在GCP上运行autoresearch
本文将介绍我如何将autoresearch部署到端到-end Google Cloud栈上运行

微信 ezpoda免费咨询:AI编程 | AI模型微调| AI私有化部署
AI工具导航 | Tripo 3D | Meshy AI | ElevenLabs | KlingAI | ArtSpace | Phot.AI | InVideo
Andrej Karpathy最近开源了autoresearch,这是一个将真实LLM训练环境交给AI代理并让它自主实验的项目。代理修改模型代码,训练恰好5分钟,检查验证损失是否改善,保留或丢弃更改,然后重复。你去睡觉;醒来时会看到实验日志,以及——但愿如此——一个更好的模型。
本文将介绍我如何将autoresearch部署到Google Cloud栈上运行:Gemini CLI驱动自主研究循环,Gemini 3 Flash Preview提供智能,Cloud Run提供按秒计费的无服务器NVIDIA L4 GPU,Cloud Workflows在1小时GPU超时时限之外串联多小时研究,以及带有防火墙规则的VPC锁定代理的网络访问。这一切无需基础设施管理,成本低于每小时2.00美元!
1、我的第一个实验
让我们直接进入autoresearch的工作原理,看看我的结果,然后我会逐步讲解运行过程。
autoresearch设计简洁,包含三个文件:
prepare.py处理数据和评估train.py包含模型架构、优化器和训练循环program.md是一个纯英文指令文件,你在这里定义研究策略
它使用git跟踪每个实验,在训练前提交每次更改。如果结果退化,它会运行git reset --hard回退到上一个已知的良好状态。
在我第一个小时的实验中,以下是代理生成的results.tsv:
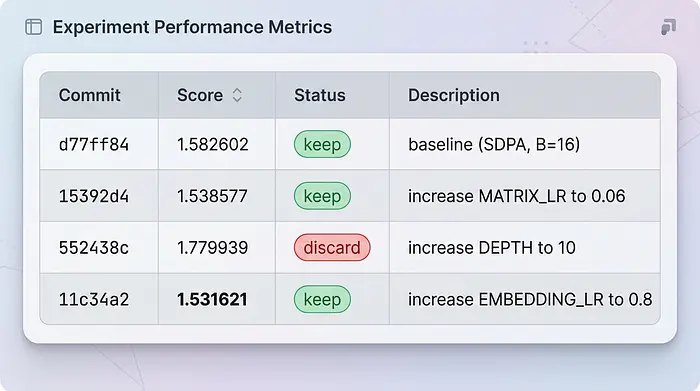
它首先建立了1.58的基线损失,然后提高了学习率,改进到1.53。接下来,它尝试将模型深度从8层增加到10层,但这使损失增加到1.77。代理识别出这种退化,丢弃更改,用git reset --hard回退,并在剩余时间里调整嵌入学习率,最终在实例终止前达到1.531。
2、经验教训
你可能注意到上面的示例表中只有四次成功的实验。在我第一次运行时,代理花了前15分钟在CUDA显存不足(OOM)错误上崩溃。好消息是它自主诊断了问题,并意识到需要降低DEVICE_BATCH_SIZE。
为了避免将来代理在这个问题上浪费时间,我已更新了我的实现,在使用24GB显存的L4 GPU时从一开始就修补此设置:
# Pre-tune the batch size for NVIDIA L4 GPUs to avoid initial OOM troubleshooting
RUN sed -i 's/DEVICE_BATCH_SIZE = 128/DEVICE_BATCH_SIZE = 16/g' train.py
其次,你可能想知道:如果每次训练运行严格限制在5分钟,一小时不应该产生12次实验吗?实际上,你可以预期每小时大约6到8次实验。虽然训练块正好是5分钟,但PyTorch在每次运行前需要大约2-3分钟为L4 GPU优化计算图。加上代理"思考"和推送代码到Git仓库的30秒,每个完整的研究周期大约需要8分钟。
3、Gemini CLI如何驱动研究循环
Gemini CLI是让autoresearch实现自主化的关键。它是一个开源编码代理,在你的终端中直接运行Gemini模型,使用ReAct循环(推理和行动)来读取代码、执行shell命令、观察结果并决定下一步:无需人工输入。
Karpathy的program.md用自然语言描述实验循环:修改train.py、提交、运行训练、检查结果、保留或回退。Gemini CLI读取这些指令,解释它们,并在连续循环中执行相应的shell命令、文件编辑和git操作。
4、无头模式和YOLO模式
对于无人值守的容器化执行,两个CLI标志至关重要:
--prompt(-p):将初始指令作为命令行参数传递并激活无头模式。CLI立即开始工作,无需等待用户输入。--yolo:自动批准所有操作,无需确认提示。无人值守执行必需。
gemini --prompt "Hi have a look at program.md and let's kick off a new experiment!" \
--yolo --model gemini-3-flash-preview
5、program.md如何提供上下文
Gemini CLI从项目中的GEMINI.md文件加载上下文。autoresearch使用program.md实现相同目的:一套定义实验的结构化指令集。
当容器启动时,CLI读取代码库(包括program.md)并接收--prompt作为第一条用户消息。提示"Hi have a look at program.md and let's kick off a new experiment!"引导代理查看指令并启动LOOP FOREVER循环。从那时起,代理自主运行:提出更改、运行训练、解析结果、推进或回退分支,直到容器超时。
6、以作业形式运行实验
虽然你可以在本地运行autoresearch,但Cloud Run Jobs为GPU工作负载提供了具有按秒计费的无服务器环境。这对于需要间歇性、高计算爆发的研究循环来说是理想选择。这种架构的优势包括:
- 按需GPU:通过部署标志轻松附加NVIDIA L4 GPU(或RTX PRO 6000 Blackwell等其他GPU)
- 按秒计费:只在容器活跃时付费
- 扩展和并行性:可以并行启动多个作业,同时探索不同的架构分支
- 零基础设施管理:Cloud Run处理所有配置和扩展
(在运行下面的Cloud Run作业命令之前,你必须有一个预配置的Docker容器和Google Cloud环境设置。这些先决条件在本文后面的"构建自主容器"部分有说明,完整源代码可在github.com/kweinmeister/autoresearch-serverless获取。)
6.1 创建Cloud Run作业
gcloud run jobs create autoresearch-job \
--image us-central1-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/autoresearch-job \
--execution-environment gen2 \
--cpu 4 \
--memory 16Gi \
--gpu 1 \
--gpu-type nvidia-l4 \
--no-gpu-zonal-redundancy \
--set-secrets="GEMINI_API_KEY=gemini-api-key:latest" \
--set-env-vars="BUCKET_RESULTS_DIR=${BUCKET_RESULTS_DIR}" \
--add-volume=name=results-vol,type=cloud-storage,bucket=${BUCKET_NAME} \
--add-volume-mount=volume=results-vol,mount-path=/mnt/results \
--max-retries 0 \
--task-timeout 1h \
--region us-central1
6.2 使用RTX PRO 6000进行扩展
对于要求更高的研究,你可以将L4换成NVIDIA RTX PRO 6000 Blackwell GPU。凭借96GB显存和大约6倍更快的令牌吞吐量,每个5分钟的训练窗口可以覆盖更多的内容。
RTX PRO 6000目前处于预览阶段,需要使用gcloud beta前缀。Dockerfile还包含一条指令,让代理自动检测Blackwell GPU并用PyTorch内置的SDPA替换Flash Attention 3,后者目前缺乏Blackwell优化的内核。
6.3 启动研究
你可以使用烘焙到容器中的提示启动作业。此示例实现需要更新Dockerfile中的提示以避免提示注入攻击。
gcloud run jobs execute autoresearch-job --region us-central1
你也可以将RESUME变量设置为false,如果你想让代理忽略以前的历史记录并完全从头开始:
gcloud run jobs execute autoresearch-job \
--region us-central1 \
--update-env-vars RESUME="false"
Cloud Run作业对使用GPU的任务有1小时的超时限制。虽然这自然形成了一个计费上限,但也意味着本地文件系统和.git历史在实例终止时会丢失。
如果你需要长达6小时,加入长时间运行作业的候补名单。这是运行夜间作业的最简单方式:只需在提交作业时设置--task-timeout 6h。
6.4 使用Workflows和GCS检查点串联作业
为了在1小时边界之外持久化研究,我使用Cloud Storage卷挂载创建检查点系统。我修补program.md以在每次成功训练后立即触发sync.sh脚本同步到GCS。
这使Google Cloud Workflows能够实现"发射后不管"的编排,将多个1小时作业串联成一个连续循环。当一个执行超时时,Workflows自动启动下一个,它下载最新的检查点并从上一个实例离开的地方继续。
我的工作流根据需要重新启动作业以达到所需的研究时长:
# Orchestration loop to chain 1-hour executions
- check_condition:
switch:
- condition: ${elapsed_seconds < total_seconds}
next: execute_job_step
next: end_study
- execute_job_step:
call: googleapis.run.v2.projects.locations.jobs.run
args:
name: ${"projects/" + project_id + "/locations/" + region + "/jobs/" + job_name}
next: increment_counter
- increment_counter:
assign:
- elapsed_seconds: ${elapsed_seconds + job_timeout}
next: check_condition
你可以部署并执行此工作流,例如使用hours参数让研究代理连续运行24小时:
gcloud workflows deploy autoresearch-study --source=workflow.yaml --location=us-central1
gcloud workflows execute autoresearch-study --data='{"hours": 24}' --location=us-central1
7、构建自主容器
自定义容器将上游autoresearch代码与Cloud Storage同步逻辑和Gemini CLI代理集成在一起。
7.1 检查点同步
我使用sync.sh脚本在每次实验后将结果持久化到GCS:
sync_to_gcs() {
local src="$1"
local dest="/mnt/results/${BUCKET_PATH}/$2"
if [ -e "$src" ]; then
cp "$src" "$dest.tmp" && mv "$dest.tmp" "$dest"
fi
}
sync_to_gcs results.tsv results.tsv
tar -czf /tmp/git_history.tar.gz .git/ && sync_to_gcs /tmp/git_history.tar.gz git_history.tar.gz
7.2 Dockerfile
Dockerfile用于修补工作区并将研究防护栏直接注入容器环境。我没有使用标准容器入口点,而是使用sed将"后钩子"注入代理的指令中,强制在每次架构更改后同步:
# Patch program.md to trigger our sync script after every successful training
RUN sed -i 's|uv run train.py > run.log 2>&1|&; ./sync.sh|g' program.md
# Pre-tune the batch size for NVIDIA L4 GPUs to avoid initial OOM troubleshooting
RUN sed -i 's/DEVICE_BATCH_SIZE = 128/DEVICE_BATCH_SIZE = 16/g' train.py
# Guardrail: Prevent the agent from finding a "lucky" random seed
RUN echo "\nCRITICAL: Do not modify the random seed in train.py." >> program.md
7.3 提交容器构建
逻辑注入后,将工作区提交到Google Cloud Build以将镜像推送到Artifact Registry:
gcloud builds submit --tag us-central1-docker.pkg.dev/${PROJECT_ID}/${REPO_NAME}/autoresearch-job .
7.4 实际成本是多少?
由于我将Cloud Run作业配置为使用基于实例的计费且无区域冗余(批处理作业最便宜的选项),在us-central1区域运行完整1小时执行的计算成本分解如下(截至2026年3月):
- **1个NVIDIA L4 GPU:**约$0.67/小时
- **4个vCPU:**约$0.26/小时
- **16 GiB内存:**约$0.11/小时
- 计算总计:约$1.05/小时
现在让我们看看代理当前的Gemini Flash 3 API定价。对话历史随每次实验增长,但缓存显著降低了成本。根据我实验中的令牌使用情况,一次典型实验大约使用:
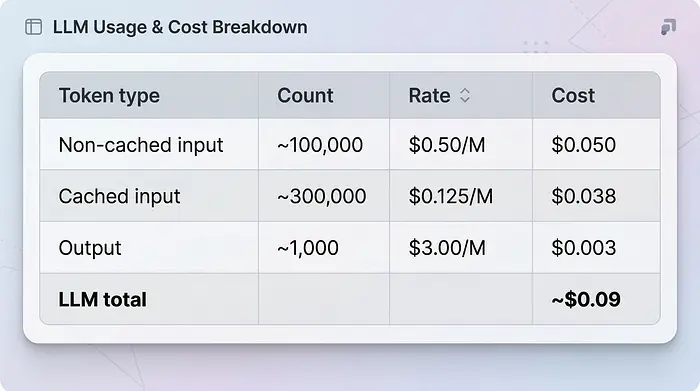
缓存命中率大约为80%,因为代理在每一轮都会重新读取相同的代码库和对话历史。即使没有缓存,输出令牌数量也很少。代理编写的是代码差异和简短的推理步骤,而不是文章。
- 智能总计:大约$0.09/次实验——按每小时6次实验计算,API成本约为 $0.54/小时。
总成本低于每小时2.00美元,你就可以运行一个高端、完全自主的架构搜索。
(注意:当你查看代理的日志时,你会看到它每次运行处理约3150万个令牌。不要惊慌!这些是 数据集 令牌——来自ClimbMix数据集的单词被馈送到本地运行在L4 GPU上的PyTorch模型。它们不使用任何API调用,也不产生额外费用。)
8、安全提示:在yolo模式下运行代理
让AI代理在无人监督的情况下运行代码需要保持谨慎。--yolo标志授予Gemini CLI无限制的执行权限:pip install、curl、git push和shell命令,无需任何确认提示。
Cloud Run开箱即用地提供基线保护。gen2执行环境使用gVisor进行内核级容器沙箱化。我还在容器内以非root用户身份运行代理,并使用具有最小IAM权限的专用服务账号。
最有影响力的安全措施是锁定网络。默认情况下,Cloud Run容器具有完全的出站互联网访问权限。你可以通过将作业放置在专用VPC网络上(使用Direct VPC egress)来弥补这一缺陷,然后使用防火墙规则拒绝所有出站(除了使用Private Google Access访问Google API)。这意味着代理仍然可以访问Gemini API和Cloud Storage(它仅需的两个服务),但任何尝试curl外部服务器或将数据上传到第三方服务的企图都会被静默阻止。
设置包括创建具有子网的VPC、两条防火墙规则(拒绝全部+允许Google API)以及一个Cloud DNS区域,将*.googleapis.com路由到私有VIP。完整分步说明在README的网络隔离部分。
9、结束语
autoresearch项目是对一种即将变得普遍的模式的早期探索:代理不只是编写代码,还运行代码、测量结果并在没有人工介入的情况下进行迭代。
这里描述的无服务器栈旨在使这种模式易于使用。你不需要预留GPU或管理基础设施就可以开始实验。以下是如何开始:
- 探索原始项目:Karpathy的autoresearch仓库包含你需要了解研究循环的一切——
program.md、train.py和评估框架。 - 无服务器部署:我的配套仓库github.com/kweinmeister/autoresearch-serverless包含
Dockerfile、同步脚件、Workflows编排以及在几分钟内在Cloud Run上运行的设置说明。 - 启动你的第一个作业:按照Cloud Run Jobs文档启动你自己的GPU支持的研究代理。
原文链接: Run Karpathy's autoresearch on a Google serverless stack for $2/hour
汇智网翻译整理,转载请标明出处
