旋转位置编码(RoPE)简明教程
RoPE,即旋转位置编码,采用了一种巧妙的方法来同时融入相对和绝对位置信息。
AI模型价格对比 | AI工具导航 | ONNX模型库 | Vibe Coding教程 | PLC在线仿真器 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
旋转位置编码(Rotary Position Embedding,RoPE) 已被广泛应用于最近的大语言模型(LLM)中来编码位置信息,包括Meta的LLaMA和Google的PaLM。
位置信息在序列模型中至关重要,而位置编码在基于Transformer的架构中扮演着重要角色。RoPE,即旋转位置编码,采用了一种巧妙的方法来同时融入相对和绝对位置信息。
1、重新思考注意力乘积
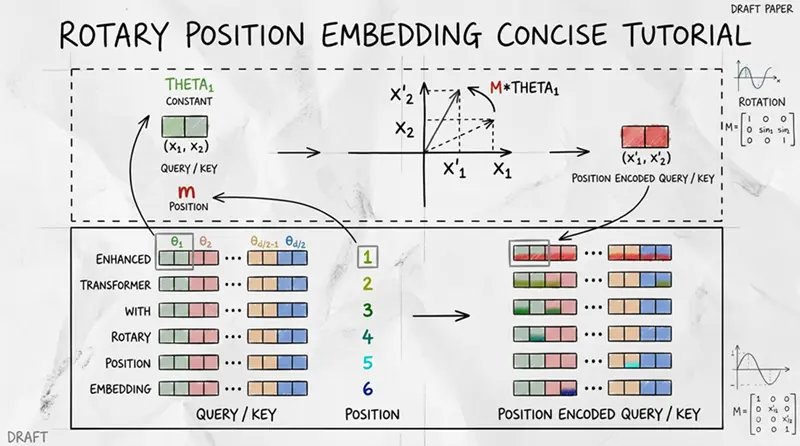
在介绍RoPE之前,让我们回顾一下注意力机制的基础知识。注意力关注的是成对关系:一个token有一个查询向量q,另一个token有一个键向量k。我们通过计算q和k的内积来获得注意力分数,而这个内积正是位置编码发挥作用的关键。
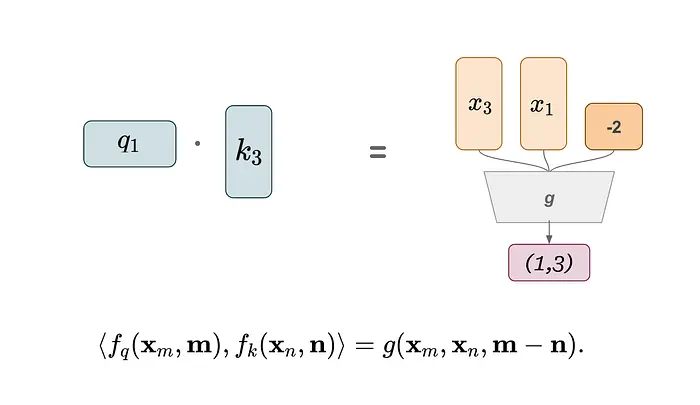
例如,要获取位置对(1, 3)的注意力分数,我们从token 1获取查询向量,从token 3获取键向量。
我们通过token编码器首先提取token的嵌入来获得查询向量q1。然后,我们将该嵌入及其位置信息输入位置+注意力编码器,该编码器整合位置信息并投影结果以产生键向量。
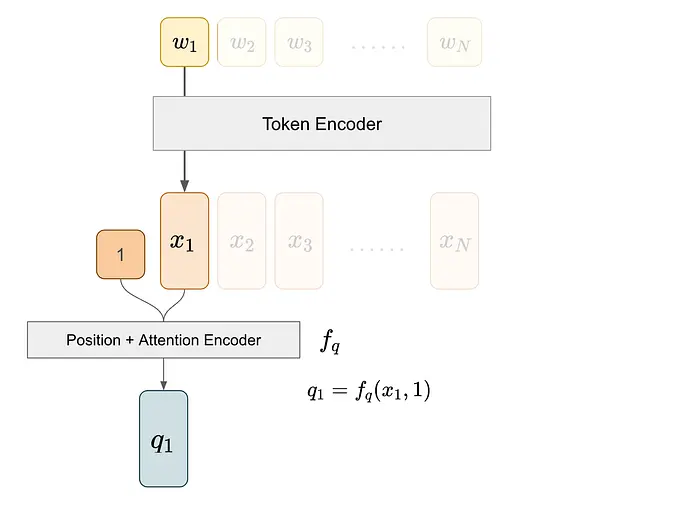
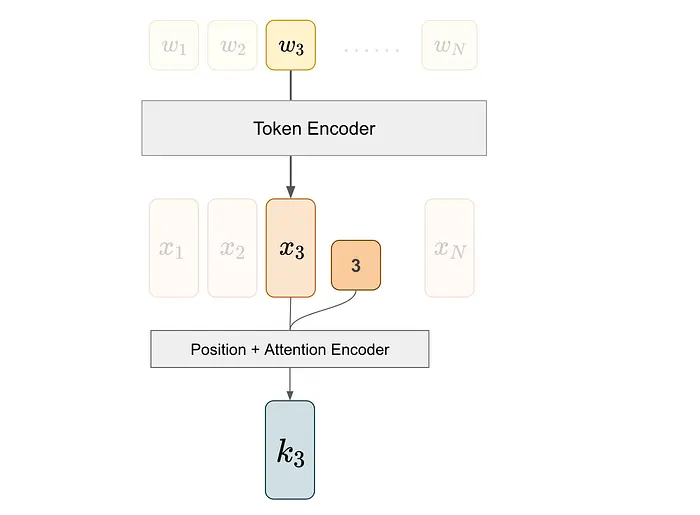
我们对第三个token执行类似的过程来获得k3,即token 3对应的键向量。
最后,我们计算q1和k3的内积来确定(1, 3)的注意力分数。在下面的等式中,尖括号 <>表示内积,x表示token嵌入,f是注意力+位置编码器。
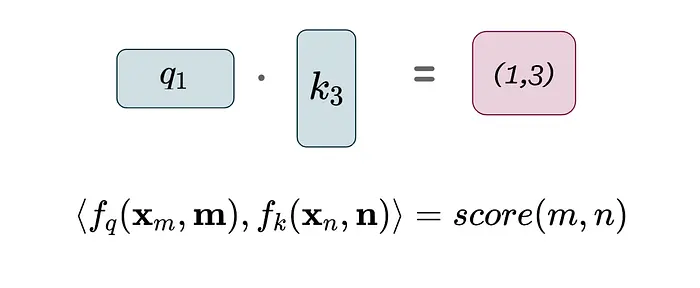
作者随后反思了这一公式,并意识到在这种设置中,相对位置信息在内积之前就被编码了——这意味着它本质上与token嵌入绑定在一起。
他们问自己:"是否存在另一种方式,只在需要注意力分数时——即执行q,k内积的那一刻——才编码相对位置信息?"或者等价地说,q,k内积等价于另一个函数g,该函数只以token嵌入及其位置作为输入?
这就是RoPE位置编码发挥作用的地方。
2、RoPE的直觉:二维简单情形
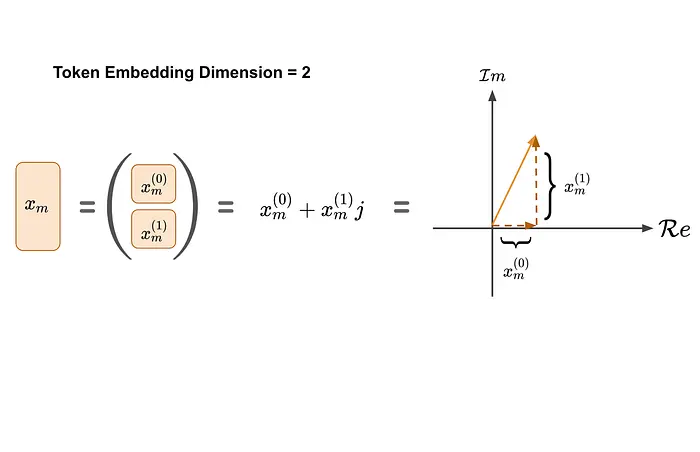
作者首先考虑一个简单的二维情形,其中token嵌入和注意力向量(查询、键)都位于二维空间中。为方便起见,这些二维向量也可以用复数表示(如图所示)。
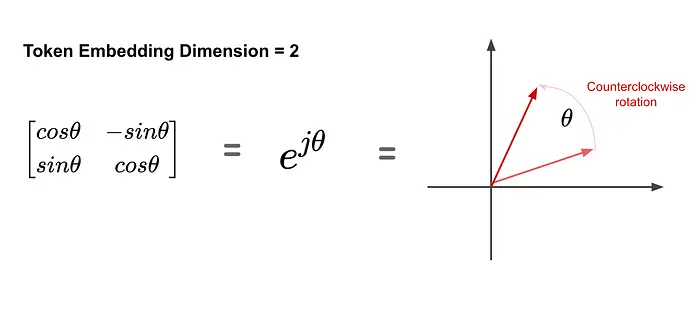
逆时针旋转矩阵可以用矩阵形式和指数形式两种方式表示。
类似地,我们可以用二维矩阵表示从token嵌入到键或查询向量的投影。

作者发现满足以下条件的一种可能解(即f和g的变换):
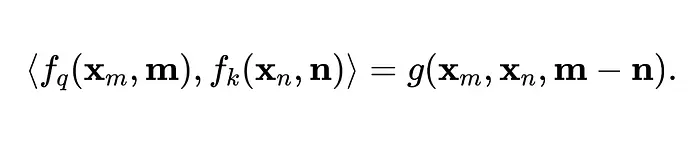
具有以下形式:
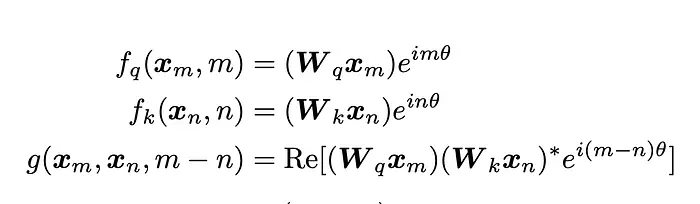
或用图形表示:
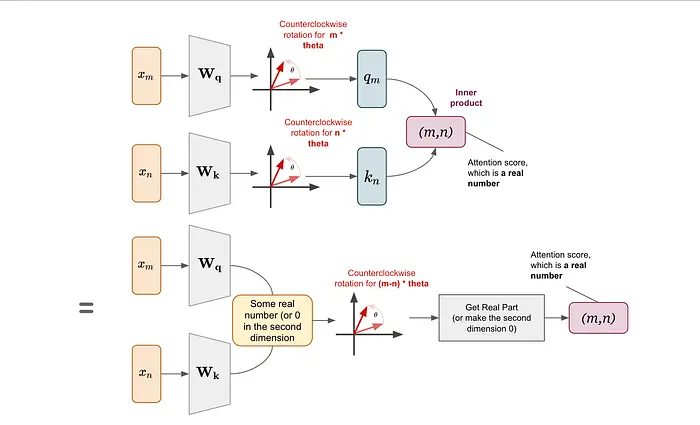
简而言之,这意味着经过变换后,我们可以先旋转再计算内积,也可以先计算内积再旋转,然后取实部。在第二种方法中,我们只需要(m–n)来进行旋转,这表明这是一种相对位置编码。
这就是旋转位置编码(RoPE)背后的直觉:只需将经过仿射变换的词嵌入向量旋转一个与其位置索引成正比的角度即可。
3、RoPE的一般形式
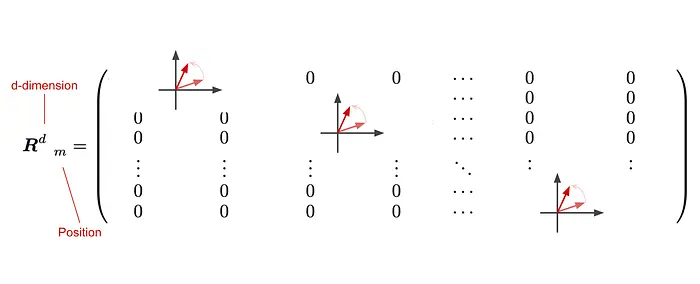
要将其推广到d维情形,考虑旋转矩阵的形式。作者首先假设d为偶数,因此可以将其分为d/2个块。每个块独立执行一次二维旋转:
现在,问题是:每个块旋转多少?回顾正弦位置编码在Transformer中的应用方式,其使用的角度参数为:
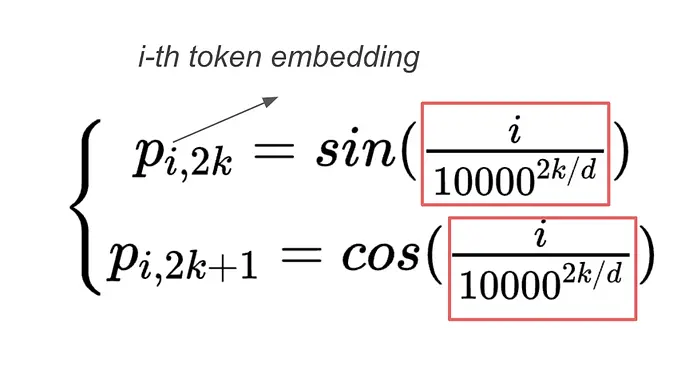
遵循这一实现方式,作者采用了类似的参数:
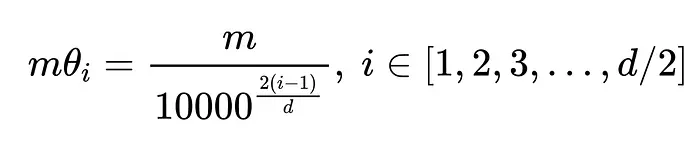
这里,i表示第i个子块,m·θ决定了对应子块的旋转角度。因此,旋转矩阵的一般形式为:
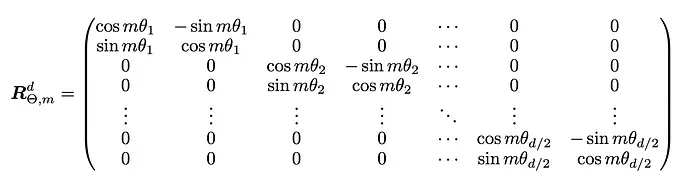
而应用于token嵌入的整体变换为:
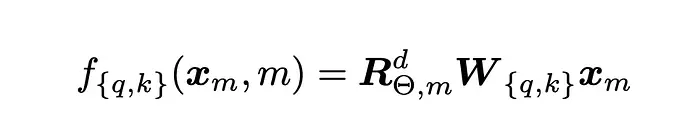
其中W是查询或键向量的d维仿射变换,R是上述旋转矩阵。下面是原论文中的图形解释。
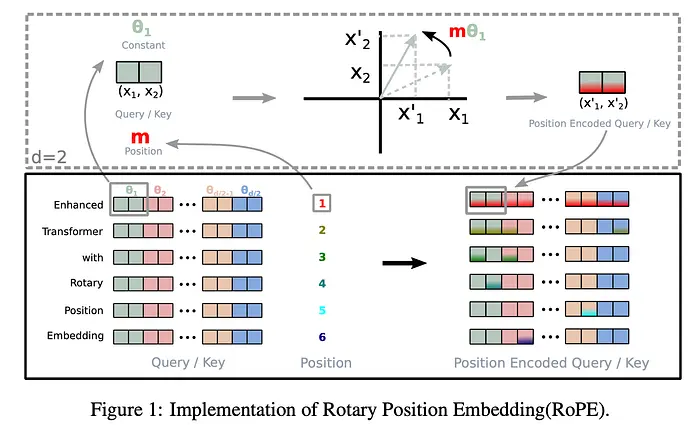
注意旋转矩阵R非常稀疏,因此直接乘法效率不高。取而代之,一种计算上更高效的R乘法实现如下:
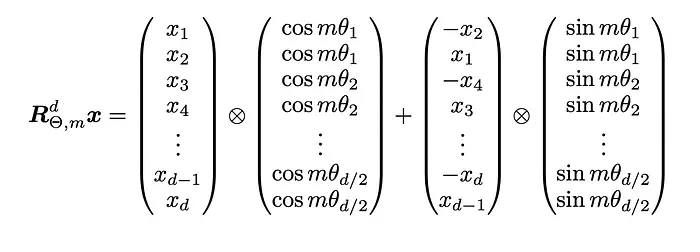
这里,带有圆圈和十字的运算符(⊗)表示逐元素(Hadamard)乘积。
4、RoPE如何改进语言模型
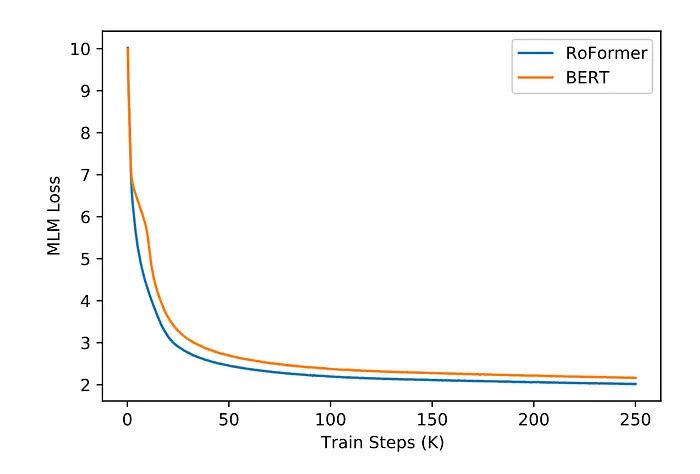
在原始RoPE论文中,作者通过在预训练阶段用RoPE替换BERT原有的正弦位置编码来验证其性能,得到的模型被称为RoFormer。在预训练过程中,掩码语言建模(MLM)损失表明,使用RoPE的BERT收敛更快。
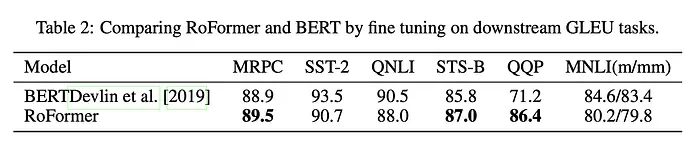
预训练完成后,作者在各种GLUE任务(NLP任务)上微调预训练的RoFormer权重,以评估其在下游NLP任务中的能力,RoFormer在6个数据集中的3个上优于BERT。
原文链接: RoPE: A Detailed Guide to Rotary Position Embedding in Modern LLMs
汇智网翻译整理,转载请标明出处
