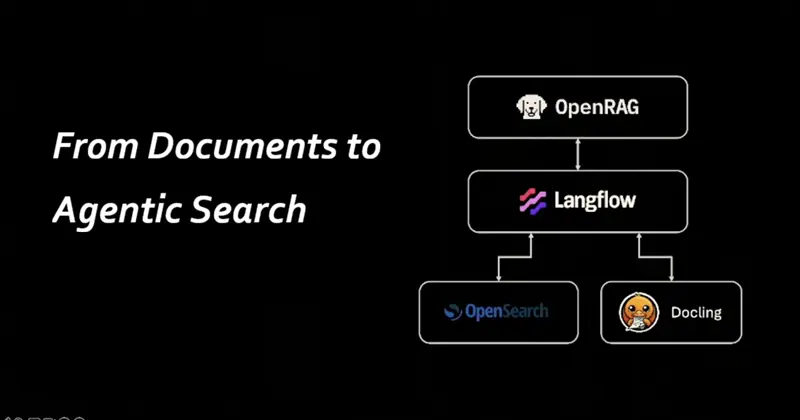
OpenRAG:从文档到代理化搜索
OpenRAG是一个全面的检索增强生成平台,可实现智能文档搜索和AI驱动的对话。用户可以通过聊天界面上传、处理和查询文档,该界面由大语言模型和语义搜索功能支持。
微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
之前我提到过接触“OpenRag”。现在我又回来了,不过这次我接触到的是一个不同的“OpenRAG”(注意大小写 😉)——这是来自IBM的版本。
说实话,别问我为什么它们有完全相同的名字;就像科技公司共享一个巨大的字母汤,不断拿出相同的字母一样。尽管存在身份危机,这个版本非常棒。安装速度之快会让你感到晕眩,而“准备就绪”的速度几乎达到了光速。
所以,在第三个OpenRAG出现之前,让我们直接进入主题吧!🪂
1、设置:五分钟内从零到RAG
如果你准备好动手了,直接前往 openr.ag。你可以点击 “Get Started” 进行快速浏览,或者直接进入 GitHub仓库。
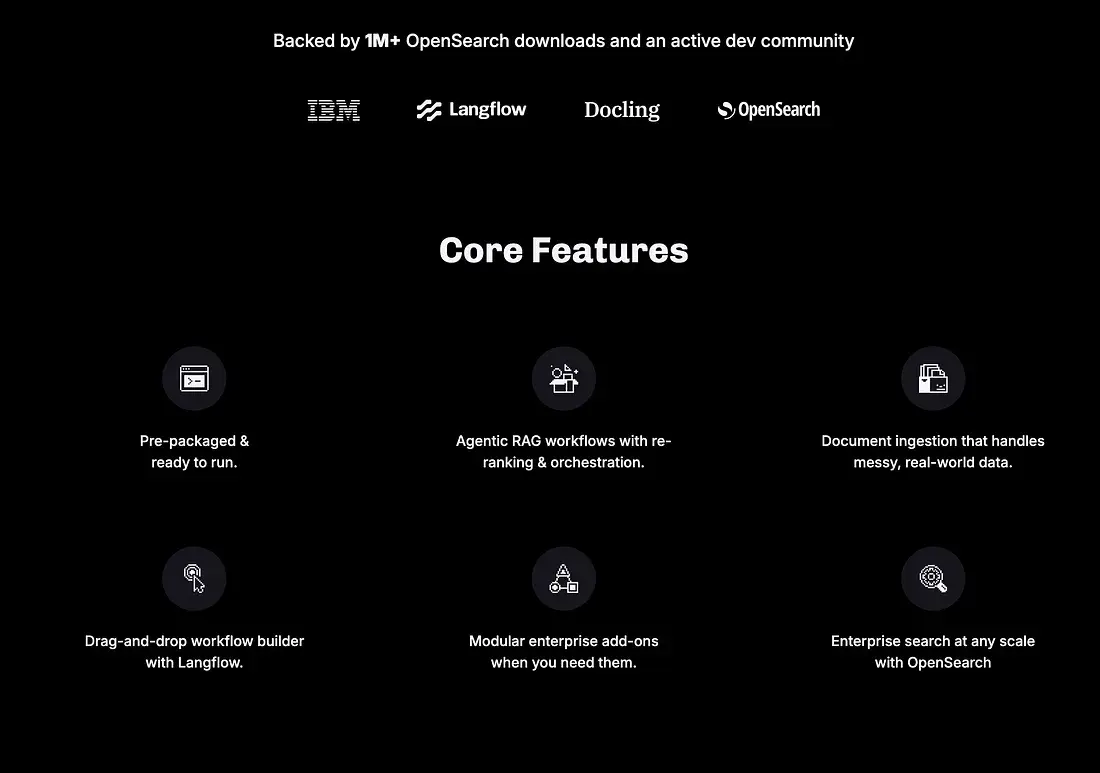
网页上清楚地展示了核心功能;
OpenRAG是一个全面的检索增强生成平台,可实现智能文档搜索和AI驱动的对话。用户可以通过聊天界面上传、处理和查询文档,该界面由大语言模型和语义搜索功能支持。系统利用Langflow进行文档摄入、检索工作流和智能提示,提供无缝的RAG体验。使用 Starlette 和 Next.js 构建。由 OpenSearch、Langflow 和 Docling 提供支持。
有一件事是肯定的:设置说明非常“整洁”。通常,“开源”意味着“花三个小时调试你的环境”,但在这里,你可以在不到五分钟内实际运行你的系统。
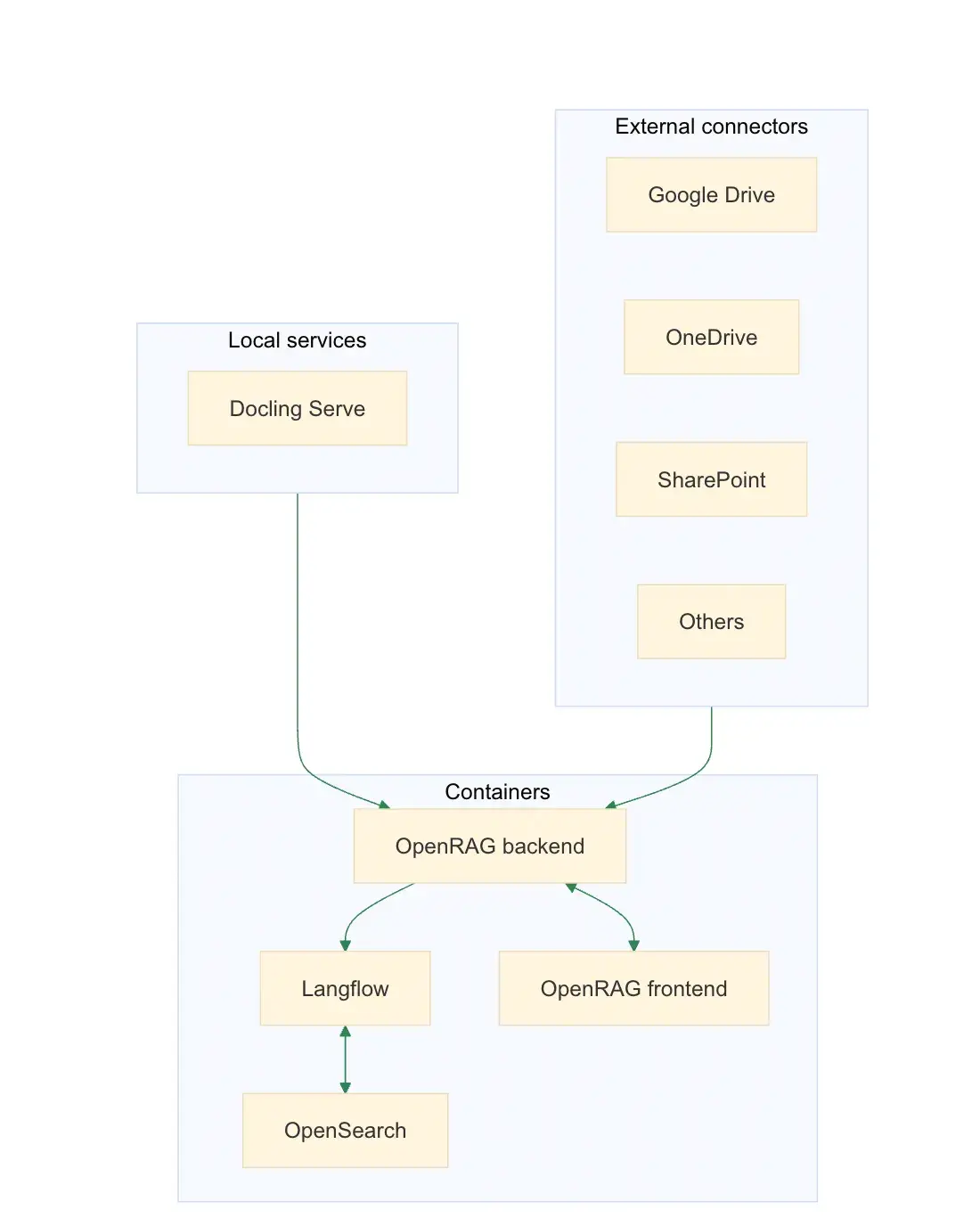
2、内部结构如何?
架构在文档中展示得非常清晰。然而,真正的“厨神之吻”功能是Docling的集成用于文档处理。
- 无需配置: 一开箱就能用。
- 无需操作的处理: 你根本不需要做任何事情来准备它——它会自己处理文档摄入的繁重任务。
3、从设置到界面的用户体验
对于这样一个强大的工具,UI出乎意料地直观。它干净、用户友好,不需要博士学位就能找到你需要的东西。让我们一步步来看,但在那之前,我应该提到我一如既往地使用Podman/Podman桌面本地搭配本地Ollama。
- 安装过程(从文档中)⚙️
mkdir openrag-workspace
cd openrag-workspace
####
# 我没有使用这个脚本!
####
curl -fsSL https://docs.openr.ag/files/run_openrag_with_prereqs.sh | bash
- 我设置OpenRAG本地的步骤;👣(Podman/Podman Desktop已经启动)
mkdir openragAAM
cd openragAAM
####
uvx openrag
uv run openrag
####
uv run openrag
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/documents
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/flows
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/keys
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/config
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/data
2026-01-08 13:03:01 [debug ] 确保目录存在:/Users/alainairom/.openrag/data/opensearch-data
2026-01-08 13:03:01 [debug ] 从 /Users/alainairom/.openrag/tui/.env 加载 .env 文件
- 拉取的镜像用于本地Podman/Docker运行
- 设置/配置屏幕

- 基本 设置
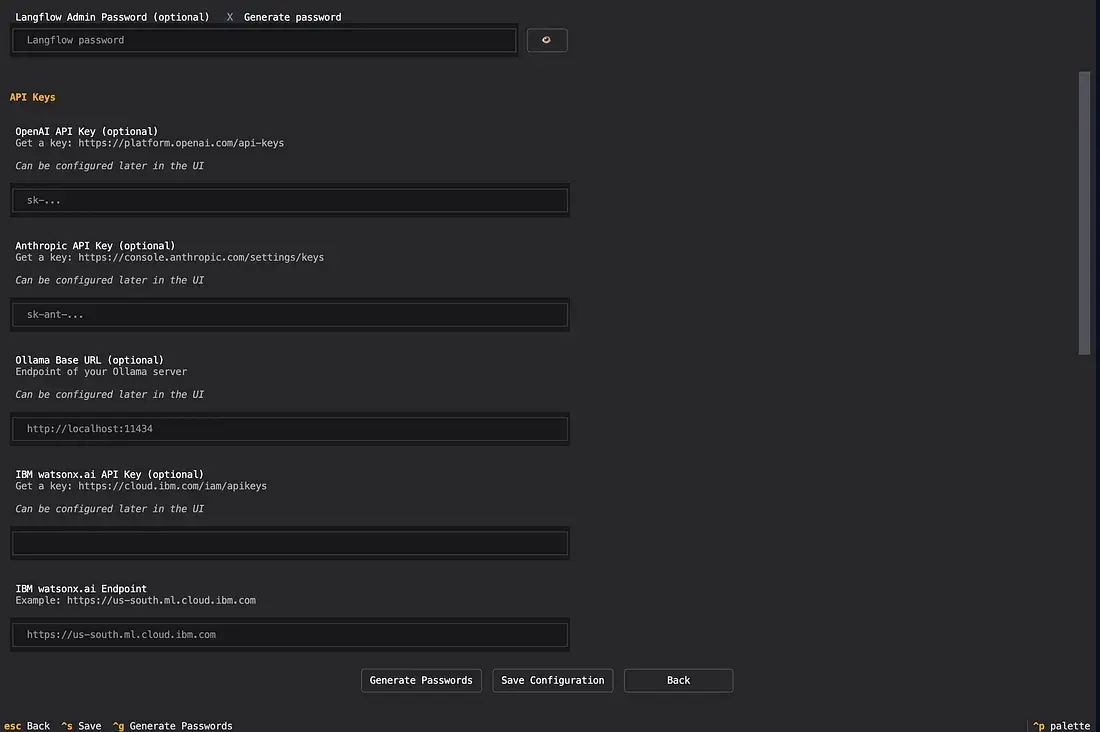
- 高级 设置
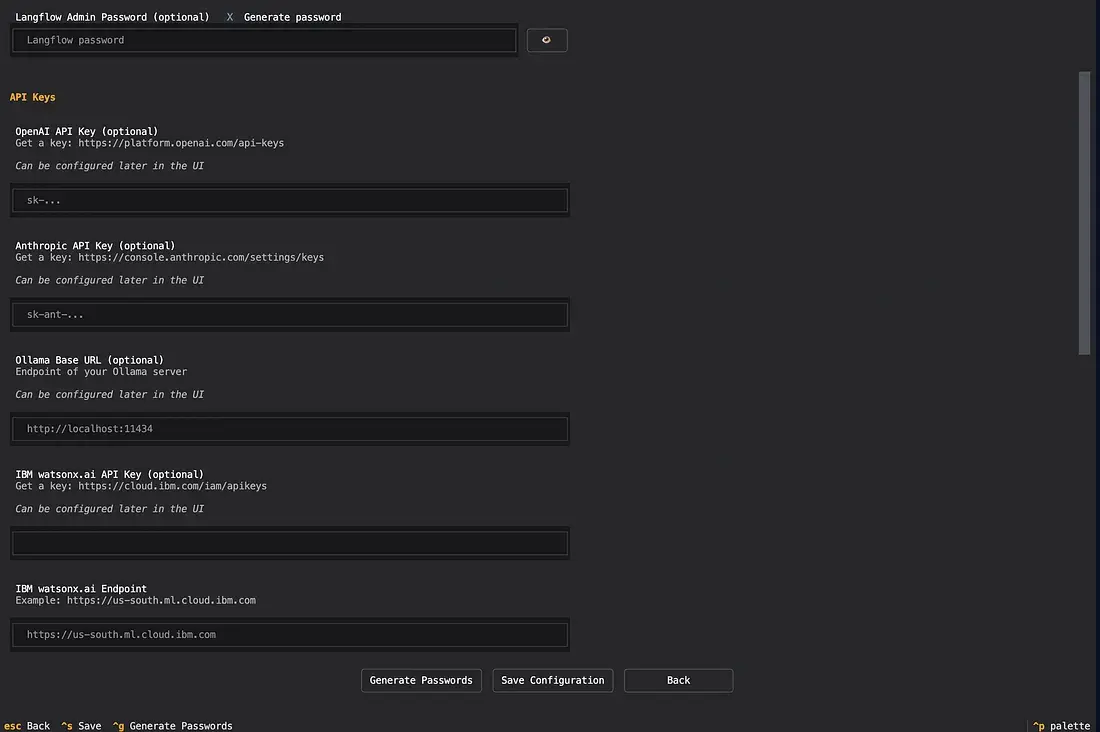
- 这些设置屏幕有助于通过非常整洁的界面更新用户的“.env”。
# 入职配置
# 设置为true以禁用Langflow入职并使用传统的OpenRAG处理器
# 如果未设置或为false,则将使用Langflow管道(默认:上传 -> 入职 -> 删除)
DISABLE_INGEST_WITH_LANGFLOW=false
# Langflow HTTP超时配置(以秒为单位)
# 对于大型文档(300+页),入职可能需要30+分钟
# 如果遇到非常大的PDF的超时问题,请增加这些值
# 默认:2400秒(40分钟)总超时,30秒连接超时
# LANGFLOW_TIMEOUT=2400
# LANGFLOW_CONNECT_TIMEOUT=30
# 如此创建:https://docs.langflow.org/api-keys-and-authentication#langflow-secret-key
LANGFLOW_SECRET_KEY=
# 聊天和入职流程的流程ID
LANGFLOW_CHAT_FLOW_ID=1098eea1-6649-4e1d-aed1-b77249fb8dd0
LANGFLOW_INGEST_FLOW_ID=5488df7c-b93f-4f87-a446-b67028bc0813
LANGFLOW_URL_INGEST_FLOW_ID=72c3d17c-2dac-4a73-b48a-6518473d7830
# 使用docling的入职流程
# LANGFLOW_INGEST_FLOW_ID=1402618b-e6d1-4ff2-9a11-d6ce71186915
NUDGES_FLOW_ID=ebc01d31-1976-46ce-a385-b0240327226c
# 为OpenSearch设置强管理员密码;此值在容器启动时生成bcrypt哈希。不要提交真实秘密。
# 必须与secureconfig中的哈希密码匹配,必须更改以用于安全部署!!!
# 注意:如果手动设置此值,它必须是一个复杂密码:
# 密码必须至少包含8个字符,并且必须包含至少一个大写字母、一个小写字母、一个数字和一个特殊字符。
OPENSEARCH_PASSWORD=
# 保存OpenSearch数据(索引、文档、集群状态)的路径
# 默认:./opensearch-data
OPENSEARCH_DATA_PATH=./opensearch-data
# 在此处创建:https://console.cloud.google.com/apis/credentials
GOOGLE_OAUTH_CLIENT_ID=
GOOGLE_OAUTH_CLIENT_SECRET=
# SharePoint/OneDrive的Azure应用注册凭证
MICROSOFT_GRAPH_OAUTH_CLIENT_ID=
MICROSOFT_GRAPH_OAUTH_CLIENT_SECRET=
# 具有访问您的S3实例权限的AWS访问密钥ID和秘密访问密钥
AWS_ACCESS_KEY_ID=
AWS_SECRET_ACCESS_KEY=
# 可选:可以从Google(等)路由的DNS以处理连续入职(类似ngrok的工具有效)。这启用了连续入职
WEBHOOK_BASE_URL=
# 模型提供商API密钥
OPENAI_API_KEY=
ANTHROPIC_API_KEY=
OLLAMA_ENDPOINT=
WATSONX_API_KEY=
WATSONX_ENDPOINT=
WATSONX_PROJECT_ID=
# LLM提供商配置。提供商可以是 "anthropic"、"watsonx"、"ibm" 或 "ollama"。
LLM_PROVIDER=
LLM_MODEL=
# 嵌入式提供商配置。提供商可以是 "watsonx"、"ibm" 或 "ollama"。
EMBEDDING_PROVIDER=
EMBEDDING_MODEL=
# 可选URL,用于在UI中将openrag链接到langflow
LANGFLOW_PUBLIC_URL=
# 可选:覆盖docling服务的主机(用于特殊网络设置)
# HOST_DOCKER_INTERNAL=host.containers.internal
# Langflow认证
LANGFLOW_AUTO_LOGIN=False
LANGFLOW_SUPERUSER=
LANGFLOW_SUPERUSER_PASSWORD=
LANGFLOW_NEW_USER_IS_ACTIVE=False
LANGFLOW_ENABLE_SUPERUSER_CLI=False
# Langfuse跟踪(可选)
# 从 https://cloud.langfuse.com 或您的自托管实例获取密钥
LANGFUSE_SECRET_KEY=
LANGFUSE_PUBLIC_KEY=
# 为空以使用Langfuse Cloud,或设置为自托管(例如 http://localhost:3002)
LANGFUSE_HOST=
- 浏览器UI(http://localhost:3000)。从这一点开始,你可以尝试与你的文档聊天!
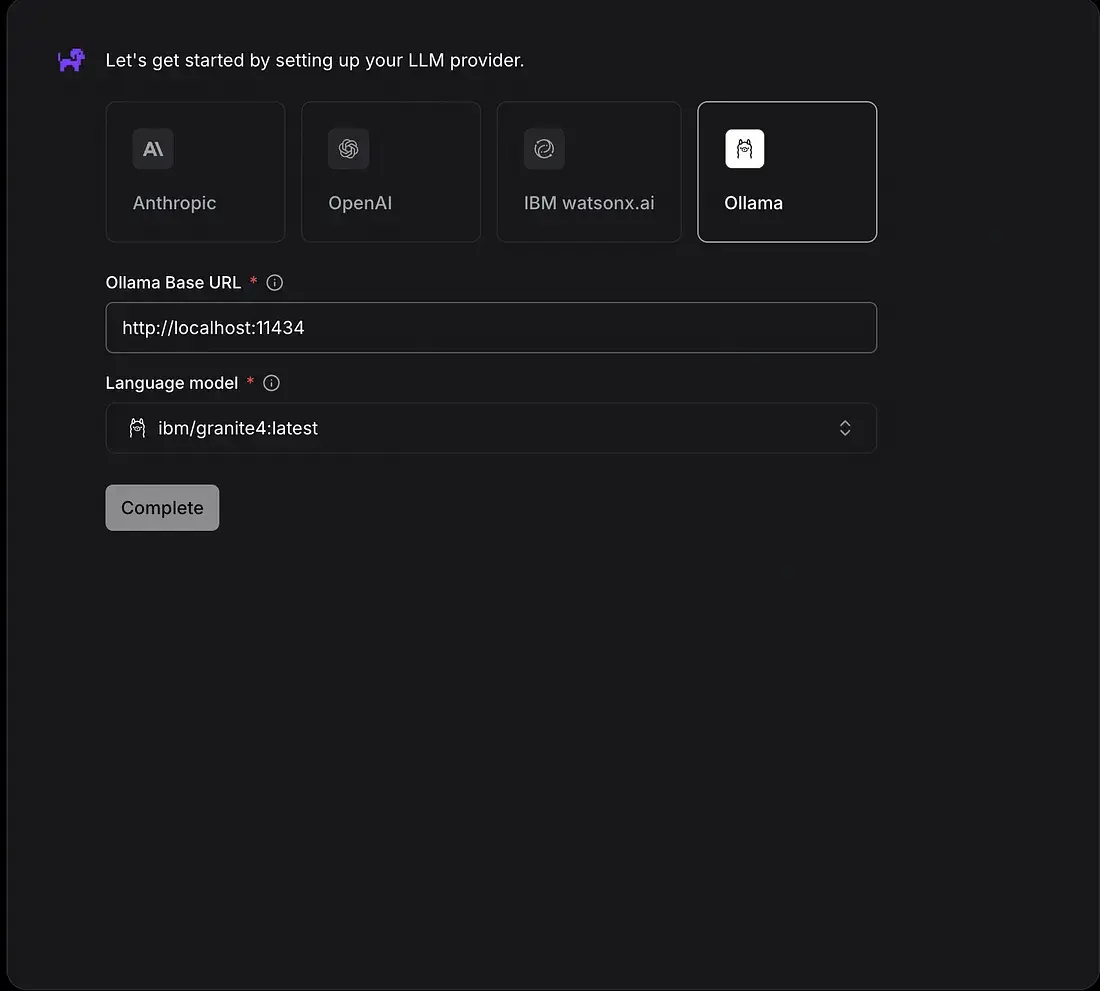
- 在作为工作区创建的文件夹中,创建了最小的Python代码; 😉
def main():
print("Hello from openragaam!")
if __name__ == "__main__":
main()
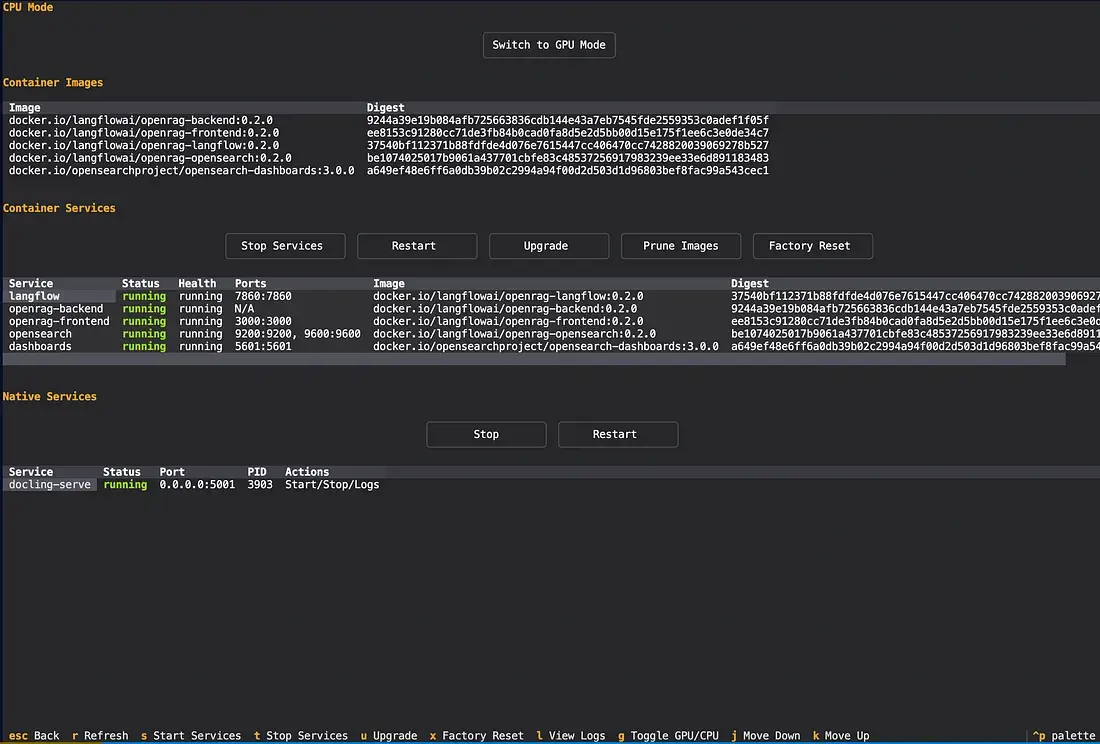
- 还可以切换CPU和GPU(如果你有的话)或对服务进行故障排除!
4、主要代码概述
在GitHub仓库中,我们可以导航到“/src/main.py”,这是主要逻辑的实现。
# 早期配置结构化日志
from connectors.langflow_connector_service import LangflowConnectorService
from connectors.service import ConnectorService
from services.flows_service import FlowsService
from utils.container_utils import detect_container_environment
from utils.embeddings import create_dynamic_index_body
from utils.logging_config import configure_from_env, get_logger
from utils.telemetry import TelemetryClient, Category, MessageId
configure_from_env()
logger = get_logger(__name__)
import asyncio
import atexit
import mimetypes
import multiprocessing
import os
import shutil
import subprocess
from functools import partial
from starlette.applications import Starlette
from starlette.routing import Route
# 设置多进程启动方法为 'spawn' 以兼容CUDA
multiprocessing.set_start_method("spawn", force=True)
# 首先创建进程池,再导入任何torch/CUDA
from utils.process_pool import process_pool # isort: skip
import torch
# API端点
from api import (
auth,
chat,
connectors,
docling,
documents,
flows,
knowledge_filter,
langflow_files,
models,
nudges,
oidc,
provider_health,
router,
search,
settings,
tasks,
upload,
)
# 现有服务
from api.connector_router import ConnectorRouter
from auth_middleware import optional_auth, require_auth
# API密钥认证
from api_key_middleware import require_api_key
from services.api_key_service import APIKeyService
from api import keys as api_keys
from api.v1 import chat as v1_chat, search as v1_search, documents as v1_documents, settings as v1_settings, knowledge_filters as v1_knowledge_filters
# 配置和设置
from config.settings import (
API_KEYS_INDEX_BODY,
API_KEYS_INDEX_NAME,
DISABLE_INGEST_WITH_LANGFLOW,
INDEX_BODY,
INDEX_NAME,
SESSION_SECRET,
clients,
get_embedding_model,
is_no_auth_mode,
get_openrag_config,
)
from services.auth_service import AuthService
from services.langflow_mcp_service import LangflowMCPService
from services.chat_service import ChatService
# 服务
from services.document_service import DocumentService
from services.knowledge_filter_service import KnowledgeFilterService
# 配置和设置
# 服务
from services.langflow_file_service import LangflowFileService
from services.models_service import ModelsService
from services.monitor_service import MonitorService
from services.search_service import SearchService
from services.task_service import TaskService
from session_manager import SessionManager
...
#######
#### 1000行后 :D
...
if __name__ == "__main__":
import uvicorn
# TUI检查已经在文件顶部处理
# 注册清理函数
atexit.register(cleanup)
# 异步创建应用
app = asyncio.run(create_app())
# 运行服务器(启动任务现在由Starlette启动事件处理)
uvicorn.run(
app,
workers=1,
host="0.0.0.0",
port=8000,
reload=False, # 由于我们从main运行,禁用重新加载
)
这里实现了一个高性能的 检索增强生成 (RAG) 后端,使用 Starlette 框架。它被设计为“即插即用”系统,连接文档处理(Docling)、向量存储(OpenSearch)和编排(Langflow)。
核心组件
- 向量引擎: 使用 OpenSearch 存储和搜索文档嵌入。
- 编排: 与 Langflow 集成以处理复杂的AI工作流和 MCP(模型上下文协议) 以管理服务器。
- 文档处理: 特色 Docling 用于“开箱即用”的文档摄入和解析。
- 认证: 支持 OIDC(开放ID连接) 用于用户和 基于API密钥 的认证用于外部集成。
4.1 运作机制
当应用启动时,它遵循严格的顺序以确保硬件和数据库的准备就绪:
- 硬件检查: 它强制使用
spawn方法进行多进程,以确保 CUDA(GPU) 兼容性,用于本地嵌入模型。 - 服务启动: 它初始化
SessionManager、DocumentService和TaskService(负责管理重型任务的进程池)。 - OpenSearch 准备就绪: 应用程序等待 OpenSearch 响应后再根据特定嵌入模型的维度创建动态索引。
- 自动摄入: 它扫描本地目录(
/app/openrag-documents)并自动摄入任何默认文件,使它们立即可搜索。
逻辑中的一个亮点是 ConnectorRouter。系统可以在两种方式之间切换处理数据:
- Langflow 连接器: 使用 Langflow 的可视化流水线进行摄入。
- OpenRAG 连接器: 使用传统、高速的内部处理引擎。
大多数端点遵循以下内部流程:
- 认证中间件: 检查有效的 JWT 或 API 密钥。
- 任务委派: 对于重任务(如上传 100 页的 PDF),API 不会让用户等待。它通过
TaskService创建一个 任务 ID,在后台进程池中处理文件,并允许用户轮询状态。 - 检索与聊天: 对
/v1/chat或/v1/search的请求使用配置的嵌入模型查询 OpenSearch 索引,并返回上下文感知的响应。
4.2 关于CUDA 和 GPU
正如我们在 main.py 文件中看到的(上面),OpenRAG 使用了一个定制的 进程池,使用 spawn 启动方法。这是一个关键的技术选择,原因如下:
- CUDA 兼容性: PyTorch 等库不是“fork-safe”。如果在 GPU 已初始化后进程 fork,子进程通常会继承一个损坏的状态,导致立即崩溃。通过使用
multiprocessing.set_start_method("spawn", force=True),OpenRAG 确保每个工作进程都从干净、独立的起点开始,这对于稳定的 GPU 加速嵌入和文档解析至关重要。 - 任务服务: 当你上传一个文档时,API 不会在主线程中处理它。相反,它将繁重的工作委托给
TaskService。该服务将任务推送到专用的进程池(在任何重大的 AI 导入之前初始化),以确保文档摄入永远不会阻塞聊天界面或 API 响应性。 - Docling 加速: OpenRAG 利用 Docling 并带有可选的 CUDA 加速。通过将这些 CPU/GPU 密集型布局分析任务卸载到后台进程,系统可以处理大量 PDF 而不会出现典型的低优化 RAG 实现中的“抖动”或内存峰值。
4.3 对用户的意义
这种“幕后”工程使得你提到的“火箭般的快速”准备就绪成为可能。因为系统主动管理其硬件资源和进程生命周期,它可以在部署后几乎立即创建索引并开始摄入文档。所有这一切——安全性、向量搜索和复杂的流程编排——都在 OpenRAG 框架内完成,使你能够专注于你的数据而不是基础设施。
5、结束语
OpenRAG 是协调 AI 生命周期每个阶段的核心引擎,从初始环境设置到复杂的文档检索。通过利用其模块化架构,系统将高速 Docling 摄入、动态 OpenSearch 索引和灵活的 Langflow 工作流无缝整合为一个统一的整体。无论是在管理安全的 OIDC 认证、通过专用池运行后台任务,还是提供用于用户交互的简洁 UI,OpenRAG 确保整个流程快速、开源且可以直接用于生产。
原文链接:“OpenRAG” From Documents to Agentic Search in Minutes
汇智网翻译整理,转载请标明出处
