OpenCode 快速指南
大多数AI编码工具感觉就像SaaS套上了一层薄薄的IDE皮肤。OpenCode颠覆了这一点:它是一个开源编码智能体,作为你技术栈中的实际基础设施运行,而不是你编辑器中的玩具

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
大多数AI编码工具感觉就像SaaS套上了一层薄薄的IDE皮肤。OpenCode颠覆了这一点:它是一个开源编码智能体,作为你技术栈中的实际基础设施运行,而不是你编辑器中的玩具。
1、为什么OpenCode很有趣
如果你试过Copilot、Cursor或Cody,你已经知道这个模式了。你输入,它建议,你接受或拒绝。
那是多了几个步骤的自动补全。它不是智能体。
OpenCode试图成为更接近"住在你的仓库和工具中的AI开发者"的东西。不仅仅是更智能的自动补全,而是一个可编程的编码工作者,你可以将其接入CI、终端和编辑器。
关键转折:它是开源的、可自托管的、与提供商无关的。
所以不是"你所有的代码都流经某个创业公司的服务器",你得到的是:在本地运行它,指向你的模型,并像扩展任何其他后端服务一样扩展它。
如果你关心隐私、合规性,或者只是想黑你自己的工具,这非常重要。
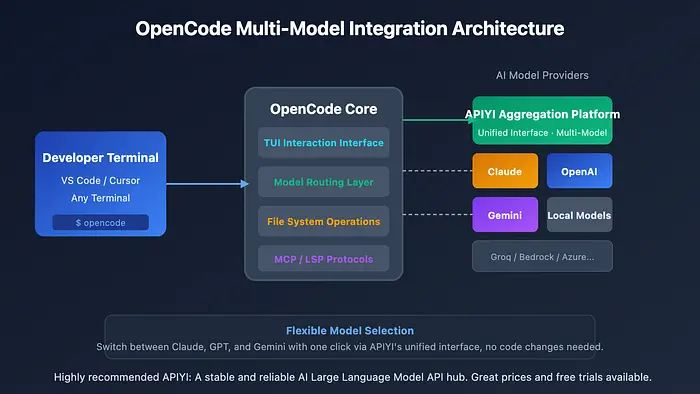
2、OpenCode到底是什么
在高层面上,OpenCode是三样东西。
它是一个与LLM和工具对话的后端服务。它是编辑器和终端的一组客户端。它是一个知道如何读取、修改和推理代码库的"智能体运行时"。
你可以把它看作"一个小型的、有主见的LangChain,但只专注于软件工程任务"。它有:
- 暴露HTTP和WebSocket API的服务器。
- 用于文件编辑、运行测试、搜索代码等的工具系统。
- 为模型索引和流式传输代码的项目上下文层。* 用于重构和错误修复等常见开发任务的工作流集。
重要的是你控制它在哪里运行以及它与哪个模型对话。这就是工程故事变得有趣的地方。
3、通俗易懂的架构
如果你剥去营销外衣,架构是这样的。
你在某个地方运行OpenCode服务器。它可以在你的笔记本电脑、开发VM或Kubernetes集群上。
该服务器有三个主要部分:
- 与一个或多个LLM提供商对话的模型连接器。
- 可以对你的文件系统或环境执行操作的工具运行器。
- 决定给定任务下一步做什么的智能体循环。
你的编辑器插件或CLI通过HTTP或WebSocket连接到该服务器。你发送一个任务,比如"修复这个测试"或"给这个服务添加日志记录",加上一些代码上下文。
智能体用一个包含你的代码、任务和它可以使用的工具的提示调用模型。模型用一个计划、工具调用和代码编辑来响应。
服务器执行那些工具调用,更新文件,可能运行测试,并将结果流式传输回你的客户端。从你的角度来看,它感觉像一个可以实际接触你的仓库的开发助手,而不仅仅是评论它。
这一切都是开源的意味着你可以:
- 添加你自己的工具。
- 交换模型后端。
- 为日志和指标检测整个循环。
这就是产品和基础设施之间的区别。
4、在本地运行OpenCode
如果你想把OpenCode当作你技术栈的严肃部分,你应该把它作为服务运行。本地优先是最简单的路径。
典型的开发设置如下:
- 在Docker中或直接在你的机器上运行OpenCode服务器。
- 配置它与你首选的LLM对话。
- 将你的编辑器或CLI指向
http://localhost:PORT。
YAML中的最小配置可能如下所示:
server:
host: 0.0.0.0
port: 8080
llm:
provider: openai
model: gpt-4.1
api_key_env: OPENAI_API_KEY
project:
root: /home/user/projects/my-app
ignore:
- node_modules
- .git
tools:
enable:
- file_edit
- search
- shell
这不是仓库中的确切配置文件,但它代表了大致的形状。你定义项目在哪里、允许哪些工具以及使用哪个模型。
从这里,你可以连接VS Code扩展或运行CLI,如:
opencode task "重构UserService以使用新的认证客户端"
服务器将读取你的项目,构建上下文,并启动任务循环。
5、智能体实际如何工作
"智能体"是那些被过度使用的词之一。所以让我们精确说明OpenCode做了什么。
在核心,OpenCode运行一个大致如下的循环:
state = init_task_state(request)
while not state.done:
prompt = build_prompt(state)
response = call_llm(prompt)
actions = parse_actions(response)
state = apply_actions(state, actions)
stream_updates(state)
有趣的部分是build_prompt、parse_actions和apply_actions。工程权衡就在那里。
5.1 提示构建
OpenCode需要给模型:
- 任务描述。
- 相关代码上下文。
- 工具描述和模式。
- 当前计划或进度。
它不能只是把整个仓库塞进提示。所以它使用代码搜索、嵌入和启发式方法来选择相关文件。
如果你完全不知道上下文选择是什么,把它想象成"智能grep加上向量索引"。它试图找到提到相关符号、路径或概念的文件,然后修剪它们以适应token预算。
5.2 工具使用
OpenCode定义了"读取文件"、"写入文件"、"搜索项目"、"运行测试"、"运行shell命令"等工具。这些作为结构化函数暴露给模型。
LLM用类似这样的东西响应:
{
"tool": "write_file",
"args": {
"path": "src/user/service.ts",
"patch": "@@ -10,6 +10,12 @@ ..."
}
}
服务器验证这个,应用补丁,并更新任务状态。然后它可以在你的编辑器或终端中显示一个diff。
关键是LLM不是直接写入磁盘。它提出结构化操作,服务器强制执行边界。
这就是你可以添加自己的护栏、批准或审查步骤的地方。
6、将OpenCode作为实际开发工具使用
让我们谈谈你作为工程师日常如何使用这个。不是作为演示,而是作为工作流。
6.1 模式:"在代码库中做这个更改"
你知道这种任务类型。重命名函数、迁移日志库、更改错误处理方式。
使用OpenCode,你可以这样表述:
opencode task "在非生产代码中将所有Logger.info迁移为Logger.debug,如果需要则更新测试"
智能体将:
- 搜索
Logger.info的使用。 - 提出更新它们的补丁。
- 可选地运行测试或代码检查器。
- 流式传输diff以便你审查。
你仍然拥有最终的git commit。但你不必手动追踪每个调用点。
6.2 模式:"解释并修改这个子系统"
这就是OpenCode的仓库级上下文发挥作用的地方。你可以要求它:
- 总结服务如何工作。
- 添加触及多个文件的功能。
- 保持更改与现有模式一致。
例如:
opencode task "使用用户服务中已有的跟踪库向支付服务添加请求跟踪"
智能体可以检查两个服务,弄清楚跟踪在一个地方是如何接入的,并在另一个地方镜像该模式。这种工作会耗费你一下午的时间,而这正是智能体擅长的。
6.3 与编辑器集成
大多数开发者不会整天在终端中操作。所以OpenCode提供钩入同一服务器的编辑器集成。
模型很简单。你的编辑器扩展:
- 知道OpenCode服务器URL。
- 发送任务以及当前文件和光标上下文。
- 接收流式更新和diff。
你获得内联编辑、代码操作和侧面板任务。从UX角度来看,它感觉类似于其他AI编码工具,但有一个很大的区别。
智能没有被烘焙到扩展中。它在你控制的后端服务中。
这意味着你可以:
- 在不更新扩展的情况下更新模型。
- 添加项目特定的工具。
- 在团队之间共享单个OpenCode服务器。
对于中型团队,共享的开发OpenCode实例可以放在CI运行器和制品注册表旁边。它成为另一块基础设施,而不是浏览器插件。
6.4 自托管和模型选择
OpenCode最强的部分之一是它不强制特定模型。你可以接入:
- 托管模型,如OpenAI、Anthropic等。
- 自托管模型,如Llama 3、Qwen或Mistral,通过OpenAI兼容端点。
如果你在API后面运行像vllm或llama.cpp这样的东西,你可以把OpenCode指向它。这让你将所有代码和提示保留在自己的硬件上。
典型的自托管设置:
- 在Docker中运行OpenCode。
- 在同一台机器或集群上运行LLM服务器。
- 用LLM API URL和密钥配置OpenCode。
权衡是可预测的。开源模型更便宜且私密,但在复杂重构或规划方面较弱。
你可以聪明一点,使用混合策略。例如:
- 使用本地小模型进行快速解释和小编辑。
- 仅对大型多文件任务使用托管前沿模型。
由于OpenCode只是你控制的服务,你可以在它前面放一个代理来放置那个路由逻辑,或者对不同任务使用不同的OpenCode实例。
6.5 用自定义工具扩展OpenCode
这就是OpenCode超越"Copilot但在你的服务器上"的地方。你可以教它你的系统如何工作。
想想对你的技术栈重要的工具:
kubectl用于集群状态。terraform用于基础设施更改。psql用于数据库内省。- 公司特定的CLI或内部API。
你可以用清晰的输入和输出模式将这些中的任何一个包装为工具。然后用"使用此工具检查生产日志,但永远不要写数据"这样的描述将它们暴露给智能体。
Python中的简单伪工具定义可能如下所示:
@tool(name="run_tests", description="运行当前项目的单元测试")
def run_tests(args: dict) -> dict:
result = subprocess.run(["pytest", "-q"], capture_output=True, text=True)
return {"exit_code": result.returncode, "stdout": result.stdout, "stderr": result.stderr}
OpenCode将序列化模式并将其传递给LLM。模型学习它可以调用run_tests来验证更改。
你可以更进一步,添加安全性:
- 限制可以触及哪些目录。
- 对某些工具要求人工批准。
- 记录所有工具调用用于审计日志。
现在你有了一个可以对你的实际系统进行操作的AI智能体,具有与任何其他自动化相同的纪律。
6.6 可观测性和调试智能体
如果你要把AI智能体信任给你的代码库,你需要可见性。这是你自己运行OpenCode的另一个优势。
因为它是你的服务器,你可以:
- 记录每个提示和响应。
- 跟踪工具调用、持续时间和失败。
- 衡量每个任务的token使用和延迟。
一个基本模式是将其接入你现有的技术栈。例如:
- 通过Prometheus导出指标。
- 将日志发送到Loki、Elasticsearch或你的云日志服务。
- 存储匿名化跟踪用于调试智能体行为。
当出问题时,你希望能够回答这样的问题:
- 为什么智能体决定触及这个文件?
- 哪个提示导致了这个糟糕的补丁?
- 是否有特定的模型版本导致回归?
因为OpenCode是开放的,你可以直接检测智能体循环。这对于只暴露高级分析的封闭工具几乎是不可能的。
6.7 风险和故障模式
让我们诚实一点。无论架构多么好,这仍然是一个LLM智能体。
你会遇到经典的故障模式:
- 过于自信的编辑微妙地破坏行为。
- 遗漏边界情况的部分重构。
- 对领域特定不变量的误解。
工程响应不是"更信任AI"。而是"把它当作拥有root权限的初级开发"。
这意味着:
- 在提交前始终审查diff。
- 使用测试和代码检查器作为护栏。
- 在生产环境中限制工具。
- 从只读或仅建议模式开始。
如果你建立适当的护栏和可观测性,OpenCode就成为强大的加速器。如果你让它在一个没有测试的单体应用中随意运行,它会伤害你。
这里没有魔法,只有权衡。
7、OpenCode在现代技术栈中的位置
如果你已经深入使用AI编码工具,OpenCode不是替代所有东西。它是不同的层。
这样想:
- 编辑器自动补全和内联建议:Copilot、Cursor等。
- 仓库感知的可以运行工具和工作流的智能体:OpenCode。
- 组织级知识和聊天:内部RAG系统、文档机器人。
OpenCode位于中间层。它是"在我的仓库中做工作"的引擎。
对于团队,现实的设置可能是:
- 开发者使用他们喜欢的AI编辑器插件处理小事情。
- OpenCode作为共享服务运行用于更大的任务和自动化。
- CI使用OpenCode为不稳定测试或样式违规提出修复建议。
这就是它不再成为玩具并开始成为基础设施的地方。
8、最后的思考
AI编码智能体正从"花哨的自动补全"转向"可编程工作者"。OpenCode是使该工作者开源、可自托管和可扩展的首批严肃尝试之一。
如果你关心:
- 将代码和提示保留在你自己的边界内。
- 将AI接入你现有的工具,而不是反过来。
- 将AI视为基础设施,而不仅仅是SaaS订阅。
那么OpenCode值得尝试。
从小处着手。在副项目上本地运行它,保持只读,观察它的行为。
然后,如果它赢得了你的信任,就提升它。给它工具、可观测性,以及在你技术栈中的真正位置。
那时,你不仅仅是在"使用AI"。你在运行一个你拥有、理解并能像任何其他工程基础设施一样演进的AI编码服务。
原文链接: Why OpenCode Is the First AI Coding Agent You Can Actually Own
汇智网翻译整理,转载请标明出处
