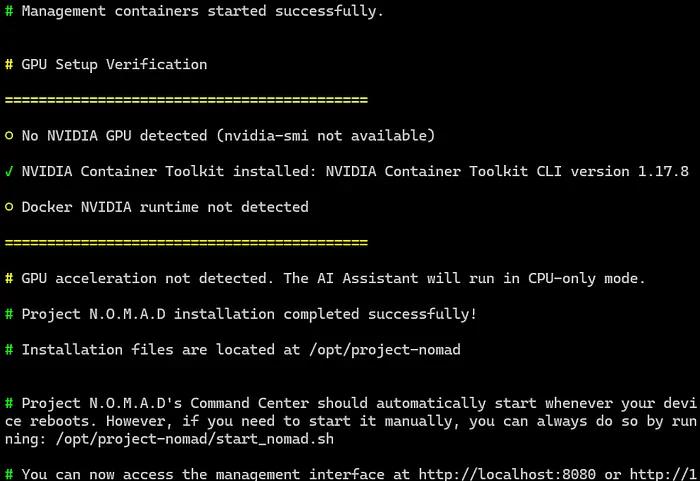
您将看到指挥中心
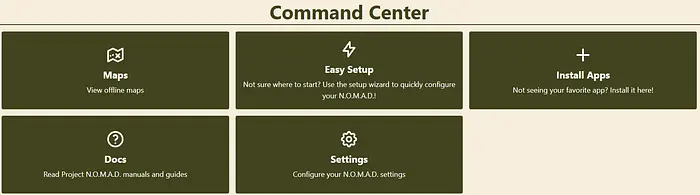
首先需要访问 http://localhost:8080/settings 并安装应用程序。
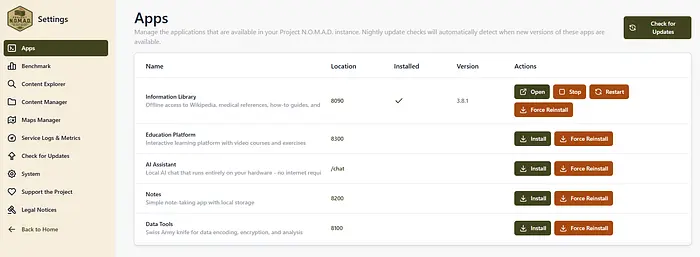
我从信息库开始。
然后可以转到内容浏览器,开始下载符合您需求的精选内容。
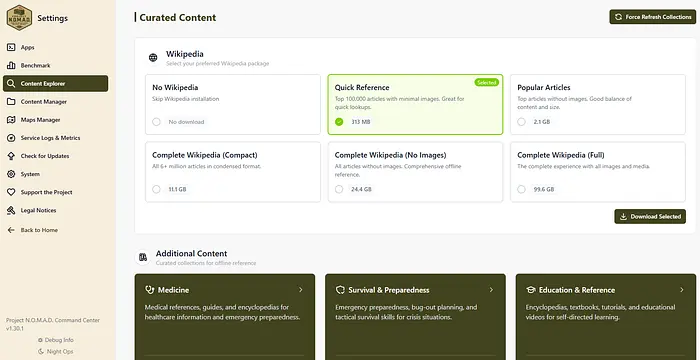
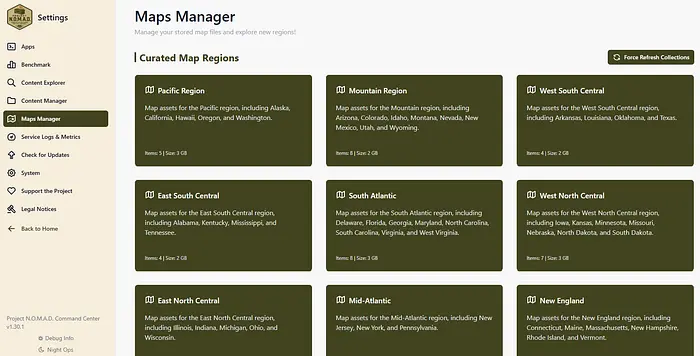
接下来,要设置地图,您需要访问 http://localhost:8080/settings/maps,并从精选地图区域下载地图。
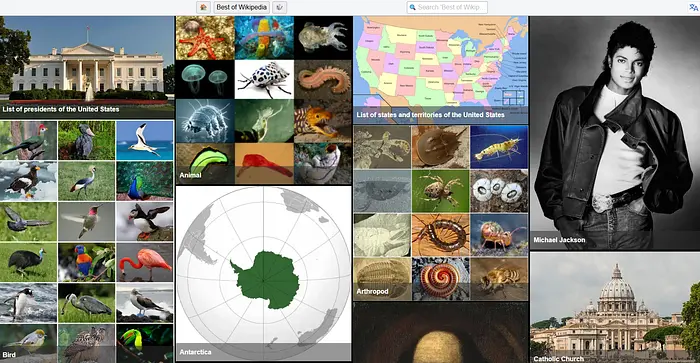
现在如果您返回 http://localhost:8080,您将看到信息库现已可用

您可以搜索和阅读下载的内容。
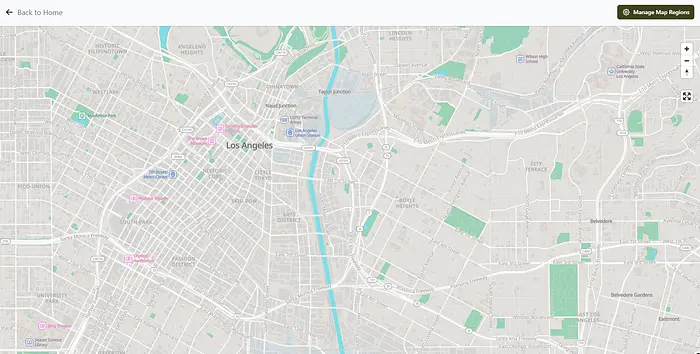
您还可以探索地图。
它还有一个设置指南,可根据您的需求定制项目。
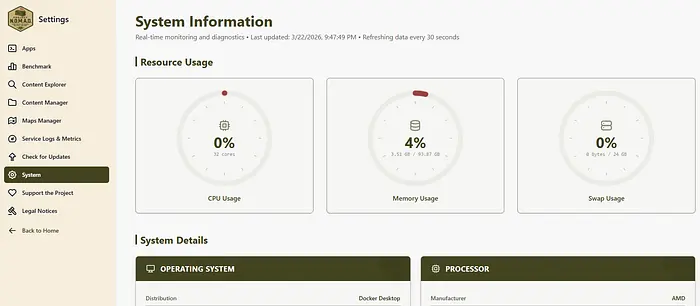
如果系统负载过高,您可以通过实时监控和诊断查看系统状态,数据每30秒刷新一次。
这是一个伟大的项目,可能性是无限的,您可以在许多不同方向扩展 N.O.M.A.D. 及其智能体。
在您开始之前,我想详细说明一些内容,以防您对它的架构感到好奇。
3、架构作为约束满足
N.O.M.A.D. 有一个基于Docker的编排层,管理多个服务。
关键服务包括:
- Ollama: 本地LLM推理
- Qdrant: 用于语义搜索和RAG的向量数据库
- Kiwix: 离线内容服务器(维基百科、医疗参考、电子书)
- 自定义管理服务: 管理上述所有服务的编排大脑
N.O.M.A.D. 不使用单一的智能体框架,即没有LangChain导入,没有CrewAI依赖。
它将核心智能体模式(如RAG、工具使用、内存、服务编排)作为其代码库中的一等公民实现。
以下是推荐的运行规格:
- 处理器:AMD Ryzen 7或Intel Core i7或更高
- 内存:32GB系统内存
- 显卡:NVIDIA RTX 3060或AMD同等产品或更高(更多显存=可运行更大模型)、
- 存储:至少250GB可用磁盘空间(最好在SSD上)
- 操作系统:基于Debian(推荐Ubuntu)
- 稳定的网络连接(仅在安装时需要)
4、容器即智能体模式
N.O.M.A.D. 的架构提出了一种我称之为容器即智能体的模式:每个Docker容器封装一个能力(推理、搜索、内容服务),编排层充当协调它们的监督智能体。
这直接映射到分层监督模式。
在这种模式中:
- 监督智能体(管理服务)将任务委托给专业智能体(容器)
- 每个专业智能体都有明确定义的接口(API端点、Docker健康检查)
- 监督者处理故障恢复(重启崩溃的容器、拉取更新)
- 通信通过显式消息传递(HTTP请求、Docker事件)发生,而不是共享内存
容器即智能体模式以进程内通信的便利性换取:
- 故障隔离: 崩溃的Ollama容器不会影响Qdrant
- 独立扩展: 您可以为Ollama分配GPU资源而不影响其他服务
- 技术异构性: 每个容器可以使用其所需的任何运行时
- 部署灵活性: 容器可以通过滚动更新独立更新
5、作业队列:异步智能体执行
N.O.M.A.D. 使用作业队列(queue_service.ts)处理长时间运行的任务:嵌入文件、下载模型、运行基准测试、检查更新。
每种作业类型都是一个单独的类(embed_file_job.ts、download_model_job.ts、run_benchmark_job.ts等),具有自己的执行逻辑。
为什么智能体需要队列
大多数智能体框架将执行建模为同步的:用户提问,智能体思考,调用工具,返回答案。
这对于简单的聊天机器人交互有效,但在以下情况下会灾难性地失败:
- 工具执行需要几分钟(嵌入大型文档、运行复杂查询)
- 多个操作需要并行发生(在嵌入文件时下载模型)
- 系统需要从故障中恢复(失败的下载应该可重试,而不是丢失)
- 用户期望进度更新(显示下载百分比、嵌入进度)
N.O.M.A.D. 通过其队列处理所有这些问题。作业是持久的(在服务器重启后存活)、可观察的(通过transmit实时事件系统跟踪进度)和隔离的(失败的嵌入作业不会阻塞模型下载)。
6、N.O.M.A.D. 做对了什么以及下一步
- 将模型视为托管依赖项,而不是服务调用。
无论您是在本地运行Ollama还是在自己的基础设施上托管模型,您的系统都应该拥有模型生命周期,例如版本控制、更新、回退。
2. 实现双内存:对话 + 知识库。
关系数据库中的短期上下文,向量存储中的长期知识。这是有用智能体的最低可行内存架构。
3. 使用异步作业队列执行工具。
在智能体工作时不要阻塞用户。排队作业,流式传输进度,并让用户干预。
4. 容器化能力,而不是智能体。
每个AI能力(推理、搜索、内容)都有自己的容器。编排层协调它们。
这为您提供了故障隔离、独立扩展和技术灵活性。
5. 为降级操作设计。
当服务宕机时会发生什么?当模型变慢时?当存储已满时?
N.O.M.A.D. 处理所有这些情况,因为离线优先的约束迫使团队从第一天起就考虑故障模式。
6. 无情地进行基准测试。
了解您系统的性能范围。在用户实际拥有的硬件上测试,而不仅仅是在您的开发机器上。
如果您对离线系统有任何评论或问题,我很乐意在评论区听到您的想法!
原文链接: Project NOMAD: Offline Agents for Wartime Survival
汇智网翻译整理,转载请标明出处
