并非所有比特都是生而平等的
是时候探索为什么CPU和GPU在处理量化数据方面有着根本不同的特性,以及byteshape.com的研究团队如何揭露了量化世界中的一个静默丑闻:某些格式偷偷地为GPU优化,它们会悄悄地破坏你的CPU性能。

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
上次,我们揭示了一个令人不安的真相……更小的模型文件并不自动意味着更快的推理。
如果你尝试了我建议的Q4_K_M实验,看到你的tokens-per-second飙升,恭喜你——你已经逃离了量化陷阱。
但如果你仍在疑惑为什么在你的i5或i7笔记本上,一个"更智能"的2位格式可能比一个"更笨"的4位格式运行得更慢,你问对了问题。
今天,我们要在这个话题上深入下去。
顺便说一句,这是系列文章"并非所有量化都是生而平等的"的第2部分。你可以在这里找到第1部分。
是时候探索为什么CPU和GPU在处理量化数据方面有着根本不同的特性,以及byteshape.com的研究团队如何揭露了量化世界中的一个静默丑闻:某些格式偷偷地为GPU优化,它们会悄悄地破坏你的CPU性能。
别担心!不需要内核代码或矩阵数学。这是关于为什么你的硬件在量化战争中选了一边,以及如何确保你在获胜的队伍中的故事。
1、快速回顾:到目前为止的情节
如果你错过了第1部分,这里是简单回顾:
- GGUF是量化模型的通用格式,但并非所有量化方法都是平等的
- 每权重的位数不等于每秒token数:解量化开销可能抵消文件大小的节省
Q4_K_M是CPU安全的默认选择:平衡的质量、CPU优化的内核- IQ格式(如
IQ2_XXS)在CPU上可能更慢,尽管文件更小
最后,我们要回答这个燃烧的问题:为什么?

2、硬件个性:CPU vs GPU
让我们从一个比喻开始。想象你让两个不同的助手来整理一个图书馆:
你的CPU是一个一丝不苟的图书管理员
- 一次只喜欢一个任务,但要彻底完成
- 擅长复杂的顺序逻辑
- 有一个小但快速的桌子(缓存)用于常用的书
- 如果你一次扔太多不相关的任务给它,就会陷入困境
你的GPU是一个仓库机器人军队
- 喜欢并行做同样的简单任务,数千次
- 不关心复杂性——只要给它相同的、重复的工作
- 有巨大的地板空间(VRAM),但单个机器人较慢
- 如果任务不完全统一就会浪费能源
小关键洞察:量化格式触发不同的"内核"(代码路径)。某些内核匹配图书管理员的工作流程。其他的只有机器人军队才能理解。
3、为什么这对量化很重要
当你的模型运行推理时,它必须即时解量化压缩的权重。你选择的格式决定了如何进行解压:

用通俗的话说:IQ格式做"更智能"的压缩,但这种智能需要CPU周期。
4、IQ vs KQ:量化家族世仇
让我们认识两个主要派系。
4.1 KQ(K-Quant):CPU可靠的伙伴
K-Quant格式使用分组量化策略。保持类比的话,这就像把书打包到贴标签的盒子里:
模型权重
│
▼
┌─────────────────┐
│ 超级块 │ ← 子块组
├─────────────────┤
│ ┌───────────┐ │
│ │子块1 │ │ ← 每个16-32个权重
│ │• 缩放 s₁ │ │ ← 简单的缩放因子
│ │• min m₁ │ │
│ └───────────┘ │
└─────────────────┘
每个子块有自己的缩放因子,所以解压快速且可预测。CPU喜欢这种:简单的数学、缓存友好的访问模式。
4.2 IQ(重要性量化):GPU的秘密武器
IQ格式将压缩更进一步。它们使用重要性矩阵来决定哪些权重最重要,然后应用非线性量化:
模型权重
│
▼
┌─────────────────┐
│ 重要性矩阵 │ ← 预计算的"哪些权重重要"
├─────────────────┤
│ 非线性代码 │ ← 复杂的查找表
├─────────────────┤
│ 额外的数学步骤 │ ← 每个权重更多CPU周期
└─────────────────┘
I-quants如IQ2_XXS、IQ2_XS、IQ2_S、IQ3_XXS、IQ3_XS、IQ3_S、IQ3_M、IQ4_XS和IQ4_NL是GGUF量化格式,瞄准在低位率下尽可能保持更多质量。
IQ家族围绕基于重要性矩阵的重建来定义:权重使用超级块缩放和重要性矩阵来恢复。——来自Benjamin Marie的Kaitchup
与K-quants相比,I-quants的主要吸引力通常是每字节的质量,尤其是当有好的imatrix可用时。这种优势是真实的,但它在整个家族中并不均匀。
IQ quants对GPU很出色:大规模并行可以一次处理复杂的查找。但对CPU呢?你是在让图书管理员为每本书解谜题。
5、Byteshape的 smoking gun
byteshape.com的团队不仅专注于理论:他们做了基准测试。他们的发现很 stark:
在GPU设置上,低位KQ内核明显不如IQ内核高效。因此,我们构建了偏向IQ量化的GPU变体。" [byteshape GPU博客]
翻译:如果你有GPU,IQ格式可能值得。
但接下来是CPU结果:
与我们在GPU设置上观察到的行为相反,KQ内核在Intel CPU上优于IQ内核。因此,我们建议如果计划在CPU上运行,先尝试KQ模型。" [byteshape CPU博客]
如果你纯CPU用户,你下载了一个IQ2_XXS模型因为"2位听起来很小,你没有节省时间:你给你的CPU一个更难解的谜题。
这里有来自上面提到的Benjamin Marie的Substack的观点:
在现代CPU和GPU上,K-quants通常在吞吐量上匹配或超过传统格式,因为你为相同的质量移动更少的字节。
那后缀(S、M和L)呢?在量化过程中,我们跨张量编码"混合级别"。Q4_K的示例:
Q4_K_S(小):几乎全部保持在4位Q4_K_M(中):选择性地为更敏感的张量(例如,注意力值投影或最终层)提高精度,使用5-6位Q4_K_L(更大):比Q4_K_M更宽松
有效位/权重相应增加,在重要的地方买回质量。在实践中(对你的决策):
Q4_K_M是4位部署的广泛有用的默认选择(对大模型Q4_K也可以)。
Q5_K_M是接近许多任务难以察觉降级的高质量设置。
Q6_K适用于你想要"几乎无损"行为但仍想要内存节省的情况。
请记住,对于大多数模型,你不会在S、M和L变体之间看到很大的质量差异,除非你在处理小模型(比如说<8B模型)。
6、真实数字:这对你的笔记本意味着什么
让我们具体化。以下是我为Qwen3.5-2B模型在我的联想X260(我的2016年老笔记本,Intel Core i5 CPU,16GB RAM,Windows 11)上收集的基准测试。你的结果会不同,但相对差异是成立的。

这个图表告诉我们什么?
- 最小的文件(
IQ2_XXS)是最慢的——只有Q4_K_M速度的60% Q4_K_M达到了最佳点:最快的TPS和高质量(96%)- 用更大的(
Q8_0)对速度没有帮助——只是用更多RAM换取最小的质量提升
这是我的非主流观点:
如果你在CPU上运行,忽略"2位"的炒作。你用速度换取了你不需要的节省。
想想看:
Q4_K_M模型约1.3 GB。IQ2_XXS模型约0.7 GB。- 你"节省"了0.6 GB。
但你损失了近2 tokens每秒。
0.7 GB磁盘空间值得每次响应等待2倍的时间吗?对于我们大多数人:不值得。
我们使用的是相对较小的模型(2B参数):如果你用3B或4B模型试试,损失会更高(在下一节关于"格式交换"实验中你会看到)!
这里是我在小型格式中的最佳模型选择:
- mistralai_Ministral-3-3B-Instruct-2512-Q4_K_M
- Qwen3-4B-Instruct-2507-Q3_K_S-2.77bpw
- granite-4.0-h-tiny-Q4_K_M
随便在你自己的PC上测试它们。
什么时候应该使用极端量化?
只有在两种情况下:
- RAM是你绝对的瓶颈(<6GB可用):那么
Q3_K_S或Q2_K可能是必要的才能容纳模型。在我的测试中Q3_K_S有很好的速度(但质量较低) - 你正在离线批量处理,不在乎延迟:那么更小的文件=内存中更多模型
否则?坚持使用KQ格式。
"把内存当作约束,而不是目标。一旦模型适合你的设备,重要的是权衡曲线:TPS vs 质量。" [byteshape GPU博客]
换句话说:不要为文件大小优化。为你的实际体验优化。
7、试试这个:"格式交换"实验
这是一个10分钟实验,可以在CPU/GPU分歧中看到实际操作(即使你只有CPU):
1) 下载同一模型的三个版本:
IQ2_XXS(极端压缩),例如Ministral-3-3B-Instruct-2512-UD-IQ2_XXS.gguf(点击下载)来自Unsloth的Ministral-3-3B-Instruct-2512-GGUF仓库。Q4_K_M(平衡)使用Ministral-3-3B-Instruct-2512-Q4_K_M.gguf:(点击下载)Q4_K_S(稍小一点)使用Ministral-3-3B-Instruct-2512-Q4_K_S.gguf(点击下载)Q8_0(接近无损)使用Ministral-3-3B-Instruct-2512-Q8_0.gguf(点击下载)
2) 运行模型并在localhost:8080打开浏览器 使用这个命令从终端: .\llama-server.exe -m .\models\Ministral-3-3B-Instruct-2512-UD-IQ2_XXS.gguf -t 2 -n 250 — reasoning-budget 0 -c 4096
3) 在聊天框中粘贴这个提示:用简单的术语解释CPU和GPU推理的区别
4) 在一个简单表格中绘制你的结果:
格式 | 文件大小 | TPS | 质量估计
----------|-----------|-------|-----------------
IQ2_XXS | 1.1 GB | ___ | ~89%
Q4_K_M | 2.15 GB | ___ | ~96%
Q4_K_S | 2.05 GB | ___ | ~94%
Q8_0 | 3.65 GB | ___ | ~99%
问问你自己:哪种格式给我的用例提供了最佳体验?
为什么选Ministral-3B?
在我看来,这个模型是你目前能找到的最佳3B LLM。它能理解用户意图,擅长编码,已准备好函数调用。
而且它在CPU上以离散速度运行(自己试试吧!)
我用Ministral-3-3B-Instruct-2512-Q4_K_S运行了一个测试,我得到了……4.1 tokens/秒
8、但如果我有GPU呢,即使是一个普通的?
我将在第4部分(尚未准备好)介绍使用llama.cpp二进制文件的Vulkan驱动。
在第1部分之后,Isaac Tigges,一位Medium读者,与我分享了他名为A.T.L.A.S(自适应测试时学习和自主专业化)的个人项目。Isaac是弗吉尼亚理工大学的商业管理学生。他使用llama.cpp完全本地运行这个项目:
整个东西使用KV缓存Q4_0量化运行,使用0.6B草稿模型进行推测解码,一切都容纳在16GB VRAM的约12.9GB中……
别担心:我们在第1部分介绍了KV缓存量化,我们很快会讨论推测解码!
但A.T.L.A.S到底是什么?
A.T.L.A.S在一个消费级GPU上使用冻结的14B模型实现了74.6%的LiveCodeBench pass@1——从V2的36-41%提升——通过约束驱动的生成和自验证的迭代细化。前提:将一个冻结的小模型包装在智能基础设施中——结构化生成、基于能量的验证、自验证修复——它可以以一小部分成本与前沿API模型竞争。无微调,无API调用,无云。完全自托管——无数据离开机器,无需API密钥,无使用计量。一块GPU,一台机器。
你可以在这里看看:
GitHub - itigges22/ATLAS: 自适应测试时学习和自主专业化
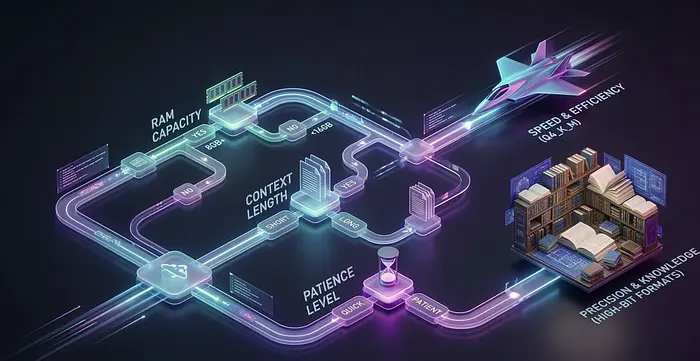
9、接下来:你的个人量化指南针
所以你现在知道了为什么某些格式喜欢GPU讨厌CPU。但百万美元的问题仍然存在:
"我应该实际下载哪种格式?"
在第3部分——"选择你的毒药:量化格式友好指南",我们将通过以下内容消除噪音:
- 一个简单的3问题决策树(RAM、上下文长度、耐心)
- 按用例的格式推荐(聊天、编码、长文档)
- 真正有帮助的快速调整(
threads、mmap、KV cache) - "我只想让它工作"的Windows入门包
不再有"试试这个看看"。
在那之前:如果你的本地AI感觉很慢,检查文件名。如果它以IQ开头,你可能不小心给你的CPU一个突击测验而不是一个任务。
换成Q4_K_M。看它飞起来。然后回来告诉我你的TPS。
原文链接: Byteshape's discovery: not all bits are created equal
汇智网翻译整理,发表于2026-03-19
