递归自学习:为何此时至关重要
循环是机器学习的基本单元。模型进行预测,获得反馈,然后更新。

AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
循环是机器学习的基本单元。模型进行预测,获得反馈,然后更新。
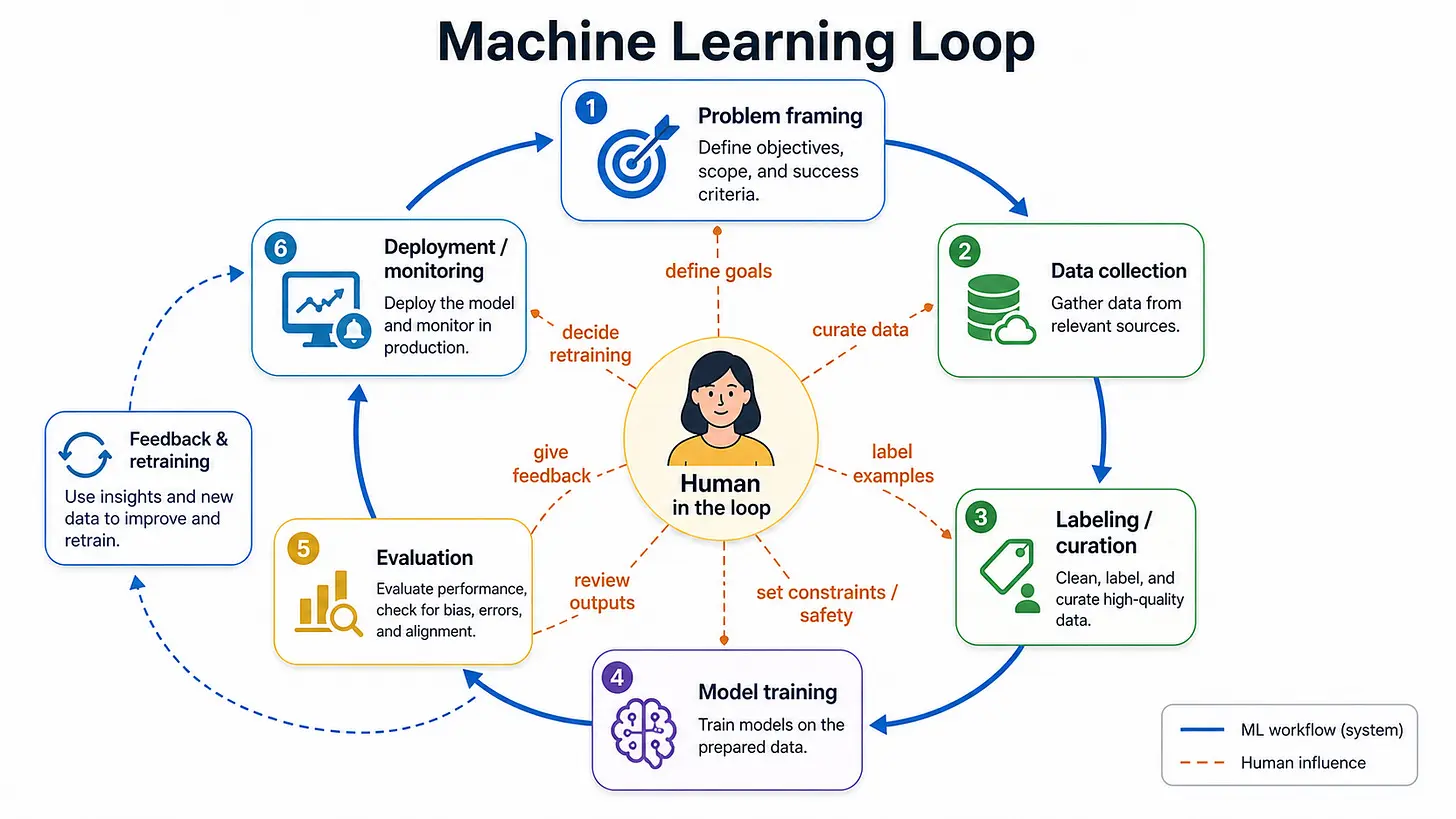
智能体也在做着类似的事情:编写代码、运行测试、编辑、再次运行测试。系统记录自己的失败,存储教训,下次尝试不同的路线。
在AI历史的大部分时间里,这个循环之外一直存在着一个常客:人类——用领域术语来说就是"人在环中"。而现在,人类成了瓶颈。
递归式自我学习(RSL)是一种改变这一现状的方式,它已经在推动边界的转移。
在他最近的推文中,Anthropic联合创始人、现任公共福利部门主管Jack Clark写道:
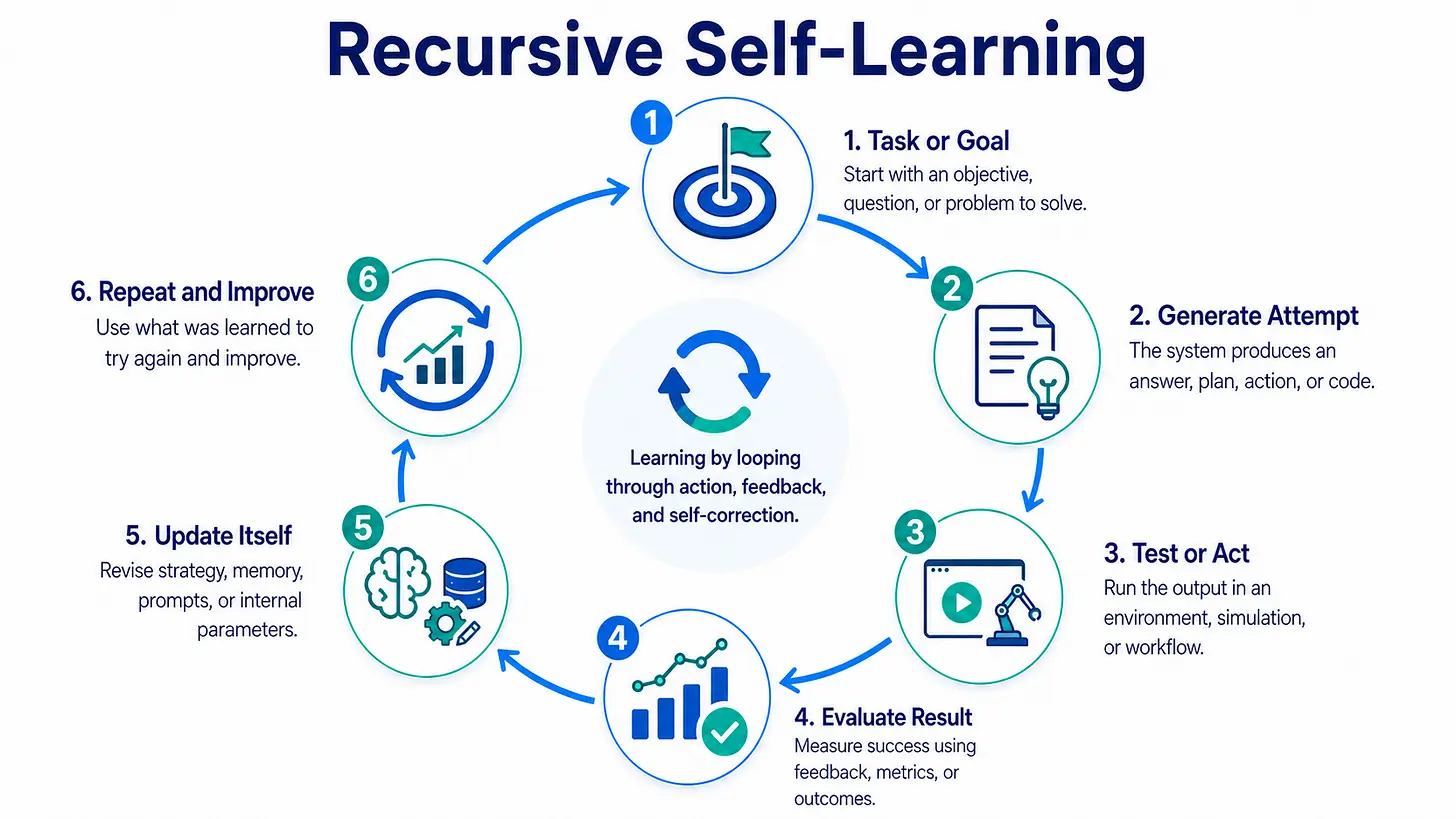
1、什么是递归自学习
这个想法最近即使没有命名也一直在流传。Andrej Karpathy的 autoresearch 是最简洁的小型示例。一个智能体被给予一个真实的LLM训练脚本,编辑代码,运行一个固定的五分钟实验,测量验证集的每字节比特数,如果改进了结果就保留修改,否则丢弃,然后重复。Autoresearch从循环中移除的是Karpathy——因为 Karpathy就是瓶颈。 他仍然设定指标、预算和初始研究计划。但他不再置身于每一次迭代之中。他已经向上提升了一个层次,从调整实验转变为设计调整实验的循环。
这是思考递归式自我学习的有用方式。它不是一个模型醒来并选择成为一个更好的模型。它是一个系统开始自动化该系统——或类似系统——变得更好的过程中的部分环节:编写代码、生成训练数据、运行实验、优化内核、微调模型、构建评估、改进提示词、改进工具,最终帮助训练后继系统。
2、递归式自我学习的历史
这个想法比这个领域本身还要古老。 1950年,艾伦·图灵提出构建一个"儿童机器"并教育它,而不是直接编程出成人的智能。20世纪50年代末,亚瑟·塞缪尔的跳棋程序通过自我对弈得到改进,证明了机器可以在无需每次改进都手工编码的情况下变得更好。I.J. Good在1965年提出了这个论点的最强版本:如果设计更好的机器本身是一项智力任务,那么一个在智力任务上比人类更优秀的机器将会设计出更优秀的机器。Jürgen Schmidhuber在2003年用 哥德尔机 给这个循环赋予了形式化的表达——一个一旦能证明重写是一种改进就重写自己代码的系统。在六十多年的时间里,几乎所有这一切都停留在理论层面。
实际版本则较为狭隘。AlphaGo Zero通过自我对弈得到了改进,但围棋是一个封闭的世界:固定的规则、清晰的奖励、没有隐藏状态。AutoML、神经架构搜索、自蒸馏和合成数据流水线都增加了各种组件——证明了机器可以帮助改进机器学习系统,但始终在人类构建的框架之内。
3、现在的变化是,这个循环正在进入AI研发本身
AI研究有一个不寻常的特性:大部分工作已经数字化了。代码、数据、训练运行、评估脚本、基准测试、日志、仪表板。日常工作并非闪电般的洞察;而是运行变体、发现错误、提高吞吐量、测试想法、比较分数,以及决定下一步尝试什么。这使得它在可自动化方面比生物学研究等更容易处理。
这是Jack Clark最新 Import AI 文章的核心。他的核心主张是,"无人参与的AI研发"——一个能够训练自己后继者的系统——在2028年底前出现的概率超过60%。这个论点并非基于某一项基准测试,而是累积效应:SWE-Bench、METR时间跨度、CORE-Bench、MLE-Bench、PostTrainBench、内核优化、自动化对齐研究,以及AI系统管理其他AI系统。他的论证是一幅由开始连接的部分循环组成的马赛克拼图。
从 No Priors播客 中我们了解到,根据Karpathy的说法,RSL最有趣的版本可能是前沿实验室已经在进行的工作:在较小的模型上进行实验,使过程尽可能自主,并尽可能将研究人员从执行循环中移除。研究人员仍然可以贡献想法,但他们不应该手动执行每一个想法。这极大地改变了研究人员的工作性质。
学术界也开始跟上这个框架。ICLR 2026递归式自我改进研讨会 将该领域描述为从推测性愿景向具体系统问题的转变:改变什么、何时改变、改变如何产生、系统在何处运行,以及对齐、评估和回滚应该如何工作。递归式自我学习已经获得了一些实践分量,正在成为一个有参数的设计问题。
甚至还有一个刚成立一个月、名为"Recursive Superintelligence"的初创公司,刚刚为自我学习AI筹集了5亿美元。所以,你知道,这一切都是认真的。
4、我想以此作为结尾
几十年来,我们构建了在循环内学习的系统。我们现在正在构建可能学会如何构建循环的系统。 我们将与它们一起学习:一旦系统也在帮助决定什么算作"更好","更好"又意味着什么。
这里还有另一项义务。当一个系统开始自主进化时,它需要严格的、持续的验证和对齐,以便其改进循环始终锚定在人类安全和福祉之上。这两个都是非常困难的问题,因为我们仍然不太清楚这些机器是如何"思考"的。
原文链接: FOD#151: Recursive Self-Learning: Why It Matters Now
汇智网翻译整理,转载请标明出处
